참고 문헌
https://gaussian37.github.io/autodrive-ose-bayes_filter/
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=msnayana&logNo=80142756028
http://refopen.blogspot.com/2014/08/blog-post_18.html
https://namu.wiki/w/%EB%B2%A0%EC%9D%B4%EC%A6%88%20%EC%A0%95%EB%A6%AC
https://m.blog.naver.com/PostView.naver?isHttpsRedirect=true&blogId=anthouse28&logNo=221077405435
우선, 가장 중요한 본질은 베이즈 정리는 조건부 확률에 대한 것이다.
나무위키의 예시를 통해 직관적인 이해가 가능하다.
결과가 양성일 때, 이 사람이 실제로 병에 걸렸을 확률을 계산하는 것이다.
식으로는 P(병|양성) = P(양성|병)*P(병)/P(양성)
P(양성)을 양변에 곱하면 양측 모두 양성이며 병에 걸린 확률을 의미 하므로 좌우가 같게 된다.
구체적 수치로, 병에 걸렸을 때 양성일 확률이 90%이라고 해서, 양성 반응때 높은 확률로 병에 걸렸다는 것을 의미하지는 않는다. 만일 양성이 나올 확률이 병에 걸릴 확률보다 극히 높다면, 오히려 검사 결과가 잘못됐을 확률이 높다.
현대에 와서 이것이 중요해진 이유는, P(병)에 해당하는 데이터를 빅데이터를 이용해 구할 수 있게 되었기 때문이다. (원래는 실제 확률을 알지 못했기 때문에 별로 무의미한 식으로도 취급됐다고 한다.) 즉, 무수히 많은 데이터를 토대로, 전체에서 병에 걸리는 확률을 계산했다고 치고, 어느 대상자가 양성이라는 새로운 사실을 알게 되었을 때 실제 확진여부(즉 좌변)를 계산할 수 있게 되었다.
여기서 P(병)은 확률에 대한 가정으로, 새 자료가 없는 상태에서 사건이 일어날 확률이다. 사전 확률이라고 한다.
P(양성|병)은 사건이 일어났다는 가정 하에(병) 새로 가진 자료가 관측될 확률로 가능도라고 한다.
구하고자 하는 좌변을 사후확률이라고 한다.
P(양성)에 해당하는 부분은 곱을 보정해주는 역할을 하고 위 같은 예시에서는 쉽게 계산이 가능하지만, 실제로는 계산이 어려운 상황도 상당히 존재한다고 한다.
즉 특이하게, 모집단의 특성을 대략적으로 추측(빅데이터)하고 있을 때, 어떤 대상의 특성을 바탕으로, 실제로 특성을 가질 확률을 추정할 수 있는 것이다.
베이즈 정리에서 수학적으로 만족하는 식들은 다음과 같다.
P(AB)=P(A|B)P(B)=P(B|A)P(A)=P(BA)
n개의 사건에 대해 P(A1....An)=P(A1)...P(An)
P(A1|B) = P(A1)P(B|A1)/[P(A1)P(B|A1)+P(A2)*P(B|A2)]
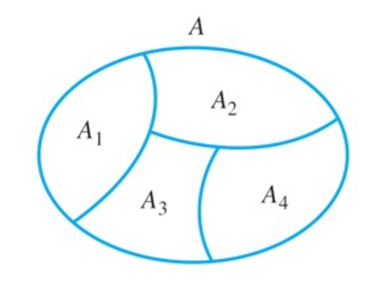
이 그림을 생각하면 된다.
이게 의미하는 바는, A 가 발생했을 때의 확률을 계산할 때 거꾸로 B가 일어났을 때의 확률들을 이용해 ㄱ뎨산이 가능하다는 것이다.
구체적 예시는, 주가가 상승할 확률 a가 50%, b가 50%라고 할 때, 주가가 상승할 확률이 실제로 주어졌을 때 3일 연속 상승할 확률이 값의 ^3임을 안다고 하면, 실제 주가가 3일 상승했을 때 확률이 a였을 확률을 계산하는 것이다.
P(0.6|3일상승)=P(3일 상승|0.6)P(0.6)/[P(3일 상승|0.6)P(0.6)+P(3일 상승|0.4)*P(0.4)]
=0.7714
베이지안 필터는 이 베이지안 정리를 이용한 것으로, 베이지안 정리를 recursive하게 따르는 것이다.
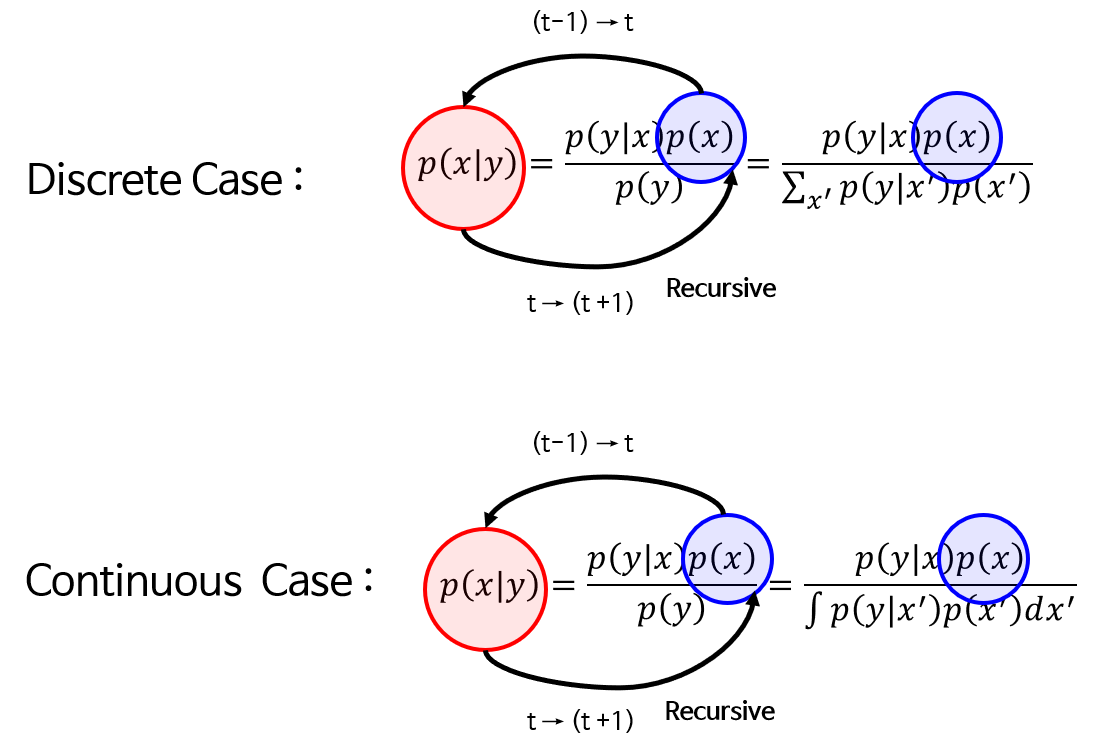
이를 잘 나타내준 그림이다. 즉, t-1까지의 결과를 토대로 P(x)를 추정해 놓은 상태에서, t에서 P(x|y)를 계산한다. 여기까지의 결과를 토대로 P(x)를 갱신한다.
즉
B(x_t) = P(x_t|z_1:t,u_1:t) 가 목적이라고 한다.
이전까지의 입력값을 통해 현재 상태를 확률적으로 추정하는 것이다. 그래서 두 가지 역할을 하는데
1. 이전 상태와 제어값을 이용해 현재 상태를 예측하는 것
2. 새로운 입력값을 현재 상태에 반영하는 것.
이게 가능한 이유는, 분포가 Markov Assumption을 따른다고 가정하기 때문. 즉, 현재의 상태가 그 이전 정보를 함축하고 있다는 것.
식 부분은 당장 안 보고 생략했다. 하지만 찾기 쉽게 링크를 기록해 둔다.
https://gaussian37.github.io/autodrive-ose-bayes_filter/
여기서 보면, 가장 큰 맹점이 적분 연산이다.
이걸 두 가지 방식으로 다루는데, Monte Carlo 적분으로 랜덤 샘플링을 통해 근사화하는 Particle Filter
적분이 되는 식만, 특히 정규 분포만 이용해 입력값들이 정규 분포를 따른다고 가정하는 것이 Kalman Filter이다.
