=== Packet Processing ===
라우터가 하는 또 다른 일이 scheduling이라는 일이 존재한다.
1. Scheduling
다양한 트래픽이 들어올때 라우터가 이걸 어떻게 처리할 것인가. 들어오는 순서대로 처리해야 하는가를 결정하는 것이 Scheduling이라고 부를 수 있다.
• deciding the order of packet processing : 패킷을 처리하는 순서를 결정하겠다.
• FIFO (First-In First-Out) queue: basic type : 먼저들어오는 것을 먼저처리하겠다는 기본적인 라우터방식
– packet arrived first is processed (and sent out) first
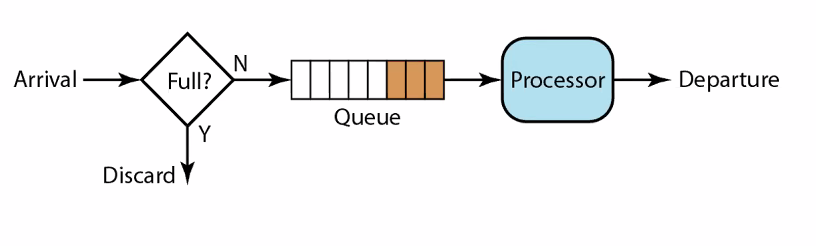
라우터 내에 queue를 하나두어서 무엇을 처리하든 queue의 앞에 들어오게 되고 프로세서가 라우팅 테이블을 보고 패킷 헤드의 dest를 보고서는 내보내게 된다.
• FIFO queue
– flows are not distinguished : 트래픽이 어느소속인지 구분이 안된다. 보다 빨리 보내주거나 real-time traffic과 같은 경우는 처리해줄 수 없다.
– no congestion control : 처리속도조절을 안해준다.
– if queue is full, the last packet is dropped (tail drop) : 큐가 full이면 패킷이 드랍된다. 누구를 드랍하는 것을 결정하는 것은 꽉찬상태에서 새로 들어온 패킷을 버린다.
– fair in terms of delay : 어느 traffic에 속한 패킷이던간에 평등하게 대한다.
– bandwidth is not considered : 처리량은 고려안한다.
-
FIFO queue: problem
- If a flow sends more packets, the flow is served more : 더 많은 flow를 보내는 쪽이 더 많은 서비스를 받게 된다.
- promotes selfish behavior : 빨리 전송을 원하면 더 많은 패킷을 라우터로 보내는 등의 문제점이 생길 수 있다.
- can be used as attack
- Packets may need different types of QoS(Quality of Service), but cannot be implemented in FIFO queue : 서로 다른 서비스에 대해서 QoS를 맞추어주지 못할 수 있다.(물론 반드시 네트워크 레이어에서 이걸 할 이유는 없다.)
- If a flow sends more packets, the flow is served more : 더 많은 flow를 보내는 쪽이 더 많은 서비스를 받게 된다.
-
Priority Queue
- Process packet depending on priority
- Even if a packet arrived late, it is processed first if it has the highest priorityIntroduction to Computer Networks
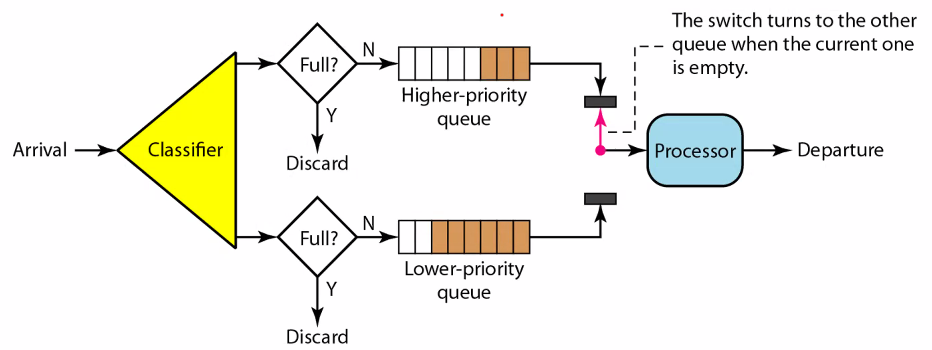
Classifier가 low인지 high인지 결정해준다. 그러면 기본적으로 되는 것은 한 쪽이 꽉차더라도 나머지 큐는 있기 때문에 계속 서비스가 유지될 수 있다.
- Even if a packet arrived late, it is processed first if it has the highest priorityIntroduction to Computer Networks
- Process packet depending on priority
-
Priority Queue: problem
- low-priority flow can be starved : higher priority를 계속 처리하다보니 low-priority는 계속 대기하고 있는 문제점이 생길 수 있다.
- cannot send packets for long time (starvation)
- cannot send packets for long time (starvation)
- low-priority flow can be starved : higher priority를 계속 처리하다보니 low-priority는 계속 대기하고 있는 문제점이 생길 수 있다.
• Round Robin
flow마다 큐를 제공해주는 방법 : src ip/dest ip를 가지고 flow를 결정할 수 있다. 그것에 따라 flow를 묶어준다. 그리고 queue를 flow 하나마다 생성해서 만들어준다.
– A queue exists for each flow
– Takes turns to go around each queue and process one packet per each queue
– Compared with FIFO, a flow does not receive more service by sending more packets : 한 flow에서 더 많은 패킷을 보낸다고 더 많은 서비스를 받지 않게된다.
– Flows sending large packets gets more serviceIntroduction to Computer Networks
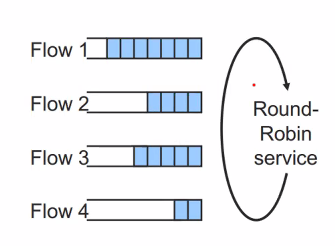
round-robin 으로 한 플로우를 한 스케쥴에 처리해준다. 만약에 비어있는 큐라면 바로 다른 스케쥴로 넘어간다.
- Fair queuing
flow별로 패킷의 크기가 다른경우- A queue exists for each flow
- Schedule packets so that the flows are given fair service
- Scheduling has to be fair even if packet sizes are different
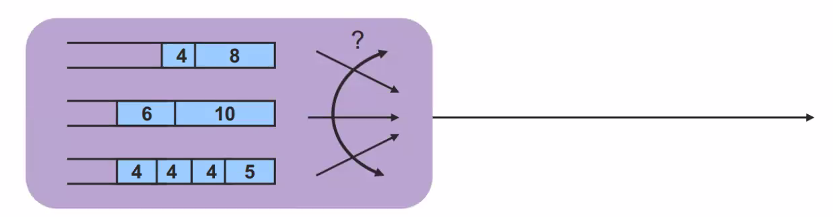
그 동안에 서비스를 많이 받은 얘는 뒤로 가고 적게 받은 얘들을 우선처리한다.
- Scheduling has to be fair even if packet sizes are different
- Fair queuing with variable packet length: algorithm
- Si = amount of data flow i has sent
- process flow with minimum Si, if it has packets to process
- Update Si after processing packet
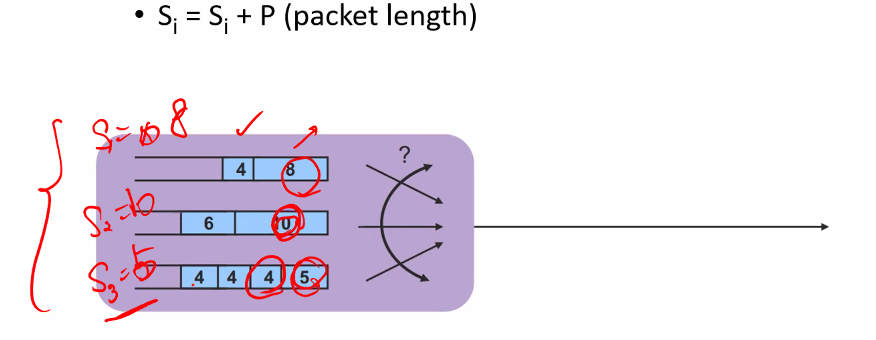
• Fair queuing: problem
– If a flow does not have data for long time and come back : 어떤 flow에 한참동안 패킷이 없다가 오게되는 경우
– The flow will have a very small Si -> will receive service alone for a long time : 한 flow가 너무 늦게와서 다른 flow의 Si값이 과하게 차있는 경우.
• Solution
– “use it or lose it”
– Smin = min(Si such that queue i is not empty)
– If queue j is empty, set Sj = Smin
오랬동안 비어있던 flow는 다른 계속 차는 flow중에서 최소값의 flow값으로 저장해준다.
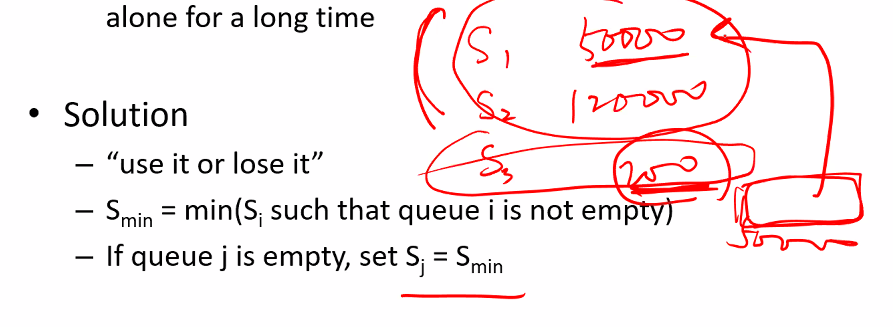
그런데 이보다 큰 문제는 이 모든것을 network layer에서 처리해주어야 한다는 점이다.
- Weighted Fair Queuing
- Similar to fair queuing, but flows have different priorities : flow마다 가중치를 주는 방법
- Each flow has a weight, wi: weight of flow i
- Si is computed in the following way
- Si = Si + P / wi

- Si = Si + P / wi
• Weighted Fair Queuing
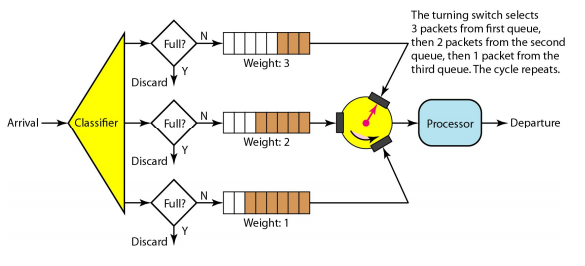
-
Weighted fair queuing: pros
- fair scheduling based on flow priorities
- avoid starvation : starving을 피할 수 있다.
-
Weighted fair queuing: cons
- complex state
- a queue for each flow
- complex computation
- low separation
- packet sorting
- processing when a flow is added or removed
- complex state
scheduling : example
- S값이 같은 경우의 우선순위: A>B>C
- 모든 flow의 weight가 같은 경우, 패킷 처리 순서는?
- WA = 4, WB = 1, WC = 2일때 패킷 처리 순서는?
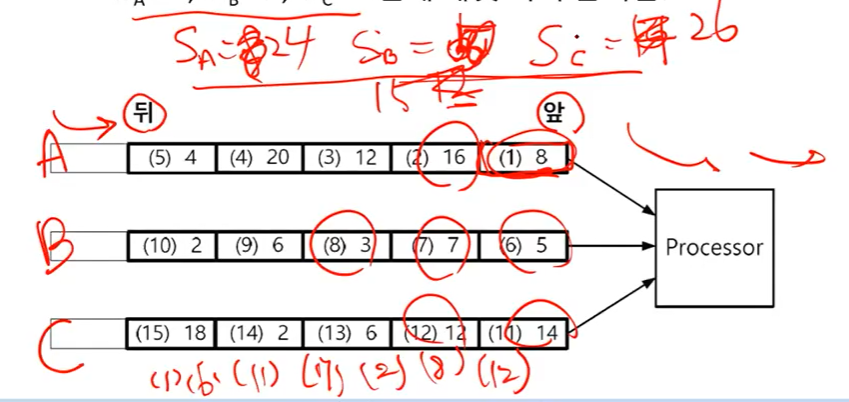
-
flow의 weight가 같은 경우
(1)8 -> (6)5 -> (11) 14 -> (7) 7 -> (2) 16 -> (8) 3 -> (12)12 -> ... -
flow의 weight가 다른 경우
(1) -> (6) -> (11) 여기까지는 S가 같기 때문에 우선순위대로 전송
-> (2) -> (7) -> (3) -> ...
Traffic Shaping
• A method to control amount of data the source sends to the network
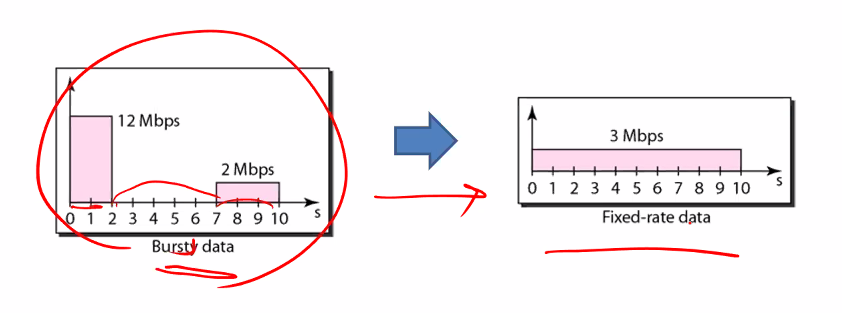
들어오는 것은 패턴이 있지만 나가는 것을 일정하게 하면 Bursty data를 조금 해결할 수 있지 않을까
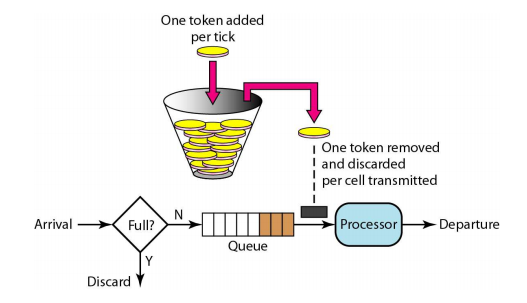
• Token bucket filter
– Token is accumulated in a bucket
• If the bucket is full, token is no longer accumulated
– When the sender sends data traffic, it also consumes tokens from the bucket
– The sender does not send traffic is there is no token in the bucket
• Token bucket
계속 패킷을 처리하면 토큰이 빈다. 그렇지 않으면 한계치까지 버킷이 차오른다. 그래서 토큰이 차오르는 속도로 패킷을 처리하는 방법이다.
- Traffic characterization
- Token rate: r
- Bucket depth: B
- Use
- 1 token is needed to send 1 byte
- for n bytes, n tokens needed
- Initially, no token is in the bucket : 초기에 버킷이 찼는지 안찼는지를 결정할 수 있다.
- r tokens are accumulated in one seconds
- number of tokens cannot exceed B
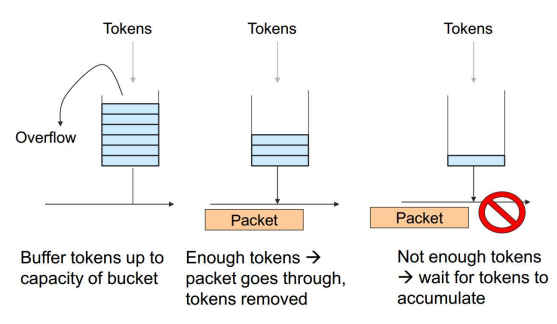
토큰 차는 속도에 맞추어서 데이터를 보내게 된다.
- 1 token is needed to send 1 byte
Token Bucket
• Look at the trace of input traffic, and find the minimum bucket size so that the traffic is not delayed
Token Bucket: exercise
-
We want to find the minimum bucket size so that traffic is not delayed
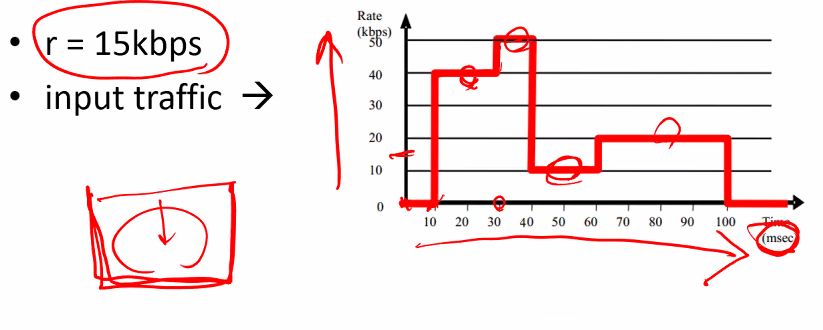
토큰이 15kbps로 차오른다. -
What is the minimum bucket size (B)?
그래서 토큰이 바닥나는 일이 생기지 않게 하려면 bucket size를 얼마로 맞추어야 할까?
• r = 15kbps
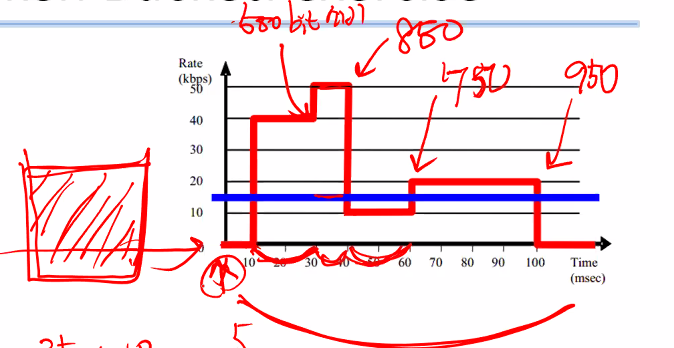
• min B = (40 – 15) * 20 + (50 – 15) * 10 – (15 – 10) * 20 + (20 – 15) * 40 = 950 bits = 500bit + 350 bit + (-100) + 200
즉 토큰 버킷을 950 bit이상으로 만들면 버킷이 비는 일이 생기지 않을 것이다.
• Start from the left, and find the maximum data that is can be accumulated in the buffer
Token Bucket: exercise
• what is the minimum B when
– r = 55kbps?
– r = 45kbps?
– r = 35kbps?
– r = 25kbps?
– r = 5kbps?
토큰이 쌓이는 속도가 달라지면 어떻게 되는가? minB가 어떻게 달라지는가를 보는 것이다. 여기에서 주의할점이 두가지 인데 중간에 토큰이 완전히 찰 수가 있다. 그러면 트래픽이 없어도 더 차지 않는다.
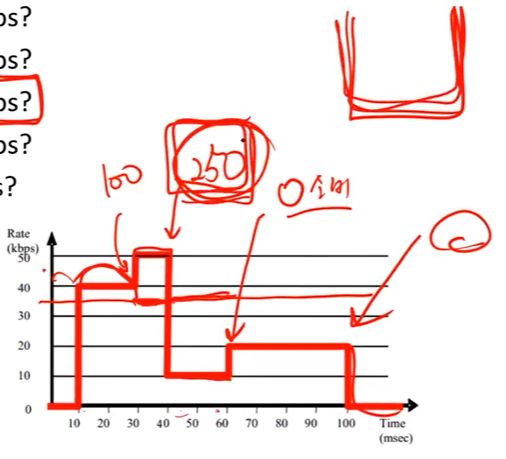
예를 들어 35kbps로 속도를 맞춘다면 가장 높은 시점에 250bits가 될것이다. 바로 이 시점을 기준으로 bucket size를 잡으면 된다.
25kbps로 한다면 최대가 되는 순간은 550bit일 것이다.
