System-Level I/O
Today
¢ Unix I/O
¢ RIO (robust I/O) package
¢ Metadata, sharing, and redirection
¢ Standard I/O
¢ Closing remarks
=== Unix I/O Overview ===
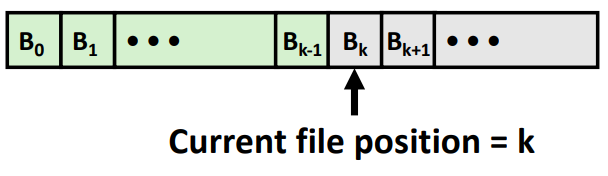
- A Linux file is a sequence of m bytes:
- B0 , B1 , .... , Bk , .... , B(m-1)
리눅스에서 파일이라는 것은 m byte의 연속이다.(chunk) 하드 혹은 디스크에 저장된다. chunk들은 fixed size로 쭉 연결이 되어 있는 sequence이다.
HDD는 sector 단위로 512B(0.5kb)
- Cool fact: All I/O devices are represented as files:
- /dev/sda2 (/usr disk partition)
- /dev/tty2 (terminal)
유닉스에서는 모든 device들이 file로 저장된다.
커널도 파일로 표현된다.
- Even the kernel is represented as a file:
- /boot/vmlinuz-3.13.0-55-generic (kernel image)
- /proc (kernel data structures)
kernel image도 파일로 표현된다.
proc은 커널안의 여러가지 자료구조를 볼 수 있고 설정할 수도 있는 인터페이스를 제공한다.
I/O는 터미널, 네트워크, 외부장치에서 데이터를 복제하는 과정을 input/output 이라고 부른다.
input이라고 하면 main memory까지 데이터가 오는 것을 이야기 한다.
output은 main memory의 데이터를 외부장치로 가는 것을 이야기 한다.
일반적으로 대부분의 언어들이 input,output을 수행하기 위한 라이브러리 제공
유닉스는 시스템 레벨 유닉스 I/O함수들을 이용해서(커널에서 제공하는 함수들) high level로 구현
- Elegant mapping of files to devices allows kernel to export simple interface called Unix I/O:
- Opening and closing files
- open()and close()
- Reading and writing a file
- read() and write()
- Changing the current file position (seek)
- indicates next offset into file to read or write
- lseek()
- Opening and closing files
파일들을 디바이스로 매핑하면서 결국 커널이 Unix I/O라고 불리는 간단한 인터페이스를 보여줄 수 있게 된다.
lseek은 파일을 열개되면 파일의 position은 0번째인데 k번째 위치로 변경을 할 수 있게 해준다.
1. File Types
- Each file has a type indicating its role in the system
- Regular file: Contains arbitrary data
- Directory: Index for a related group of files
- Socket: For communicating with a process on another machine
- Other file types beyond our scope
- Named pipes (FIFOs)
- Symbolic links
- Character and block devices
Regular file은 일반적인 데이터를 가지고 있는 파일들
directory : 각각의 파일들에 대한 포인터 값(파일들의 id번호)
Socket : 프로세스들이 다른 기계들과 통신할때 사용
Named piped, symbolic links, character and block devices등등 다 파일이다.
Regular Files
- A regular file contains arbitrary data
- Applications often distinguish between text files and binary files
- Text files are regular files with only ASCII or Unicode characters
- Binary files are everything else
- e.g., object files, JPEG images
- Kernel doesn’t know the difference!
regular file에는 text, binary file이 존재한다.
text file은 ASCII, Unicode
Binary는 거의 모든 것
커널은 별로 신경안씀
- Text file is sequence of text lines
- Text line is sequence of chars terminated by newline char (‘\n’)
- Newline is 0xa, same as ASCII line feed character (LF)
Text file의 각줄은 \n으로 되어 있다.
- Text line is sequence of chars terminated by newline char (‘\n’)
- End of line (EOL) indicators in other systems
- Linux and Mac OS: ‘\n’ (0xa)
- line feed (LF)
- Windows and Internet protocols: ‘\r\n’ (0xd 0xa)
- Carriage return (CR) followed by line feed (LF)
- Linux and Mac OS: ‘\n’ (0xa)
EOL은 \n으로 되어 있고 window, internet에서는 CRLF를 사용한다.
Directories
-
Directory consists of an array of links
- Each link maps a filename to a file
디렉토리는 파일들의 링크들에 대한 배열
- Each link maps a filename to a file
-
Each directory contains at least two entries
- . (dot) is a link to itself
- .. (dot dot) is a link to the parent directory in the directory hierarchy (next slide)
각 디렉토리는 자기자신과 부모 디렉토리를 포함하고 있다.
-
Commands for manipulating directories
- mkdir: create empty directory
- ls: view directory contents
- rmdir: delete empty directory
Directory Hierarchy
- All files are organized as a hierarchy anchored by root directory named / (slash)
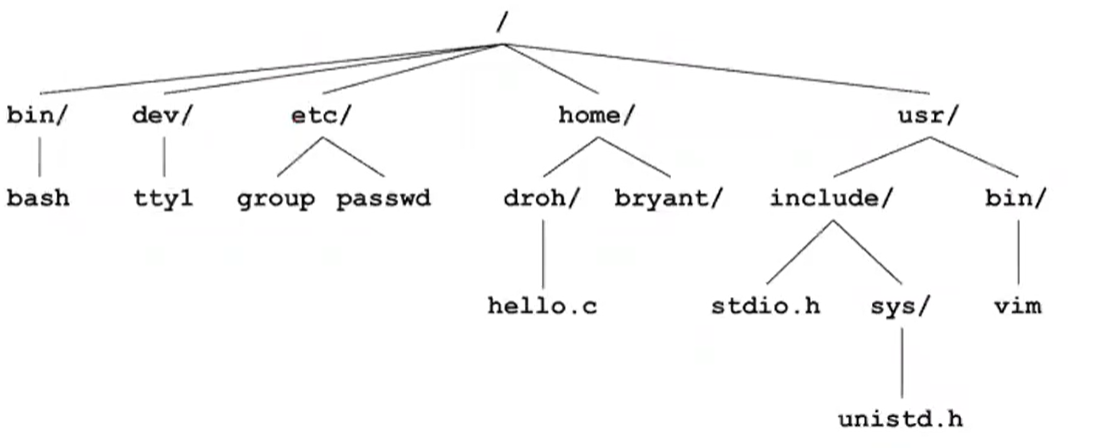
각 디렉토리는 루트부터 해서 쭉 이어져있다.
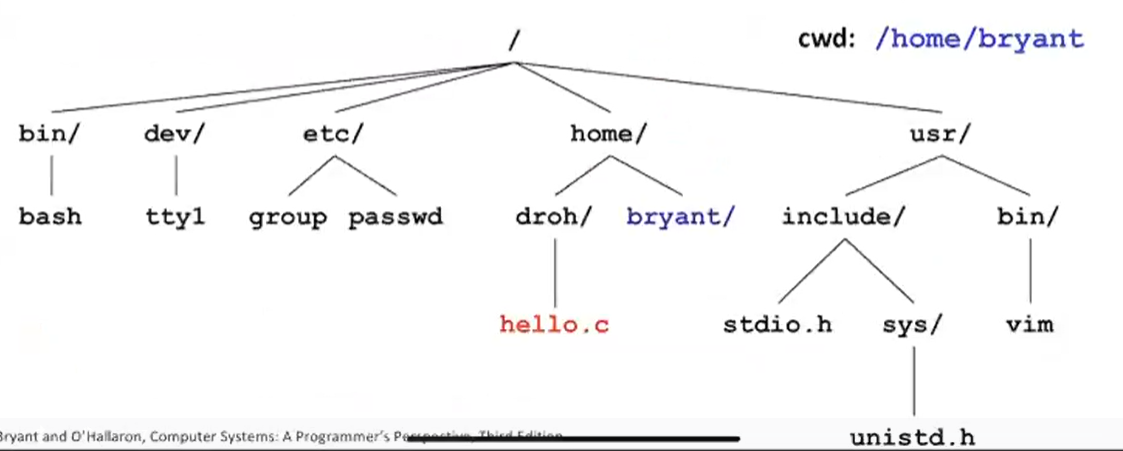
- Kernel maintains current working directory (cwd) for each process
- Modified using the cd command
커널은 각 프로세스마다 현재 디렉토리가 무엇인지 가지고 있다.
Pathnames
- Locations of files in the hierarchy denoted by pathnames
- Absolute pathname starts with ‘/’ and denotes path from root
- /home/droh/hello.c
절대경로는 위와 같이 root에서 시작해서 경로를 말한다.
- /home/droh/hello.c
- Relative pathname denotes path from current working directory
- ../home/droh/hello.c
상대경로는 현재 위치를 기준으로 시작한다.
- ../home/droh/hello.c
- Absolute pathname starts with ‘/’ and denotes path from root
2. Opening Files
- Opening a file informs the kernel that you are getting
ready to access that file
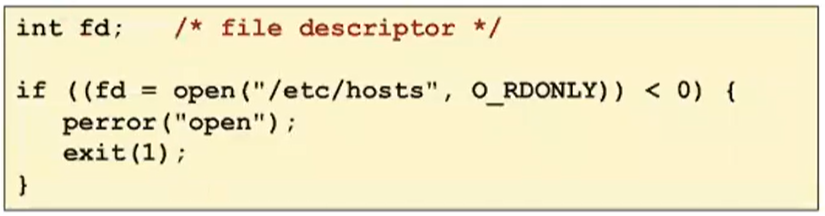
지금부터 파일에 access할거라고 커널에 알려주는 것을 이야기 한다.
위의 코드에서는 절대경로, readonly 모드로 열었다.
- Returns a small identifying integer file descriptor
- fd == -1 indicates that an error occurred
- Each process created by a Linux shell begins life with three open files associated with a terminal:
- 0: standard input (stdin)
- 1: standard output (stdout)
- 2: standard error (stderr)
0, 1, 2으로 서로 다른역활로 파일이 열린다
Closing Files
-
Closing a file informs the kernel that you are finished accessing that file

-
Closing an already closed file is a recipe for disaster in threaded programs (more on this later)
-
Moral: Always check return codes, even for seemingly benign functions such as close()
파일이 닫히고 또 닫으면 문제가 생길 수 있다.
Reading Files
- Reading a file copies bytes from the current file position to memory, and then updates file position
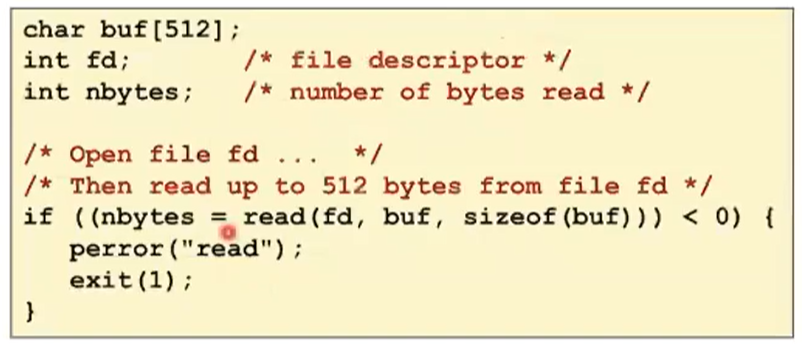
파일 읽어서 저장을 하고 읽는 위치를 업데이트 한다.
잘 읽었으면 버퍼사이즈보다 작거나 같은 값이 반환되고 그 외는 음수가 반환된다.
- Returns number of bytes read from file fd into buf
- Return type ssize_t is signed integer
- nbytes < 0 indicates that an error occurred
- Short counts (nbytes < sizeof(buf) ) are possible and are not errors!
읽고자 하는 데이터보다 작은 경우는 Short count가 반환된다.
Writing Files
-
Writing a file copies bytes from memory to the current file position, and then updates current file position
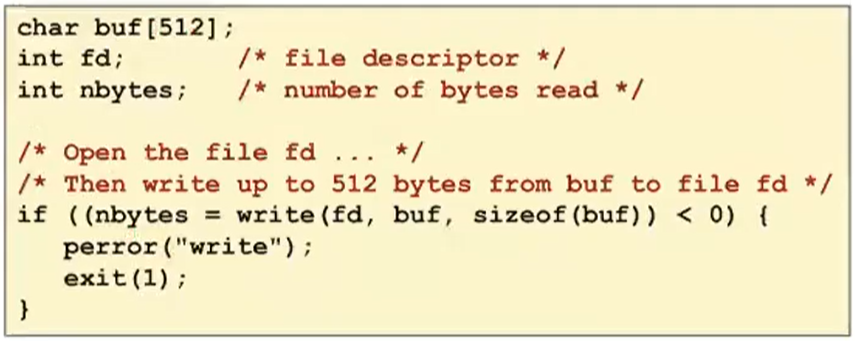
-
Returns number of bytes written from buf to file fd
- nbytes < 0 indicates that an error occurred
- As with reads, short counts are possible and are not errors!
여기에서도 short count가 발생할 수 있지만 에러는 아니다.
Simple Unix I/O example
¢ Copying stdin to stdout, one byte at a time

시스템 콜로 한바이트씩 데이터를 읽고 쓰게 된다. 비효율적이다. 굉장히 overhead이기 때문에 효율에 문제가 생긴다.
=== The RIO Package ===
1. The RIO Package
robust I/O Package
-
RIO is a set of wrappers that provide efficient and robust I/O in apps, such as network programs that are subject to short counts
-
RIO provides two different kinds of functions
- Unbuffered input and output of binary data
- rio_readn and rio_writen
- Buffered input of text lines and binary data
- rio_readlineb and rio_readnb
- Buffered RIO routines are thread-safe and can be interleaved arbitrarily on the same descriptor
-
Refer to à csapp.c and csapp.h
RIO는 application에서 I/O를 보다 robust하게 사용할 수 있다. network program할때 매우 좋다.
RIO는 Unbuffered I/O, Buffered Input 를 제공한다.
Unbuffered RIO Input and Output
- Same interface as Unix read and write
- Especially useful for transferring data on network sockets

- rio_readn returns short count only if it encounters EOF
- Only use it when you know how many bytes to read
- rio_writen never returns a short count
- Calls to rio_readn and rio_writen can be interleaved arbitrarily on the same descriptor
- rio_readn returns short count only if it encounters EOF
우리가 얼만큼 데이터를 읽을지 알때 사용하고 EOF를 만나면 종료한다.
Implementation of rio_readn
/*
* rio_readn - Robustly read n bytes (unbuffered)
*/
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nread = 0; /* and call read() again */
else
return -1; /* errno set by read() */
}
else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* Return >= 0 */
} csapp.creadn은 n byte만큼 데이터를 읽는다. 그리고 while을 돌면서 데이터를 읽기 시작한다. return값이 0이라면 EOF 라는 이야기 이기 때문에 nleft와 bufp를 바꾸어준다. 만약 음수라면 interrupt가 발생한 경우와 일반적인 에러 경우로 나누게 된다.
Buffered RIO Input Functions
- Efficiently read text lines and binary data from a file partially cached in an internal memory buffer

일부는 메모리의 캐시에 저장하는 이걸 읽는 방식이다.- rio_readlineb reads a text line of up to maxlen bytes from file fd and stores the line in usrbuf
- Especially useful for reading text lines from network sockets
- Stopping conditions
- maxlen bytes read
- EOF encountered
- Newline (‘\n’) encountered
위의 3가지 경우에 대해서 멈추게 된다.
- rio_readlineb reads a text line of up to maxlen bytes from file fd and stores the line in usrbuf

- rio_readnb reads up to n bytes from file fd
- Stopping conditions
- maxlen bytes read
- EOF encountered
위의 두가지 경우에 대해서 멈추게 된다.
- Calls to rio_readlineb and rio_readnb can be interleaved arbitrarily on the same descriptor
- Warning: Don’t interleave with calls to rio_readn
Buffered I/O: Implementation
-
For reading from file
-
File has associated buffer to hold bytes that have been read from file but not yet read by user code

파일이 지금까지 읽었던 buffer을 가지고 있고 그 버퍼가 지금까지 읽었던 바이트와 유저코드에 의해서 읽히지 않은 것을 포함하고 있다. -
Layered on Unix file:

이걸 언제 쓰냐면 항상 char를 읽는것이 아닌 시스템 콜로 일단 많이 읽어놓은 다음 user code에서 한 바이트씩 천천히 읽어들일때 도움이 될 수 있다
Buffered I/O: Declaration
- All information contained in struct
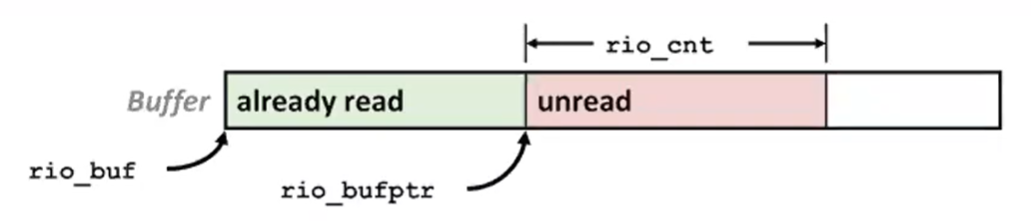
typedef struct {
int rio_fd; /* descriptor for this internal buf */
int rio_cnt; /* unread bytes in internal buf */
char *rio_bufptr; /* next unread byte in internal buf */
char rio_buf[RIO_BUFSIZE]; /* internal buffer */
} rio_t;RIO Example
- Copying the lines of a text file from standard input to standard output
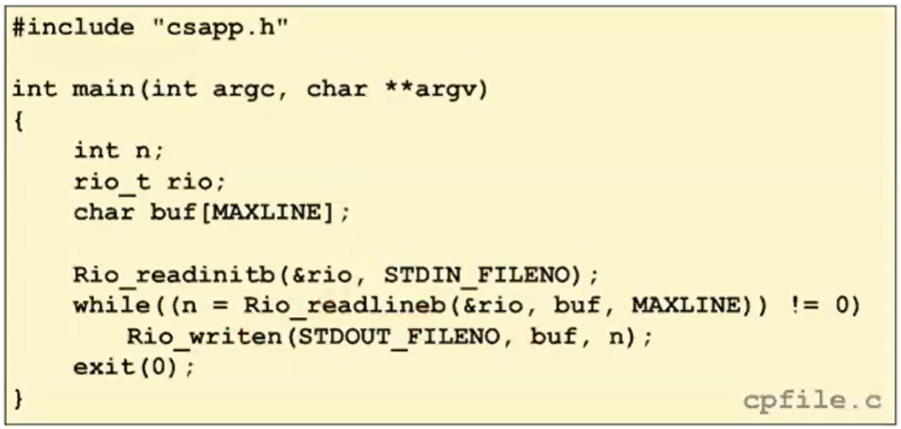
=== Metadata, sharing, and redirection ===
1. File Metadata
- Metadata is data about data, in this case file data
- Per-file metadata maintained by kernel
- accessed by users with the stat and fstat functions
메타데이터는 파일마다 갖고 있는 메타정보이다. 이건 stat, fstat 함수를 통해서 확인할 수 있다.
- accessed by users with the stat and fstat functions
/* Metadata returned by the stat and fstat functions */
struct stat {
dev_t st_dev; /* Device 몇번째 디바이스 */
ino_t st_ino; /* inode : unique한 링크는 무엇이냐 */
mode_t st_mode; /* Protection and file type */
nlink_t st_nlink; /* Number of hard links */
uid_t st_uid; /* User ID of owner */
gid_t st_gid; /* Group ID of owner */
dev_t st_rdev; /* Device type (if inode device) */
off_t st_size; /* Total size, in bytes */
unsigned long st_blksize; /* Blocksize for filesystem I/O */
unsigned long st_blocks; /* Number of blocks allocated */
time_t st_atime; /* Time of last access */
time_t st_mtime; /* Time of last modification */
time_t st_ctime; /* Time of last change */
};Example of Accessing File Metadata
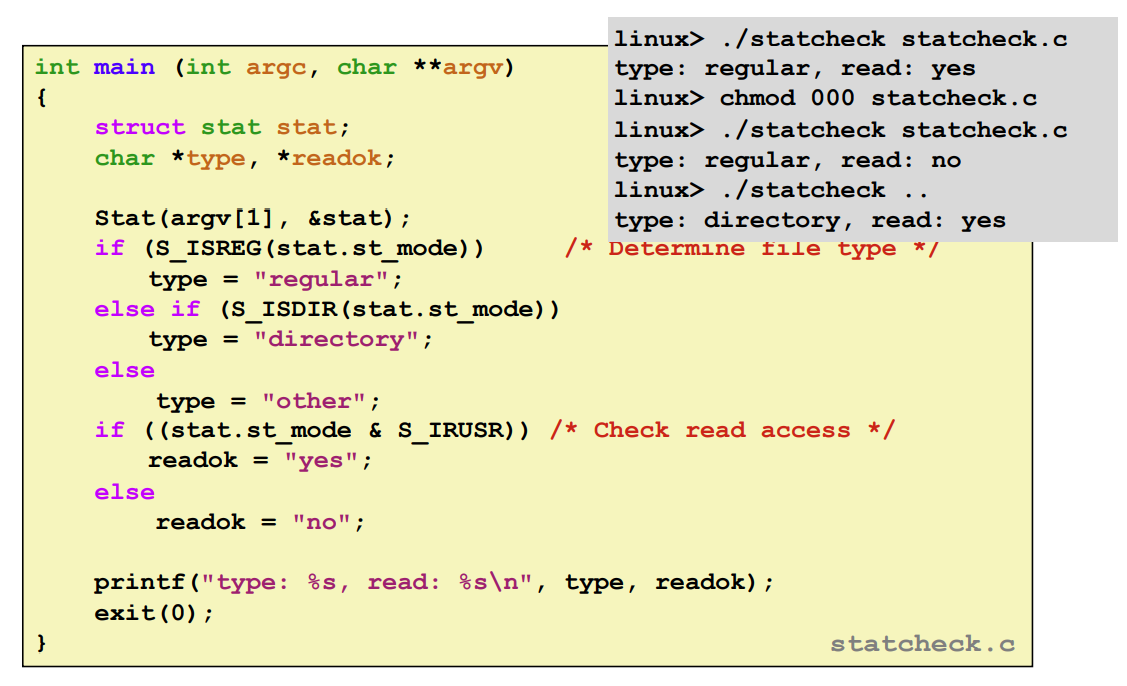
Stat을 통해서 파일의 정보를 struct stat에 넣을 수 있다.
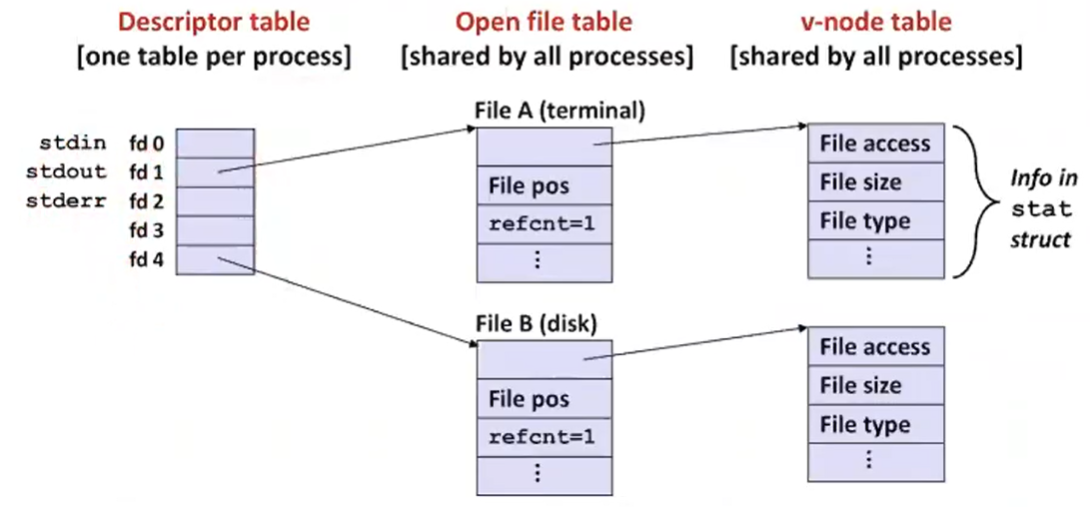
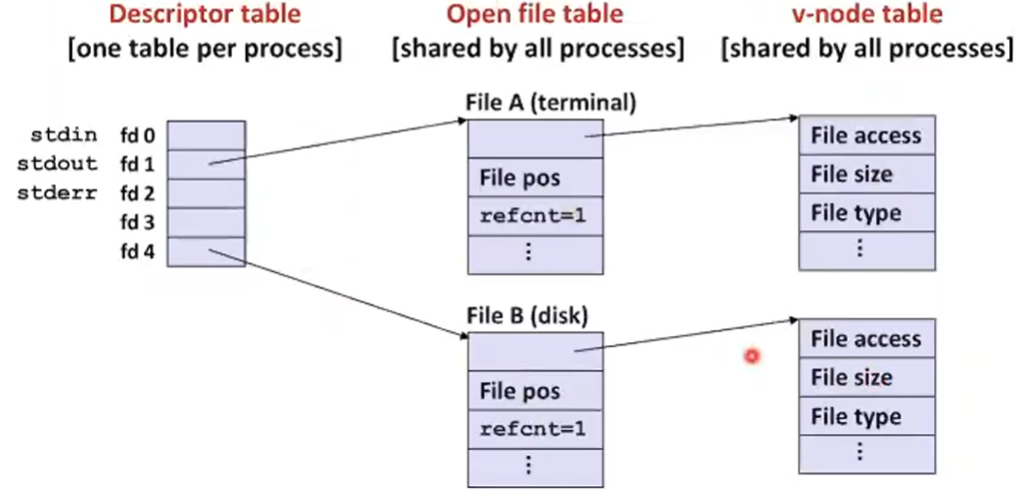
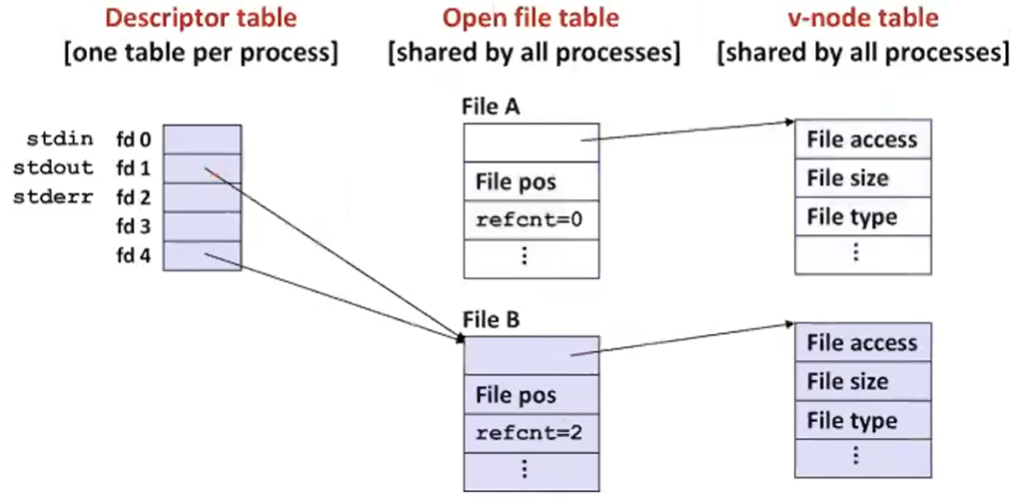
How the Unix Kernel Represents Open Files
- Two descriptors referencing two distinct open files. Descriptor 1 (stdout) points to terminal, and descriptor 4 points to open disk file
커널이 파일을 open한 것을 어떻게 표현할 것인가?
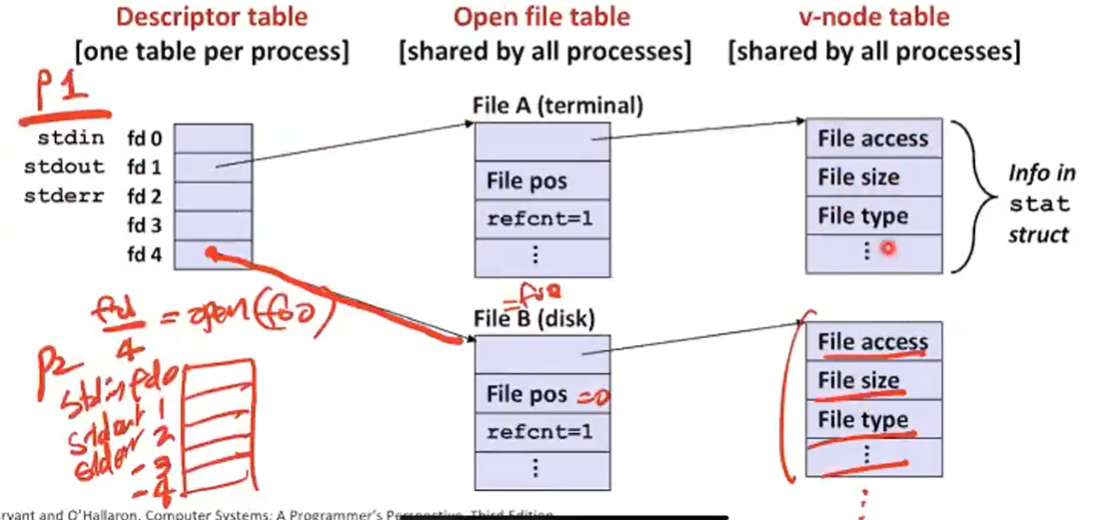
내가 foo라는 파일을 열었는데 fd 4라는 값이 넘어왔다고 하면 refcnt =1로 프로세스 하나가 접근하고 있고 file pos는 0이다(offset = 0)
v-node table이라고 해서 실재파일에 대한 meta 정보를 가지고 있다. 내가 어떤 stat 정보를 가지고 넘겨주면 커널이 파일 테이블에서 v-node까지 찾아가서 유저 버퍼에 정보를 넘기어 준다.
Descriptor table은 프로세스마다 있고 open file table, v-node table은 여러 프로세스가 공유할 수 있다.
2. File Sharing
- Two distinct descriptors sharing the same disk file through two distinct open file table entries
- E.g., Calling open twice with the same filename argument
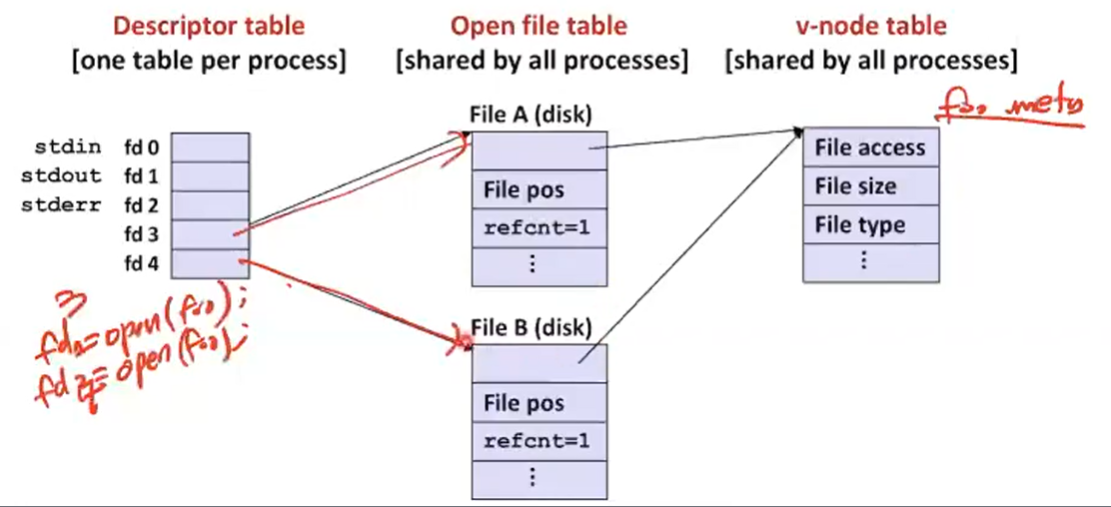
- E.g., Calling open twice with the same filename argument
예를 들어서 서로 다른 descriptor가 동일한 disk file을 접근할 수 있다. 동일한 파일에 두번 접근하면 open file은 다른 두개가 나온다. 하지만 파일에 대한 meta 데이터는 하나만 존재하게 된다.
How Processes Share Files: fork
- A child process inherits its parent’s open files
- Note: situation unchanged by exec functions (use fcntl to change)
- Before fork call:
만약 fork를 하게 된다면 child process는 parent process의 open file들에 대한 desciptor table을 복제한다.
fork 호출전에는는 각 파일에 대해 meta data를 가지고 있다.
- A child process inherits its parent’s open files
- After fork:
- Child’s table same as parent’s, and +1 to each refcnt
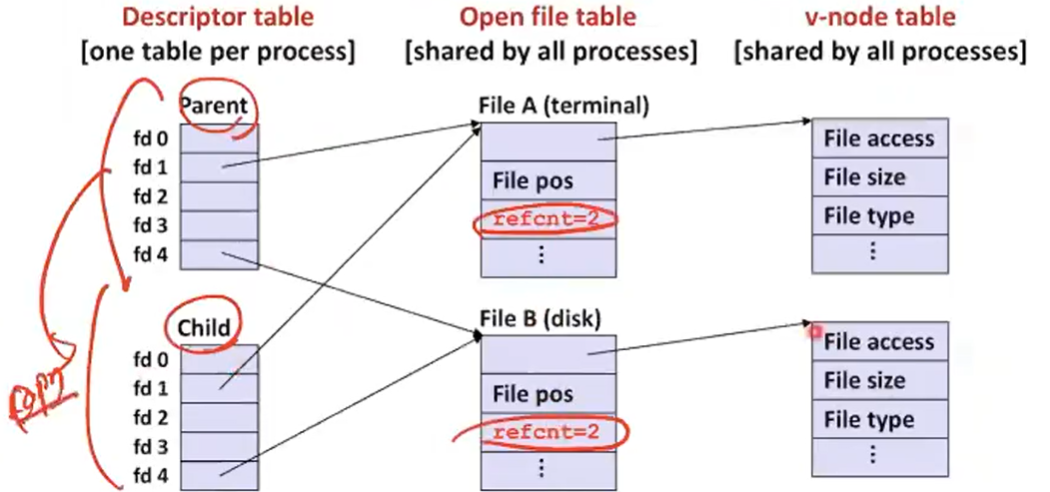
- Child’s table same as parent’s, and +1 to each refcnt
fork를 하면 parnet 프로세스를 그대로 복제를 하고 refcnt=2로 바뀌게 된다.
3. I/O Redirection
- Question: How does a shell implement I/O redirection?
linux> ls > foo.txt - Answer: By calling the dup2(oldfd, newfd)
function- Copies (per-process) descriptor table entry oldfd to entry newfd
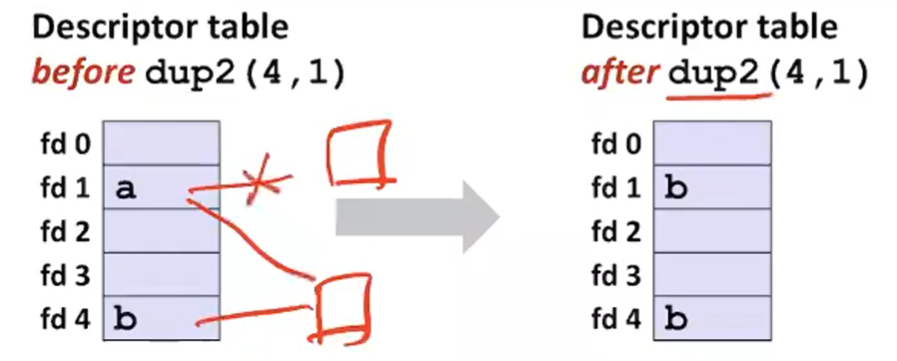
- Copies (per-process) descriptor table entry oldfd to entry newfd
dup2라는 시스템 콜을 사용한다. 예를 들어서 dup2(4,1)이라고 해서 ls에서 나오는 output을 foo.txt의 input으로 사용할 수 있게 된다. 그래서 위의 그림과 같이 fd1을 fd4가 가리키는 것을 가리키도록 만들 수 있다.
I/O Redirection Example
- Step #1: open file to which stdout should be redirected
- Happens in child executing shell code, before exec
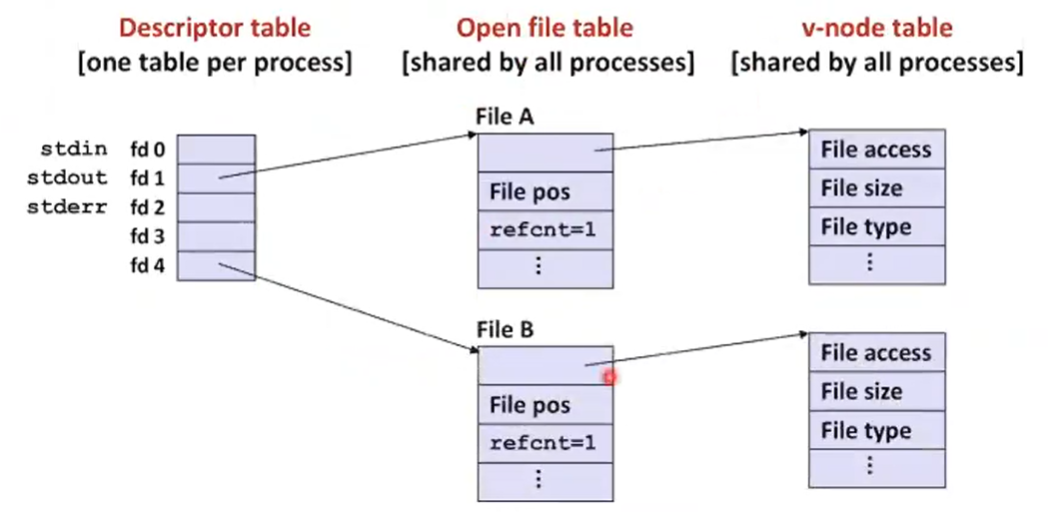
- Step #2: call dup2(4,1)
- cause fd=1 (stdout) to refer to disk file pointed at by
- cause fd=1 (stdout) to refer to disk file pointed at by
=== Standard I/O ===
1. Standard I/O Functions
- The C standard library (libc.so) contains a collection of higher-level standard I/O functions
- Documented in Appendix B of K&R
- Examples of standard I/O functions:
- Opening and closing files (fopen and fclose)
- Reading and writing bytes (fread and fwrite)
- Reading and writing text lines (fgets and fputs)
- Formatted reading and writing (fscanf and fprintf)
Standard I/O Streams
- Standard I/O models open files as streams
- Abstraction for a file descriptor and a buffer in memory
standard I/O 함수들은 stream이라고 해서 I/O 모델들이 파일들을 갖다고 stream으로 보고 있고 file desciptor와 메모리의 buffer을 추상화를 해서 사용한다.
- C programs begin life with three open streams
(defined in stdio.h)

Buffered I/O: Motivation
- Applications often read/write one character at a time
- getc, putc, ungetc
- gets, fgets
- Read line of text one character at a time, stopping at newline
얘네들은 기본적으로 buffered I/O를 사용해서 overhead가 크다.
-
Implementing as Unix I/O calls expensive
- read and write require Unix kernel calls
10,000 clock cycles
- read and write require Unix kernel calls
-
Solution: Buffered read
- Use Unix read to grab block of bytes
- User input functions take one byte at a time from buffer
- Refill buffer when empty
한번에 여러개의 byte를 block으로 해서 가지고 온다. 그 buffer로 부터 요청되는 바이트를 가지고 오는 것이다.

Buffering in Standard I/O
- Standard I/O functions use buffered I/O
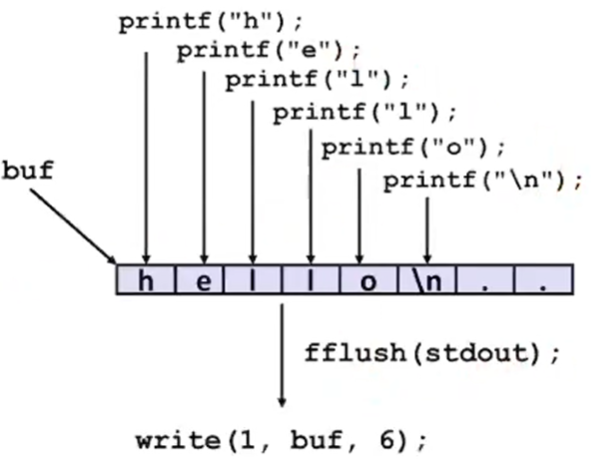
Buffered I/O를 Standard I/O에서 하는 예제이다. 그래서 hello를 한 문자씩 적으면 내부적인 buf pointer에다가 하나씩 찍게 된다. 코드상에서 fflush를 한다. 이러면 결국 strace라는 utility를 사용하면 현재 사용되는 시스템을 모두 가지고가서 화면에 출력을 해준다.
¢ Buffer flushed to output fd on “\n”, call to fflush or exit, or return from main.
Standard I/O Buffering in Action
¢ You can see this buffering in action for yourself, using the always fascinating Linux strace program:

execve를 호출하고 write는 한 번만 호출이 된다. 그래서 printf는 한번만 호출을 해서 성능을 최적화했다.
=== Closing remarks ===
1. Unix I/O vs. Standard I/O vs. RIO
¢ Standard I/O and RIO are implemented using low-level
Unix I/O
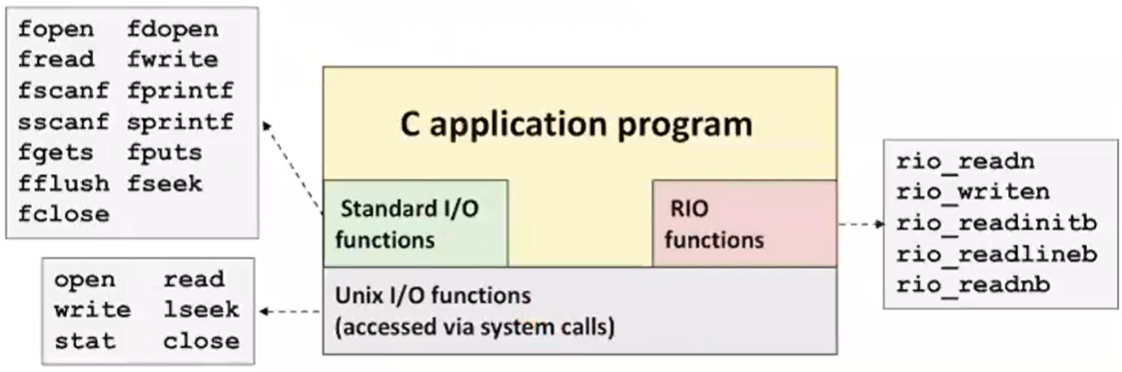
맨밑에 Unix I/O가 있고 그 위에 RIO와 Standard I/O가 올라가 있는 것을 확인할 수 있다. 결국에 Standard I/O는 시스템콜을 기반으로 구현한 라이브러리이다.
- Which ones should you use in your programs?
그럼 둘 중에 어떤 것을 사용할 것인가? RIO를 사용하는 이유는 네트워크 communication을 위해서 사용한다. Standard I/O는 local 데이터를 위해서 사용된다.
그리고 알아두어야 하는 것이 이 둘을 섞어서 쓰면안된다. 쓰는 버퍼가 다르기 때문에 잘못하면 섞인다.
Pros and Cons of Unix I/O
- Pros
- Unix I/O is the most general and lowest overhead form of I/O
- All other I/O packages are implemented using Unix I/O functions
- Unix I/O provides functions for accessing file metadata
- Unix I/O functions are async-signal-safe and can be used safely in signal handlers
- Unix I/O is the most general and lowest overhead form of I/O
직접 metadata접근, async-signal-safe하다.
- Cons
- Dealing with short counts is tricky and error prone
- Efficient reading of text lines requires some form of buffering, also tricky and error prone
- Both of these issues are addressed by the standard I/O and RIO packages
버그 많고 버퍼직접써야한다.
Pros and Cons of Standard I/O
- Pros:
- Buffering increases efficiency by decreasing the number of read and write system calls
- Short counts are handled automatically
우리가 직접적으로 read, write를 사용하지 않아서 효율적
- Cons:
- Provides no function for accessing file metadata
- Standard I/O functions are not async-signal-safe, and not appropriate for signal handlers
- Standard I/O is not appropriate for input and output on network sockets
- There are poorly documented restrictions on streams that interact badly with restrictions on sockets (CS:APP3e, Sec 10.11)
Choosing I/O Functions
- General rule: use the highest-level I/O functions you can
- Many C programmers are able to do all of their work using the standard I/O functions
- But, be sure to understand the functions you use!
- When to use standard I/O
- When working with disk or terminal files
- When to use raw Unix I/O
- Inside signal handlers, because Unix I/O is async-signal-safe
- In rare cases when you need absolute highest performance
- When to use RIO
- When you are reading and writing network sockets
- Avoid using standard I/O on sockets
