1. 데이터베이스 아키텍처
프로세스
필수기억
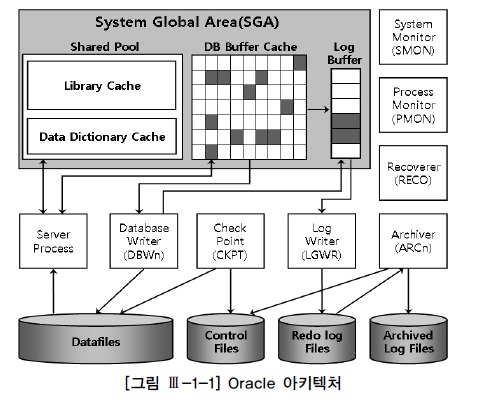
SGA : 여러 프로세스가 동시에 액세스할 수 있는 메모리 영역(공유 풀, DB 버퍼 캐시 + 로그 버퍼)
- 액세스 직렬화 메커니즘 사용 : 여러 사용자 및 프로세스가 공유하는 메모리 영역으로 SGA 내 자원을 보호하고 동기화하는 메커니즘(래치, 버퍼 Lock, 라이브러리 캐시 Lock/Pin)
[Shared Pool]
- Library Cache : SQL 및 PL/SQL(프로시저) 문을 재사용 가능하도록 저장.
- Data Dictionary Cache : 테이블, 인덱스, 사용자 권한 등의 메타 데이터를 저장하여 조회 속도 향상(user_tables, user_constraints)
[그외 공간]
-
DB Buffer Cache : 데이터 블록을 캐싱하여 읽기/쓰기 성능 향상. LRU 알고리즘으로 사용빈도가 높은 블록을 위주로 구성
- Free 버퍼 : 무료함
- Dirty 버퍼 : 기록만 안됨
- Pinned 버퍼 : 읽기/쓰기중
-
Log Buffer : 트랜잭션 변경 사항을 Redo 로그로 기록하기 전 저장
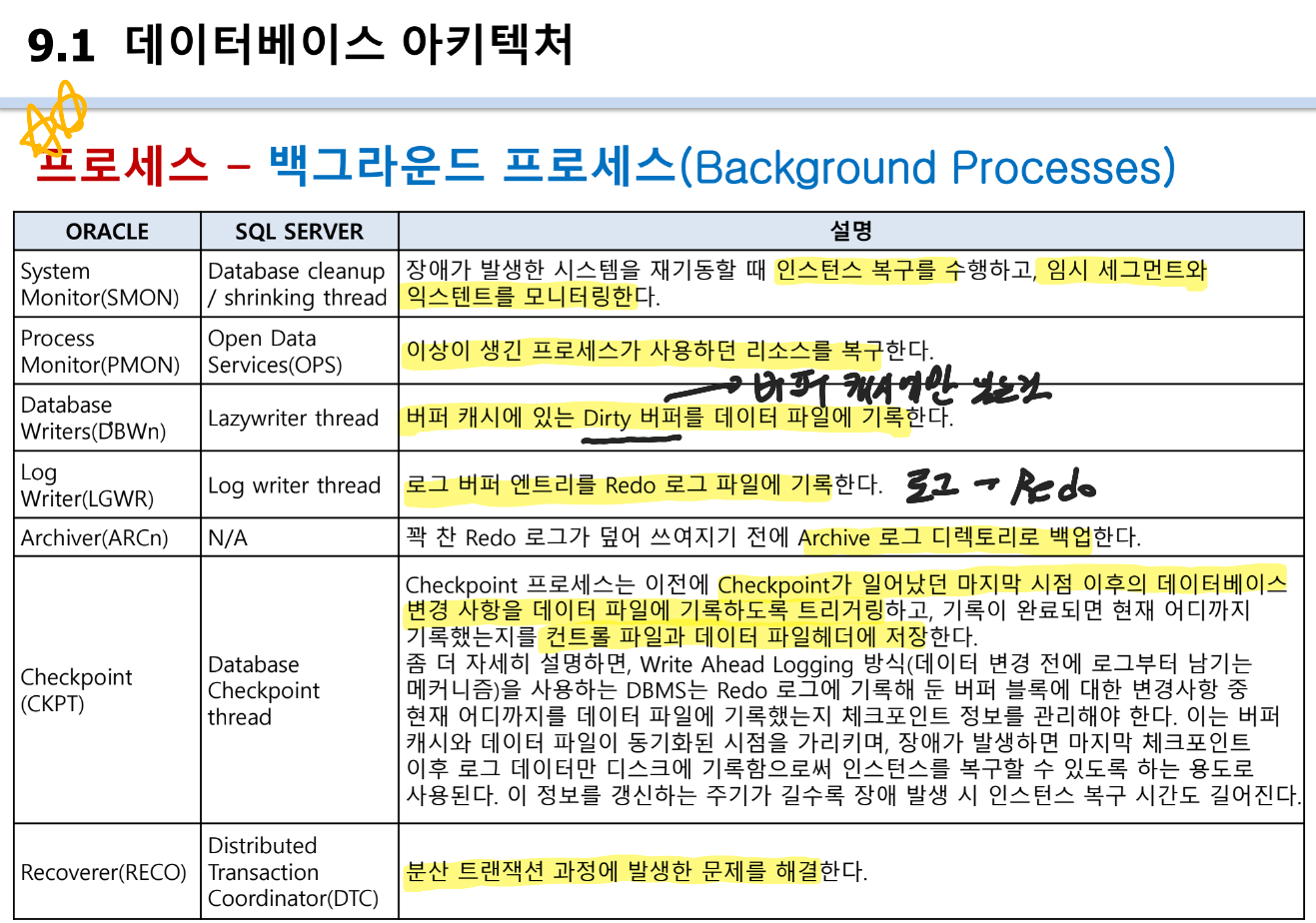
- SMON
인스턴스: 오라클 DB가 실행될 때 형성되는 메모리(SGA) + 프로세스(백그라운드 프로세스)의 집합
임시 세그먼트: 정렬(SORT)이나 임시 테이블 등에 사용되는 일시적인 저장공간
익스텐트 모니터링: SMON이 사용되지 않는 익스텐트를 회수하여 테이블스페이스의 공간을 최적화하는 기능
-
PMON
프로세스가 진행하던 SQL을 취소하고 원상태로 돌리는 것 -
DBWn
버퍼 캐시(Dirty 버퍼) -> 데이터 파일
버퍼 캐시는 SGA(메모리) 내 캐시
Dirt 버퍼(버퍼 캐시)는 아직 디스크에 기록되지 않은 버퍼
데이터파일는 테이블, 인덱스, 트랜잭션 데이터 등 모든 영구 데이터를 저장하는 물리적 파일 -
LGWR
트랜잭션이 실행되면 Redo 엔트리(로그 기록 단위 = 엔트리)가 생성되어 로그 버퍼에 저장됨
LGWR : 로그 버퍼에 있는 Redo 엔트리를 로그 파일에 저장

Redo 로그의 역할
1) DB Recovery -> 디스크 결함 복구시 Offline Redo 사용
2) Cache Recovery -> 캐시에 저장된 트랜잭션 데이터 유실에 대비하기 위한 Redo 로그
3) Fast Commit -> Append 방식으로 로그 파일에 기록하고(LGWR) 나중에 버퍼캐시 블록과 데이터파일 블록 간 동기화(DBWR 사용)
Redo Log Files 안에 Online Redo 로그파일로 구성됨
Online Redo 판일 : 인스턴스 복구. 데이터베이스 트랜잭션 변경 사항을 실시간 저장.
Offline(=Archived) Redo : 미디어, PITR 복구. Online Redo 로그가 덮어쓰기 되기 전에 별도로 저장된 파일로 ARCH가 Archive 로그 디렉토리로 백업한다.
파일구조
필수기억
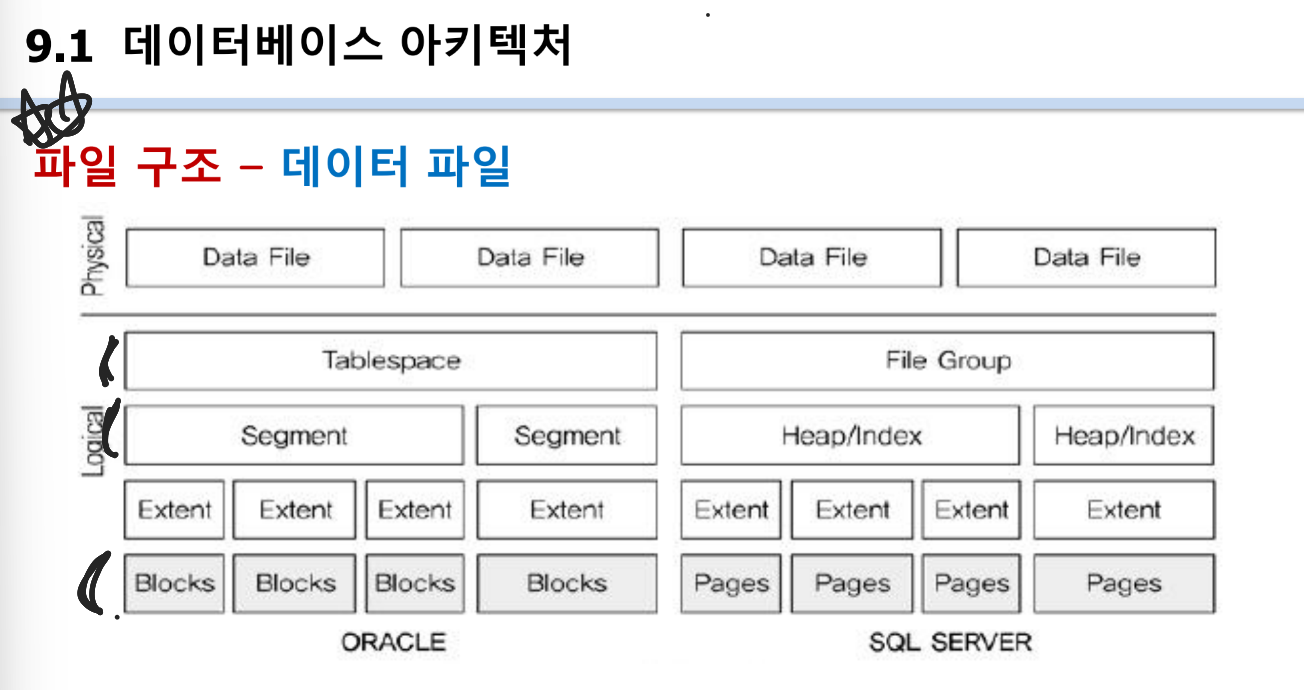
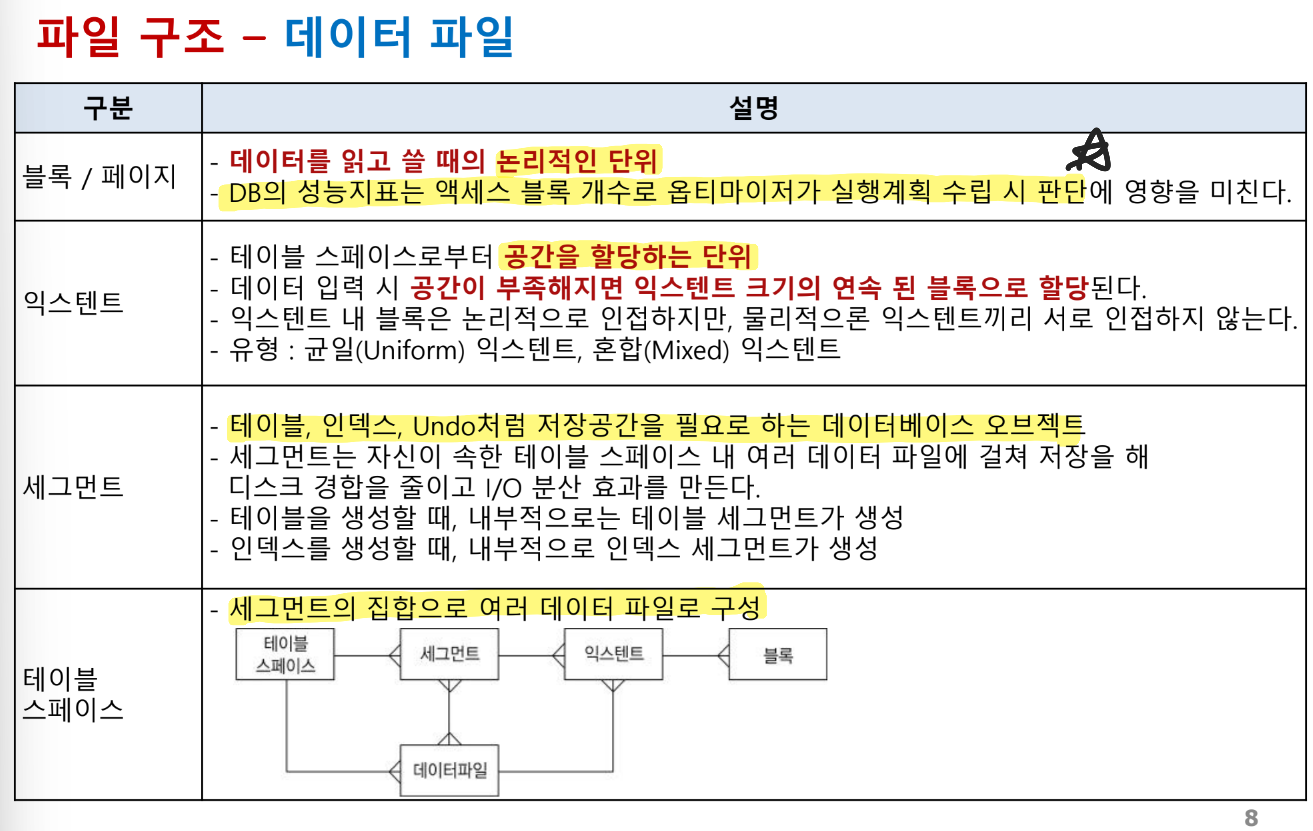
블록 : I/O 최소 단위(4kb, 8kb...)
익스텐트 : 저장 공간 관리 기본 단위. 공간을 할당하는 단위(STORAGE (INITIAL 64K NEXT 128K)). 그래서 블록 단위만큼 익스텐트내에 블록이 생성됨
세그먼트: 테이블, 인덱스 등의 데이터를 저장하는 논리적 저장 단위.
ex) 테이블 생성하면 세그먼트 생성 -> 익스텐트는 64K 먼저 생성하고 더 필요하면 128k씩 늘어남
데이터 파일: 데이터베이스의 모든 데이터를 저장하는 물리적 파일
메모리 구조

PGA : 서버 프로세스의 전용 메모리 영역
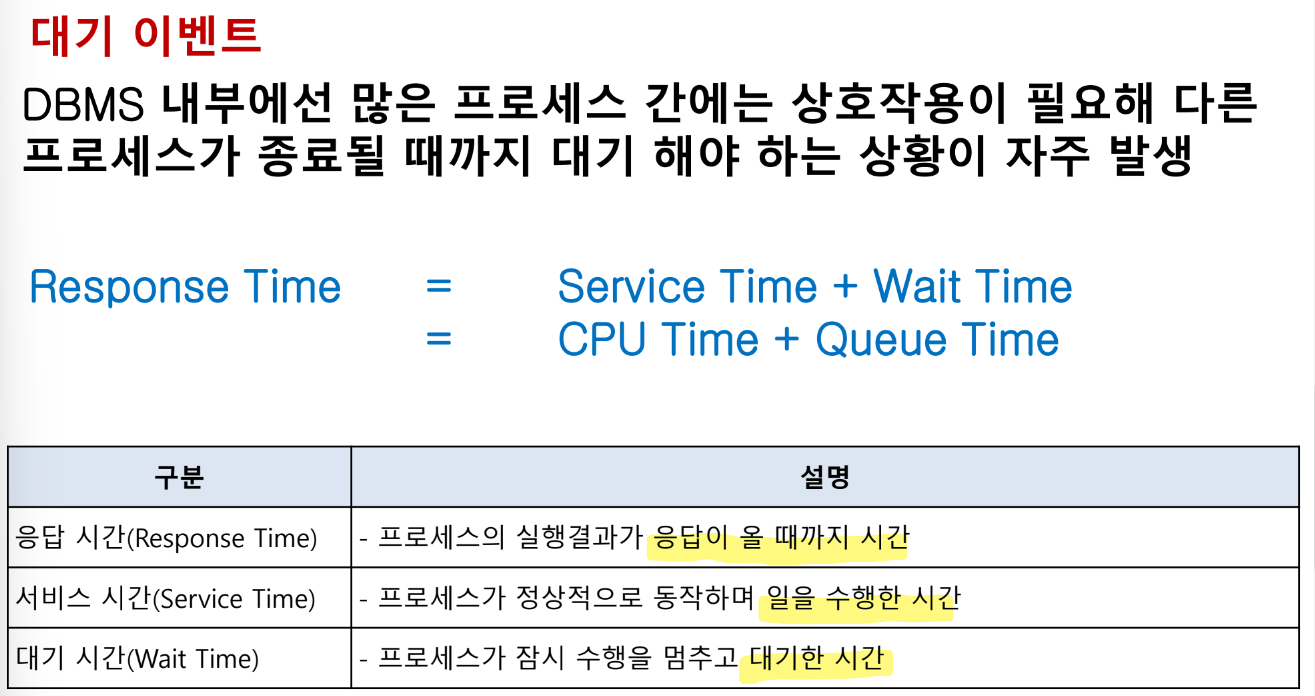
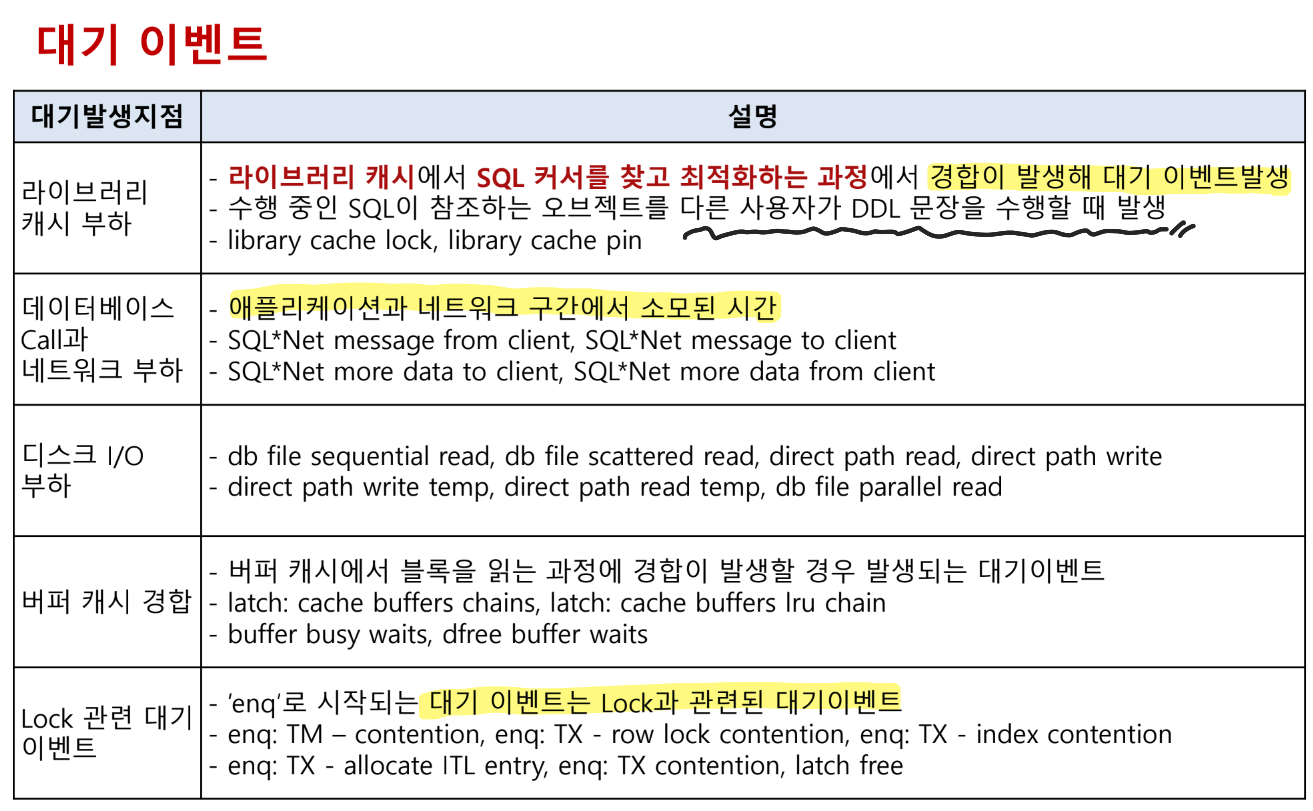
대기 이벤트
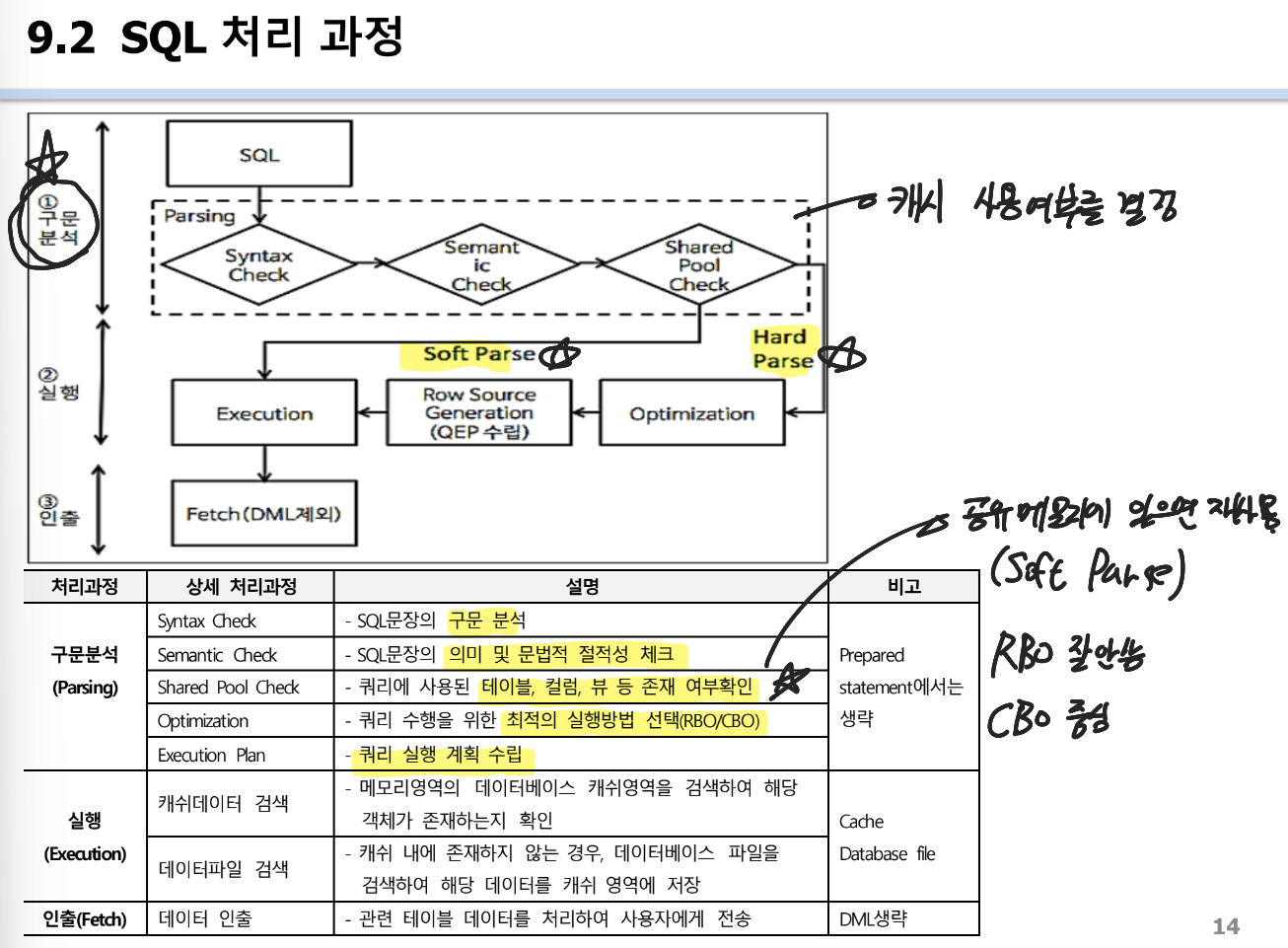
SQL 처리 과정
SQL 언어의 특징
- 구조적 : R-DBMS를 처리함
- 선언적 : 결과만 적음(과정 안적음)
- 집합적 : 반복문 없이 명령어 하나로 처리
최종 하나를 고르는 기준
현재는 CBO(Cost-Based Optimization)
과거에는 RBO(Rule-Based Optimization)
옵티마이저 힌트 - 무시되는 경우
1. 문법적으로 맞지 않게 힌트를 기술
2. 잘못된 참조 사용
3. 논리적으로 불가능한 액세스 경로
4. 의미적으로 맞지 않게 힌트를 기술
5. 옵티마이저에 의해 내부적으로 쿼리가 변환
6. 버그
옵티마이저 힌트 제대로 기술
- 힌트 안에는 ','를 사용할 수 있지만 힌트 사이에 하면 안됨
- 테이블을 지정할 때 스키마명까지 명시하면 안 됨
- FROM 절에 ALIAS 사용시 힌트에도 ALIAS를 사용
데이터베이스 I/O 메커니즘
블록 단위 I/O 하는 경우

데이터베이스 I/O 메커니즘

Sequential 액세스와 Random 액세스
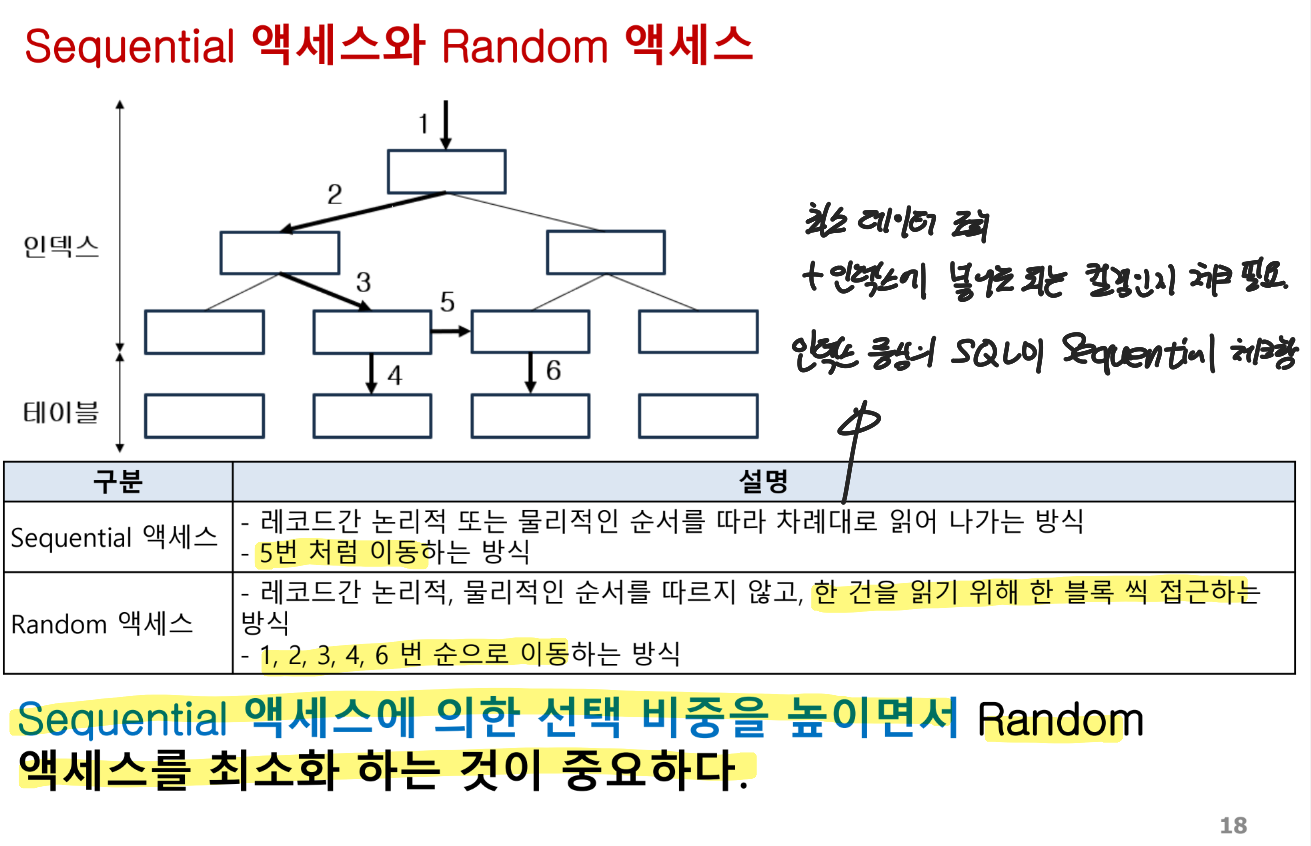
Sequential 액세스의 비중을 늘리고 Random 액세스를 최소화
- Random 액세스(Random Access) 발생 상황
- 데이터를 비연속적으로, 특정 위치에서 직접 읽거나 수정할 때 발생
- 인덱스 스캔(Index Scan) 사용 시 주로 발생
- 대량의 작은 단위 읽기(IO 비용 증가)
- Sequential 액세스(Sequential Access) 발생 상황
- 데이터를 연속된 순서로 읽거나 처리할 때 발생
- Full Table Scan(테이블 풀 스캔) 또는 Index Range Scan(범위 스캔) 사용 시 발생
대량의 데이터를 한 번에 읽을 때 유리

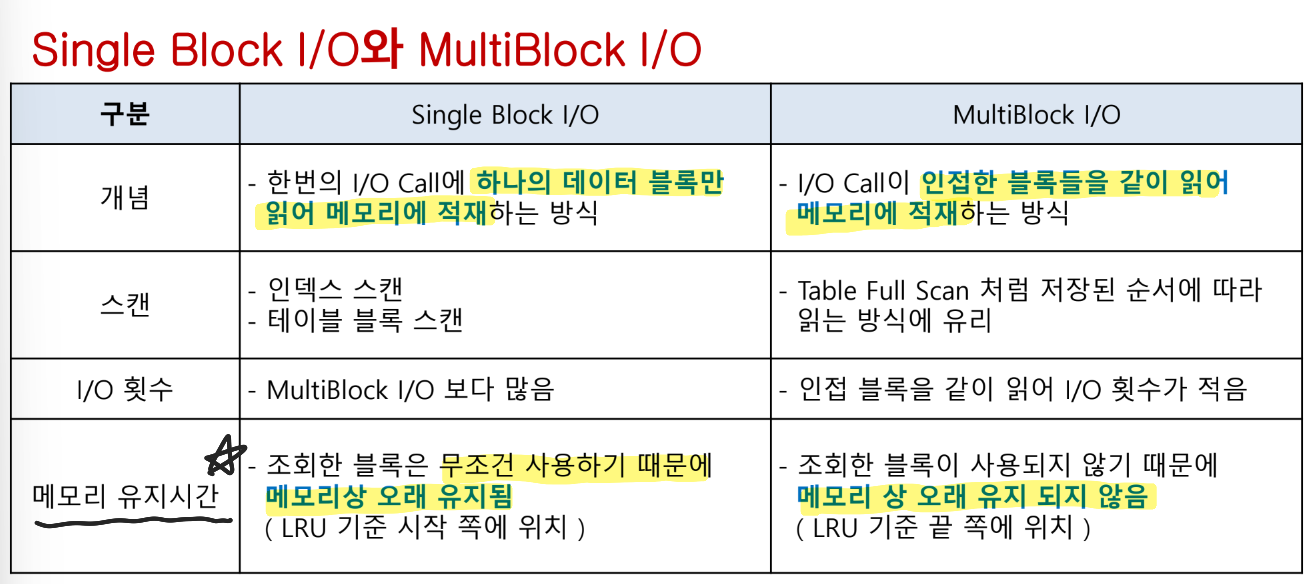
(중요)Single Block I/O와 MultiBlock I/O + I/O 효율화 원리
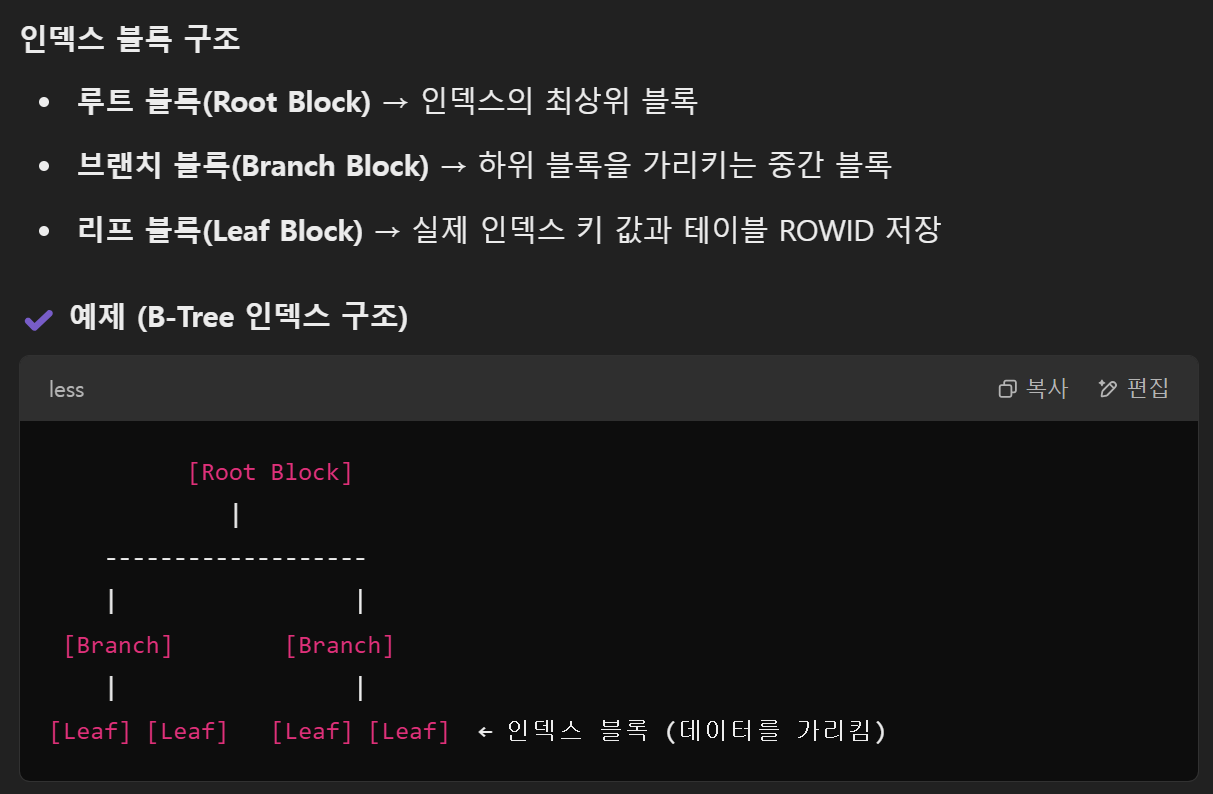
인덱스 블록 = 인덱스(Index) 데이터를 저장하는 블록. B-Tree 구조(대부분의 RDBMS에서 사용)로 구성됨. 검색 속도를 빠르게 하기 위해 정렬된 키 값을 유지. 랜덤 액세스(Random Access)에 최적화됨
테이블 블록 = 테이블의 실제 데이터를 저장하는 블록. Full Table Scan 또는 Index Lookup 후 데이터 접근 시 사용. Sequential Access가 주로 발생
Single Block I/O
인덱스를 이용할 때 인덱스와 테이블 블록 모두 Single Block I/O를 사용. 인덱스는 소량 데이터를 읽을 때 주로 사용하므로 이 방식이 효율적.(db file sequential read 대기 이벤트 발생)
- 인덱스 루프 블록을 읽을때
- 루프 블록 정보로 브랜치 블록을 읽을때
- 브랜치 블록으로 리프 블록을 읽을때
- 리프 블록으로 테이블 블록을 읽을때
Multi Block I/O
한 번에 여러 개의 블록을 읽거나 씀
db_file_multiblock_read_count 파라미터에 의해 결정됨
익스텐트 경계를 못 넘음
(필수는 아님)Direct Path I/O
버퍼 캐시를 우회하고 PGA에서 직접 읽고 씀. 주로 OLAP 환경 (대량 데이터 조회, 병렬 처리)
1. 병렬 쿼리를 실행할 때 Direct Path I/O가 발생
2. Direct Load (SQL*Loader, INSERT APPEND)
3. Index Fast Full Scan
4. 대량 정렬(Large Sort Operation)

