=== ECF ===
1. Exceptional Control Flow
CPU가 명령어를 실행하는 sequence를 control flow라고 부른다.
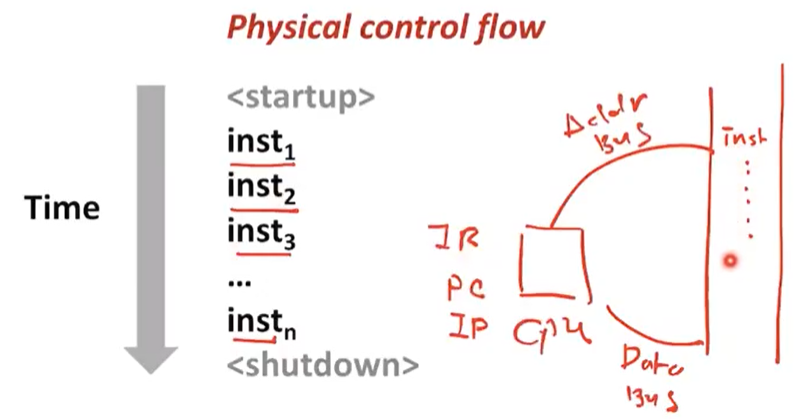
Addr Bus에 신호를 준다
-> cpu 안에 있는 PC(program counter), IP(intruction pointer)의 값을 보고 addressing을 해서 instruction 값을 fetch한다.
-> fetch된 instruction이 data bus를 통해서 cpu의 IR(insturction register)에 들어간다.
-> 그걸 cpu는 decoding한다.
-> 그리고 opcode가 무엇인지 확인하고 execution한다.
sequence는 cpu입장에서는 control을 sequence 순으로 한다고 생각하고 flow를 가지게 된다. 이것을 control flow라고 한다.
Altering the Control Flow
-
이 sequence를 프로그래머가 의도적으로 변경하는 방법이 있다.
-
Jumps and branches : 원래 pc의 그 다음 주소를 다른 곳에 저장하고 jmp의 주소로 pc를 업데이트, 실행하고 돌아온다.
-
Call and return : 서브루틴을 호출하는 경우. 프로그램 상태의 변화에 반응하는 거라고 보면 된다.
- 프로그래머의 의도가 아닌 경우
- Data arrives from a disk or a network adapter : 디스크에서 데이터가 다 온 경우, 네트워크에서 데이터 패킷이 온 경우
- Instruction divides by zero : 0으로 나눈 경우
- User hits Ctrl-C at the keyboard : ctrl-c를 누른 경우
- System timer expires : system timer가 만료된 경우
=> 이러한 예외를 처리하기 위해서 Exception table이 존재한다. 예외처리 별 인덱스가 존재해서 각각의 Exception 번호는 해당하는 exception handler의 주소를 가지고 있다.
2. Exceptions
User 코드가 작동하다가 Event가 발생하면 예외가 발생했으니 kernel로 제어권을 넘기어 주는 것이다. 그럼 kernel은 예외처리 handler가 작동한다.
예외처리를 위한 Exception table이 존재한다. 예외처리 별 인덱스가 있다. 각각의 Exception 번호는 해당하는 exception handler의 주소를 가지고 있다.
Classes of Exceptions
Interrupt는 비동기
Traps, Faults, and Aborts는 동기방식이다.
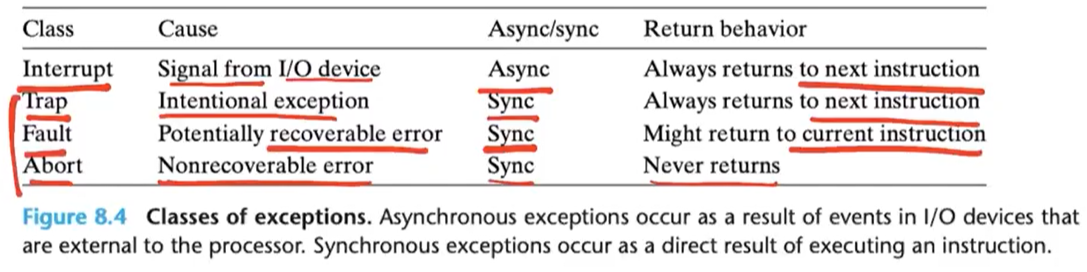
Interrupt는 I/O device로부터 signal이 온다. signal이 오면 현재 명령어를 끝내고 그 다음 명령어를 실행한다.
recoverable error은 segment fault, page fault가 떳을 때를 이야기 한다.
Asynchronous Exceptions (Interrupts)
외부에서 발생하는 이벤트에 의해서 야기되는 Exception이다. cpu가 instruction을 매번 읽을 때마다 interrupt pin이 셋팅되어 있는지 확인한다.
Synchronous Exceptions
Traps, Fault, Abort
-
트랩(trap)은 실행 중인 프로그램 내에 테스트를 위해 특별한 조건을 걸어 놓은 것을 말한다
-
폴트(fault)는 현재 명령라인이 실패하면, 폴트처리루틴(fault handler)을 수행한후 이전라인으로 복귀하는 것을 이야기 한다.
- CPU가 DRAM에 mapping되어 있지 않은 메모리에 접근할 때 page fault가 발생하고
-
어볼트(abort)는 현재 명령라인이 실패하면 중지하는 걸 말한다.
- DRAM에 비트들이 저장되어 있는 데 이게 bit flip이 될 수 있다. 이때 이전으로 돌릴 수 있냐 없냐로 recoverable, unrecoverable하다고 한다.
3. Processes
즉 프로그램은 우리가 짠 텍스트 파일이고
프로세스는 메모리에 올라간 프로그램을 이야기 한다.
프로세서는 cpu이고
- 프로그램의 두가지 중요 개념
- Logical control flow : 각 프로그램은 cpu를 배타적으로 혼자 사용하는 것처럼 실행을 한다.
- Private address space : 개인 메모리 주소 공간이 존재한다. cpu안에는 register가 있는데 register set을 사용해서 프로그램이 실행된다.
Multiprocessing
-
마치 각 프로세스가 내가 CPU, 메모리를 독점해서 사용하는 것처럼 환상을 가지고 돌아가게 된다. 굉장히 빠르게 time sharing하면서 switching을 하기 떄문에 프로세스들은 이를 느끼지 못한다.
-
single processor을 가지고 이해하면 cpu가 register에 적재된 프로그램을 실행하게 되는 것이다.
-
interrupt가 발생했다면 interrupt handler가 발생한다. 그때 handler는 context switching을 하고 그 안에서는 또 schedule이라는 함수를 호출해서 그 다음에 수행한 프로그램을 선택하고 실행하는데 cpu안의 값을 저장해야 한다.
Concurrent Processes
-
두 개의 프로세스가 함께 실행되고 있으면 concurrent하다고 하고 그렇지 못한것을 sequential하다고 한다.
-
Concurrent: A & B, A & C
-
Sequential: B & C
Context Switching
context switching 이란 현재 진행하고 있는 Task(Process, Thread)의 상태를 저장하고 다음 진행할 Task의 상태 값을 읽어 적용하는 과정을 말한다.
4. Process Control
System Call Error Handling
- fork에 해당하는 system call handler는 kernel code이다. 보통 system call은 에러발생시 -1이 반환되고 errno에 에러를 발생시킨 원인들을 기록한다.
Creating and Terminating Processes
-
Running : executing, waiting하고 있는 상태를 이야기 한다. scheduling이 되기 위해 기다리는 상태
-
Stopped : suspended 되어 있는 상태를 이야기 한다. signal을 받기 전까지 기다리는 상태이다.
-
Terminated : main함수에서 종료, exit 받은 경우 terminate를 받은 경우
-
Creating Processes : fork를 하면 자식 프로세스를 만들고 자식은 0을 반환 부모는 자식의 pid를 반환한다.
Reaping Child Processes
-
zombie : OS에서 정상적으로 제거되지 못하고 리소스를 사용하고 있는 child process
-
reaping : child process를 제거하는 과정
-
wait : parent가 wait를(시스템콜) 이용해서 child를 reap할 수 있다. child가 끝날때까지 parent는 suspend된 상태이다. 그리고 child가 정상적으로 terminate되면 child process pid가 반환된다. 또한 child_status도 함께 넘어오는데 null이 아니면 integer로 왜 child가 terminate되었는지에 대해 표시하는 값이 들어가 있다.
pid_t wpid = wait(&child_status);
pid_t wpid = waitpid(pid[i], &child_status, 0);- execve: Loading and Running Programs
=== Signals and Nonlocal Jumps ===
1. Shell
-
쉘이라는 것은 user program인데 다른 사용자들 대신에 그 프로그램을 실행시키어 주는 프로그램이다.
-
Inter-Process Communication(IPC) : 프로세스간 통신이라는 뜻으로 프로세스들 사이에서 서로 데이터를 주고 받는 행위, 또는 그에 대한 방법이나 경로를 뜻한다. 명령어에 파이프라인을 넣으면 두 개의 프로세스를 띄운다음 첫 명령어의 결과를 두번째 명령어 입력으로 넣는다. 각자 address space를 가지고 있고 공유 space가 없다. 즉 단방향 통신이다.
inr n, fd[2], pid; char line[100];
if (pipe(fd) < 0) exit(-1);- bg 프로세스가 끝났을때 kernel이 특정 프로세스에게 끝났다는 것을 알려준다. 그것이 signal이다.
2. Signals
- signal은 어떤 프로세스에 어떤 이벤트가 발생했다고 알려주는 메세지라고 생각하면 된다.
Nested Signal Handlers
- Nested Signal Handlers : signal은 중첩이 될 수 있다. 프로세스가 context switch되어서 다시 돌아와 수행되는 시점에 커널이 이 프로세ㅐ스에게 전달이 된 시그널이 있으면 핸들러를 수행해준다.
Blocking and Unblocking Signals
implicit blocking mechanism : 만약 SIGINT 핸들러는 다른 SIGINT signal을 받았을 때 수행하지 않도록 blocking한다. 이것을 위해 sigprocmask를 사용한다.
sigset_t mask, prev_mask;
Sigemptyset(&mask); // blocking하고자 하는 signal을 모두 masking
Sigaddset(&mask, SIGINT); //해당하는 signal을 mask해서 blocking 하겠다.
/* Block SIGINT and save previous blocked set */
Sigprocmask(SIG_BLOCK, &mask, &prev_mask); // Sigprocmask를 호출해서 mask를 blocking하는데 이 함수 이전에 있던 signal mask를 잠시 저장하고(prev_mask) mask로 setting
.
./* Code region that will not be interrupted by SIGINT */
. //이때부터는 SIGINT는 모두 blocking 가능
/* Restore previous blocked set, unblocking SIGINT */
Sigprocmask(SIG_SETMASK, &prev_mask, NULL);
//다시 예전것으로 복구해준다. 그리고 sigint는 unblocking
Safe Signal Handling
- handler는 최대한 간단하게 작성하자
- async-signal-safe한 함수만 호출하자
printf,sprintf,malloc, andexitare not safe!
- entry와 exit시 global 변수는 임시변수에 저장하고 나중에 복원을 하는 방법을 권장한다.
- 만약 공유자료구조를 접근한다면 다른 signal을 blocking해서 corruption을 방지
- global 변수를 volatile로 생성
- 글로벌 flag 선언시 sig_atomic_t 타입으로 선언해라.
Async-Signal-Safety
_exit, write, wait, waitpid, sleep, kill
-
while문으로 좀비프로세스가 있는 만큼 wait해서 다른 좀비들을 여러번 체크해서 ccount를 declined한다.
-
Deadlick : 프로세스가 자원을 얻지 못해 다음 처리를 하지 못하는 상태로, ‘교착 상태’라고도 하며 시스템적으로 한정된 자원을 여러 곳에서 사용하려고 할 때 발생합니다.
signal handler를 수행중에 printf를 수행하려고 하지만 이미 부모 프로세스가 lock을 하고 있어서 자식 프로세스가 실행하지 못하고 있어서 기다리게 된다.
ssize_t sio_puts(char s[]) /* Put string * /
ssize_t sio_putl(long v) /* Put long * /
void sio_error(char s[]) /* Put msg & exit * /void sigint_handler(int sig) /* Safe SIGINT handler */
{
Sio_puts("So you think you can stop the bomb with ctrl-c, do you?\n");
sleep(2);
Sio_puts("Well..."); //여기가 원래 printf였으면 async하게 바꾸었다.
sleep(1);
Sio_puts("OK. :-)\n"); //여기가 원래 printf였으면 async하게 바꾸었다.
_exit(0);
} sigintsafe.cPortable Signal Handling
-
old system과 같은 경우 signal을 받아 handler가 처리하고 default로 돌아가는 문제점 / interrupt 처리중에 signal을 받아서 돌아올때 error을 발생하는 경우 / read 시스템 콜을 발생하다가 시스템이 그냥 abort해서 error을 발생하는 경우
-
프로그래머가 시스템 콜을 다시 보내는 식으로 문제를 해결
-
Solution: sigaction
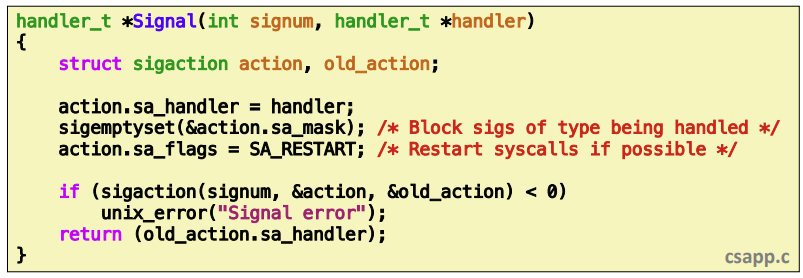
그래서 이러한 문제점을 해결하기 위해 sigaction을 사용하게 된다.
Synchronizing Flows to Avoid Races
- 어쩌다 보니 addjob이 deletejob 수행후 발생하면 프로세스가 죽었음에도 불구하고 job queue에는 addjob이 들어와 있을 수가 있다.
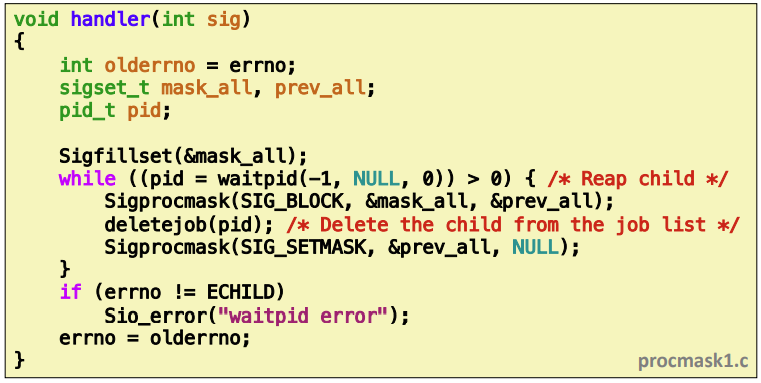
- 그래서 위의 문제를 해결하기 위해서 Sigemptyset으로 마스크를 하나더 만들고 SIGCHLD만 처리한다.
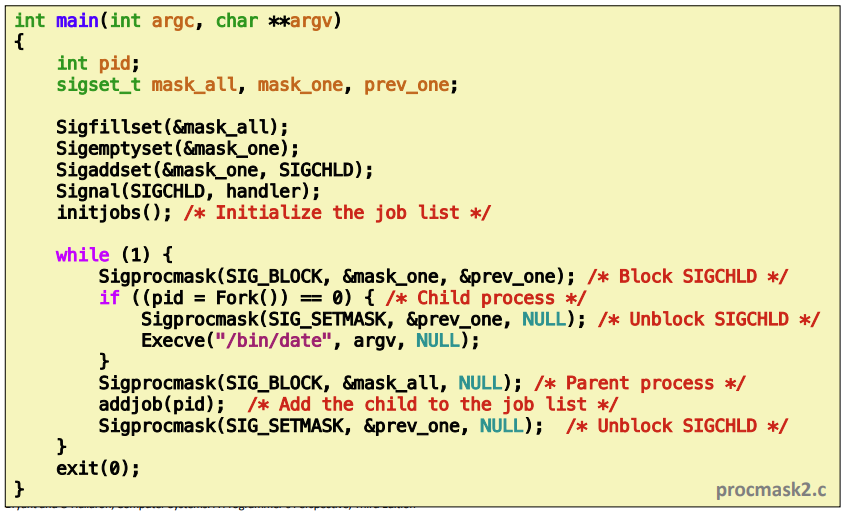
Explicitly Waiting for Signals
-
waitpid를 사용해서 명시적으로 pid라는 것을 volatile로 선언하고 return 값을 가지고 pid의 값을 확인하는 방법이 있다. 이때 pid를 main에서 기다리고 있기 때문에 cpu cycle을 너무 많이 쓰는 문제가 있다.
-
pause는 signal을 받으면 깨어난다.
-
sleep은 시간이 지나면 깨어난다.
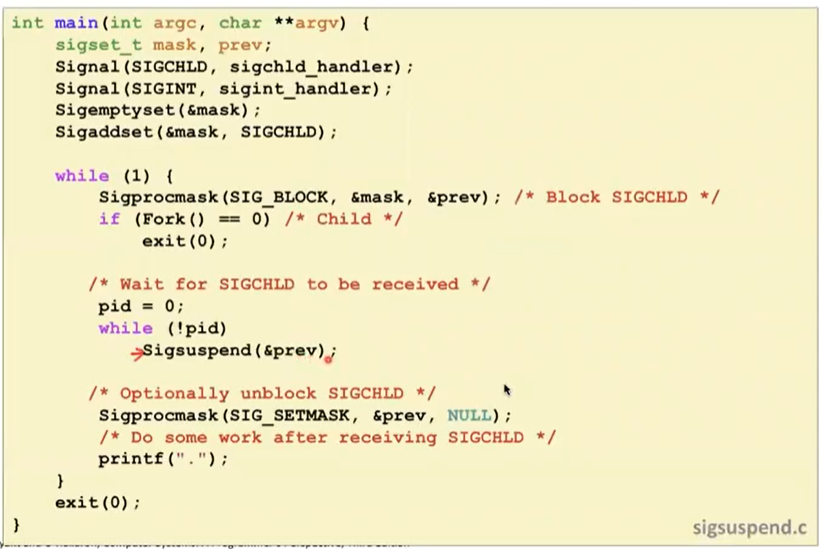
sigprocmask(SIG_BLOCK, &mask, &prev);
pause();
sigprocmask(SIG_SETMASK, &prev, NULL);시그널을 안받고 기다렸다가 마스크를 푸는 형태이다.
=== System-Level I/O ===
1. Unix I/O
리눅스에서 파일이라는 것은 m byte의 연속이다.(chunk) 하드 혹은 디스크에 저장된다.
I/O는 터미널, 네트워크, 외부장치에서 데이터를 복제하는 과정을 input/output 이라고 부른다.
input이라고 하면 main memory까지 데이터가 오는 것을 이야기 한다.
output은 main memory의 데이터를 외부장치로 가는 것을 이야기 한다.
파일들을 디바이스로 매핑하면서 결국 커널이 Unix I/O라고 불리는 간단한 인터페이스를 보여줄 수 있게 된다.
File Types
Regular file : 일반적인 데이터를 가지고 있는 파일들(text, binary file)
directory : 각각의 파일들에 대한 포인터 값(파일들의 id번호), 링크들에 대한 배열
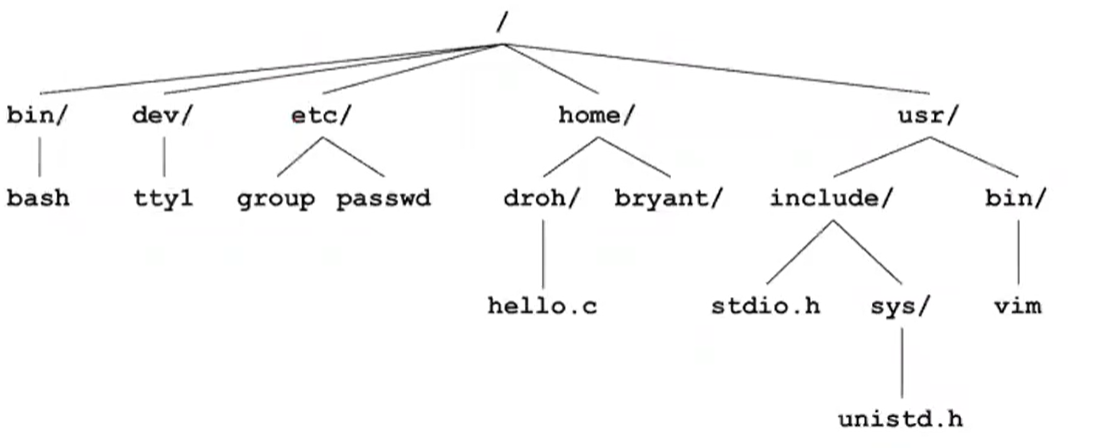
Socket : 프로세스들이 다른 기계들과 통신할때 사용
-
opening files
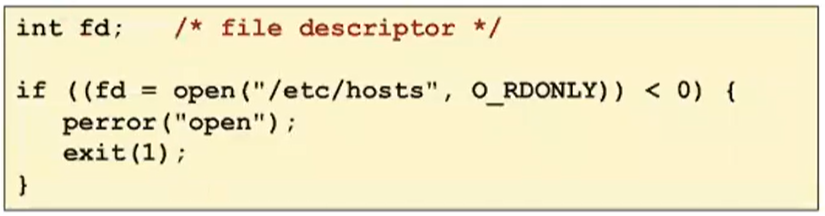
지금부터 파일에 access할거라고 커널에 알려주는 것을 이야기 한다. -
Closing Files

-
Reading Files
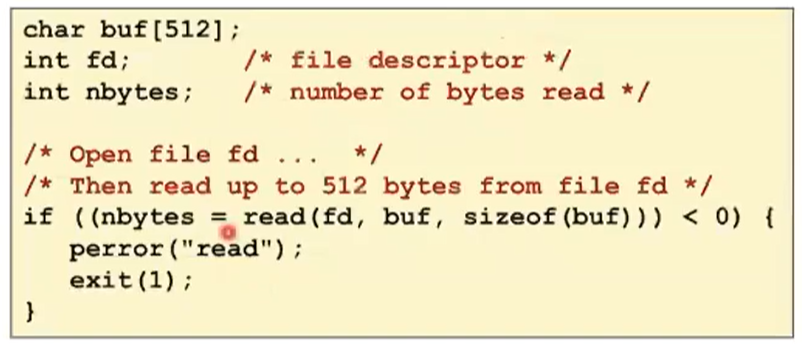
-
Writing Files
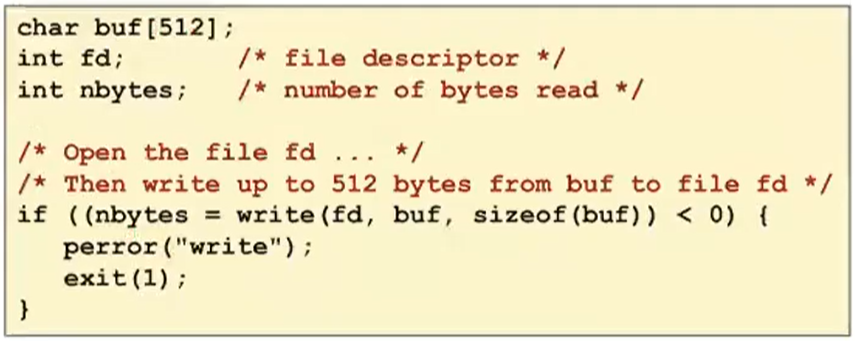
The RIO Package
-
RIO는 Unbuffered I/O, Buffered Input 를 제공한다. network program할때 매우 좋다.
-
Unbuffered RIO Input and Output

-
rio_readn은 우리가 얼만큼 데이터를 읽을지 알때 사용하고 EOF를 만나면 종료한다.
-
rio_readn은 n byte만큼 데이터를 읽는다. 그리고 while을 돌면서 데이터를 읽기 시작한다.
-
Buffered RIO Input Functions


파일이 지금까지 읽었던 buffer을 가지고 있고 그 버퍼가 지금까지 읽었던 바이트와 유저코드에 의해서 읽히지 않은 것을 포함하고 있다.
이걸 언제 쓰냐면 항상 char를 읽는것이 아닌 시스템 콜로 일단 많이 읽어놓은 다음 user code에서 한 바이트씩 천천히 읽어들일때 도움이 될 수 있다
Metadata, sharing, and redirection
-
Flie Metadata
v-node table이라고 해서 실재파일에 대한 meta 정보를 가지고 있다. 내가 어떤 stat 정보를 가지고 넘겨주면 커널이 파일 테이블에서 v-node까지 찾아가서 유저 버퍼에 정보를 넘기어 준다. -
File Sharing
만약 fork를 하게 된다면 child process는 parent process의 open file들에 대한 desciptor table을 복제한다. -
I/O Redirection
dup2라는 시스템 콜을 사용한다. 예를 들어서 dup2(4,1)이라고 해서 ls에서 나오는 output을 foo.txt의 input으로 사용할 수 있게 된다.
2. Standard I/O
standard I/O 함수들은 stream이라고 해서 I/O 모델들이 파일들을 갖다고 stream으로 보고 있고 file desciptor와 메모리의 buffer을 추상화를 해서 사용한다.

- Buffered I/O: Motivation
얘네들은 기본적으로 buffered I/O를 사용해서 overhead가 크다.
3. Closing remarks
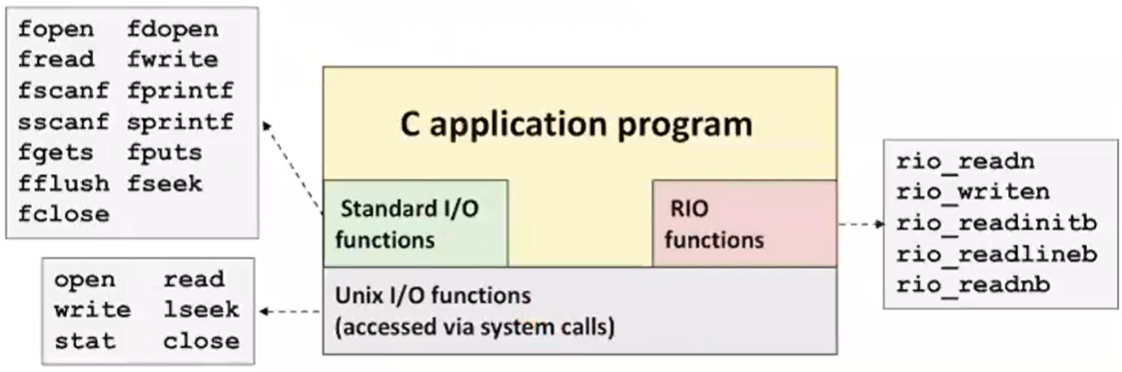
맨밑에 Unix I/O가 있고 그 위에 RIO와 Standard I/O가 올라가 있는 것을 확인할 수 있다. 결국에 Standard I/O는 시스템콜을 기반으로 구현한 라이브러리이다.
RIO를 사용하는 이유는 네트워크 communication을 위해서 사용한다. Standard I/O는 local 데이터를 위해서 사용된다.
-
Pros and Cons of Unix I/O
직접 metadata접근, async-signal-safe하다.
버그 많고 버퍼직접써야한다. -
Pros and Cons of Standard I/O
우리가 직접적으로 read, write를 사용하지 않아서 효율적
metadata 접근 불가능, async-signal-safe 하지 않음, 네트워크 소켓 input, ouput에 부적절
=== Concurrent Programming ===
Concurrent Programming에서 생기는 문제점
- Livelock은 lock을 계속 획득해서 critical section에 들어가기 위해 lock을 계속 요청하는 경우
- Starvation은 내가 critical section에 들어가고 싶은데 다른 프로세스가 이미 들어가 있어서 스케쥴링도 잘못되어서 내가 그 안에 들어갈 수 있는 기회를 계속 놓치어 굶어 주는 경우
- Fairness는 스케쥴링이 되는 순서에 따라서 내가 필요한 만큼의 clock cycle을 받지 못하는 경우
Approaches for Writing Concurrent Servers
concurrent flow를 여러개 만드는 3가지 방법
- Process-based : connection 맺을때마다 parent가 accept하고 child를 띄어준다.
단점은 fork를 띄우면 자원을 굉장히 많이 소모한다.
그리고 프로세스간의 data sharing이 안된다.
- Event-based : Event 기반은 포크를 띄우지 않고 서버 프로세스는 하나만 있다. connfd 또는 listenfd를 포함한 array를 가지고 있으면서 만약에 file descriptor 각각의 뭔가 pending input이 있다는 것을 확인해서 pending input이 있을때 그때에 해당하는 input에 대해서 맞는 action을 수행한다.
select, epoll을 사용해서 file descriptor을 살피어본다.
장점
- 논리적인 control flow가 단 하나이다.
- debugging할때도 단일 address space에 logical control flow도 하나라서 쉽다.
- control overhead가 없다.
- 그래서 고성능 웹서버나 검색엔진에 사용한다.
단점
- 단점은 코딩하기가 복잡하다.
- fine-graind concurrency를 제공하지 않는다.
- 그래서 multi-core 기능을 적극적으로 활용못한다.
- Thread-based : Process-based와 기본원리는 동일하나 각 flow는 동일한 address space를 공유한다.
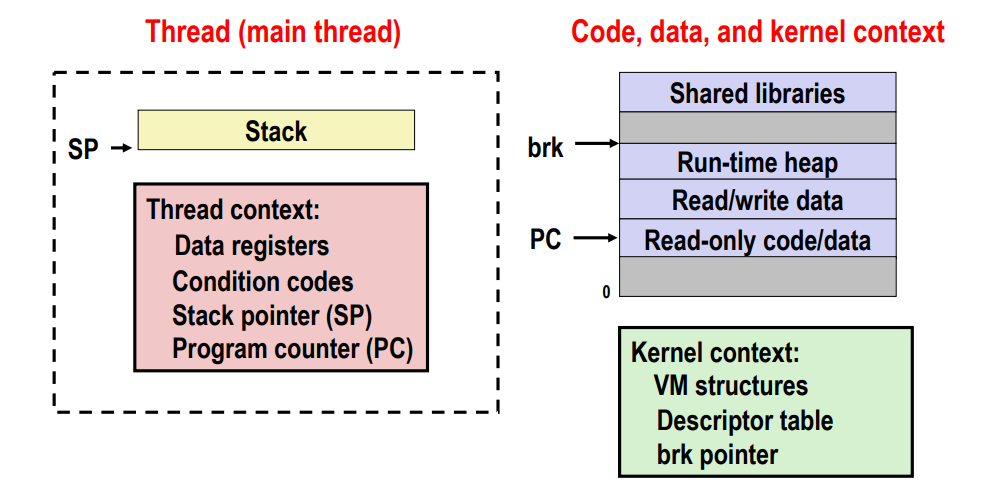
프로세스를 스레드 관점으로 볼 수 있다. program context와 stack을 스레드로 보고 코드 data 부분은 그대로 있고 keren context로 나뉘어진다.
Posix Threads (Pthreads) Interface
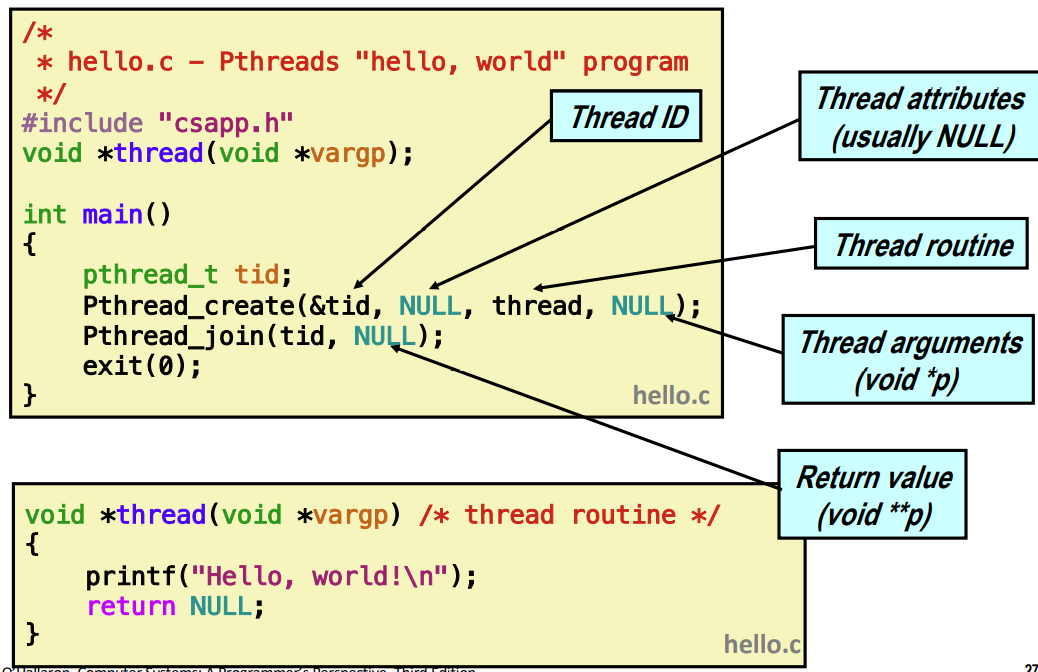
main 함수에서 Pthread_create 하는데 새로운 프로세스를 만드는 것이 아닌 새로운 execution flow를 만드는 거라고 생각하면 된다. 인자로 Thread ID를 받는다. 스레드의 속성, 스레드가 실행할 함수, thread routine이 받는 인자이다.
CPU가 하나라면 각 스레드의 실행 사이의 context swith가 이루어진다.
Thread-Based Concurrent Echo Server
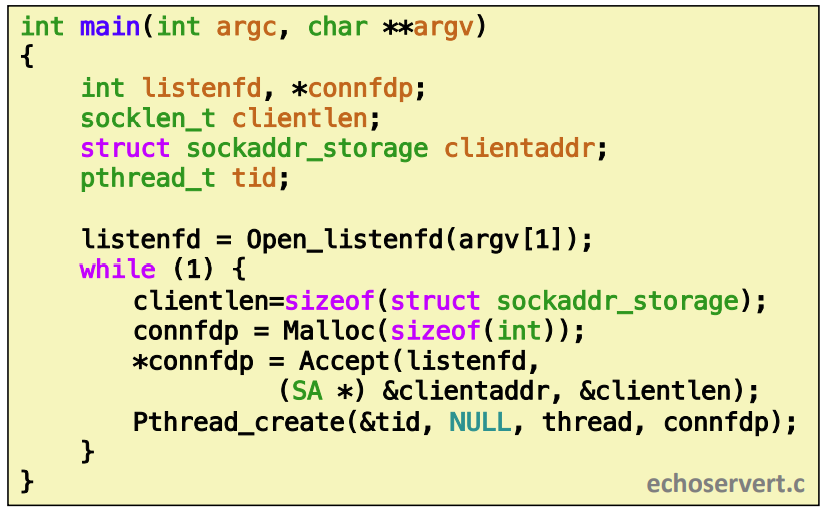
while에서 listen하다가 accept하게 되는데 그때 Malloc으로 connfdp를 하나 만든다. 이건 반드시 해야 한다.
스레드 Accept하고 Pthread_create 해서 thread 함수를 수행하게 한다. 그리고 스레드를 만들어 스레드의 file descriptor을 만들어서 인자로(connfdp) 전달해준다. 그럼 스레드 하나가 만들어진거다.

스레드 안에서는 Pthread_detach모드로 실행한다. 이건 다른 스레드와 독립적으로 하되 이게 termination 되었을때 커널이 자동적으로 reaping해준다.
- Issues With Thread-Based Servers
joinable : 다른 스레드가 그 스레드를 kill할 수 있다.
detached : 다른 스레드가 kill, reap 불가 대신 커널이 자동으로 reap해준다.
Pthread_create(&tid, NULL, thread,(void *)&connfd);sharing을 통해서 문제가 생길 수 있다. 스레드가 생성되었는데 메인 스레드 스택에 있는 변수를 reference할 수 있다.
스레드 기반의 장점 : 스레드들끼리 공유하고 있어서 data share가 쉽다.
context switch overhead도 줄어든다.
의도하지 않은 data sharing이 발생가능
=== Synchronization: Basics ===
Shared Variables in Threaded C Programs
Thread기반은 process와 유사하지만 contect switching도 적고 reaping도 적다는 것을 배웠다.
어떤 변수들이 shared인가? global 변수들은 shared이다. stack 변수들은 private이다.
Synchronizing Threads
쓰레드 동기화하다보면 내가 예상 못한 상황이 생길 수 있다.
변수를 atomic하게 실행할 수 있다면 좋을거 같다.
Progress Graphs
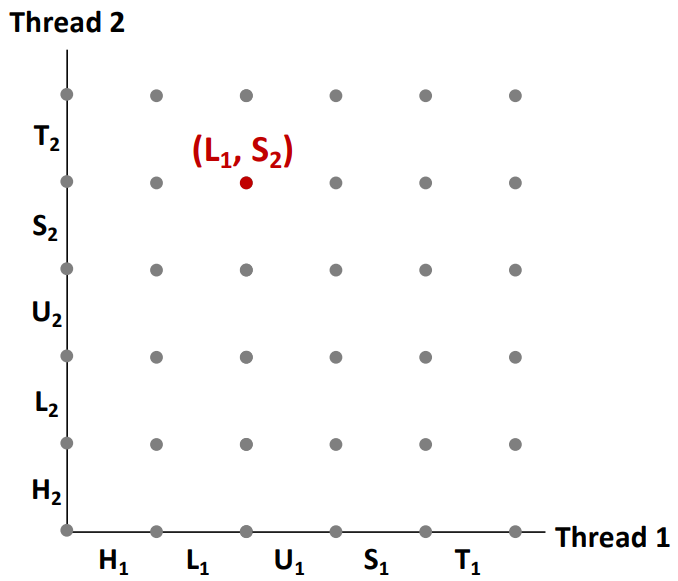
프로세스 그래프 : 스레드 1,2 번이 동시에 실행될때(concurrent) execution state space를 discrete해서 설명하는 공간을 이야기 한다.
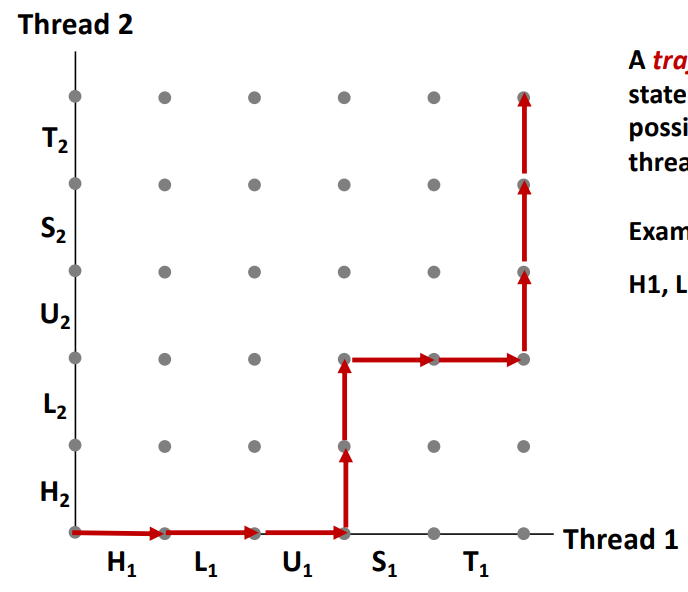
- trajectory : concurrent하게 스레드들이 실행될때 가능한 상태 transition의 sequence를 보고 trajectory라고 부른다.
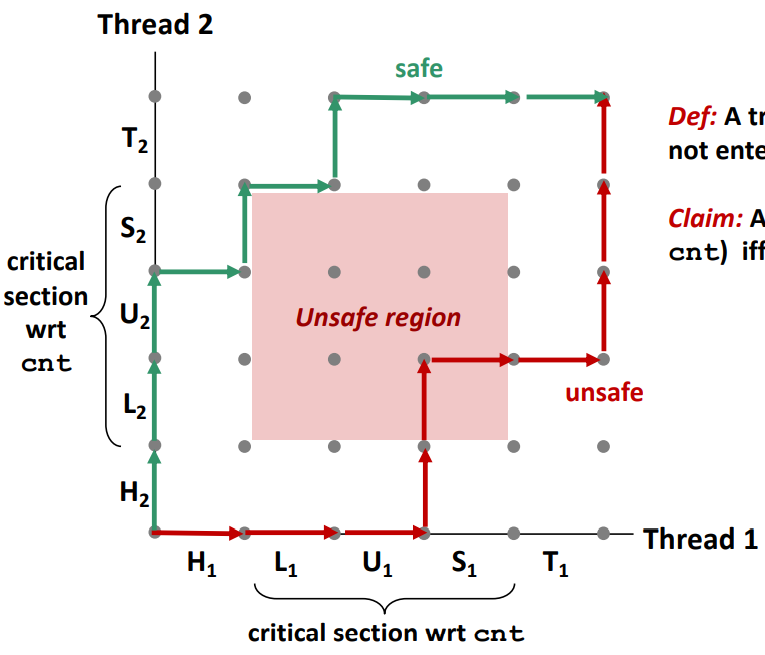
-
하지만 이중에서도 unsafe한 영역이 존재한다. unsafe한 영역은 cnt++ 결과값이 각각 스레드들이 0->1로 나올 수 있는 영역이라고 보면된다. 그 영역을 보고 Unsafe하다 혹은 critical section이라고 부른다.
-
이 critical section에 있는 instruction들은 interleaving이 되지 않도록 동기화하는 것이다. 그래서 mutually exclusive access를 보장해주는 것을 synchronize 하는 것이다.
Semaphores
- 세마포어(Semaphore) : 공유된 자원의 데이터 혹은 임계영역(Critical Section) 등에 여러 Process 혹은 Thread가 접근하는 것을 막아줌(즉, 동기화 대상이 하나 이상)
세마포어는 항상 0보다 크거나 같은 global integer 변수값이다. 이것을 조작할 수 있는 operation은 P(wait, sleep)와 V(signal, wake up)이다.
P는 s라는 변수가 1이라면 우선 s값을 체크한다. 만약 0이 아니라면 값을 줄이고 return한다. P(s)는 모든 스레드가 부를 수 있기 때문에 내가 보았을때 s가 0일 수 있다. 그럼 P를 호출한 함수는 suspend한다. V라는 operation을 통해서 s라는 값을 증가시켜 주기전까지 계속 잠자고 있는다. 그래서 깨어난 다음에는 P함수를 통해서 s값을 줄이고 caller에게 제어권을 돌려준다.
sem_init : sem_t를 val로 초기화한다.
sem_wait, sem_post를 사용해서 스레드를 suspend하고 깨우면 된다.
=== Synchronization: Advanced) ===
Producer-Consumer Problem
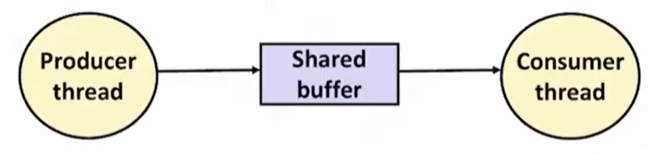
producer-consumer은 생성자와 소비자 문제라고 생각하면 된다. shared buffer은 array로 된 버퍼로 하나씩 채워나간다. producer입장에서는 계속 채우다가 array가 full되면 중단한다. consumer은 array가 empty가 아니면 계속 소비한다.
producer, consumer은 n개의 element buffer을 가지고 있다.
counting semaphore은 slot이 몇개가 있느냐 즉 buffer에 몇개가 남아있는지를 카운팅한다.(Producer)
item은 buffer에 아이템을 몇개의 아이템을 집어넣었는가를 카운팅한다.(Consumer)
- Readers-Writers Problem
문제는 object를 여러 스레드가 read, write하고 있다. Writer 입장에서는 그 object를 배타적으로 접근해야 한다. 무조건 자기혼자만 써야 한다.
만약 누군가가 read하고 있다면 무한대로 읽을 수 있다.
reader에게 우선순위를 주는 것이다. 아무도 안읽고 있을때는 writer가 쓸 수 있다. reader는 계속해서 오는 reader들이 읽을 수 있다.
writer에게 favor을 주는 방향은 누군가가 쓰고 있다면 그것을 빨린 끝내게 하는 것이다. 그래서 writer에게 favor을 주는 방법이다.
하지만 두개다 starvation문제가 존재한다.
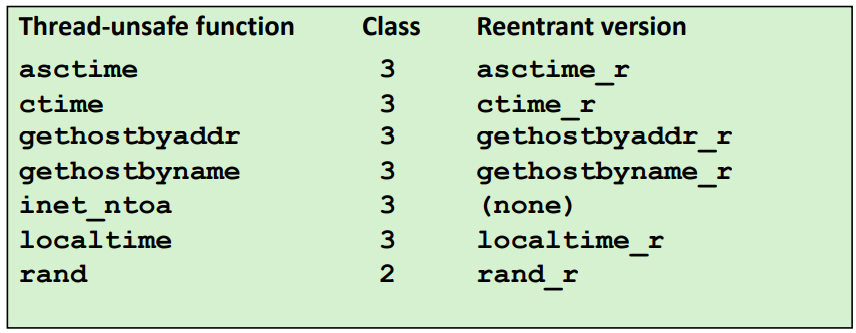
Crucial concept: Thread Safety
스레드로부터 호출되는 함수들은 thread-safe해야 한다는 개념이다.
스레드 unsafe 한 함수를 4단계로 나누었다.
class1 : shared variable을 protect 하지 않는 변수(공유변수를 같이 sharing할때 mutex lock으로 잡아주지 않는 경우)
class2 : 스레드들이 함수를 계속 호출하는데 호출할때마다 상태를 계속 기억해야 하는 함수들을 이야기 한다.
class3 : return value가 static variable이다. 그래서 스레드들이 static variable의 pointer을 반환하는 경우이다.
class4 : thread-unsafe 함수를 호출하는 경우이다.
Reentrant Functions
재진입이 가능하다 = 여러 스레드가 이 함수를 호출하는데 스레드간의 shared variable이 전혀 없는 것을 reentrant하다고 부른다.
Reentrant function과 같은 경우는 synchronize가 필요하지 않다. 왜냐하면 shield variable이 전혀없기 때문이다.
One worry: Races
어떤 스레드가 다른 스레드가 도달하기 전에 누가 언제 어떤 순서로 접근하는지에 따라서 순서를 보장할 수 없기 때문에 correctness를 보장할 수 없다. 이런경우를 보고 race가 발생한다고 이야기 한다.
이를 해결하기 위해 main thread에서 malloc을 해서 heap space을 사용하는 것이다. 그리고 ptr의 값을 넘기는 것이다.
Another worry: Deadlock
Deadlock이 생기었다는 건 여러스레드가 이 프로그램을 실행하고 있는 것이다. 스레드가 조건을 만족못해서 진행못하는 경우이다.
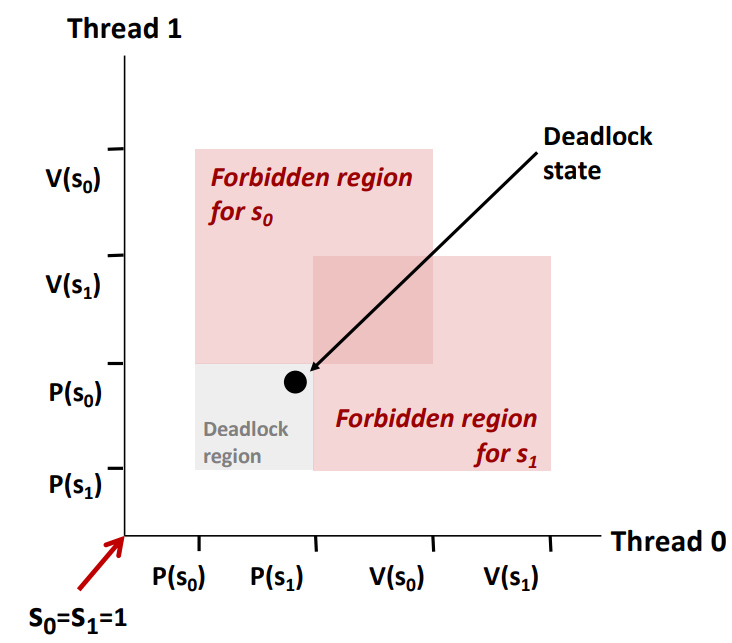
스레드0의 세마포어 0과 스레드1의 세마포어 1번을 차지하여 다른 스레드가 접근하면 안되는 상황이다. 하지만 위의 그래프를 보면 진행방향에 이미 deadlock이 있어서 접근이 불가능하게 된다.

그래서 해결하는 방법이 thread의 P함수를 쓰는 부분의 순서만 바꾸었다.
=== Thread-Level Parallelism ===
Hyperthreading이 가능하다면 CPU가 여러개의 코어를 가진것처럼 보인다.
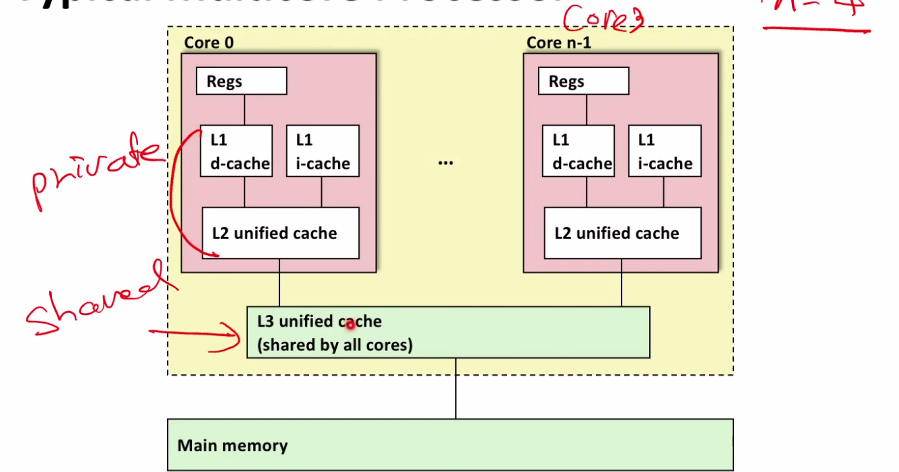
L1, L2 캐시는 private cache, L3는 shared cache라고 부른다. 보통 메인메모리는 DRam으로 만들고 L3는 SRam으로 만든다. reg에 가까울 수록 latency가 빠르다.
- Benchmark Machine
/proc/cpuinfo
OS안에서 관리하는 하드웨어 정보를 이 파일 안에 저장하고 있다.
psum-local Performance
p는 프로세서의 코어이고, Tk는 k개의 코어를 사용할 경우 사용시간을 이야기 한다.
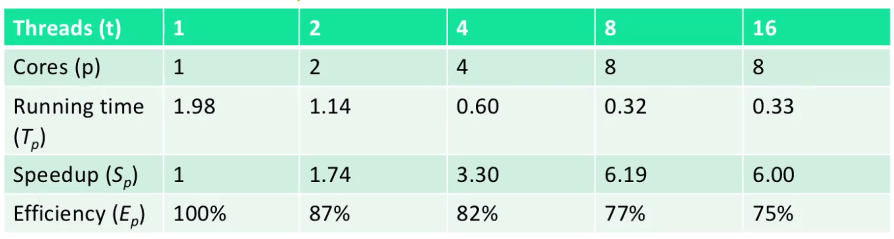
Sp = T1/Tp
Sp는 T1이 1코어로 병렬로(p개로) 움직일때의 상대적인 작동시간이다.
혹은 Sp는 T1dl 1코어로 순차적으로 움직일때 절대적인 작덩시간이다.
Ep = Sp/p = T1/(p * Tp)
병렬작동시의 overhead를 계산할 수 있다. (0...100] 사이이기 때문에 100에서 Ep로 나온 값을 뺀것이 곧 overhead값이다.
Memory Consistency
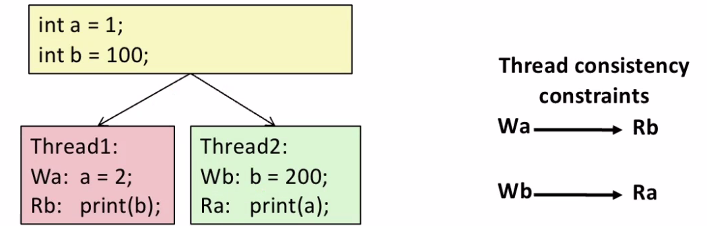
실행 순서에 따라 결과가 크게 달라진다.
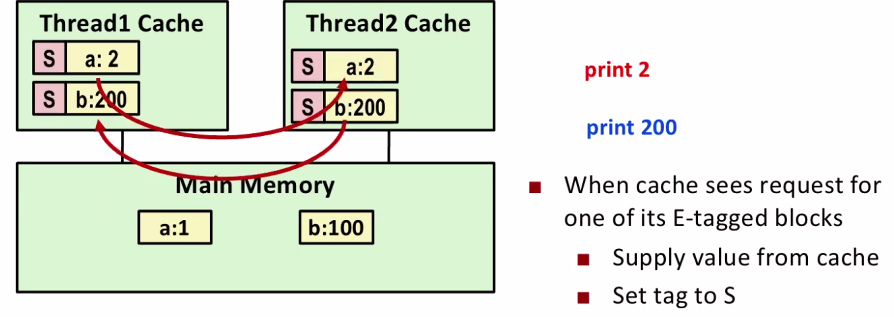
- snoopy caches : 각각의 cpu에서 돌아가고 있는 메모리에 tag를 붙이는 거다. 스레드 2번이 1번을 접근하는 경우 스레드 2번이 다른 cpu의 값을 읽을때 E->S로 바꾸어서 값을 복사해온다.
값이 바로 복사 되는 것이 아닌 어느정도 overhead가 있지만 그럼에도 불구하고 이 방식을 사용한다.
Network Programming
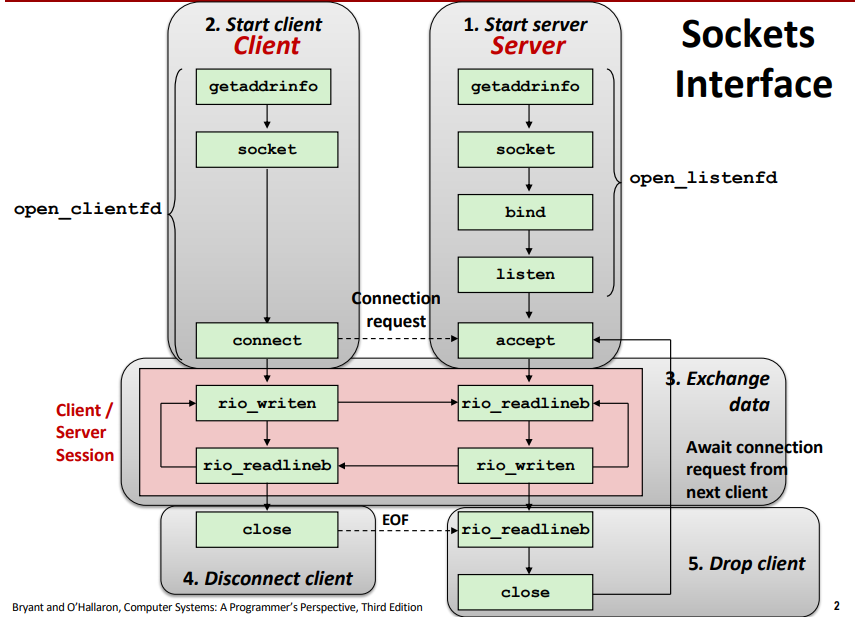
getaddinfo를 호출하면 ip와 port번호를 가지고 온다. socket 만들고 bind를 통해서 만들어진 소켓을 가지고 listen한다. listen은 서버가 클라이언트로 부터 오는 정보를 받겠다는 것이다. 여기에서 client가 connection request를 하게 되면 accept를 함수를 통해서 그 connection을 establish한다. 클라이언트와 메세지를 주고 받을 수 있게 된다.
client
getaddrinfo를 통해 ip와 port번호를 가지고와 socket을 만들고 connect으로 connection request를 보낸다. 그럼 서버에서는 connection request를 커널안에 있는 tcp mannager에서 connection을 queueing한다. 거기에서 accept해서 client와 서버의 connection이 build된다.
이 상황에서 rio_readlineb로 버퍼리드로 무언가 오기를 기다린다. 클라이언트는 write한다. 서버쪽으로 메세지가 날아가 서버에서 그 데이터를 읽고 서버에서는 그 데이터를 소켓을 통해서 writen으로 쓰기를 하고 서버는 다시 realineb로 간다.
client는 writen하고 서버에서 데이터가 오기를 기다리다가 화면에 쓰고 다시 writen으로 온다.
close를 하면 결국 서버단에서도 닫게 된다.
만약에 다른 client의 요청이 드어오면 다른 client는 계속 기다려야 한다.
