=== Web and HTTP ===
웹서버와 통신이 가능하게 해주는 HTTP에 대해 다루어 보자
1. Web and HTTP
HTTP(hyper text transfer protocol)
우리가 웹브라우저를 이용해서 서버에 접속, 서버가 컨텐츠를 보여주는 서버가 웹서버라고 부른다. 이때 웹브라우저가 클라이언트이다. 통신할때 사용하는 프로토콜이 HTTP이다.
웹페이지는 objects(HTML file, JPEG image, Java app, audio file...)로 구성되어 있다.
web page는 base HTML file로 구성된다. HTML 파일 내에서 object 파일들이 reference 되어 있다.(영상, 파일 등등)
각 object는 URL(Uniform Resource Locator = web address)로 주소화가능하다.
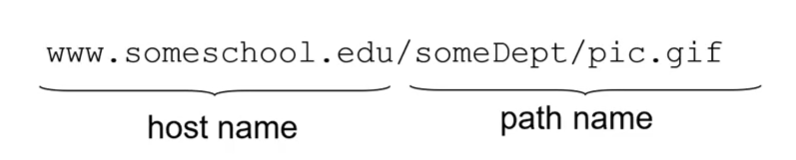
URL의 앞부분은 host name, 뒷부분은 path name이다.
URL의 앞부분은 host name, 뒷부분은 path name이다.
HTTP overview

HTML(Hyper Text Markup Language)인데 HTTP는 (Hyper Text Transfer Protocol)이다. 즉 HTML을 전송하는 프로토콜이다.
-
HTTP
- application layer protocol
- client/server model
- client : HOST, 웹 브라우저가 processor. 브라우저가 요청을 보내고 웹페이지 데이터를 받아서 화면에 출력하는 역활
- server : object들을 request를 받아서 response에 담아서 보내주는 역활
-
HTTP uses TCP
- TCP connection to server 을 만드어야 한다.
- The server accepts TCP connection from the client
- HTTP messages (application-layer protocol messages) exchanged
between browser (HTTP client) and web server (HTTP server) - TCP connection closed
-
HTTP is stateless
- server가 클라이언트에 대한 정보를 저장하고 있지 않는다.(관리의 어려움 때문, 쿠키는 제외)
- Stateful protocols vs. stateless protocol
- stateful protocols maintain past history (state) 다른 형태로(쿠키) state를 기억해야 한다.
- server/client 중 하나가 crash한 경우, their views of the "state" may be inconsistent and must be reconciled
HTTP는 (Hyper Text Transfer Protocol)
HTTP는 80번을 써서 TCP연결
HTTP는 stateless : client의 요청을 기억하지 않는다.
HTTP connections
-
non-persistent HTTP(TCP 연결하고 단 하나의 object만 전송 v1.0)
- at most one object sent over TCP connection
- connection then closed
- downloading multiple objects requires multiple connections
-
persistent HTTP(한번 연결되면 여러개의 object 전송가능 v1.1)
- multiple objects can be sent over a single TCP connection between client and server
- modern web browsers use persistent HTTP connection(모든 웹 브라우저가 사용)
1.0 : non-persistent : TCP 연결하고 단 하나의 object만 전송.
1.1 : persistent HTTP : 한번 연결되면 여러개의 object 전송가능
Non-persistent HTTP

1a : client가 server와 HTTP connection을 맺을려고 함, 포트 80
1b : server는 80번 포트로 TCP 연결을 대기중, accept connection
(handshake)
2 : HTTP client는 request message를 보낸다.
3 : HTTP server는 request message를 받는다. response message를 만든다. 있는 경우 requested object를 넣어서 보내준다.

4 : TCP connection을 끊는다.
5 : HTTP client는 response를 받는다. 그런데 그 내부에 jpeg 가 또 있는 경우가 있다.
6 : 그 경우 jpeg 이미지 모두를 연결하고 끊고를 반복한다.
Non-persistent HTTP: response time
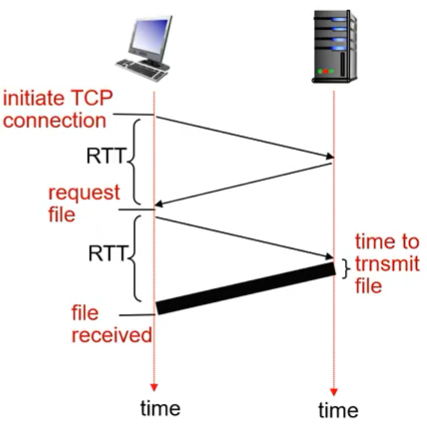
- RTT(round-trip time) : 패킷을 서버에 주고 받은 시간
- HTTP response time
- 연결할때 RTT 한 번
- 데이터를 요청할때 RTT 한 번
- 파일 크기에 따른 file transmission time
- HTTP response time = 2 x RTT + file transmission time
(중요)
RTT(round-trip time) : 패킷을 서버에 주고 받은 시간
HTTP response time = 2 X RTT + file transmission time
Persistent HTTP
non-persistent HTTP는 2RTT가 계속 필요하다. referenced objects들도 또 가지고 와야 한다.
- persistent HTTP
- 서버와의 연결을 유지한다.
- 차후 HTTP message의 전송은 같은 열려있는 connection을 가지고 진행한다.
- HTML 내부의 reference들도 바로 요청할 수 있다.
- 추가적인 자료는 하나의 connection으로 필요한 object를 서버로부터 병렬로 받아올 수 있다.
HTTP request message
request, response 두가지의 메세지가 존재한다.
메세지는 ASCII로 되어 있다. 그래서 사람이 읽을 수 있다.
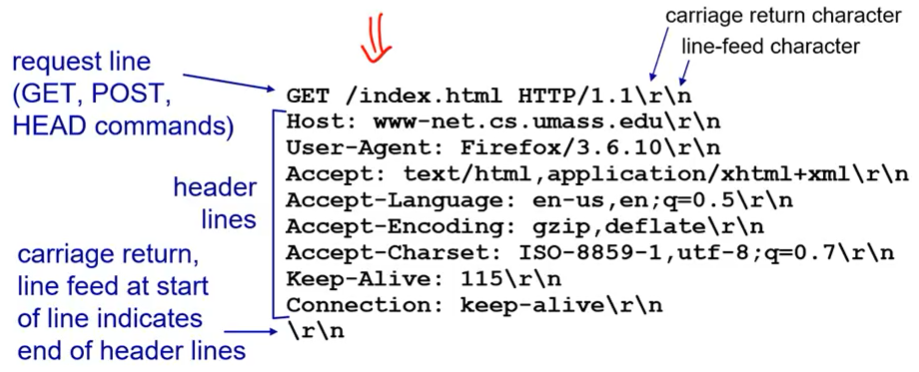
HTTP request message: general format
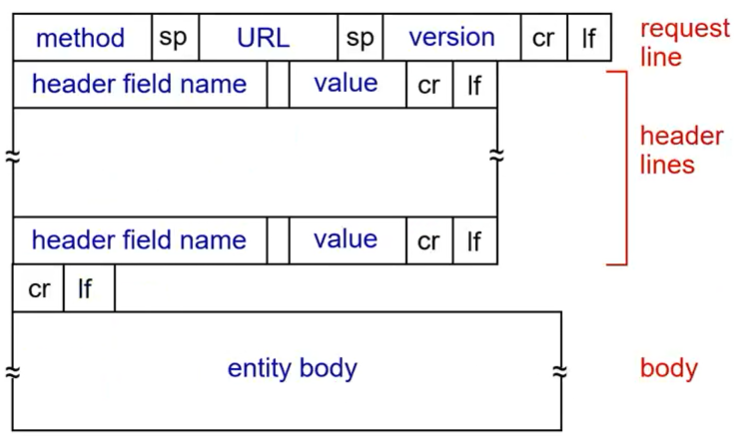
이걸 반드시 외울필요는 없다. 대신에 이렇게 구성된다는 것을 이해하고 있어야 한다.
method는 GET이고
URL은 TCP connection을 맺을때 이미 있었다. 그렇다면 Host name은 왜 있는가? 이것은 나중에 웹 proxy를 할때 필요하기 때문에 존재한다.
version HTTP/1.1
Uploading form input
GET과 POST 방식이 존재한다.
-
POST method
- web page often includes form input
- input is uploaded to server in entity body

-
URL method
- uses GET method
- input is uploaded in URL field of request line

뒷 부분은 client가 server 쪽으로 주는 값이다.
2. HTTP request message: GET vs POST
HTTP POST 는 client가 input으로 주는게 message body에 들어감
HTTP GET 은 URL에 들어가게 된다.
HTML의 form 태그 안에 사용하게 되고 method="POST", method="GET"으로 나뉘어진다.
GET vs POST
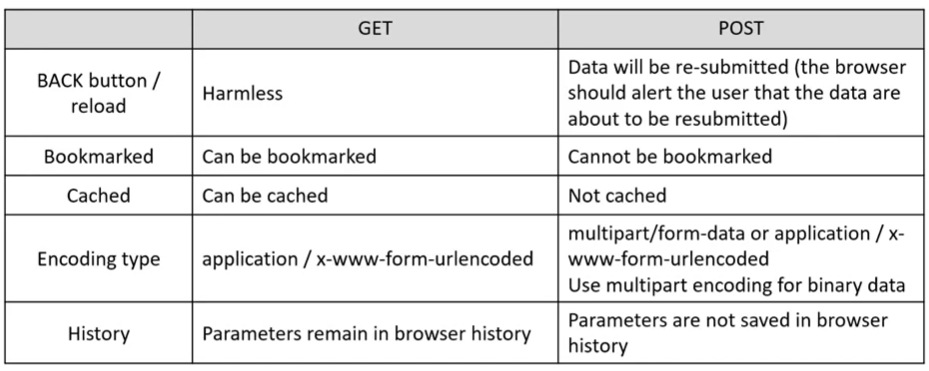
BACK Button으로 앞뒤로 이동시 GET은 문제가 없지만 POST는 두 번 전송하게 된다. 그래서 웹브라우저에서 다시 submit되었다는 것을 알려주는 방식으로 이를 방지한다.
어떤 URL을 Bookmarked할 경우 GET은 URL을 저장할 수 있지만 POST는 불가능하다.
GET은 cached될 수 있다.(로컬이나 서버에 일부 데이터를 저장) POST는 저장할 수 없다.
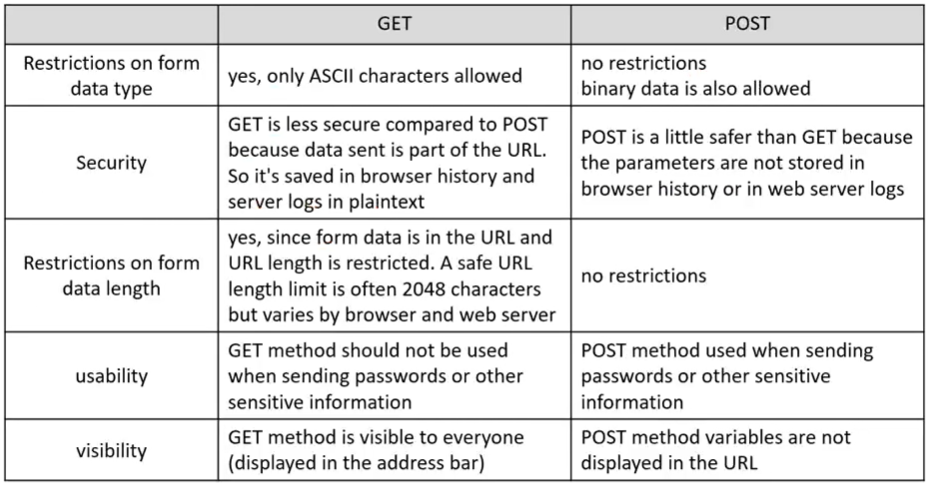
form data type은 GET의 경우 ASCII만 가능하다. 하지만 POST 방식은 binary data만 가능하다.
Security방식에 GET보다 POST가 보다 안정적이다. POST는 로그도 보이지 않고 내용이 URL에 보이지도 않아 보다 안전하다.
usability에서 GET은 sensitive information이나 password에 사용하면 안된다. 대신에 POST 방식을 사용해야 한다.
Method types

HEAD는 GET과 비슷한데 response는 오는데 그 object는 오지 않는 방식이다. 테스트용이다.
PUT은 파일 업로드시 사용
DELETE는 어떤 URL을 삭제할때 사용하는 것이다.
1.0 : GET, POST, HEAD
1.1 : GET, POST, HEAD + PUT, DELETE
HTTP response message

status라인에 버전 / status code(중요) / 메세지 내용
그 아래로 데이터에 대한 정보가 기록되어 있다.
Date는 보낸시간이고
Last-Modified는 마지막으로 바뀐 시간을 이야기 한다. 이건 캐쉬때문에 사용한다. 만약에 이미 html 파일을 받은 기록이 있다면 구지 새로운 html을 받을 필요가 없기 때문이다.
Content-Length : 데이터의 길이
HTTP response status codes

404 Not Found는 그냥 띄어주는데 200은 Object를 보여준다.
400은 request를 서버가 알아듣지 못한 경우
505은 HTTP 페이지 버전이 서버랑 다른경우
Trying out HTTP (client side) for yourself
서버에 직접 요청하고 결과를 받는 부분

telnet : 어떤 서버로 TCP connection을 맺고 유저가 무슨 메세지든지 typing 해서 보내게 해주는 프로그램. TCP 서버에 연결을 맺고 메세지를 보낼 수 있다.
3. User-server state: cookies
사용자의 정보를 기록하는게 필요한 경우
- Cookie can be used for recording user's activity such as
- log in
- shopping cart
- game score
- user configuration, themes
- pages visited by the user
등등의 서비스가 필요할 것이다.
Cookie는 유저의 작은 데이터로 client쪽에 우선적으로 저장된다.
(요약)
쿠키 구성요소
1.HTTP 응답 메세지에 쿠키 헤더라인이 존재
2. HTTP 그 다음 보내는 메세지에 쿠키 헤더라인 존재
3. 유저의 호스트 브라우저에 의해 쿠키파일이 저장
4. 백엔드 데이터베이스가 존재
HTTP가 이 방식을 support하지 반드시 하는것이 아니다.
작동원리
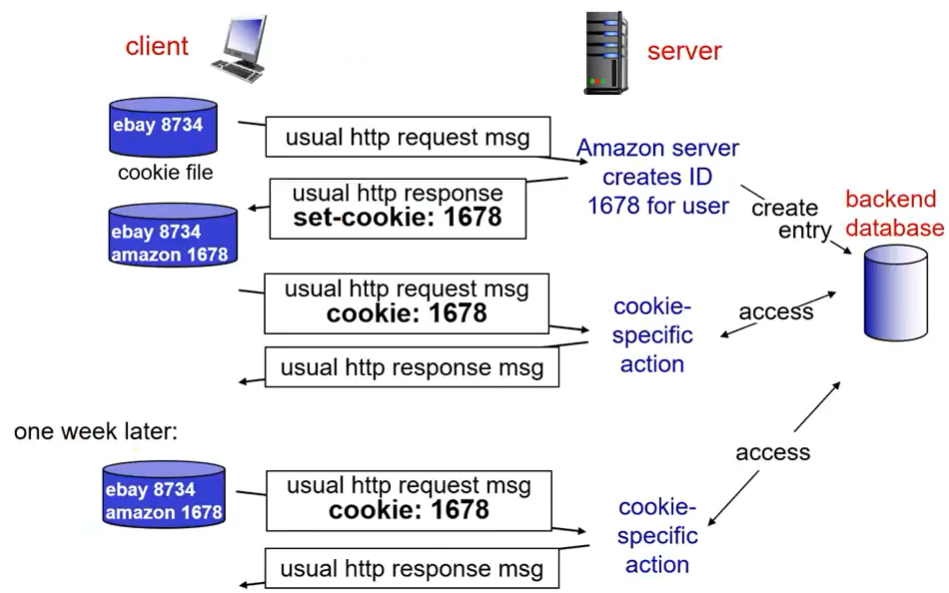
client가 server에 접속했다고 하자 이때 접속한 user을 위해 ID를 만든다. http response의 부분중에서 set-cookie 부분에 id, string을 보내준다. 또한 자기쪽 서버 database에 저장한다.
그 다음에 웹브라우저가 재 접속시 cookie의 정보를 포함해서 전달한다. 그러면 database에 해당 정보가 있는지 확인해서 특정활동들을 수행한다.
시간이 지나서 재접속할때에도 쿠키의 정보를 가지고 database에 접속한다.
(요약)
방법론
1. 처음 요청 메세지 보내기
2. ID를 만들어 backend에 보낸다.
3. http response에 set-cookie 부분이 보내진다.
4. client에서 쿠키정보 저장
5. 이제 쿠키의 정보를 담아서 서버에 전달
쿠키의 장점
1. 인증/쇼핑카트/추천/유저 세션
Web caches (proxy server)

web cache 혹은 proxy server 라고 하는 것은 진짜 데이터를 제공하는 서버를 origin server라고 하는데 client와 origin server 사이에 있는 서버이다. 자주 가지고 오는 내용은 프록시 서버에 놔두어서 속도 향상을 이루는 것이다.
브라우저가 proxy server을 쓸려면 셋팅이 되어 있어야 한다. 어떤 서버로 브라우저가 request를 보낼때 우선 proxy server로 보내는데 만약에 object가 있으면 바로 보내주지만 없다면 origin server로 request를 보낸다. 그리고 이때 보낸 내용을 cache에 저장한다.
(요약)
웹캐시/프록시를 사용하겠다고 하면 client는 반드시 프록시 서버로 데이터를 보낸다.
More about web caching
cache는 client, server 다 된다.
web cache는 ISP(대학교, 회사, 아파트 단지)를 가지고 있다.
클라이언트 입장에서는 빠르게 데이터를 가지고 올 수 있다.
기관의 access link는 항상 데이터를 주고 받기 때문에 bottleneck이 걸릴 수 밖에 없다. web cache를 사용하면 access link를 사용하지 않기 때문에 traffic을 줄일 수 잇다.
(요약)
web cache는 ISP에 의해서 인스톨된다.
Web Caching: Example
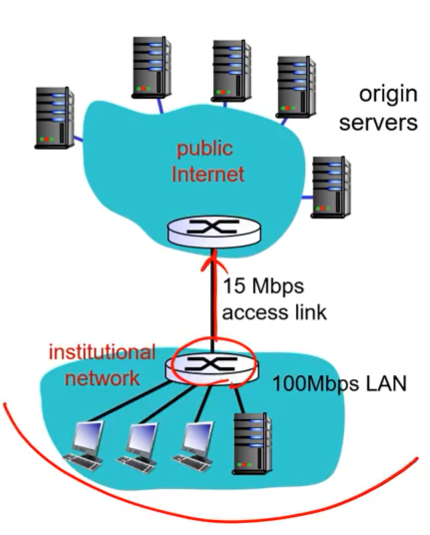
-
Assumptions
– avg object size: 1Mbits
– avg request rate from browsers to
origin servers: 15/sec
– time taken to fetch data from
origin server to the router on the
Internet side of access link: 2 sec
– delay inside access link: 0.01 sec
– access link rate: 15Mbps -
Consequences
– LAN utilization: 15%
– access link utilization: 100%
– delay becomes very large
(congestion at access link)
institutional network에서의 delay는 0.01sec이고
queueing delay가 100%이기 때문에 데이터를 주고 받는데 오랜시간이 걸린다.
(시험)
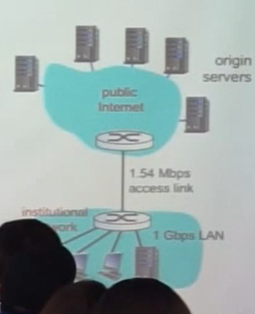
-
Assumptions
– avg object size: 100K bits
– avg request rate from browsers to origin servers: 15/sec
= avg data rate to browsers: 1.50 Mbps
– RTT from institutional router to any origin server: 2 sec
– access link rate: 1.54 Mbps -
Consequences
– LAN utilization: 15%
– access link utilization: 99%
– total delay = Internet delay + access delay + LAN delay = 2sec + minutes + usecs
Web Caching: Fasteer Access Link
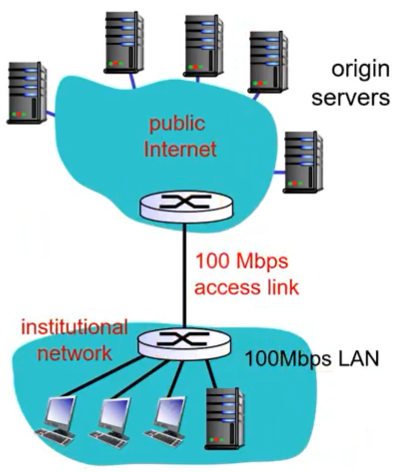
해결책
1. access link의 회선을 100Mbps로 늘리는 방법
- access link utilization: 15%
- delay roughly 2 seconds
대신에 비용이 많이 든다.
Web Caching: Install Local Web Cache
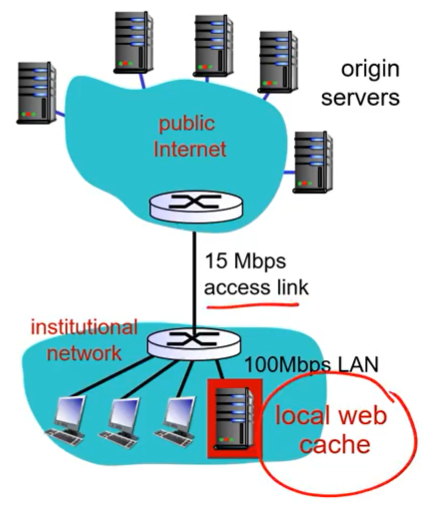
해결책
1. local web cache를 설치한다.
대신 조건은 40%는 이미 local에 있는 데이터야 한다.
그러면 60%만 origin server에 갔다온다.
- 60% of requests takes 2.01 seconds
- average: 1.2 seconds
(요약)
웹 캐시를 두고 다시 계산하는 것이다.
web cache의 hit rate가 가장 중요한 성분이다.
이게 강해지면 비용이 감소
Conditional GET
웹 캐시로부터 데이터를 가져오는 경우 생긴는 문제
- 자주 바뀌는 값에 대해서 대처할 수 없다.
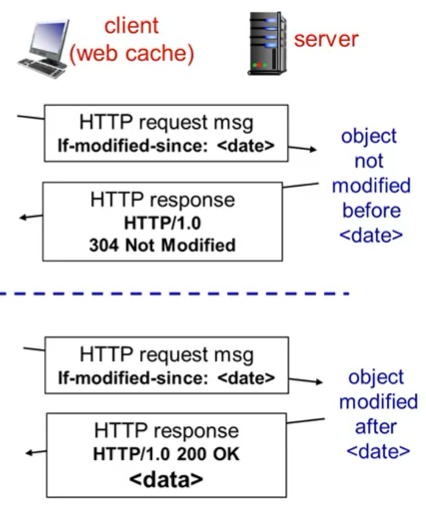
이것을 해결하기 위한 방법
Conditional GET은 Request msg는 GET인데 option에 if-modified-since가 있다. 내가 어떤 data를 받은 날짜가 있었다. 그래서 메세지에 date를 추가한다. 그리고 만약에 date가 바뀌었다면 origin server로 부터 object를 받게 된다.
만약 바뀌지 않았다면 304 NOT modified를 반환해준다. 반대로 바뀐경우에는 200 OK와 새로운 data를 받게 된다.
(요약)
conditional GET은 web cache를 처리하기 위한 방식이다.
만약 바뀌지 않았다면 304 NOT modified를 반환해준다. 반대로 바뀐경우에는 200 OK와 새로운 data를 받게 된다.
