1. 리스트(list)
데이터를 마음데로 삽입삭제 할 수 있지만 그만큼 메모리를 많이 먹음
리스트 선언
1차원
d=[0]*100001 : 100001 크기의 리스트 생성
3차원
d = [[[[False]*436 for k in range(31)] for j in range(31)] for i in range(31)]
# 이때 가장 안쪽에 들어간 게 배열에서는 가장 마지막 부분(행,열,높이,깊이 순으로 안쪽으로 들어감)
# 436이 깊이 31이 높이 31이 열 가장 마지막 31이 행
https://shoark7.github.io/category/programming
offset index
d[이상:미만:이동수]
만약 입력을 하지 않거나 훨씬 큰 숫자를 입력하면 그냥 전체를 반환
리스트 연산
a=[]
b=[]
a+b
c=[0]*2내장 함수들
- append(데이터) : 뒤에 값 추가
- extend(리스트) : 더하기 연산과 동일(단 리스트에 리스트만 더할 수 있음)
- insert(위치,데이터) : 특정위치에 데이터 삽입
- remove(데이터) : 특정 값을 지움
- del 리스트[번호] : 특정 위치의 값을 지움
- sum(리스트) : 리스트에 있는 값 모두 합치기
- max(리스트) : 최댓값 찾아 반환
- min(리스트) : 최솟값 찾아 반환
리스트 길이 반환
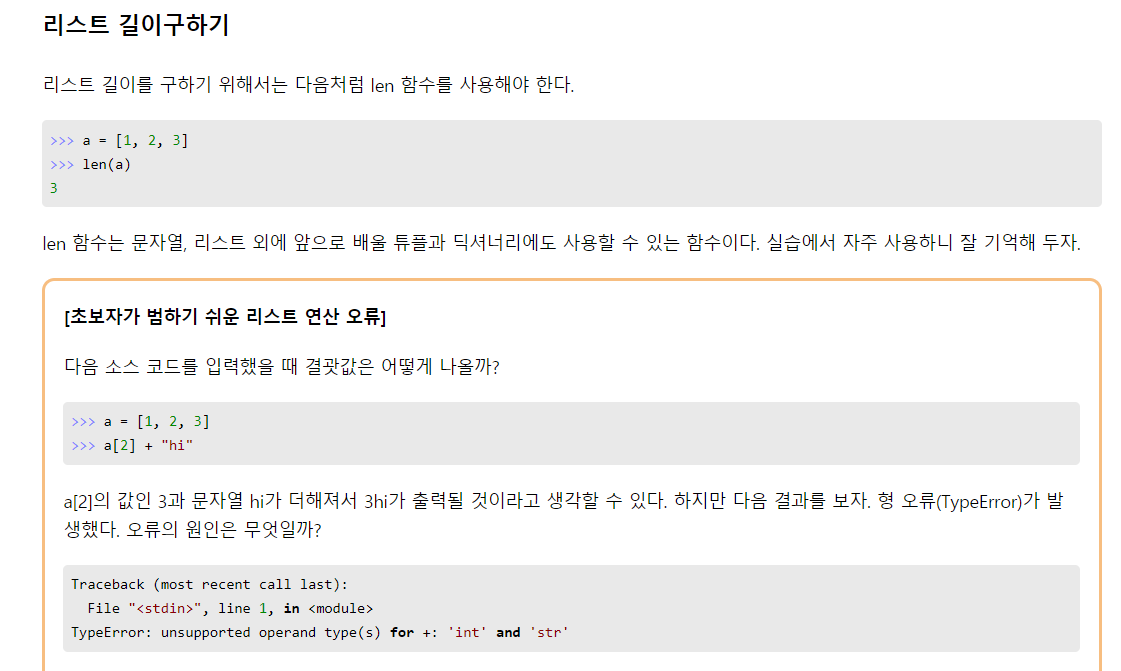
2차원 리스트 길이 반환 및 2차원 리스트 탐색
https://dojang.io/mod/page/view.php?id=2292
리스트, 튜플 출력 순서 지정
https://dojang.io/mod/page/view.php?id=2300
3차원 이상의 배열 생성하기
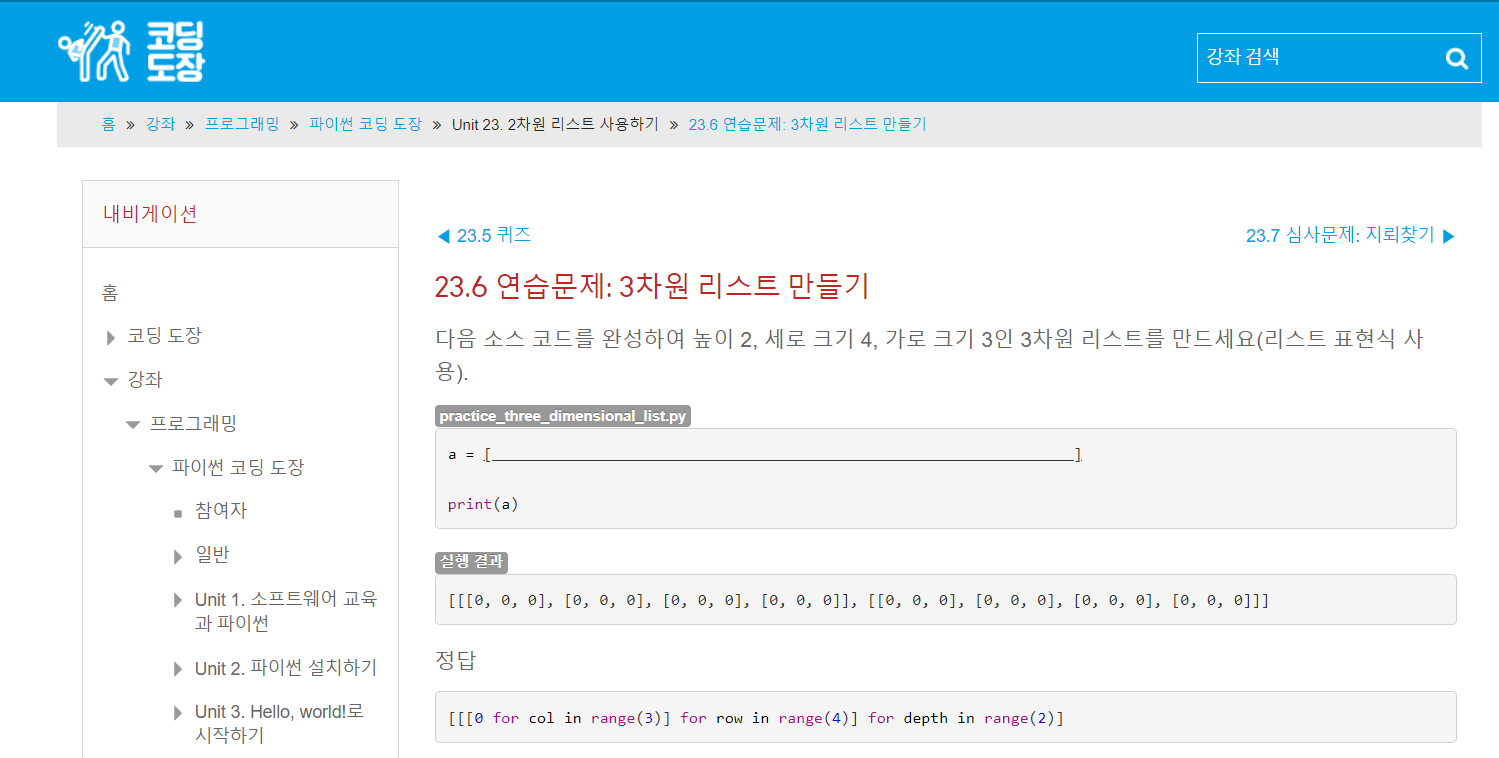
https://dojang.io/mod/page/view.php?id=2297
d = [[[[False]*436 for k in range(31)]
for j in range(31)] for i in range(31)]정리하자면 for i in range 반복
이때 가장 안쪽에 들어간 게 배열에서는 가장 마지막 부분(행,열,높이,깊이 순)
파이썬 정렬

역 정렬 포함
람다 사용하기 : 오직 기준만을 제시 가능 그래서 람다라고 작성하고 : 한다음 첫번째 정렬 순서와 정렬된 후 두 번째 정렬 순서를 정의한다.
a=[[1,2],[3,4],[5,6]]
a.sort(key=lambda(x) : (x[1],-x[0]))
sorted(a,key=lambda a : (a[1],-a[0]))파이썬 리스트 값 합치기

파이썬 리스트에 값을 덧붙이기
ans=[]
ans.append("Hello")리스트 값 초기화
list =[]
list.clear()리스트 깊은 복사하기
a=[0,0,0]
t=a[:]
이 방법으로 하거나
t=a.copy()
이 방법으로 하거나중복제거(set)
my_list = ['A', 'B', 'C', 'D', 'B', 'D', 'E']
my_set = set(my_list) #집합set으로 변환
my_list = list(my_set) #list로 변환
print(new_list)
출력된 값은 ['D', 'B', 'A', 'E', 'C']2. 출력
print(a,b,c)
print(a+b+c)
백슬래쉬, 이스케이프 문자
\t 는 키보드의 tab 버튼을 눌렀을 떄처럼 중간에 공백 넣기
format 사용하기
# 직접 대입하기
s1 = 'name : {0}'.format('BlockDMask')
print(s1)
# 변수로 대입 하기
age = 55
s2 = 'age : {0}'.format(age)
print(s2)
# 이름으로 대입하기
s3 = 'number : {num}, gender : {gen}'.format(num=1234, gen='남')
print(s3)출처: https://blockdmask.tistory.com/424 [개발자 지망생]
% 사용하기

# 이전 방식
print('나의 이름은 %s입니다'%('한사람'))
print('나의 이름은 "%s"입니다. 나이는 %d세이고 성별은 %s입니다.'%('한사람',33,'남성'))
print('나이는 %d세이고 성별은 %s입니다. 나의 이름은 "%s"입니다. '%(33,'남성','한사람'))
print('나이는 %03d세이고 신장은 %6.2f입니다. 나의 이름은 "%s"입니다. '%(33,56.789,'한사람'))
print('-' * 40)3. 입력
두 개이상의 숫자를 int로 받기
n,m = map(int,input().split())참고문헌
map은 리스트의 요소를 지정된 함수로 처리해주는 함수
map(func, list) 형태로 원래는
for i in range(len(a)):
a[i] = int(a[i])이렇게 처리해야할 함수를
map(int,a)의 한줄 짜리로 변경할 수 있다.
여러 줄 입력받아 리스트로 만들기
a = [0] * 10
for i in range(10):
a[i] = int(input())이 짓거리를 해야하는 반복문을
a=list(map(int,input()) for _ in range(10))만으로 해결 가능
하지만 위의 방식은 생각보다 에러가 자주 발생함 a가 map 타입이 된다던가 하는 그래서 아래의 방식이 조금 더 안전할 수 있음
a=[int(input()) for _ in range(9)]추가적으로 두 줄 이상이라면
a=list(list(map(int,input().split())) for _ in range(2))정리하면 가로줄 입력은
a=list(map(int,input()) for _ in range(10))
세로줄 입력은
a=[int(input()) for _ in range(9)]
빠른 입력
import sys
a = int(sys.stdin.readline())하면 캐빠름
두 개이상의 값을 받을려면
import sys
a,b = map(int,sys.stdin.readline().split())해주면 됨 '\n' 문자 기준으로 문장을 읽어옴
관련 문제 링크
https://www.acmicpc.net/problem/15552
\n 개행문자 제외하고 입력받기
5
YCPZY
CYZZP
CCPPP
YCYZC
CPPZZ
t=int(input())
a=list(list(input().split('\n')[0]) for _ in range(t))지도와 같이 숫자가 붙어있는 2차원 배열 받기
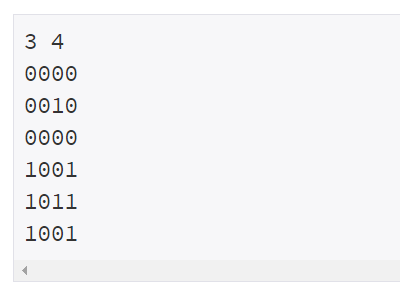
a=[list(map(int,list(input().rstrip()))) for _ in range(m)]
b=[list(map(int,list(input().rstrip()))) for _ in range(m)]받은 걸 일단 리스트로 바꾼다음 map으로 모두 int로 바꾸고 그걸 다시 리스트로 묶는다.
이게 문자열의 나열에서도 문자를 나누는 방법이 된다.
t=int(input())
a=[list(map(str,list(input().rstrip()))) for _ in range(t)]4. 연산자
숫자, 문자, 함수, 객체, 리스트
문자는 반드시 따옴표
파이썬에는 상수라는 개념이 존재하지 않음
파이썬은 숫자 크기에 제한이 없음 하지만 float 타입은 소수점이 무한 반복되면 표시할 수 있는 수에 한계가 존재
사칙연산
- ☞ 더하기
- ☞ 빼기
- ☞ 곱하기
** ☞ 거듭제곱
/ ☞ 나누기
% ☞ 나머지 구하기
따옴표 세개 사용가능 """ '''이걸 사용하면 중간에 쌍따옴표와 단다옴표를 사용가능
파이썬에는 증감 연산자가 없음

https://ondemand.tistory.com/255
역시 파이썬은...
암튼 쓸거면 for문을 주로써야함
5. if 문,조건문
if 조건:
실행코드
elif 조건:
실행코드
else:
실행코드
비교연산자 <,<=,>,>=,==
6. 반복문,for문
for i in range(횟수 반드시 정수 이상, 미만,증가숫자):
반복할 코드
리스트 출력도 가능
for j in [내용1,내용2]
반복할 코드
그래서 일반적으로는 증가숫자가 1이기 때문에
for i in range(0,2): 로 사용하지만 값을 감소시키고 싶을 때는
for i in range(2,0,-1): 로 작성한다. (이하,초과)
혹은 for i in reversed(range(10)) 도 된다고 한다.
파이썬 반복문 인덱스 값 변경
파이썬은
for i in len(str):
i =10
으로 바꾸어도 i는 for문에서 계속 다음 값으로 초기화 된다. 이러한 문제를 해결하기 위해 다음과 같은 코드로 바꾸는 것이 좋다.
i=0
while i < len(s):
print(s[i])
if s[i] == 'a':
i+=1
i+=1출처: https://publivate.tistory.com/207
인덱스와 값을 함께 받아오기
for i,v in enumerate(d)7. 변수
파이썬에서 전역변수 사용하기
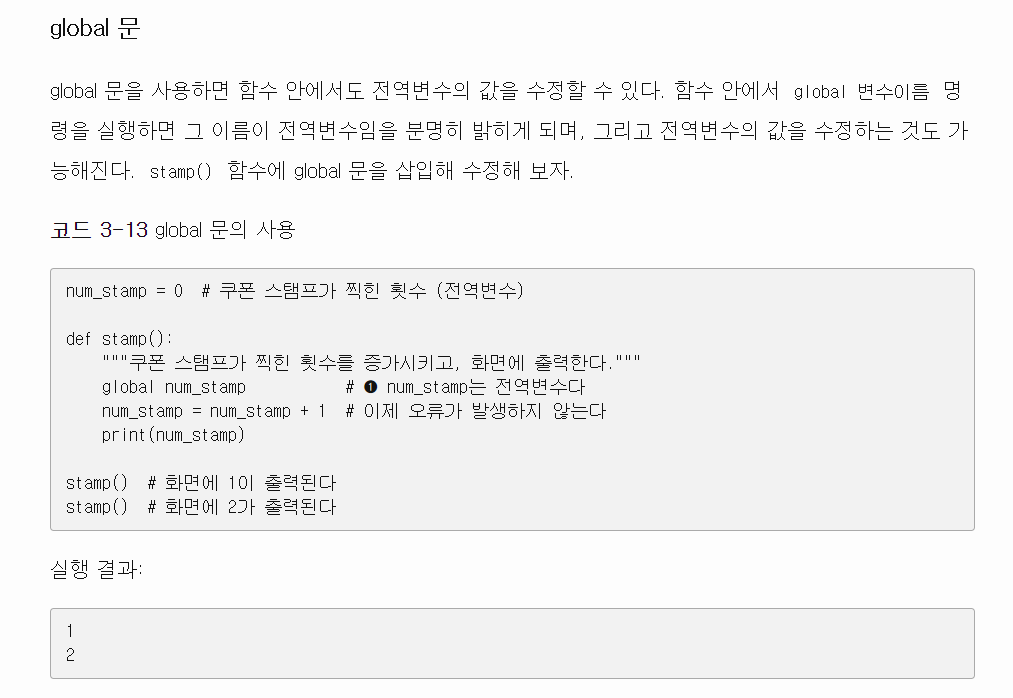
https://python.bakyeono.net/chapter-3-4.html
결론은 그냥 변수명만 쓰면 이게 전역인지 지역인지 알 수 없기 때문에 전역변수를 함수 내에서 사용하려면 global 문구가 필수 임
8. 함수
def 함수 이름(매개변수1, 매개변수 2=기본값 ...):
return 반환값특정 문자열을 기준으로 리스트를 나누어서 출력하기

https://ourcstory.tistory.com/46
결론은 .join을 사용하면 됨
문자 아스키 값 반환
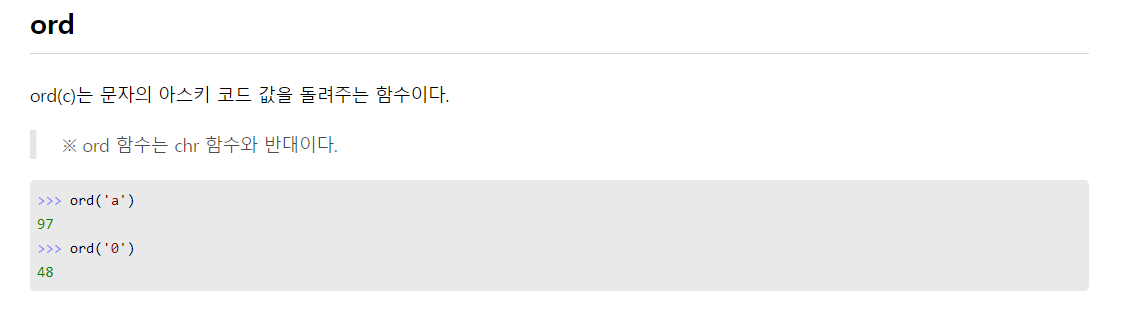
ord('A') #65 반환극한 값 구하기

https://codepractice.tistory.com/75
min/max 함수, 인덱스
min(list)
max(list)반대로 max 혹은 min 값의 인덱스를 찾기 위해서는 다음의 함수를 사용하면 된다.
list.index(max(list))
list.index(min(list))특정 행 또는 열만 사용하기
print(min(d[1][0:2])1행 0,1만 사용
math, sqrt
import math
math.sqrt(10)순열
from itertools import permutations
a=[1,2,3]
permutations(a)
permutations(a,2)순열문제는 가급적 C++로 풀기
우선순위 큐(힙)
import heapq
maxheap=[]
# 최소힙
heapq.heappush(maxheap,2)
# 최대힙
heapq.heappush(maxheap,2)
heapq.heappop(maxheap)
기존리스트를 heap으로 변경
heapq.heapify(maxheap)문제는 파이썬 heapq는 최소힙만을 지원해 주기 때문에 우리가 알아서 수정해 주어야 한다. 아직 문제가 많다.
9. 문자열
a="abcde"
a[2]
b="fghij"
a+b
a*2문자열 함수
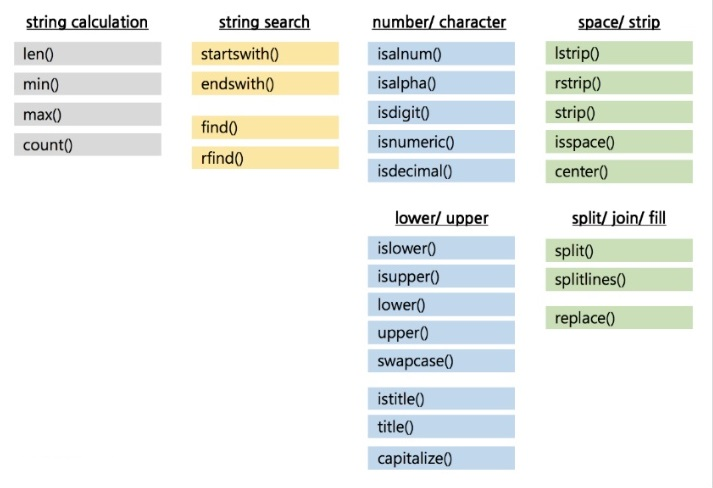
- len(리스트) : 문자열의 문자갯수 반환
- .count("특정문자") : 특정문자의 갯수 반환
- .upper()
- .lower()
- .split("특정문자") : 특정문자가 사라져서 그걸 기준으로 문자열을 나눔
10. 파일
파일 객체 = open(파일이름, 파일 열기 모드)그냥 "a.txt" 하면 현재 .py 파일이 있는 위치
모드

f=open("a.txt","w")
파일에 쓰기
f.write("2020-03-17 \n")
파일 닫기
f.close()
파일 읽기
f.read() -> 그냥 전체 다 읽음
f.readline() -> 각 줄을 나눠 리스트에 담고 리스트 반환11. 모듈(라이브러리)
모듈은 하나하나 연결해 어떤 목적을 가진 프로그램을 만드는 작은 프로그램
import 를 사용해서 모듈 가져오기
import random
num=random.randint(1,1000)모듈은 현재 디렉토리에 있거나 파이썬 라이브러리에 저장되어 있어야 함
단 모듈명을 파이썬의 내장 모듈과 같게 설정하면 안됨
이진탐색트리(BST)
안타깝게도 이진탐색트리, 이진트리는 외부 라이브러리라서 새로 설치해야 한다.
pip install bintrees
힙큐(heapq)
다행히도 파이썬에는 힙이 존재해서 사용 가능하다.
import heapq12. 예외처리
try:
except 예외 타입 as e: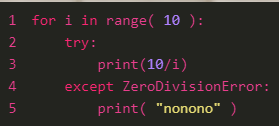


13. 클래스
클래스는 설계 도면
객체는 클래스로 만든 피조물
class Book(상속 클래스):
# 생성자
def __init__(self,title,author):
self.title=title
self.author=author
def outputAuthor(self):
print(self.author)
book1=Book(author="Victor",title="Res")
book1.outputAuthor()14. 웹 크롤링
from urllib.request import urlopen
import urllib.request
html=urlopen("주소")
doc=html.read().decode("UTF-8")15. 에러
리스트 join 사용시 TypeError: sequence item 0 뜰때 해결방법
이게 뜨는 이유가 join은 반드시 str 만을 매개변수로 사용하기 때문. 그렇기 때문에 리스트의 원소들을 모두 str로 바꾸어 주는 과정이 필요하다.
import sys
sys.stdin = open("input.txt","r")
input=sys.stdin.readline
t = int(input())
d = list(int(input()) for _ in range(t))
d.sort()
print("\n".join(map(str,d)))출처 : https://hyesun03.github.io/2017/04/08/python_int_join/
PS 속도조절
- 상수 는 가급적 뒤에 적는게 더 빠르다.
2133 타일채우기를 아래와 같이적은 것들간의 차이
t = int(input())
d=[0]*(t+1)
d[0]=1
for i in range(2,t+1,2):
d[i]=d[i-2]*3
for j in range(i-4,-1,-2):
d[i]+=d[j]*2
print(d[t])t = int(input())
d=[0]*(t+1)
d[0]=1
for i in range(2,t+1,2):
d[i]=3*d[i-2]
for j in range(i-4,-1,-2):
d[i]+=2*d[j]
print(d[t])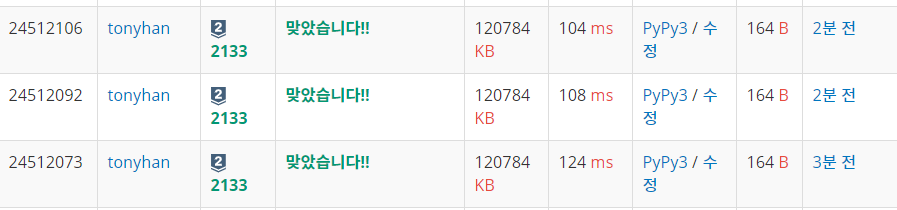
차이가 꽤 난다. 위쪽게 상대적으로 빠른것을 확인할 수 있었다.
참고자료

개꿀 포스트 감사합니다