컴퓨터는 처리 대상인 수와 문자를 비트열로 변경하여 처리한다. 따라서 이미 수와 문자에 대해서 비트열로 대응되는 규칙이 정해져 있다.
어떤 속성을 나타내는 집합에 포함된 대상을 일정한 대응 규칙에 의해서 비트열로 표현하는 체계를 타입 Type이라고 한다. 이미 C/C++의 경우 기본 타입primitive type이 정의되어 있어서 수와 문자를 쉽게 처리할 수 있다.
ex) 타입 종류
- 숫자 : int, short, long, __int64, float, double 등
- 문자 : char, wchar_t 등
- 문자열 : 문자들의 모임이기 때문에 문자들을 담을 수 있는 문자열 전용 파생 타입을 제공
- 시간이나 날짜 : 구조체 타입
1. 정수 타입
정수 타입은 크게 두가지로 나뉜다.
- 부호 없는 정수 타입 : 0을 포함하는 자연수 체계
- 부호 있는 정수 타입 : 0, 자연수, 음의 정수를 아우름
1.1 부호 없는 정수
0을 포함한 자연수를 부호 없는 정수(unsigned type)라고 한다. 부호 없는 정수 타입에 대한 특징은 다음과 같다.
- 부호가 항상 양이기 때문에 unsigned로 표시
- 종류 : unsigned short, unsigned int, unsigned long, unsigned __int64 등
- 공통점 : 수가 비트열로 대응되는 규칙이 일정하다.
- 차이점 : 비트열의 비트 수가 다르다.
ex) unsigned short의 경우 16비트 사용하지만 unsigned __int64의 경우 64비트를 사용- 비트열의 비트 수가 다름 -> 비트 수가 클수록 큰 수 표현 가능 -> 메모리 공간 많이 사용
32비트 운영체제 기준에서 타입별 대응되는 수의 범위는 아래와 같다. 참고로 4비트==0~15 로 16가지 상태를 나타낼 수 있고, 8 bit는 1 byte와 같다.
| 타입 | 바이트 | 비트 | 표현 가능한 값의 범위 |
|---|---|---|---|
| unsigned short | 2 byte | 16 bit | 0~65,535 |
| unsigned int | 4 byte | 32 bit | 0~4,294,967,295 |
| unsigned long | 4 byte | 32 bit | 0~4,294,967,295 |
| unsigned __int64 | 8 byte | 64 bit | 0~18,446,744,073,709,551,615 |
1.2 음의 정수 표현
단순히 가장 왼쪽 최상위 1 비트인 부호 비트를 사용하여 부호를 나타낼 경우 0이 [+0, -0]과 같이 두 개의 비트열로 대응되어 수를 오직 15개 밖에 표현할 수 없다는 단점이 있다. 이런 단점으로 인해 '2의 보수' 방법이 채택되었다.
2의 보수를 배우기 전에 먼저 1의 보수부터 알아야한다. 어떤 수를 비트열로 나타냈을 때 각 비트를 반전시킨 것을 1의 보수라고 한다. 2의 보수는 1의 보수에 1을 더한 것을 나타낸다.
ex) 5가 1의 보수를 거쳐 2의 보수가 되는 과정
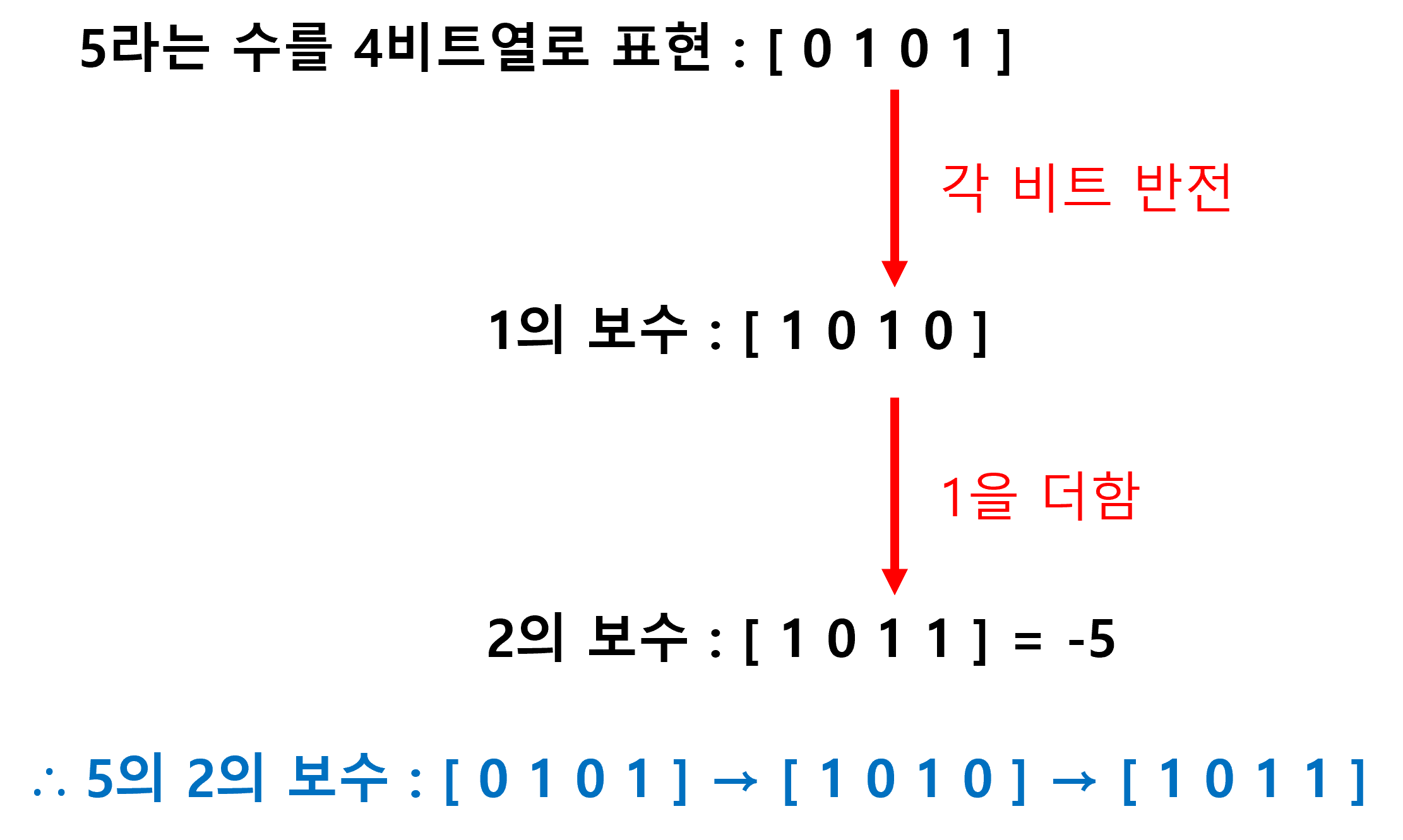
2의 보수를 사용하는 근본적인 이유는 2의 보수를 부호가 반대인 수로 사용하기 위해서이다. 예를 들어서 5는 [ 0 1 0 1 ] 이고 2의 보수는 [ 1 0 1 1 ] 인데 [ 1 0 1 1 ]을 부호가 반대인 -5로 대응시킨다. 당연히 반대로 성립한다. -5는 [ 1 0 1 1 ]이고 2의 보수는 [ 0 1 0 1 ]이므로 5가 된다. 아래 그림에서 7부터 -8까지가 2의 보수법 범위이다.
ex) 2의 보수 : 4비트 표현

위의 그림에서 눈여겨볼 점은 2의 보수법으로 인하여 음수의 경우 가장 왼쪽 비트가 항상 1이므로 자연스럽게 부호 비트로 사용된다. 즉, 가장 왼쪽 비트만 조사해도 양수인지 음수인지 판단할 수 있다. 또한 위의 그림을 통해서 외워도 될 가치가 있는 몇 가지 중요한 점을 알 수 있다.
- 가장 작은 수는 부호 비트가 1이면서 나머지 비트는 모두 0이다.
- -1은 모든 비트가 1이다.
- 반대로 가장 큰 수는 부호 비트가 0이면서 나머지 비트는 모두 1이다.
1.3 부호 있는 정수
부호가 없는 타입 앞에는 unsigned 키워드가 앞에 붙는 반면, 부호가 있는 타입은 보통 signed 키워드를 생략한다. 따라서 부호가 있는 타입은 short, int, long, int64 등이 있다.
short, int, long, int64는 서로 비트 수가 다르지만, 각 타입에 따른 비트 수는 시스템에 시스템에 따라서 달라질 수 있다.
시스템에 따른 타입의 비트 수 변화
- short
- Window 계열 : 2바이트
- Linux 계열 : 2바이트
- int
- Window 계열 : 4바이트
- Linux 계열 : 4바이트
- long
- 32비트 Windows, Linux 시스템 : 4바이트
- 64비트 Windows : 4바이트
- 64비트 Linux 시스템 : 8바이트
- long 타입을 사용하게 될 경우 64비트 Windows와 Linux의 코드 이식을 할 경우 호환성 문제가 발생할 수 있기 때문에, 가능하면 정수형 타입으로 long을 사용하지 않는 것이 좋다.
- __int64
- Window 계열 : 8바이트
- Linux 계열 : 8바이트 -> Linux 계열은 __int64대신 long long을 사용
2. 부동소수점 타입
부동소수점은 실수를 정규화해서 유효 숫자와 지수를 추출하여 저장한다. 부동소수점을 비트열에 대응시킬 경우 고정소수점에 비해서 넓은 범위의 수를 저장할 수 있지만, 그만큼 오차가 커진다는 사실을 꼭 기억해야 한다.
2.1 소수의 2진수 변환
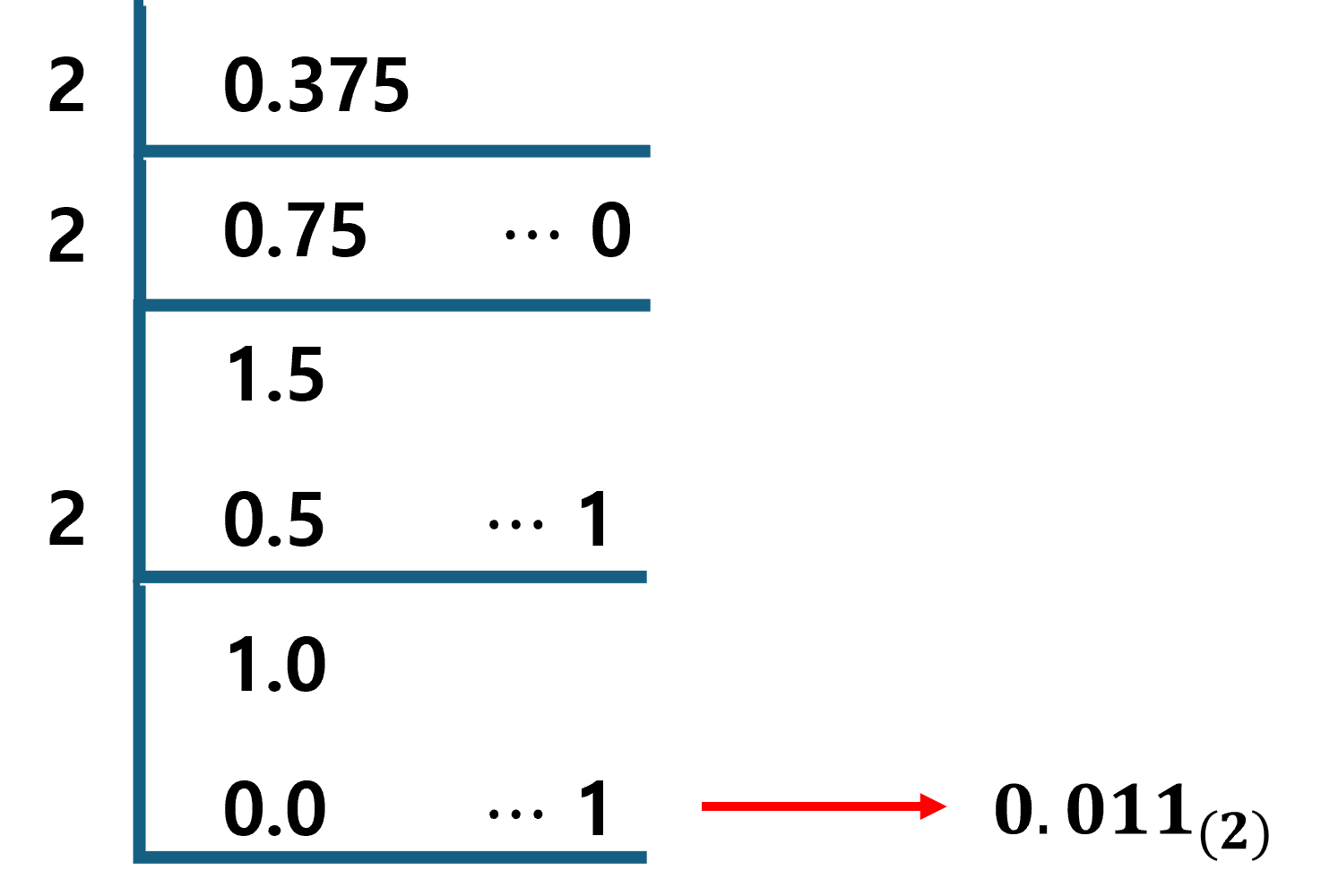
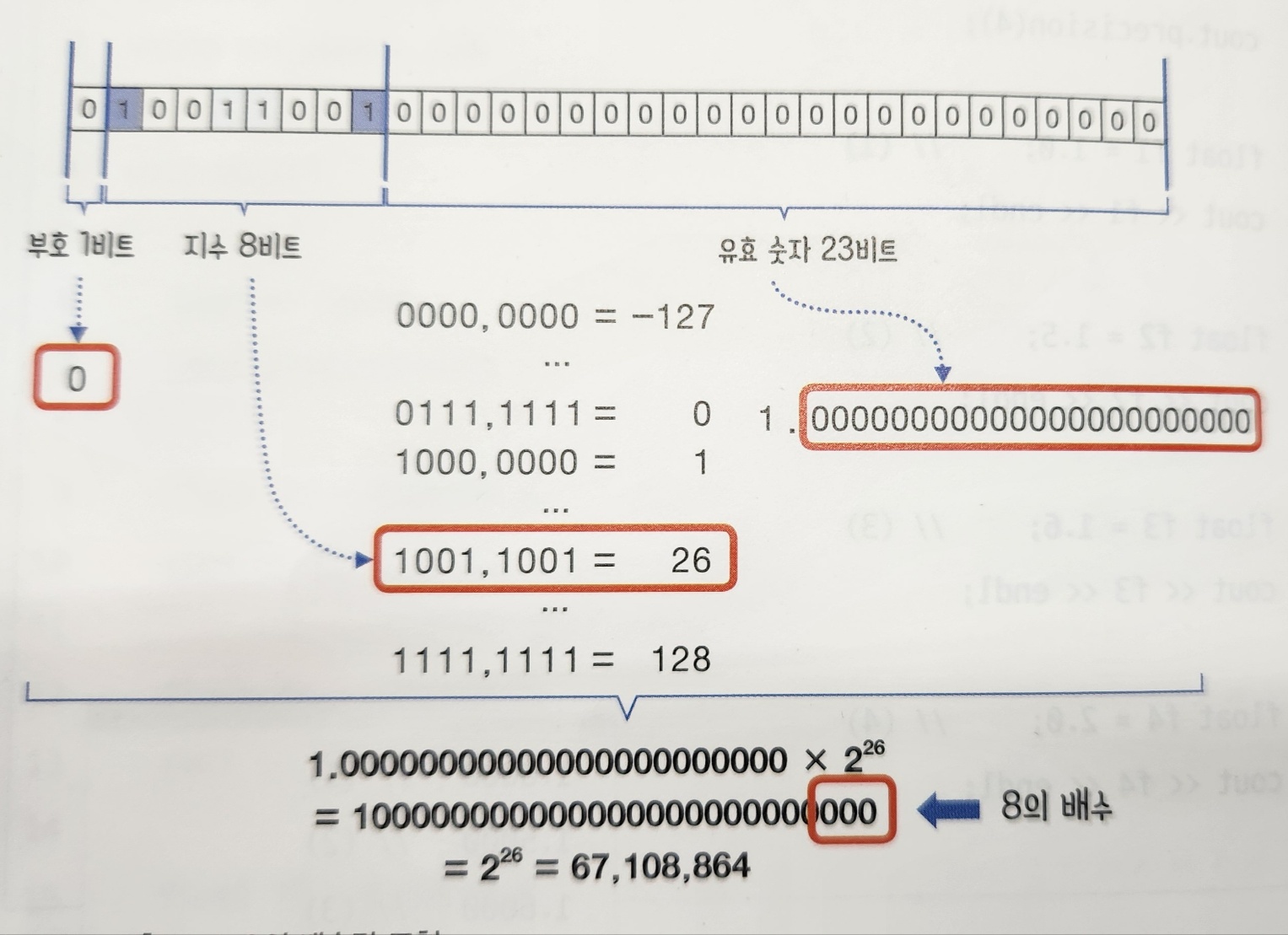
10진법으로 표현되는 -5.375를 2진법으로 변환해보자. 소수를 2진수로 변환할 때는 소수 부분에 2를 곱해서 정수부분을 얻는다. 만일 2를 곱한 결과가 1을 넘을 경우 1을 뺀다. 각 단계에서 정수 부분(1 or 0)을 얻어내면 2진수가 된다. 최종 결과가 0이 나오면 계산이 종료되며, 보통 대부분의 실수는 이 과정을 순환하면서 무한 반복하기 때문에 적당한 개수의 유효 숫자를 얻어낸다. 결국 -5.375를 2진법으로 표현하면 이 된다. 아래 그림은 소수 부분을 2진법으로 변환하는 과정을 보여주는 그림이다.
2.2 부동소수점의 구조
이제 앞에서 구한 을 부동소수점 타입 중 크기가 4바이트(32비트)인 float로 저장해보자.
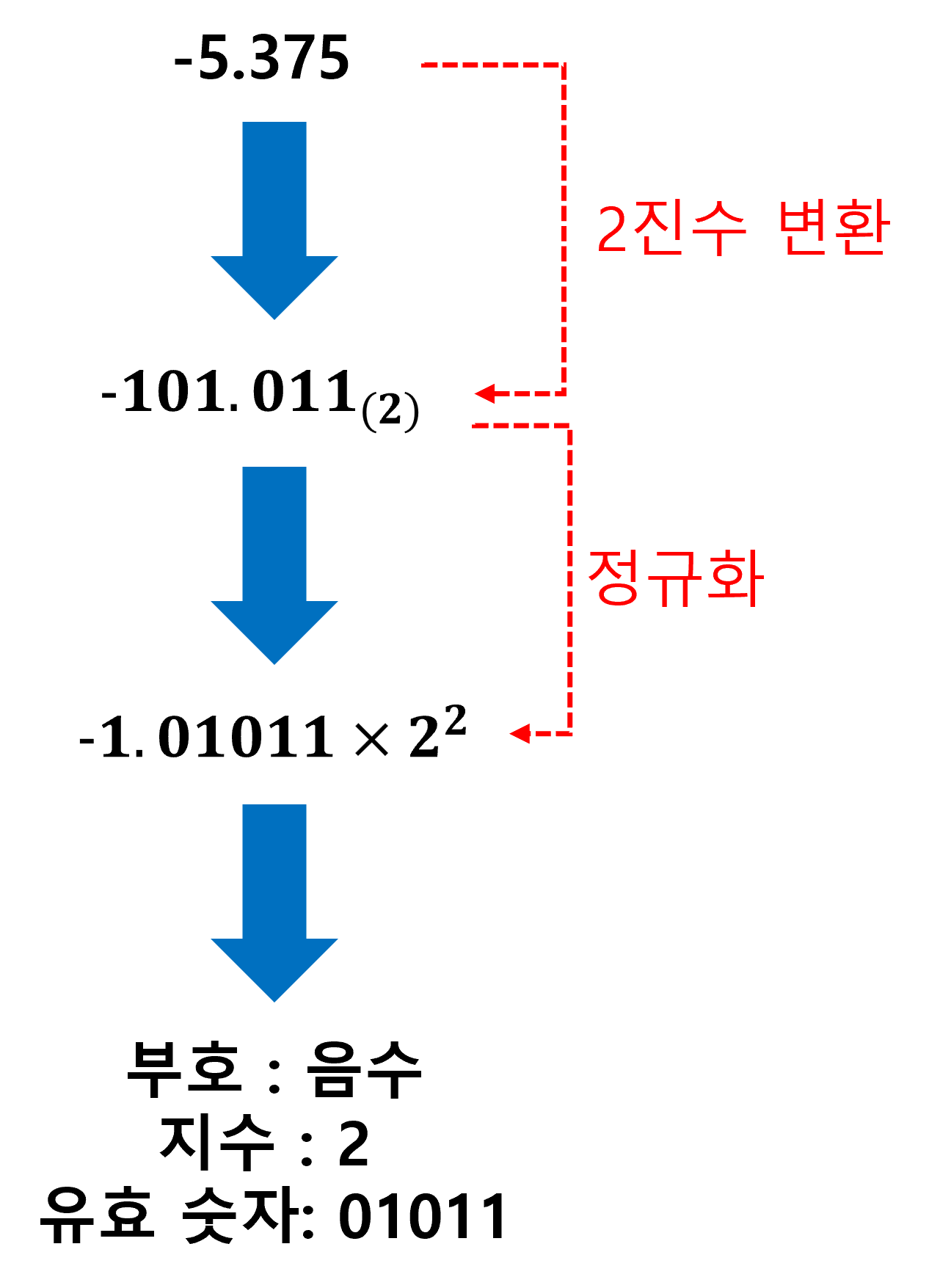
부동소수점 타입으로 변환하기 전에 먼저 2진수를 정규화한다. 10진법의 정규화와 2진법의 정규화는 조금 다르다.
- 10진법의 정규화 : 정수부를 0으로 만들면서 소수점 바로 다음이 0이 아닌 수가 되도록 지수를 조정하는 작업
- 2진법의 정규화 : 정수부가 1이 되도록 지수를 조정하는 작업
여기서는 2진수를 정규화해야 하기 때문에 2진법의 정규화를 해야한다. 따라서 은 정규화할 경우 이 된다. 이제 [부호,유효 숫자, 지수]를 추출해야 한다. 여기서 유효 숫자란 정규화 후의 소수부의 숫자를 말한다. 따라서 [부호: 음수, 유효 숫자: 01011, 지수: 2]가 추출된다.이제 남은 작업은 이미 정의된 부동소수점 타입 float의 구조에 맞게 [부호, 지수, 유효 숫자]를 잘 배치하는 것이다.
C++는 부동소수점 타입으로 float(32비트), double(64비트)을 기본으로 제공한다. 아래의 표는 IEEE754에 정의된 부동소수점 타입의 구조를 나타낸 것이다.
| 타입 | 부호(비트) | 지수(비트) | 유효 숫자(비트) | 총합(비트) |
|---|---|---|---|---|
| float | 1 | 8 | 23 | 32 |
| double | 1 | 11 | 52 | 64 |
위의 표를 통해 두 타입의 부호 비트는 양수면 0, 음수면 1이 되기 때문에 공통적으로 1비트임을 알 수 있다. 두 타입의 다른 부분은 지수와 유효 숫자의 비트 수인데 double에 할당된 비트가 더 많다. 따라서 double이 float에 비해서 정밀도가 좋으며 표현할 수 있는 수의 범위도 훨씬 넓다. 정밀도가 좋다는 것은 실수를 표현하는 데 오차가 적다는 의미이고, 표현할 수 있는 수의 범위가 넓다는 것은 지수의 비트가 늘어나기 때문에 그로 인해서 절댓값이 큰 수거나 작은 수를 표현할 수 있다는 의미이다.
절댓값이 작고 클 때의 오차 변화에 대해 정리하면 아래와 같다.
-
작은 절댓값: 절댓값이 작을 때, 즉 숫자가 0에 가까울 때, 부동소수점 표현의 유효숫자 범위 내에서 정확하게 표현될 확률이 높기 때문에 상대적으로 오차가 적다.
ex) 와 같은 작은 수를 표현할 때, 유효숫자의 모든 비트가 유효 숫자를 표현하는 데 사용된다. 즉, 작은 절댓값에서는 유효숫자의 비트 대부분이 유효숫자로 채워지기 때문에 상대적으로 높은 정밀도를 유지할 수 있다. -
큰 절댓값: 절댓값이 클 때, 즉 숫자가 매우 크다면, 부동소수점 표현에서 유효숫자 부분에 할당된 비트 수가 동일하더라도 표현할 수 있는 숫자의 정밀도가 떨어진다.
ex) 큰 절댓값을 표현하기 위해 지수가 커지면, 유효숫자의 비트가 상대적으로 더 큰 값을 표현하는 데 사용된다. 예를 들어 와 같은 큰 수를 표현할 때, 유효숫자의 작은 변화도 실제 값에서 큰 차이를 만든다. 따라서, 큰 절댓값에서는 유효숫자의 비트수가 같더라도 절대적인 오차가 더 커지게 된다.
결론적으로, 부동소수점에서 절댓값이 작을수록 유효숫자의 비트가 작은 변화를 잘 표현할 수 있어 오차가 작고, 절댓값이 커질수록 유효숫자의 동일한 비트 변화가 더 큰 차이를 유발하여 오차가 증가한다.
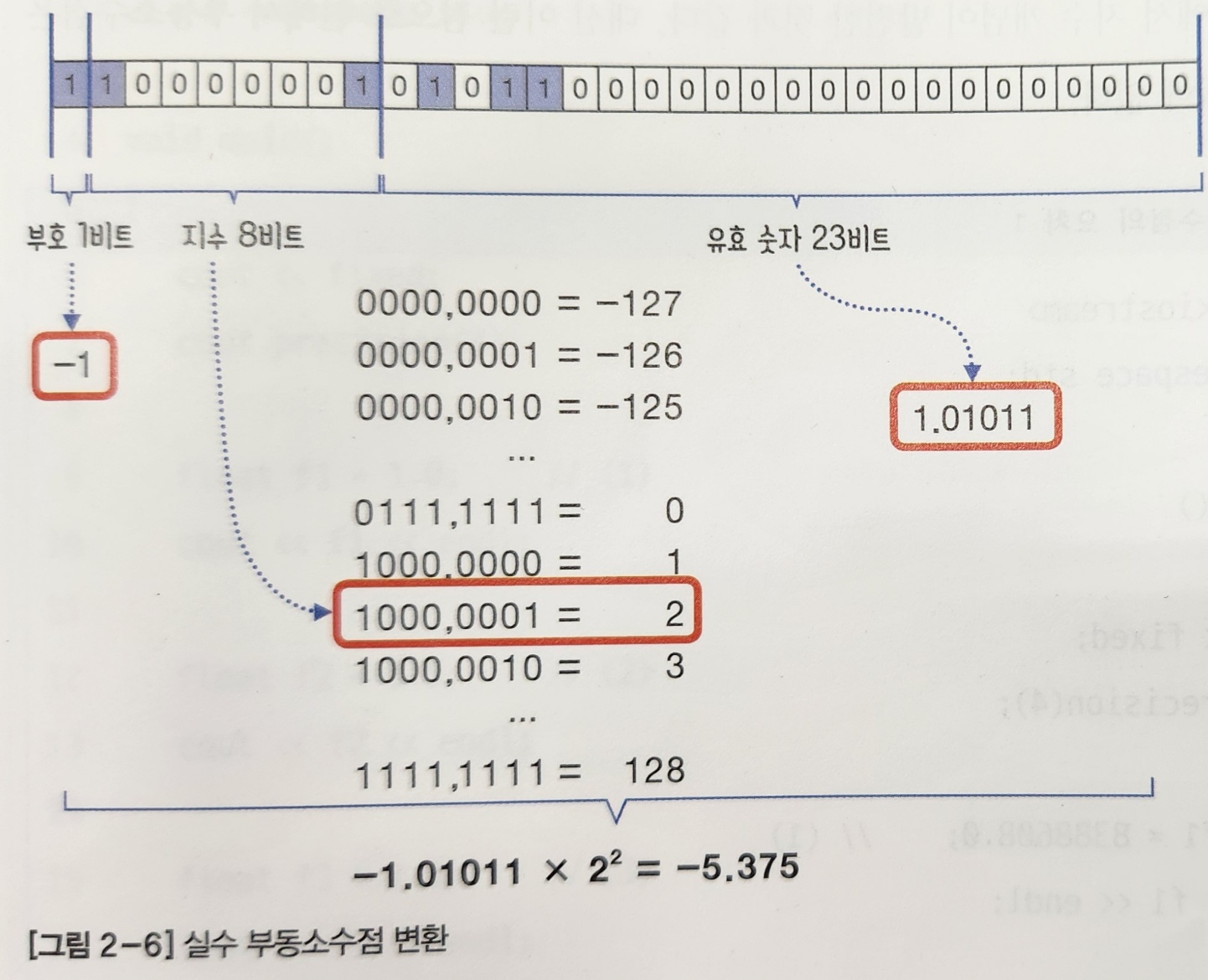
위의 그림을 통해서 실수 -5.375가 float로 어떻게 대응되는지 보자. -5.735는 부호가 음수이므로 맨 앞의 비트는 1로 채워지고, 유효 숫자인 01011은 float의 유효 숫자 23비트에 그대로 채워진다. float의 지수 비트는 8비트이므로 총 256개의 지수(-127 ~ 128 범위의 지수)를 표현할 수 있다. 즉, 지수 비트 [0000,0000]~[1111,1111]은 그대로 지수 -127~128로 대응된다. 그러므로 의 지수는 2이므로 지수 비트로 표현하면 [1000,0001]이 된다.
2.3 부동소수점의 오차
부동소수점의 목적
- 실수 표현
- 아주 작은 수와 아주 큰 수를 표현
부동소수점은 마치 수학에서 지수 개념이 발전한 것과 같지만, 대신 이런 점으로 인해서 오차가 발생할 수밖에 없다. 아래는 부동소수점의 오차를 보여주는 예시이다.
#include <iostream>
using namespace std;
void main()
{
cout << fixed; // 소수점 이하 네 자리를 보여주기 위한 옵션
cout.precision(4); // 소수점 이하 네 자리를 보여주기 위한 옵션
float f1 = 8388608.0; // (1)
cout << f1 << endl;
float f2 = 8388608.5; // (2)
cout << f2 << endl;
float f3 = 8388608.6; // (3)
cout << f3 << endl;
float f4 = 8388609.0; // (4)
cout << f4 << endl;
}
/* 출력
8388608.0000 // (1)
8388608.0000 // (2)
8388609.0000 // (3)
8388609.0000 // (4)
*/(1), (4)의 f1, f4는 입력된 값으로 잘 출력되는 반면, (2), (3)의 f2, f3은 입력된 값의 소수점 이하가 사라지고 정수만 출력되고 있다. 즉, 소수점 한 자리도 제대로 표현하지 못하는 것이다. 다음의 부동소수점 오차 예시도 보자.
#include <iostream>
using namespace std;
void main()
{
cout << fixed;
cout.precision(4);
float f1 = 1.0; // (1)
cout << f1 << endl;
float f2 = 1.5; // (2)
cout << f2 << endl;
float f3 = 1.6; // (3)
cout << f3 << endl;
float f4 = 2.0; // (4)
cout << f4 << endl;
}
/* 출력
1.0000 // (1)
1.5000 // (2)
1.6000 // (3)
2.0000 // (4)
*/첫번째 예제와 달리 위의 예제는 모든 수가 제대로 출력되고 있다. 두 예제의 결과에서 차이가 나타나는 이유는 부동소수점 타입의 구조에 따른 것이다. 부동소수점은 절댓값이 작을수록 오차가 줄어들고 절댓값이 커질수록 오차가 급격히 증가한다. float의 구조에서 유효 숫자는 23비트인데, 만일 유효 숫자 비트가 23 이상이면 float는 더 이상 소수 이하를 표현할 수 없음을 의미한다. 왜냐하면 소수점이 유효 숫자의 오른쪽으로 이동하면서 유효 숫자는 모두 정수만 나타내기 때문이다.
예제 2-3은 실제 확인 코드이다.
#include <iostream>
using namespace std;
void main()
{
cout << fixed;
cout.precision(0);
for (int i = 0;i<9;i++)
{
float f = 67108864 + i;
cout << f << endl;
}
}
/* 출력
67108864
67108864
67108864
67108864
67108864
67108872
67108872
67108872
671088722.4 정확한 계산을 위해 주의할 점
부동소수점 타입을 이용해서 큰 숫자에 대해서 정밀 계산을 하는 것은 무척 위험하다. 따라서 정수를 대상으로 큰 수에 대하여 계산을 하려면 64비트 정수 타입인 __int64나 long long을 사용해야 한다.
#include <iostream>
using namespace std;
void main()
{
cout << fixed;
cout.precision(0);
float f = 67108864 + 4; // (1)
cout << f << endl;
__int64 i64 = 67108864 + 4; // (2)
cout << i64 << endl;
}
/* 출력
67108864
67108868
*/위 예시의 출력 결과에서 알 수 있듯이 (1)의 float 변수 f는 잘못된 값이 저장된다. 그에 비해서 12행의 __int64 변수 i64는 올바른 값을 보여준다. 큰 정수의 계산을 위해서는 64비트 정수 타입을 사용해야 한다. 위의 결과에서 부동소수점 타입과 정수 타입은 절대 호환될 수 없음을 알 수 있다.
3. 문자 타입
C++가 기본으로 제공하는 문자 타입은 두 가지가 있다. 알파벳과 숫자 및 기호들을 나타내는 'char'와 유니코드 문자를 나타내는 'wchar_t'이다.
3.1 char
ASCII(American Standard Code for Information Interchange)는 알파벳, 숫자, 각종 기호에 번호를 붙인 것이다. 이렇게 대상에 번호를 붙이는 것을 인코딩이라고 하는데 아스키 ASCII가 바로 문자 인코딩이다. ASCII는 각 문자를 7비트로 표현한다. 따라서 개의 문자를 표현할 수 있다.
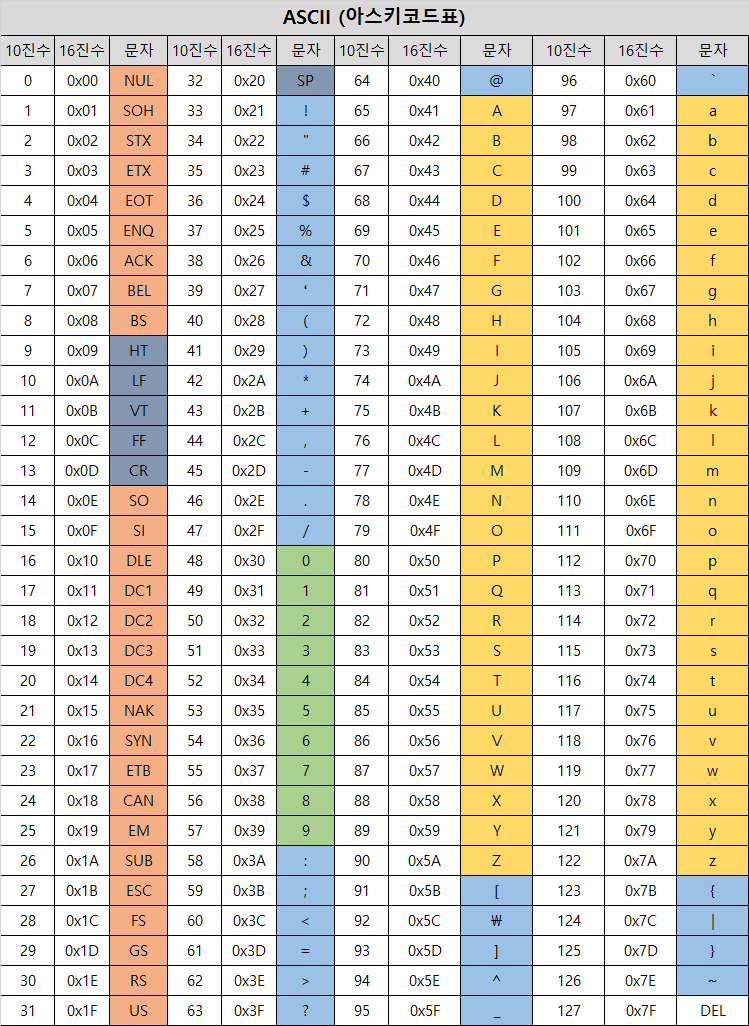
위의 아스키 코드 표에서 확인할 수 있듯이 나열된 문자가 128개이다. 따라서 7비트면 충분히 대응 가능하다는 것을 알 수 있다. C++에서는 char 문자 타입을 제공하는데, char 문자 타입은 첫 비트는 0으로 설정한 채 1바이트(8비트)를 아스키 코드에 대응시킨다.
아스키 코드 표에서 알 수 있듯이 문자를 저장하는 방법은 간단하다. 각 문자에 해당하는 코드(10진수, 16진수)를 저장하거나 직접 문자를 대입하면 된다. 따라서 char는 실제로 1바이트 크기의 부호 있는 정수 타입과 같다.
// 예제[2-5] char가 정수 타입으로 사용되는 방법
#include <iostream>
using namespace std;
void main()
{
char c1 = 'A'; // 문자 직접 대입
char c2 = 65; // 코드(10진수) 대입
char c3 = 0x41; // 코드(16진수) 대입
// char는 정수 타입이기 때문에 사칙연산도 가능
char d1 = 'A' + 1; // 11행
char d2 = 66;
char d3 = 0x42;
cout << c1 << c2 << c3 << d1 << d2 << d3 << endl;
}char는 정수 타입이기 때문에 사칙 연산도 가능하다. 따라서 11행과 같은 문자와 숫자를 더하는 식도 가능하다. 이는 'A'라는 문자가 컴파일러에 의해서 65로 치환되기 때문이다. 참고로 문자를 나타날 때는 'A'처럼 작은 따옴표로 문자 하나를 묶어야 한다. 그렇지 않으면 컴파일 오류가 발생한다.
3.2 유니코드
-
아스키 코드
- 영문자와 숫자 기타 기호들에 코드를 부여한 것
- 128 개의 문자를 나타내기 때문에 1바이트 char로 모두 대응 가능
-
유니코드(Unicode)
- 전 세계 모든 문자에 유일한 코드를 부여한 체계
- 상당히 많은 문자가 있기 때문에 1바이트는 턱없이 부족
- 따라서 유니코드를 대응시키는 여러 가지 방법이 개발됨
- 그런 방법을 통틀어서 UTF(Unicode Transformation Format)-N이라고 함
ex) N의 값에 따라서 UTF-8, UTF-16, UTF-32
3.3 UTF-N
UTF-N은 문자 하나를 대응시키기 위하여 N비트의 배수 크기만큼 사용하는 것이다.
- UTF-8
- 문자 코드에 따라서 한 글자가 8비트(1바이트), 16비트(2바이트), 24비트(3바이트), 32비트(4바이트)를 차지
- 알파벳과 숫자는 1바이트를 사용 → UTF-8의 1바이트 문자는 아스키와 호환 가능
- 유럽지역의 문자는 2바이트를 사용
- 한글은 글자 하나가 3바이트에 대응 → 한글 문화권의 경우 메모리 사용량이 좋지 않음
- 알파벳이 많이 사용된다면 메모리를 조금만 사용하기 때문에 인터넷 통신에 많이 사용됨.
- UTF-16
- 문자 코드에 따라서 한 글자가 16비트(2바이트), 32비트(4바이트)를 차지
- 알파벳과 숫자, 한글, 한자 모두 2바이트를 차지 → 길이를 구하거나 검색 및 변환을 할 때 성능이 좋음
- 한글의 경우도 2바이트를 차지하므로 메모리 절약 면에서 UTF-8보다 더 나음
- Windows 시스템은 UTF-16 사용
- UTF-32
- 모든 문자가 32비트(4바이트)를 차지
- 공간을 너무 많이 차지하기 때문에 거의 사용 X
현재 가장 많이 사용되는 유니코드 대응 방식은 UTF-8과 UTF-16이다.
3.4 wchar_t
C++는 UTF-16, UTF-32로 대응되는 문자 타입 wchar_t를 기본으로 제공한다. 시스템에 따라서 wchar_t는 2바이트나 4바이트를 차지한다. Windows 시스템을 비롯하여 많은 시스템은 wchar_t가 2바이트이다.
char의 경우 문자 하나를 나타내기 위하여 작은따옴표로 묶는다. 즉, 'A'는 1바이트 아스키 문자를 나타낸다. 그에 비해서 wchar_t의 경우 문자 하나를 나타내려면 L 매크로와 작은 따옴표를 같이 사용해야 한다. 즉, L'A'는 2바이트 유니코드 문자를 나타낸다.
3.5 Escapde Sequence(탈출 문자)
탭, 백스페이스, 작은따옴표와 같이 문자 중에는 눈으로 볼 수 없거나 모양은 있으나 표기하기 어려운 경우도 있다. 이러한 문자를 표시하기 위해서 특별한 형식으로 정의한 문자를 Escape Sequence(탈출 문자)라고 한다. 탈출 문자는 백슬래시()를 조합하여 표기한다.
| Escapde Sequence | 아스키 코드 | 설명 |
|---|---|---|
| \0 | 0 | NULL |
| \b | 8 | Backspace |
| \t | 9 | Tab |
| \n | 10 | Line Feed(LF) |
| \r | 13 | Carriage Return(CR) |
| \" | 34 | 큰따옴표 |
| \' | 39 | 작은따옴표 |
| \ | 92 | Backslash |
[표]주요 Escape Sequence
편집기에 Enter를 누를 경우, '\r\n'이 입력된다. 보통 약어로 CR, LF로 표기하기도 한다.
4. 문자열
문자열은 문자들이 모여서 만들어진다. 문자열은 길이가 천차만별이기 때문에, 고정된 크기의 비트열에 대응시킬 수가 없고, 수나 문자 타입처럼 고정된 크기의 타입이 존재할 수 없다. 대신 여러 가지 방식으로 문자열을 저장하는데 C++를 비롯하여 많은 프로그래밍 언어가 채택한 방식이 바로 NULL 종료 문자열이다.
4.1 NULL 종료 문자열
대부분의 프로그래밍 언어는 문자열을 나타내기 위하여 문자 배열을 이용한다. 특히 C++를 비롯하여 주요 프로그래밍 언어는 문자 배열의 끝에 문자열의 끝을 표기하기 위하여 NULL을 기록하는 방식을 사용하는데 이런 방식의 문자열을 'NULL 종료 문자열'이라고 한다.
실제로 C++는 문자열을 다룰 때 배열을 읽으면서 NULL을 만날 경우 문자열의 끝이라고 판단하여 처리를 마친다. 배열 안에 NULL이 없을 경우 배열의 영역을 벗어나서까지 NULL을 찾으려고 하기 때문에 제대로 문자열이 출력되지 않는다. 따라서 제대로 문자열을 마무리하려면 배열 마지막에 NULL을 대입하면 된다.
문자열은 큰따옴표로 묶어서 나타내는데, 배열을 정의할 때 문자열을 대입할 수 있다. 배열에 문자열이 대입될 때는 배열의 끝에 NULL이 자동으로 대입된다.
// [예제 2-7] char 타입 문자 배열의 문자열 대입
#include <iostream>
using namespace std;
void main()
{
char str1[8] = "C++"; // 배열 str1은 8개의 char 문자가 저장될 수 있음. // 6행
char str2[] = "C++"; // 7행
char str3[8]; // 9행
str3 = "C++"; // Error // 10행
cout << str1 << endl << str2 << endl;
}배열 str1은 앞에서부터 'C','+','+'가 대입되고 바로 다음에 NULL이 대입된다. str2와 같이 배열에 첨자가 없을 경우, 자동으로 char 4칸 배열이 생성되면서 'C','+','+',NULL이 대입된다. 10행의 경우는 컴파일 오류가 발생한다. 배열은 오직 정의되는 순간에만 초기화(대입)할 수 있기 때문이다.
4.2 유니코드 문자열
앞에서는 char 타입의 문자 배열이었다면, 이번에는 wchar_t 타입의 문자 배열에 대해 다룬다. wchar_t 또한 문자 배열의 끝에는 NULL이 들어간다. char 타입의 문자 배열에서 NULL을 탈출 문자로 표기할 때 '\0'이었다. wchar_t 타입의 문자 배열에서 NULL은 L'\0'이다.
// 유니코드 문자열
#include <iostream>
using namespace std;
void main()
{
wchar_t str[] = L"C++";
wcout << str << endl;
}wchar_t는 char 문자열과 사용법이 거의 비슷하다. char 대신 wchar_t를 사용하고, 문자열을 나타낼 때는 L 매크로와 함께 큰따옴표로 감싼다. 마지막으로 문자열을 출력하기 위하여 cout 대신 wcout을 사용한다.
4.3 한글 문자열
한글 문자열을 문자 배열로 저장하는 가장 좋은 방법은 유니코드 문자열을 사용하는 것이다. 유니코드 문자열을 사용하지 않으면 char 타입의 문자 배열을 사용해야 하므로 char 배열 2개에 한글 한 자를 저장할 수 있지만, 유니코드 문자열을 사용하면 wchar_t 타입의 문자 배열을 사용해야 하므로 wchar_t 배열 요소 1개에 한글 한 자씩 저장할 수 있다.
// [예제 2-9] char 배열과 wchar_t 배열을 이용하여 한글 문자열이 저장되는 방식
#include <iostream>
using namespace std;
void main()
{
char str[] = "대한민국";
int length = sizeof(str); // sizeof() : 피연산자의 크기를 바이트 단위로 반환하는 연산자
cout << str << length << endl; // 출력결과 : 대한민국9
wchar_t wstr[] = L"대한민국";
int wlength = sizeof(wstr);
wcout << str << wlength << endl; // 출력결과 : 대한민국10
}1바이트 char 타입에는 한글 하나가 저장될 수 없다. 따라서 한글 하나를 저장하기 위하여 char 두 개를 사용한다. 따라서 "대한민국"이 4글자 이므로 char 8개가 필요하고 마지막 NULL 문자를 포함하면 총 9개의 char가 필요하다.
반면에 wchar_t 배열 wstr에는 유니코드 방식으로 한글 문자열이 저장된다. 따라서 NULL을 포함하여 총 5개의 wchar_t가 필요하다. wchar_t는 하나가 2바이트를 차지하므로 총 10바이트가 필요하다.
4. 파생 타입
지금까지 배운 int, __int64, char, wchar_t 등은 모두 C++의 기본 제공 타입이다. 파생 타입은 이미 알려진 타입들을 이용하여 새롭게 만들어진 타입이다. 대표적인 파생 타입은 배열, 클래스(구조체), 포인터가 있으며 사용자가 직접 파생 타입을 만들 수 있도록 typedef가 제공된다.
4.1 배열
배열(Array)은 동일한 타입이 한 개 이상 일렬로 모인 집합 타입이다. 배열을 이루는 동일한 타입의 영역을 요소(element)라고 부른다. 배열은 최초로 정의될 때 요소의 개수가 정해져야 한다. 즉, 요소의 개수는 상수여야 한다.
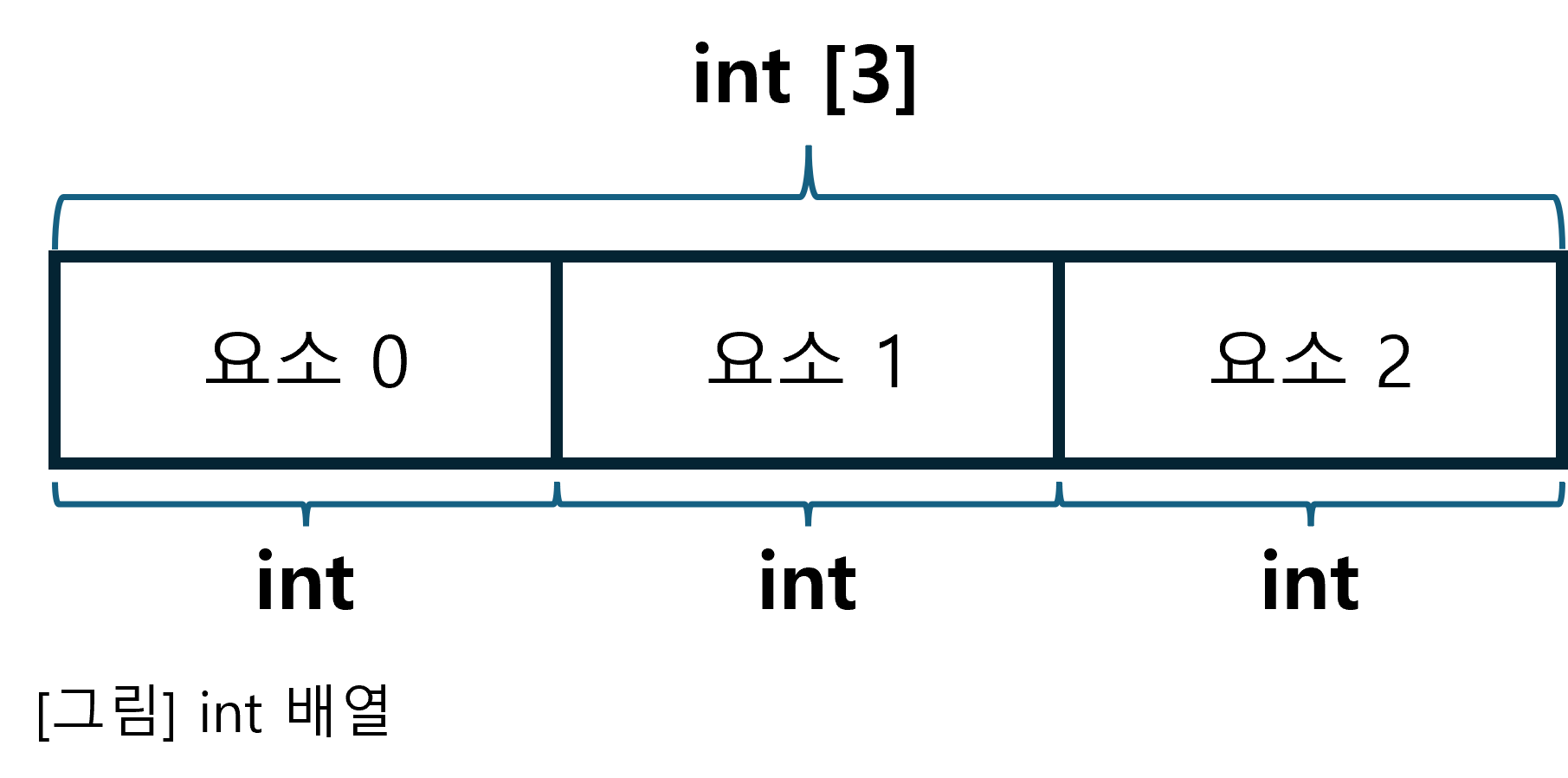
4.2 포인터
정수 타입이 정수를 비트열에 대응시키는 체계라고 한다면, 포인터 타입은 메모리 영역의 주소를 비트열에 대응시키는 체계이다.
// 포인터
#include <iostream>
using namespace std;
void main()
{
int a = 3; // 6행
int* pa = &a; // 7행 a가 나타내는 메모리 영역의 시작 주소를 Address라고 가정해보자.
cout << pa << endl << *pa << endl;
}- 6행의 의미 : 메모리의 어느 곳에 4바이트 영역을 마련하고 해당 영역의 이름을 a라고 짓고, 그 영역에 2의 보수법을 이용하여 3을 나타내도록 비트열을 구성하라.
- 7행의 의미 : pa라는 변수에 a의 주소 Address를 대입하라는 의미이다. 즉, pa는 변수 a의 주소를 담는 특수한 변수이며, 변수(pa)의 값(a의 주소)을 통해서 a를 가리킬 수 있으므로 포인터라고 불린다. 이때 pa의 타입을 포인터 타입이라고 한다. 포인터 타입을 나타낼 때는 간접(*)연산자를 사용하는데 pa가 가리키는 대상이 int 변수이므로 pa의 타입은 int*로 나타낸다.
4.3 클래스
클래스와 배열의 차이점을 비교해보도록 하자.
- 배열
- 동일한 타입을 모아놓은 것
- 배열의 동일 타입이 나타내는 영역 하나를 요소(element)라고 부른다.
- 요소는 이름이 없기 때문에 오직 순서를 나타내는 첨자에 의해 구분된다.
- 클래스(구조체)
- 하나 이상의 타입을 모아놓은 집합 타입
- 클래스를 이루는 각각의 타입이 나타내는 영역을 멤버(member)라고 부른다.
- 멤버는 이름을 갖기 때문에 이름을 통해서 구분이 가능하다.
- 클래스에는 멤버 함수도 포함될 수 있다.
클래스를 정의하는 구문은 다음과 같다.
class [CLASS_NAME] : [상속 지정자][PARENT_CLASS_NAME]
{
[접근 지정자]
타입1 멤버명1;
타입2 멤버명2;
...
[접근 지정자]
타입# 멤버명#;
타입# 멤버명#;
...
};각 파생 타입별 실제 사용 예제를 보도록 해보자.
// [예제 2-11] 파생 타입 사용
#include <iostream>
using namespace std;
class CPerson // 4행
{
public:
char* m_Name; // 타입 멤버
int m_Age; // 타입 멤버
void print()
{
cout << "Name: " << m_Name << endl;
cout << "Age: " << m_Age << endl;
}
}; // 15행
void main()
{
CPerson p[2]; // 19행
p[0].m_Name = "Kim Do Hyung"; // 21행
p[0].m_Age = 11;
p[0].print();
p[1].m_Name = "Kim Na In"; // 25행
p[1].m_Age = 9;
p[1].print();
}- 4~15행 : 클래스를 정의하는 구문
- 멤버 : m_Name, m_Age
- m_Age의 타입 : int
- m_Name의 타입 : 포인터 타입으로서 char*
- 멤버 함수: 클래스 안에 print라는 함수가 포함되어 있는데, 함수도 일종의 타입으로 취급하므로 멤버가 될 수 있다.
- 19행 : CPerson 타입이 두 개 모인 배열 p를 정의
- 배열 p에는 요소 2개가 있으며 각 요소의 타입이 CPerson이 된다. → 즉, 각 요소의 타입이 클래스 타입!!
- 각 요소는 첨자 [ ]연산자를 통해서 접근될 수 있다.
- 21행, 25행 : 멤버 m_Name에 문자열을 대입
- 큰따옴표로 묶은 문자열은 메모리의 어딘가를 char 배열의 형태로 차지한다.
- 따라서 타입이 char*인 m_Name에는 문자열이 차지하고 있는 메모리 영역의 주소가 대입된다.
5. 타입 표기
아래 표기는 대부분의 C/C++ 교재에서 사용되는 변수, 배열, 포인터, 함수의 정의 방법이다.
TYPE Name; // 변수
TYPE ArrName[N]; // 배열
TYPE* pName; // 포인터
TYPE FuncName(ARGLIST); // 함수
- 변수 : 타입을 명기하고 한 칸(혹은 탭) 이상 띄우고 변수 이름을 써준다.
- 배열 : 타입을 명기하고 한 칸(혹은 탭) 이상 띄우고 배열 이름을 적은 후 이어서 첨자([ ]) 연산자를 요소의 개수와 함께 써준다.
- 포인터 : 타입을 명기하면서 바로 뒤에 간접 연산자(*)를 붙이고, 포인터 이름을 써준다.
- 함수 : 반환 타입을 명기하고 함수 이름을 적은 후 괄호로 묶은 인자열을 적는다.
5.1 이름 자리
타입을 생각할 때는 키워드(char, int, long, float, double 등)뿐만 아니라 '이름 자리'까지 고려해야 한다. '이름 자리'란 타입의 객체가 선언될 때 객체의 이름이 표기되는 자리이다. 이름 자리는 [NP]Name Place로 표기한다.
char [NP]
int [NP]
...
double [NP]위에서 볼 수 있듯이 기본 타입으로 제공되는 타입 키워드(char, int, __int64, float, double 등)의 이름 자리는 항상 타입 키워드 바로 오른쪽에 위치한다. 몇몇 타입의 경우에는 이름 자리의 위치가 변경되기 때문에 이름 자리의 위치는 매우 중요하다. 즉, 지금 기억해야 할 것은 기본적으로 제공되는 원시 타입의 이름 자리는 타입 키워드 바로 오른쪽이라는 사실이다.
참고) 이름 자리 [NP]는 개념적인 것으로 실제 타입을 표기할 때는 생략된다.
5.2 타입 파생 규칙
앞에서 이름 자리 [NP] 개념을 제시한 이유는 기준 타입을 통해서 새로운 타입이 파생될 때 [NP] 기준으로 몇몇 기호가 덧붙여지면서 표기되기 때문이다.
배열 타입 파생
배열의 요소 타입 T를 기준으로 요소가 N개인 배열 타입을 파생하려면 타입 T의 이름 자리 [NP] 바로 뒤에 첨자 ([N]) 연산자를 붙인다. 파생된 배열 타입의 이름 자리는 그대로 유지된다.
ex1) ex1) int 요소 3개인 배열 타입을 파생
int [3]
ex2) int 요소 3개가 모인 배열 자체가 두 개 모인 배열
int arr[2][3] // 아래 그림 참고
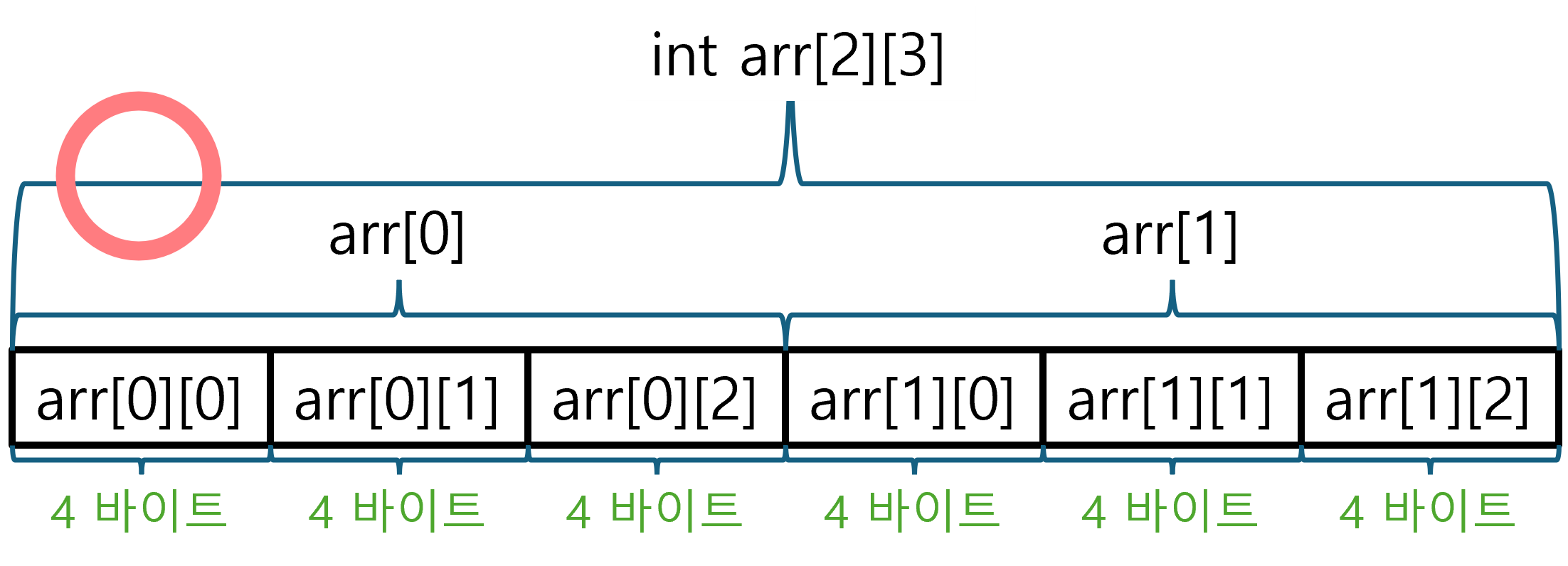
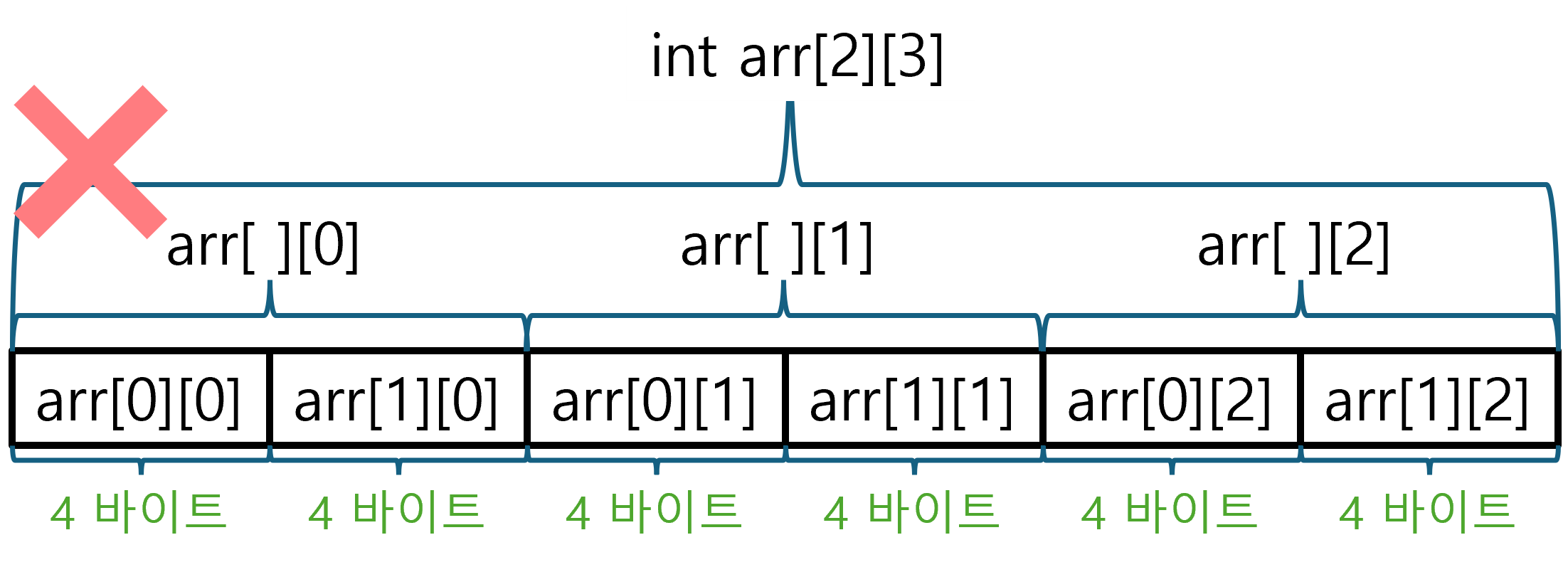
※ 참고로 C/C++에서 배열은 오직 동일한 타입이 일렬로 모인 1차원 형태만 존재한다. 2차원 이상 다차원 배열이라는 개념은 편의상 부르는 것일 뿐 2차원 이상 다차원 배열을 나타내는 타입은 존재하지 않는다. 따라서 흔히 2차원 배열이라 불리는 것은 배열 타입이 일렬로 모인 것으로 배열의 배열일 뿐이다.
포인터 타입 파생
포인터가 가리키는 타입 T를 기준으로 포인터 타입을 파생하려면 타입 T의 이름 자리 [NP] 바로 앞에 간접(*)연산자를 붙인다. 간접(*) 연산자의 결합 순위가 떨어질 경우 간접(*)연산자와 이름 자리 [NP]를 괄호로 묶어준다. 파생된 포인터 타입의 이름 자리는 그대로 유지된다.
ex1) int 타입 객체를 가리키는 포인터 타입을 파생 :
int *
ex1) int 요소 3개가 모인 배열을 가리키는 포인터 타입
int (\*)[3]
※ 간접(*)연산자는 첨자([3]) 연산자보다 결합 우선순위가 낮으므로 간접(*)연산자와 이름 자리 [NP]를 괄호로 묶어야 한다. 만일 괄호로 묶지 않을 경우 int *[3]이 되어서 int 타입을 가리키는 포인터 요소가 3개 모인 배열로 잘못 파생된다.
함수 타입 파생
함수는 반환 타입 T를 기준으로 이름 자리 [NP] 바로 뒤에 (인자 리스트)를 붙인다. 파생된 함수 타입의 이름 자리는 그대로 유지된다. C++의 함수는 전역 함수와 클래스 멤버 함수가 있다. 클래스 멤버 함수로 파생될 경우 추가로 이름 자리 [NP] 앞에 클래스명과 범위 연산자[CLASS_NAME::]를 붙인다.
ex1) 반환 타입이 int이고 인자 타입이 double인 함수 타입을 파생
int (double)
ex2) int 타입 요소가 3개인 배열 자체가 2개 모인 배열을 가리키는 포인터를 반환하는 함수 타입, 단 함수의 인자 타입은 double
int (\*(double))[2][3]
ex3) int 타입 요소가 3개인 배열 자체가 2개 모인 배열을 가리키는 포인터를 반환하는 함수를 가리키는 포인터 타입
int (\*(\*)(double))[2][3] // 함수 포인터 타입
타입 객체 정의
타입의 객체를 정의하는 것은 타입의 크기만큼 메모리의 영역을 할당한 후에 해당 영역에 이름을 붙여주는 것이다. 타입 객체를 정의하는 구문은 타입의 이름 자리 [NP]에 객체의 이름을 써주면 된다(정의 구문이므로 끝에 세미콜론(;)을 붙인다. 함수인 경우 함수 본체를 정의해야 하므로 블록을 추가한다).
ex1) int 변수 a 정의
int a;
ex2) int 요소 3개가 모인 배열 자체가 2개 모인 배열 arr을 정의
int arr[2][3];
// 타입 테스트
#include <iostream>
using namespace std;
int g_Arr[2][3];
int (*func(int arg))[2][3] // 인자 타입이 int이고, 2차원 배열 int [2][3]을 가리키는 포인터를 반환하는 함수
{
for (int i = 0; i < 2; i++)
{
for (int j = 0; j < 3; j++)
{
g_Arr[i][j] = arg; // 인자 arg의 값을 2차원 전역 배열 g_Arr의 모든 요소에 채움
}
}
return &g_Arr; // 전역배열 g_Arr을 나타내는 주소 &g_Arr을 반환
// 여기서 &g_Arr의 타입이 바로 int [2][3]을 가리키는 포인터 타입
}
void main()
{
// 함수 func에 인자 7을 넣어서 호출하여 얻은 2차원 배열의 포인터에 간접(*)연산자를 적용하여
// 다시 2차원 배열로 바꾼 후 첨자 연산자([ ])를 통해서 처음과 끝 요소의 값을 출력
cout << (*func(7))[0][0] << endl;
cout << (*func(7))[1][2] << endl;
}5.2 타입 표기 정리
매우 중요하기 때문에 반드시 기억!!
- 기본 제공되는 원시 타입의 이름 자리 [NP]는 타입 키워드 바로 오른쪽에 있다.
- 배열 요소 타입을 기준으로 [NP] 오른쪽에 첨자 연산자를 쓰면 배열 타입이 파생된다.
- 포인터가 가리키는 타입을 기준으로 [NP] 왼쪽에 간접(*) 연산자를 쓰면 포인터 타입이 파생된다(단, 우선순위를 고려하여 간접(*)연산자와 [NP]를 괄호로 묶을 필요가 있다).
- 함수의 반환 타입을 기준으로 [NP] 오른쪽에 (인자 리스트)를 쓰면 함수 타입이 파생된다.
- typedef를 통해서 새롭게 정의된 타입 키워드의 이름 자리 [NP]는 원시 타입처럼 키워드 바로 오른쪽에 있다.
6. typedef
typedef를 사용하여 복잡한 타입에 새로운 이름을 붙여서 좀 더 쉽게 정의할 수 있다.
6.1 타입 정의 방법
- 원하는 타입을 표기한 후에 이름 자리 [NP]를 새로운 타입 이름으로 교체한다.
- 가장 앞에 typedef를 붙이고 마지막에는 세미콜론(;)을 붙인다.
중요!!
typedef를 통해서 새롭게 정의된 타입의 이름자리 [NP]는 기본 제공되는 원시 타입처럼 타입 키워드 바로 뒤에 온다.
ex) int 요소 3개인 배열 자체가 2개 모인 배열 타입을 INT_ARR_23이라고 정의해보면
typedef int INT_ARR_23[2][3];
위의 예를 통해 2차원 배열 타입인 int [2][3]이 새로운 타입 이름인 INT_ARR_23으로 정의되었다. INT_ARR_23의 이름 자리 [NP]는 INT_ARR_23 바로 뒤가 된다. 따라서 INT_ARR_23 객체 arr을 정의하는 방법은 다음과 같다.
- 객체의 타입 INT_ARR_23을 기준으로 한다. → INT_ARR_23 [NP]
- 이름 자리 [NP] 대신에 객체 이름 arr을 써주고 세미콜론을 붙인다. → INT_ARR_23 arr;
// typedef를 이용한 2차원 배열 포인터 반환 함수
#include <iostream>
using namespace std;
typedef int(*ARRAY2D_POINTER)[2][3];
int g_Arr[2][3];
// 함수 이름은 func
// 인자 리스트는 int arg
// 반환 타입이 ARRAY2D_POINTER인 함수 func
ARRAY2D_POINTER func(int arg)
{
for (int i = 0; i < 2; i++)
{
for (int j = 0; j < 3; j++)
{
g_Arr[i][j] = arg;
}
}
return &g_arr;
}
void main()
{
cout << (*func(7))[0][0] << endl;
cout << (*func(7))[1][2] << endl;
}6.2 유효 범위
typedef는 유효 범위가 있다. typedef를 소스 파일에 정의했을 경우 정의된 이후부터 소스 파일 끝까지 새롭게 정의된 타입을 사용할 수 있지만, 함수 안에서 typedef를 정의했을 경우 새롭게 정의된 타입은 오직 해당 함수 안에서만 사용할 수 있다.
// typedef 유효 범위
typedef int GLOBAL_INT; // 전역 정의 -> 어디서나 사용 가능
void Func()
{
typedef int LOCAL_INT; // 지역 정의 -> 자신이 정의된 함수 안에서만 사용 가능
LOCAL_INT i; // OK
}
GLOBAL_INT g1; // OK
LOCAL_INT g2; // ERROR
void main()
{
GLOBAL_INT a1; // OK
LOCAL_INT a2; // ERROR
}위의 예시와 같이 typedef는 주로 전역 정의로 많이 사용된다!!
7. const 한정자
7.1 변수 초기화
#include <iostream>
using namespace std;
int ga; // 0 초기화 // 4행
int gb = 1; // 1 초기화
void main()
{
int a; // 미정의 값 초기화 // 9행
int b = 2; // 2 초기화
cout << ga << endl;
cout << gb << endl;
cout << a << endl;
cout << b << endl;
}4행의 전역 변수의 경우 기본 초깃값이 0이 되지만, 9행의 지역 변수의 경우 기본 초깃값 자체가 존재하지 않고 지역 변수가 점유하는 메모리 영역의 원래 값이 그대로 사용되기 때문에 사용자 PC 환경과 시점에 따라 어떤 값으로 초기화 될지는 알 수가 없다. const에서 변수의 초기화를 살펴본 이유는 const가 한정된 변수는 초기화되어 있어야 하기 때문이다.
7.2 변수 상수화
const 한정자는 변수를 상수화 시키는 역할을 한다.
void main()
{
const int c1 = 1; // const와 int의 위치는 바뀌어도 상관없다.
int const c2 = 2; // const와 int의 위치는 바뀌어도 상관없다.
}c1, c2에는 const 한정자가 붙어 있기 때문에 c1, c2는 변수임에도 불구하고 상수가 된다. 변수이면서 상수가 된다는 의미는 변수의 고유 성질인 대입이 더 이상 가능하지 않음을 나타낸다. 즉, const가 한정된 변수에는 값을 대입할 수 없다.
// const 컴파일 오류
const int gc1; // ERROR
const int gc2 = 1;
void main()
{
const int c1 = 1; // ERROR
c1 = 1; // ERROR
const int c2 = 1; // OK
}const 변수는 대입을 통하여 값을 변경시킬 수가 없다. 즉, const변수는 정의되는 순간의 초깃값이 항상 유지된다. 따라서 초깃값이 매우 중요하며 2행, 9행처럼 직접 특정한 값으로 초기화를 해야만 한다.
< const 한정자의 특징 >
변수에 const가 한정될 경우 해당 변수는 상수화된다. 그로 인해서 상수화된 변수에는 더 이상 대입을 통해서 값을 변경할 수 없으므로 반드시 특정한 값으로 초기화가 필요하다!!
7.3 const 한정 규칙
타입을 표기할 때는 각 타입의 이름 자리 [NP]를 고려해야 한다. [NP]는 곧 변수의 이름이 된다. const는 변수에 상수 속성을 한정하는 것이기 때문에 [NP] 바로 왼쪽에 붙는다. 참고로 타입명과 인접한 const의 순서는 바꿀 수 있다.
ex1) int 변수 a에 const를 한정해보면 :
int const a; // 타입명과 인접한 const의 순서는 바꿀 수 있다. const int a; // 타입명과 인접한 const의 순서는 바꿀 수 있다.
ex2) int 요소 3개가 모인 배열 arr을 한정해보면 :
const int arr[3];배열은 그 자체가 상수 객체이다. 따라서 const 한정자를 붙일 수가 없다. 따라서 const int arr[3]은 int 타입 상수가 3개가 모인 배열을 의미한다.
// const 배열
void main()
{
const int arr1[3]; // ERROR (초기화가 없는 배열이기 때문에 컴파일 오류)
const int arr2[3] = {1, 2, 3}; // OK
arr2[0] = 7; // ERROR (대입 연산자를 사용했기 때문에 컴파일 오류)
}요소가 const 한정된 배열에서 중요한 점은 요소에 const가 한정되어 있기 때문에 배열의 각 요소가 특정한 값으로 초기화가 이루어져야 한다는 사실이다. 따라서 요소의 초기화가 없는 배열은 허용되지 않는다. 또한 요소에 const가 한정되었다는 의미는 각 요소에 대입을 통하여 값을 변경할 수 없음을 의미한다.
이번에는 const와 포인터의 관계를 살펴보자. 두 가지 경우를 살펴보아야 한다.
- 포인터가 가리키는 대상에 const 한정을 하는 경우
- 포인터 자체에 const 한정을 하는 경우
// 1. 포인터(cp)가 가리키는 대상(int 객체)에 const 한정된 경우
void main()
{
int a;
const int* cp; // OK // 5행
cp = &a;
*cp = 1; // ERROR // 7행
a = 2; // OK // 9행
}5행은 포인터 cp에 const가 한정된 것이 아니라, cp가 가리키는 대상에 const가 한정되었기 때문에 초기화가 없어도 문제가 없다. 따라서 7행과 같이 const가 한정된 대상을 나타내는 *cp에는 대입 연산자를 사용하여 값을 변경할 수 없다.
여기서 주의할 점이 두가지 있다.
1. cp가 가리키는 대상이 이미 const가 한정되었어야 하는 것이 아니라 cp가 가리키는 대상에 const를 한정한다는 의미이다. 즉, 과거가 아니라 현재부터 const 한정을 한다는 의미이다.
2. 9행처럼 a에 2를 대입해도 아무 문제가 없는 이유는 const가 한정하는 대상은 메모리 영역 자체가 아니라 이름을 기반으로 하기 때문이다. 즉, const는 변수명 a에 한정된 것이 아니라 간접(*)연산자가 사용된 cp에 한정되는 것이기 때문에 7행처럼 오직 cp를 통해서 값을 바꾸는 것만이 제한된다.
// 2. int 객체를 가리키는 포인터(cp)에 const가 한정된 경우
void main()
{
int a;
int* const cp; // const 한정된 포인터 // ERROR // 5행
int* const cp = &a; // OK
*cp = 1; // OK // 7행
}포인터에 const가 한정되었기 때문에 반드시 특정한 값으로 초기화가 이루어져야 한다. 따라서 5행처럼 특정값 초기화가 없을 경우 오류가 발생한다. 7행의 경우는 포인터 자체에 const가 한정된 것이지 포인터가 가리키는 대상은 const가 한정된 것은 아니기 때문에 허용된다.
여기서 주의할 점은 int와 const의 순서를 바꿀 수 없다는 점이다. 오직 const가 타입명과 인접하고 있을 때만 순서를 바꿀 수 있는데, int와 const 사이에 간접(*) 연산자가 있으므로 바꿀 수 없다!!
// const 한정된 포인터가 가리키는 대상에 const가 한정된 경우
void main()
{
int a;
// 포인터와 포인터가 가리키는 대상 모두에 const가 한정된 경우
const int* const ccp; // const 한정된 포인터 // ERROR
const int* const ccp = &a; // OK
*ccp = 1; // ERROR
}포인터 ccp는 자기 자신과 자신이 가리키는 대상 모두에게 const가 한정되었으므로 ccp는 특정 값으로 초기화가 반드시 필요하고, *ccp에는 대입을 통한 값 변경을 할 수 없다.
8. auto
8.1 자동 변수 지정자 auto
C 컴파일러와 C++ 컴파일러 중 구버전에서 auto 키워드는 자동 변수를 의미한다. 자동 변수란 지역 변수와 같아서 함수 안에서 정의되는 변수이며, 함수 호출 시 생성되고 함수 반환 시에 소멸되는 변수를 말한다. 구형 컴파일러를 포함하고 있는 Visual Studio 2005에서 컴파일할 경우 auto 키워드는 기존의 의미와 같고 심지어 생략해도 무방하다. auto가 새로운 의미를 갖게 된 것은 C++0x이고, 새로운 auto가 지원되는 컴파일러 버전은 Visual Studio 2010부터이다.
8.2 C++0x auto
auto는 컴파일 타임에 자동으로 적절한 타입으로 추론되는 키워드이다.
// auto의 변환
#include <iostream>
using namespace std;
void main()
{
// 컴파일 허용
auto a = 1; // auto -> int // 6행
cout << a << endl; // 7행
// 컴파일 에러
auto a; // 8행
a = 1; // 9행
}6행에서 auto는 컴파일 타임에 가장 적절한 타입인 int로 추론되기 때문에, auto는 int로 변경된다. 현재 수준의 컴파일러 상황에서 auto가 타입을 추론하기 위해선는 정의 즉시 초기화가 필요하며, 8행과 같이 즉시 초기화를 하지 않을 경우 타입 추론을 할 수 없다.
// auto 추론
#include <iostream>
using namespace std;
double Divide(int a, int b)
{
return (double)a / b;
}
void main()
{
auto r = Divide(1, 2); // auto -> double // 11행
cout << r << endl;
}11행 r이 Divide(1, 2)의 반환 값으로 초기화되기 때문에 auto를 추론할 수 있다. 함수 Divide의 반환 타입이 double이므로 auto는 double로 추론된다.
위의 예시들에서 알 수 있듯이 현재의 컴파일러에서 auto가 추론될 수 있는 조건은 변수 정의 시 초기화가 이루어지는 경우이기 때문에, 초기화와 상관없는 경우 auto 추론을 할 수 없다. 일반적으로 클래스의 멤버 변수와 함수의 매개 변수는 초기화를 할 수 없으므로 auto를 사용할 수 없다.
// 매개변수의 auto 추론 실패
double Divide(auto a, auto b) // Compile Error
{
return (double)a / b;
}8.3 auto 추론 가능 타입
auto는 초기화 값의 타입으로 추론되지만 초기화 값의 타입에 const 한정자가 있어도 const는 무시되며, 초기화 값이 참조 타입일지라도 일반 타입으로 추론된다.
// auto 비참조 타입 추론
#include <iostream>
using namespace std;
const int Add(int a, int b) // 함수 Add의 반환 타입은 int이고 const 한정자가 붙어 있음
{
return a + b;
}
int& GetRef(int& arg) // 함수 GetRef의 반환 타입은 참조 타입인 int&
{
return arg;
}
void main()
{
auto s = Add(1, 2); // auto -> int // 16행
s = 7; // 17행
cout << s << endl;
int a = 1;
auto r1 = GetRef(a); // auto -> int // 22행
r1++;
cout << a << endl;
auto& r2 = GetRef(a); // auto& -> int& // 26행
r2++;
cout << a << endl;
}함수 Add의 반환 타입은 int이고 const 한정자가 붙어 있지만, 16행의 auto는 const int로 추론되지 않고 int로 추론된다. 따라서 17행처럼 s의 값을 변경할 수 있다.
함수 GetRef의 반환 타입은 참조 타입인 int&이지만, 22행의 auto는 int&로 추론되지 않고 int로 추론된다. 만약 참조 타입으로 추론되도록 만들고 싶으면 26행처럼 auto&를 사용한다. 이때 auto는 int로 추론되기 때문에 auto&는 int&로 추론된다.
const와 참조 타입이 auto로 추론될 수 없는 이유는 애초에 일반 타입의 변수도 초기화 값으로 const 한정되거나 참조 타입 반환 값을 받는 경우가 많기 때문이다.
// auto 비참조 타입 추론
void main()
{
int s = Add(1, 2);
int a = 1;
int r = GetRef(a);
}즉, 위의 예제와 같이 사용하는 경우도 많기 때문에 일반 타입으로 추론하는 것이 더 자연스럽다.
8.4 auto 사용의 장점(auto가 많이 사용되는 경우)
auto는 컴파일 타임에 자동으로 타입이 추론되기 때문에 매우 편하게 사용할 수 있다. 특히 타입의 이름이 길 경우 타이핑을 줄여주는 효과를 준다.
// 타이핑을 줄여주는 auto
#include <iostream>
#include <vector> // STL 컨테이너의 하나인 vector를 사용
using namespace std;
void main()
{
vector<int> v = { 1, 2, 3 };
int Sum = 0;
// auto -> vector<int>::iterator
for (auto it = v.begin(); it != v.end(); it++) // 초기화 식인 v.begin()의 반환 타입을 통해서 auto 추론 가능
{
Sum += *it;
}
cout << Sum << endl;
}일반적으로 auto는 vector와 같은 STL 컨테이너와 함께 자주 사용되는데, 이는 STL 컨테이너의 반복자 타입의 이름이 생각보다 길기 때문이다. 만약 auto를 사용하지 않는다면 반복자 it을 정의하기 위하여 vector의 반복자 타입인 vector::iterator를 it 앞에 써야 한다.
※ STL은 기본으로 제공되는 C++라이브러리로서 많은 자료구조와 알고리즘을 제공한다.
