=== Thread-Level Parallelism ===
Today
- Parallel Computing Hardware
- Multicore
- Multiple separate processors on single chip
- Hyperthreading
- Efficient execution of multiple threads on single core
- Multicore
- Thread-Level Parallelism
- Splitting program into independent tasks
- Example: Parallel summation
- Splitting program into independent tasks
- Consistency Models
- What happens when multiple threads are reading & writing shared state
1. Exploiting parallel execution
- So far, we’ve used threads to deal with I/O delays
- e.g., one thread per client to prevent one from delaying another
- Multi-core/Hyperthreaded CPUs offer another
opportunity- Spread work over threads executing in parallel
- Happens automatically, if many independent tasks
- e.g., running many applications or serving many clients
- Can also write code to make one big task go faster
- by organizing it as multiple parallel sub-tasks
대부분의 하드웨어는 멀티코어로 되어있다. 그리고 여러개의 프로세서로 구성된다. 그리고 Hyperthreading이 가능한 CPU가 존재한다.
Hyperthreading이 가능하다면 CPU가 여러개의 코어를 가진것처럼 보인다.
multi-core는 cpu가 여러개인 환경을 가정한다. 여기에서 hyperthread하면 cpu에 mapping되어서 작동한다.
스레드들끼리 공유하는 자료구조가 있다보니 완전히 병렬적으로 실행하기 어려운 부분이 있었다.
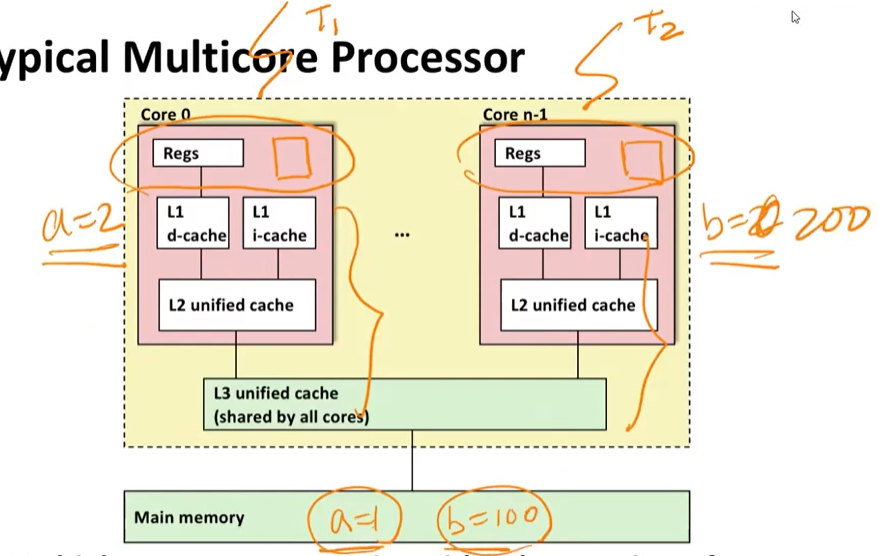
Typical Multicore Processor
- Multiple processors operating with coherent view of memory
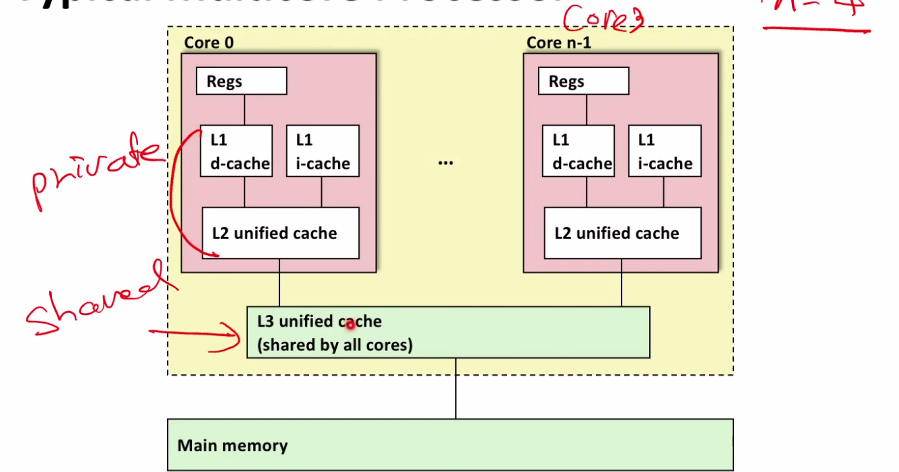
위의 이미지와 같이 단일칩안에 여러개의 코어가 있다. 하나의 코어는 여러개의 캐시로 나뉘어져 있는 것을 확인할 수 있다.
L1, L2 캐시는 private cache, L3는 shared cache라고 부른다. 보통 메인메모리는 DRam으로 만들고 L3는 SRam으로 만든다. reg에 가까울 수록 latency가 빠르다. 그래서 순차적으로 메모리들을 확인한다.
L1 캐시는 d-cache, i-cache로 나뉜다.
Benchmark Machine
- Get data about machine from /proc/cpuinfo
OS안에서 관리하는 하드웨어 정보를 이 파일 안에 저장하고 있다.
- Shark Machines
- Intel Xeon E5520 @ 2.27 GHz
- Nehalem, ca. 2010
- 8 Cores
- Each can do 2x hyperthreading
Example 1: Parallel Summation
- Sum numbers 0, …, n-1
- Should add up to
((n-1) * n)/2
- Should add up to
- Partition values 1, …, n-1 into t ranges
- under(n/t) values in each range
- Each of t threads processes 1 range
- For simplicity, assume n is a multiple of t
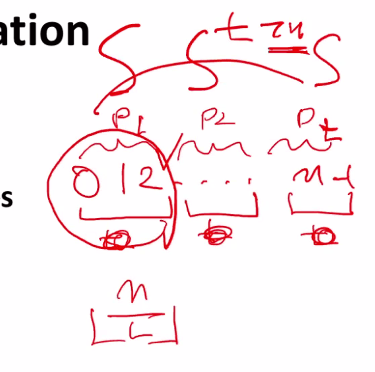
0부터 n-1까지 일정 크기로 t개의 파티션을 나눈다고 하자. 각각의 파티션마다 스레드를 assign한다고 생각하자.
- Let’s consider different ways that multiple threads might work on their assigned ranges in parallel
2. First attempt: psum-mutex
- Simplest approach: Threads sum into a global variable protected by a semaphore mutex.
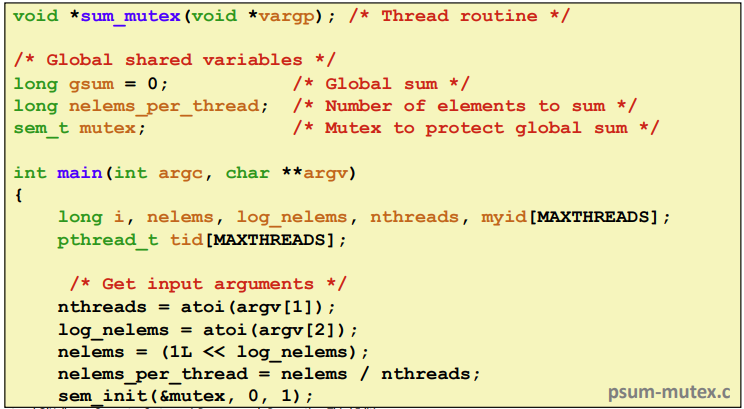
스레드당 element의 갯수를 스레드의 갯수로 나눈다.
- Simplest approach: Threads sum into a global variable protected by a semaphore mutex.

스레드를 nthread갯수만큼 띄우고 sum_mutex라고 스레드가 실행하는 함수와 아이디를 넘기어 준다.
마지막에는 gsum을 가지고 출력해본다.
psum-mutex Thread Routine
¢ Simplest approach: Threads sum into a global variable
protected by a semaphore mutex.
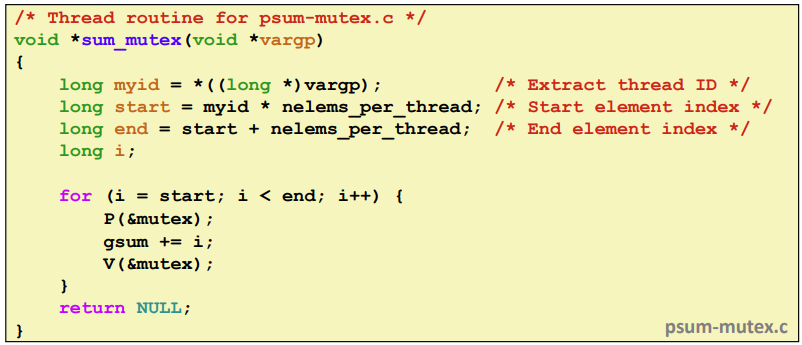
여러개의 스레드를 띄운다음에 gsum이라는 global 변수를 하나 선언해서 주기적으로 업데이트 하는 것이다. 그래서 모든 스레드가 각자 실행해야 하는 범위가 저장될 것이다.
그래서 mutex로 선언해서 한번에 접근하지 않도록 만든다. 비용은 많이 들지만 최대한 critical section에 안들어가도록 만든다.
psum-mutex Performance
- Shark machine with 8 cores, n=2^31

hyperthreading을 띄우기 때문에 16개까지 사용이 가능하다.
웃긴것은 1스레드보다 2스레드, 4스레드가 더 느리다. 갈수록 속도가 느리다.
- Nasty surprise:
- Single thread is very slow
- Gets slower as we use more cores
그런데 단일 스레드도 느리다. 왜냐하면 뮤택스락을 잡고 풀고를 반복했기 때문이다.
3. Next Attempt: psum-array
- Peer thread i sums into global array element psum[i]
- Main waits for theads to finish, then sums elements of psum
- Eliminates need for mutex synchronization

해결책은 배열을 만들어서 partial sum을 한다. 그래서 각자가 자기 위치에서 수행하게끔 만들자
psum-array Performance
- Orders of magnitude faster than psum-mutex
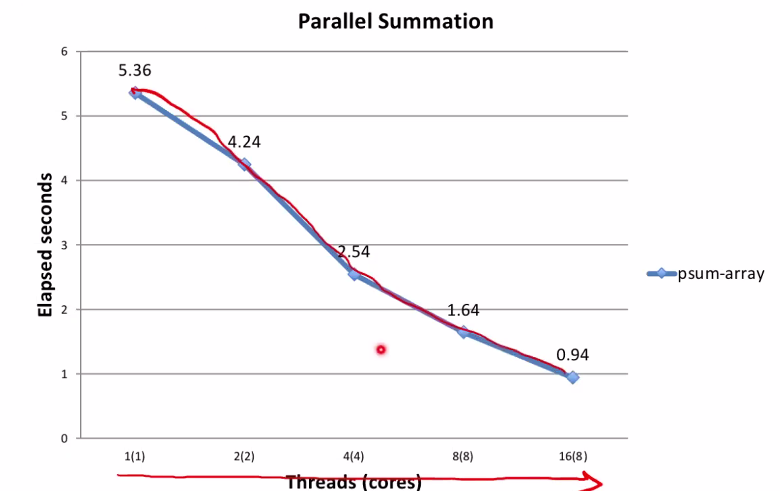
여기에서는 성능이 점차 좋아지는 것을 확인할 수 있다.
4. Next Attempt: psum-local
- Reduce memory references by having peer thread i sum into a local variable (register)

본인의 레지스터에서 값을 업데이트 한다.
5. psum-local Performance
- Significantly faster than psum-array
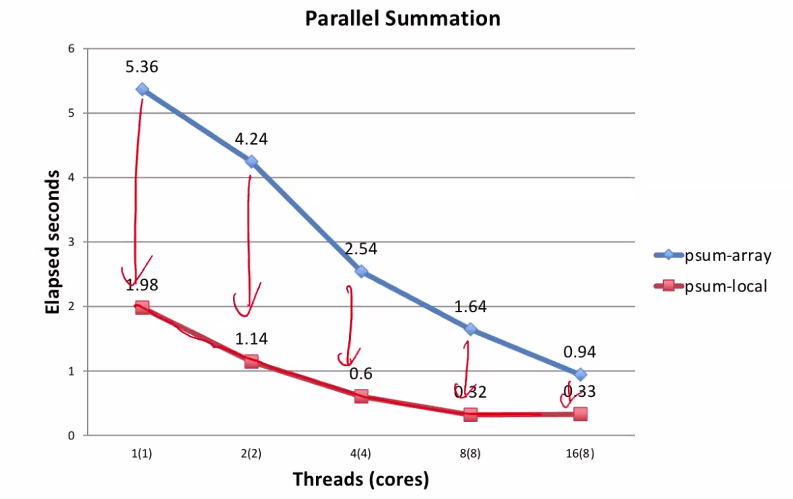
Characterizing Parallel Program Performance
-
p processor cores, Tk is the running time using k cores
-
Def. Speedup: Sp = T1 / Tp
- Sp is relative speedup if T1 is running time of parallel version of the code running on 1 core.
- Sp is absolute speedup if T1 is running time of sequential version of code running on 1 core.
- Absolute speedup is a much truer measure of the benefits of parallelism.
- Def. Efficiency: Ep = Sp /p = T1 /(pTp)
- Reported as a percentage in the range (0, 100].
- Measures the overhead due to parallelization
Efficiency는 내가 순수하게 cpu, thread 하나만 가지고 했을 때
Performance of psum-local
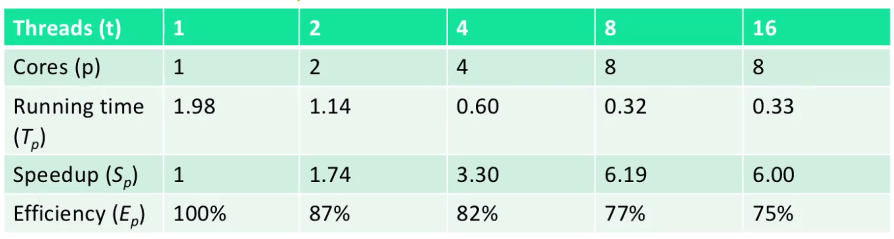
- Efficiencies OK, not great
- Our example is easily parallelizable
- Real codes are often much harder to parallelize
S1은 혼자돌았을때 1로 손실이 없다.
S2는 cpu 2개를 돌았을때 (1.98/1.14)=1.74가 되었다. (1.74/2) = 87%이다. 그러므로 13%의 손실이 있었다.
S4는 18%, S8는 23%, S16는 25$의 손실이 있었다고 볼 수 있다.
그래서 CPU를 16개를 사용하게 되면 효율이 떨어진다는 것을 알 수 있다.
6. Memory Consistency
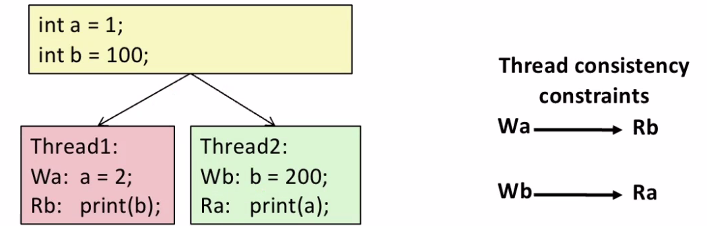
Memory Consistency는 메모리에 변수가 두개가 존재한다. 스레드 1번이 코드를 수행하는데 a를 2로 바꾸고 b를 출력한다. 스레드 2번은 b를 바꾸고 a를 출력한다. program execution order는 각 스레드마다 W하고 R을 한다.
하지만 이 출력되는 b,a가 있다면 이게 deterministic하지 않다. 스레드간의 interleaving할 수 있기 때문에 실행되는 순서에 따라서 결과가 달라질 수 있다.
-
What are the possible values printed?
- Depends on memory consistency model
- Abstract model of how hardware handles concurrent accesses
-
Sequential consistency
- Overall effect consistent with each individual thread
- Otherwise, arbitrary interleaving
Sequential consistency은 각 스레드들이 순서에 따라서 실행될 수 있도록 했는데 만약에 순서에 따라 실행되지 않는다면 나올 수 있는 값을 보장할 수 없다.
Sequential Consistency Example
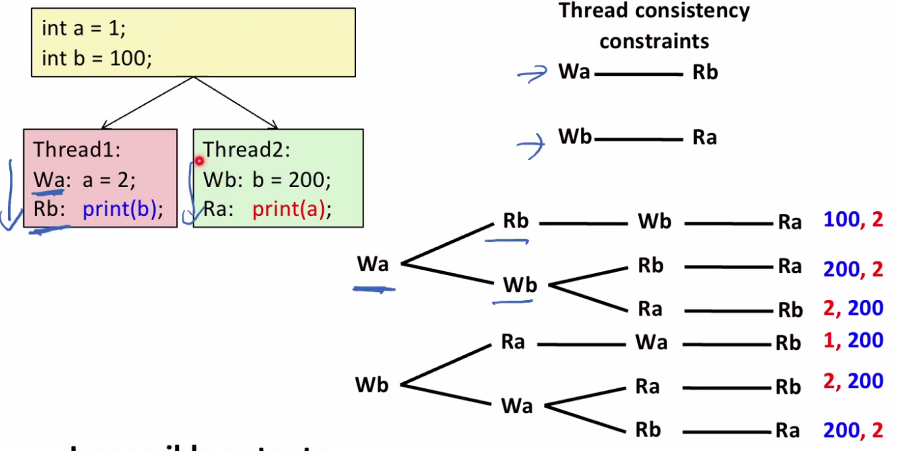
위의 순서는 바꿀 수 없다. 하지만 interleaving을 바꾸어볼 수 있다. 그 결과가 오른쪽에 있는 트리이다. 진행순서에 따라 결과가 다른 것을 확인할 수 있다.
- Impossible outputs
- 100, 1 and 1, 100
- Would require reaching both Ra and Rb before Wa and Wb
Non-Coherent Cache Scenario
여기에서 캐시가 들어가면 보다 복잡해진다. main memory에 있는 값을 스레드에 있는 캐시에 복사해와서 막 바꿀 수 있다. 그러면 캐시에 있는 값과
메인 메모리의 값이 다른 경우가 생길 수 있다.
이 상태에서 스레드1번이 b를 출력하면 메인메모리에 있는 b = 100을 출력할 수 밖에 없어서 스레드 2번의 값을 출력할 수 없게 된다.
- Write-back caches, without coordination between them
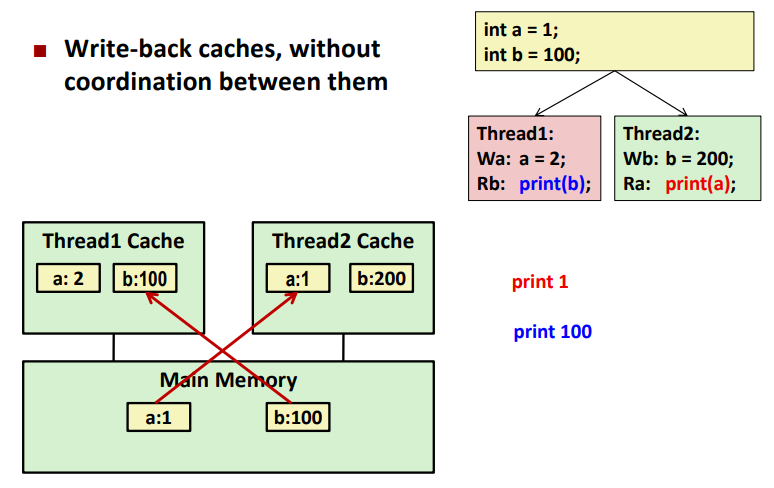
각각 캐시의 복제본을 가지고 출력하다보면 최신값을 출력할 수 없게 된다.
Snoopy Caches
snoopy caches : 각각의 cpu에서 돌아가고 있는 메모리에 tag를 붙이는 거다.
- Tag each cache block with state
Invalid : Cannot use value
Shared : Readable copy
Exclusive : Writeable copy
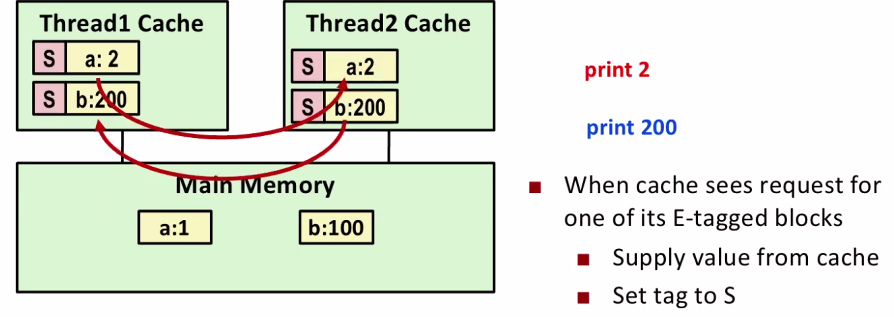
스레드 2번이 1번을 접근하는 경우 스레드 2번이 다른 cpu의 값을 읽을때 E->S로 바꾸어서 읽게 된다.
그럼 서로서로 어떤 태그를 가지고 있는지 확인하는 방법이 하드웨어적으로 구현되어 있다. 결국에 이 cache coherency protocol을 하드웨어적으로 implement 해놓았는데 순수하게 값이 날아오는 것이 0이 아니기 때문에 그만큼의 overhead를 감수해서라도 값을 복사해 와서 성능상에 변화가 생길 수 있다.
- When cache sees request for one of its E-tagged blocks
- Supply value from cache
- Set tag to S
