More on Digital Circuits
Binary Addition
- 가산기
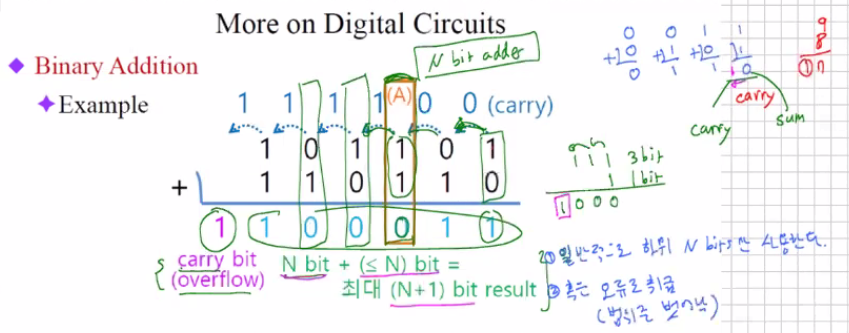
캐리를 저장해서 프로그래머에게 알려주어야 한다. 그러면 프로그래머가 일반적인 N bit인지 혹은 오류인지를 알아서 판단해서 프로그램을 짜준다. 그래서 이러한 carry를 저장하는 것을 flag라고 부른다.
- 전가산기

위와 같이 전가산기의 표현 하기도 한다.
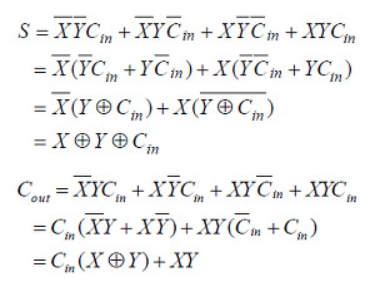
이때의 불 함수는 위와 같이 표현한다.
- 진리표
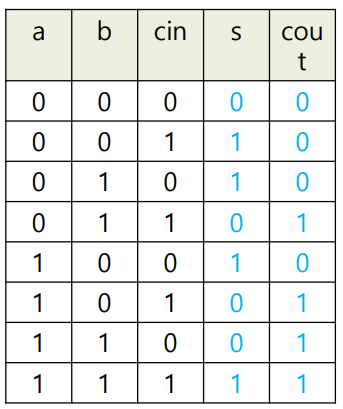
이때의 불 함수를 다르게 표현해보면
S = (a+b+Cin)%2 (2로 나눈 나머지)
cout = (a+b+Cin)/2 (정수 나눗셈, 2로 나눈 몫)
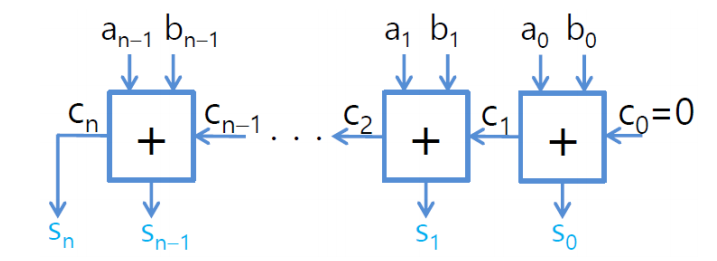
N bit 전 가산기로 입력에 대한 결과가 나오는데 까지는 델타만큼 필요. 왜냐하면 캐리가 나와야 하기 때문이다.

그래서 fast adder structure가 필요하다.(computer arithmetic)
이때 나온 Carry out은 프로그래머가 프로그램으로 처리한다.
-
Software Simulation
-
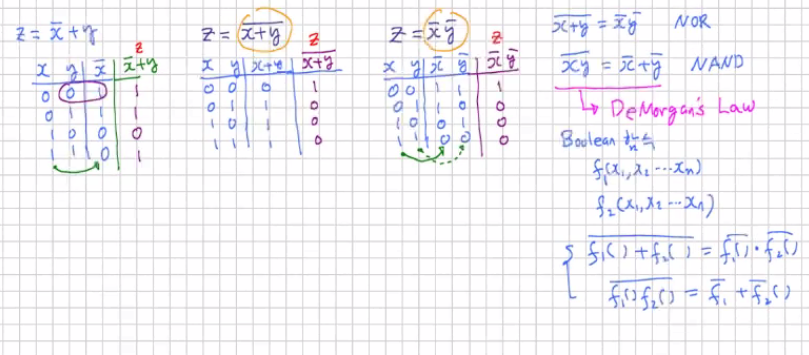
진리표로 부터 sum과 carry에 대한 Boolean expression을 얻는다.
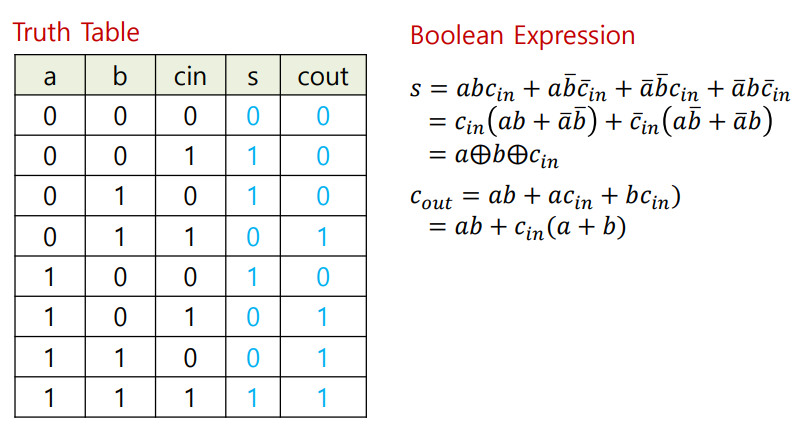
-
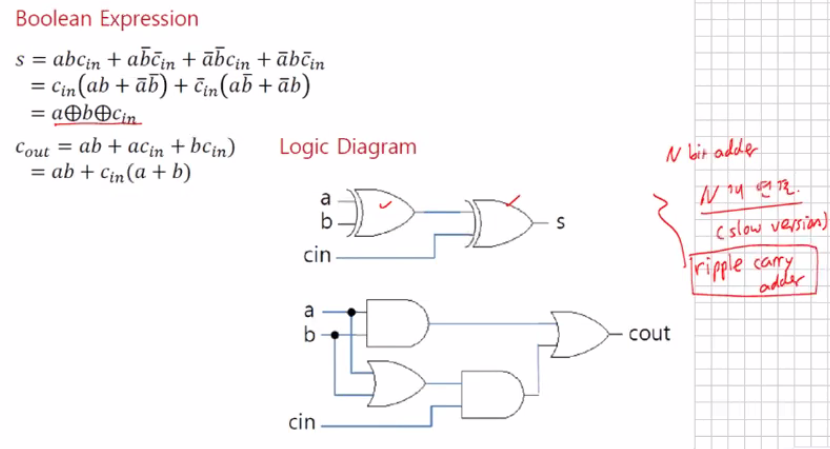
회로를 구현한면 아래와 같이 구현할 수 있다.
기억 장치
- SR 플립플롭
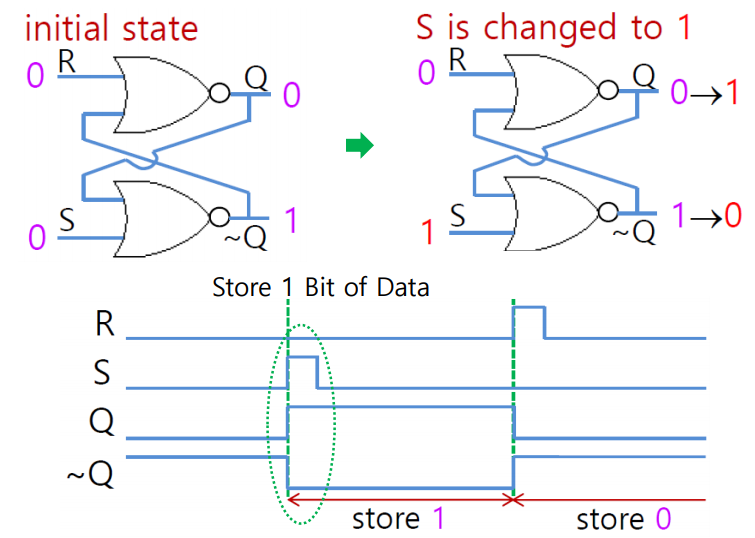
S가 1이면 Q가 1이 되어 1을 저장하고 있는 상태라고 부른다.
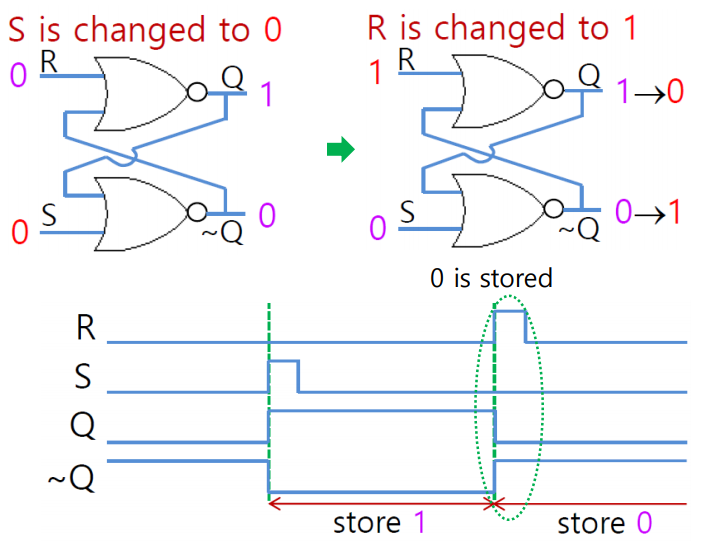
반대로 R이 1이 되면 Q가 0이 되고 ~Q가 1이 되어 0을 저장한 상태라고 부른다.
- Edge Triggered Flip Glop(D flip flop)

CLK가 rising edge에서 D 값을 Q에 저장하는 플립플롭이다.
R이 따로 저장되어 있어서 active(1 또는 0)이면 Q가 0으로 저장된다.
특이하게도 EN이 있어서 EN이 1일 때만 값이 저장될 수 있다.
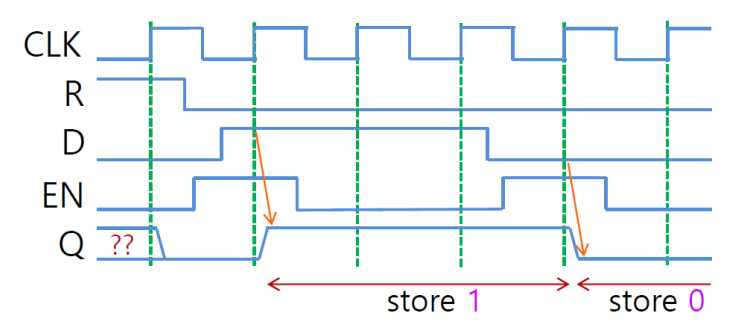
처음의 Q는 무슨 값인지 알 수 없다.
매 클럭 라이징마다 D 값에 따라서 Q 값이 바뀌게 된다.
하지만 EN이 0이면 D값이 아무리 바뀌더라도 Q 값을 바뀌지 않는다.
- Register
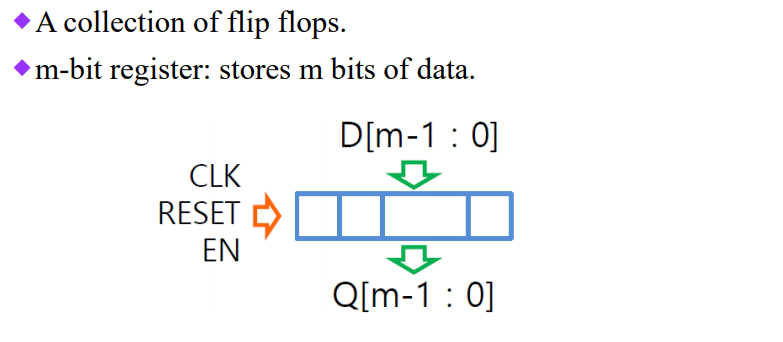
플립플롭은 1bit만 저장하기 때문에 효율성이 떨어진다. 그래서 n bit를 저장하기 위해서 레지스터를 개발하게 되었다.
이때 여러개의 레지스터를 또 묶으면 레지스터 파일이 된다.
플립플롭 < 레지스터 < 레지스터 파일
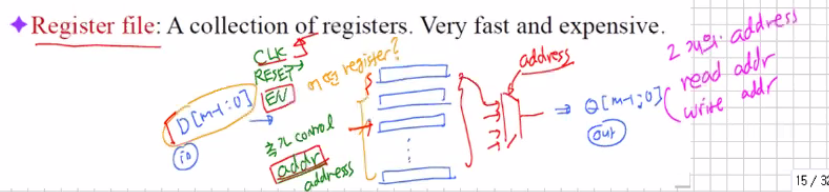
추가로 control addr address가 입력된다. 이때의 address도 read addr과 write addr이 존재한다.
-
Memory
레지스터로도 부족한 공간은 메모리라는 특별한 구조의 저장공간을 제작하게 된다. cost/bit가 아주 낮게 제작된 기억장치이다.
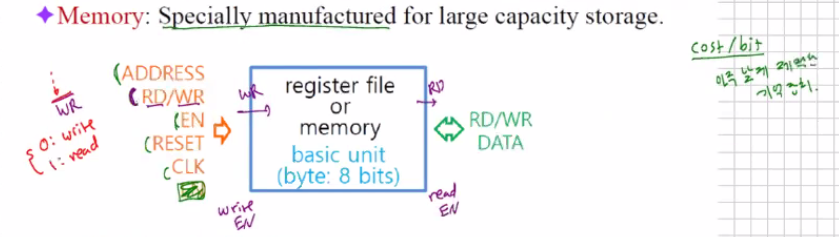
EN 역시 Write EN과 READ EN이 존재한다.
RD/WR도 0 또는 1로 write와 read를 구분한다.
이때의 메모리는 8bit이다.- On-chip and off-chip 메모리
On-chip : CPU안에 존재하는 칩(빠르지만 비쌈)
Off-chip : CPU 밖에 존재하는 칩(느리지만 쌈) - Static and dynamic 메모리
Static : 파워가 없어도 데이터를 저장한다.
Dynamic : 시간이 지나면 데이터가 없어진다.(주기적으로 dummy read) - Size of 1M memory
메모리의 기본 단위는 8 bit
1 M byte = address size : 20bit(2^20 = 10^6)
(8 + a) x 10^6 플립플롭
a : 에러와 정상상태를 확인하기 위한 추가 비트
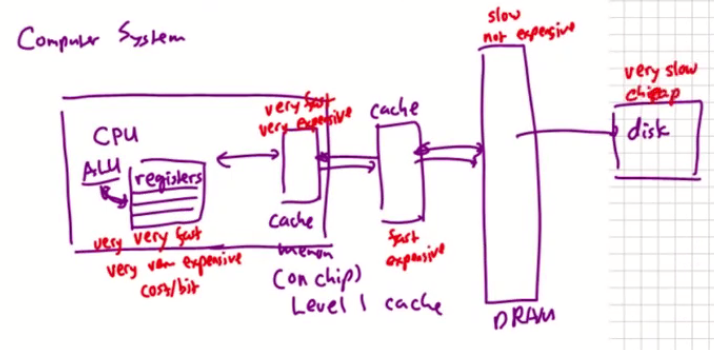
그래서 컴퓨터 시스템을 만들면 위와 같이 각 부품별로 속도와 가격이 결정된다.
- On-chip and off-chip 메모리
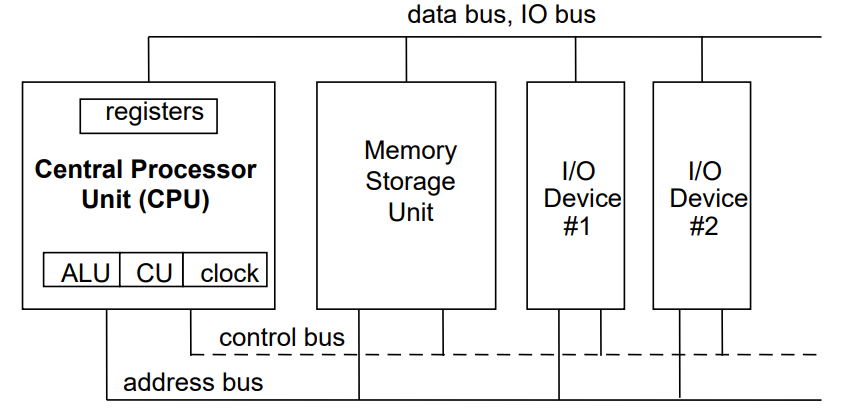
Computer Systems
System BUS
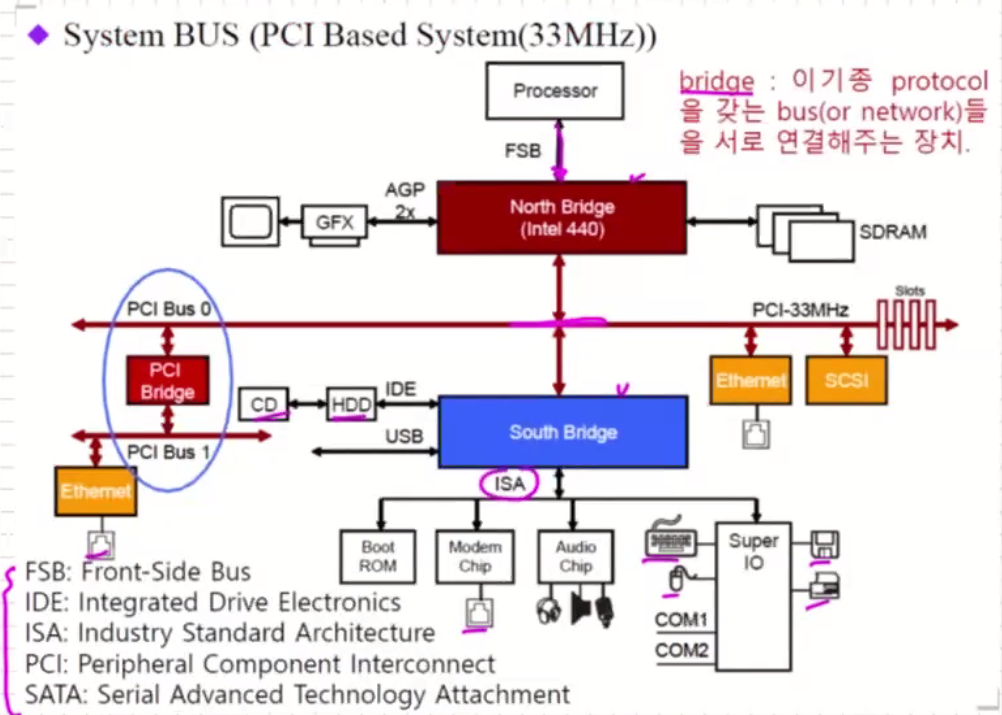
bride : 이기종 프로토콜을 갖는 bus들을 서로 연결해주는 장치
Intel Pentium CPU
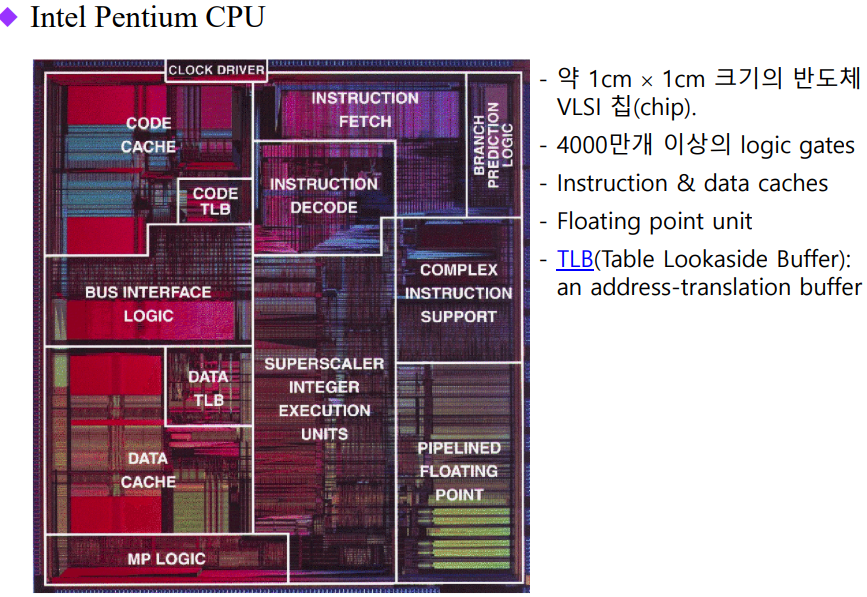
ALU는 덧셈연산만
VLSI (Very Large Scale Integration) -> ULSI(Ultra Large Scale Integration) -> SoC(System On Chip)
으로 점차 CPU가 연산하는 크기가 커지며 다른 기능들도 부가적으로 추가중)
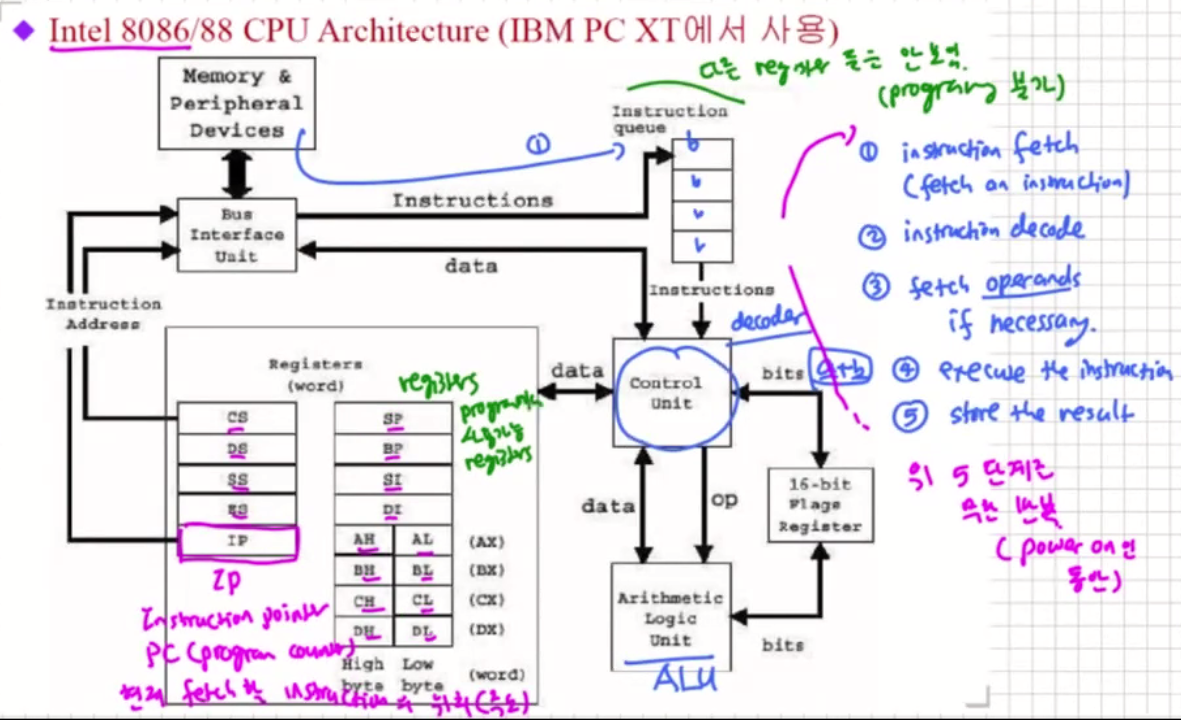
Simplified CPU Block Diagram
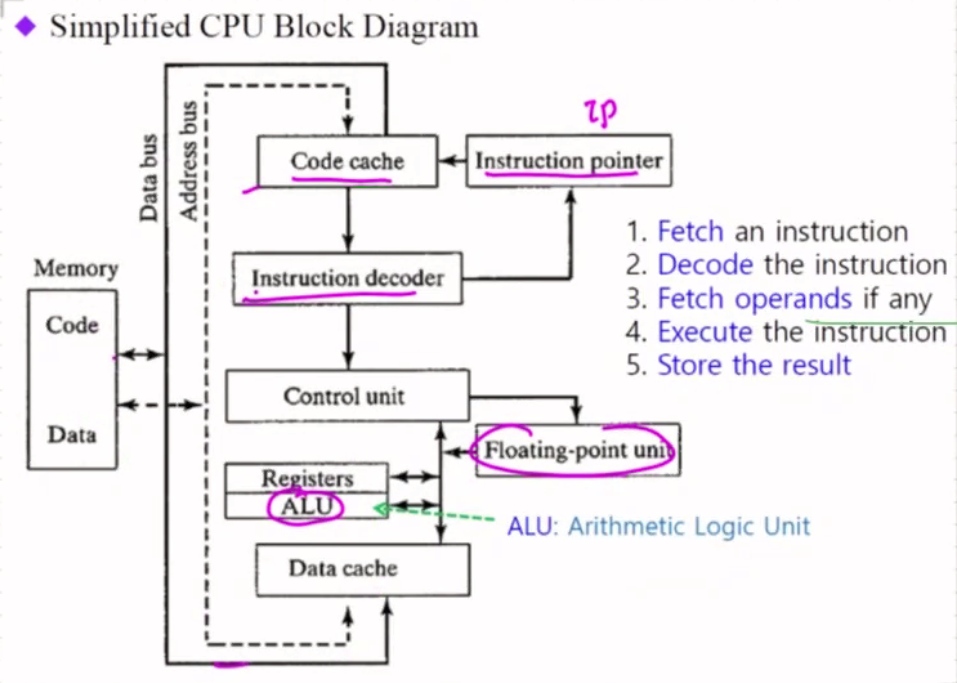
결국 CPU가 하는 것은 오른쪽의 5가지를 계속 반복한다.
Instruction Execution Cycle
http://www.cs.uwm.edu/classes/cs315/Bacon/Lecture/HTML/ch05s06.html
위에서 instruction execution cycle에 대해 자세하게 나와있다. Intel CiSC(Complex instruction set computer)
실제 CPU는 보다 복잡한 단계를 가질 수 있다.
Generic RISC 컴퓨터의 경우 다음과 같은 Instruction Execution Cycle을 가진다.

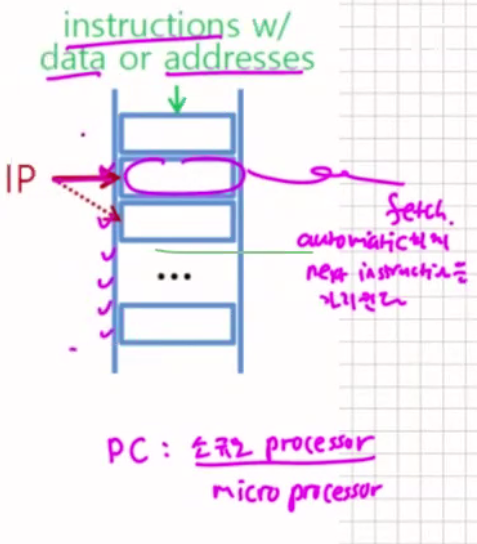
(Instruction Pointer)IP
PC와 같은 기능으로 현재 수행해야할 instruction 주소를 저장하고 있다.
Contro; instruction을 통하여 원하는 ㅑㅜㄴㅅ겿샤ㅐㅜwnthfh qusrud rksmd
Operations Inside he CPU
-
Data Movements(가장 자주 이용)
레지스터.매모리 -> 레지스터/메모리 -
Arithmetic
+, - 등등 -
Logical Operation
NOT, AND, OR -
Program Control
if, for, while -
Input/Output (usually use IO library)
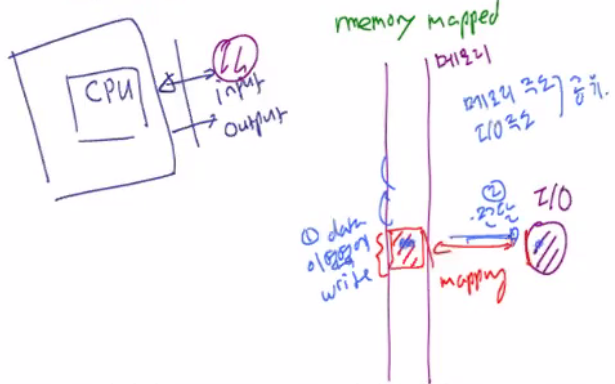
- Memory mapped : IO operations은 같은 memory operations의 주소를 사용한다.
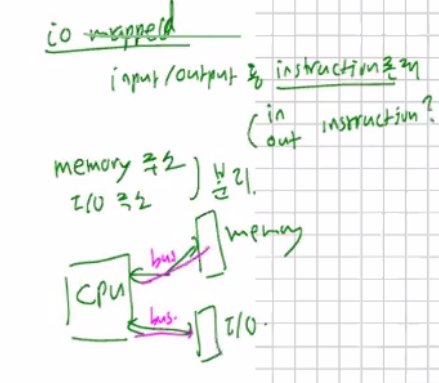
- IO mapped
input/output용 instruction 존재, memory주소와 I/O주소 분리
- IO mapped
How a Program Runs
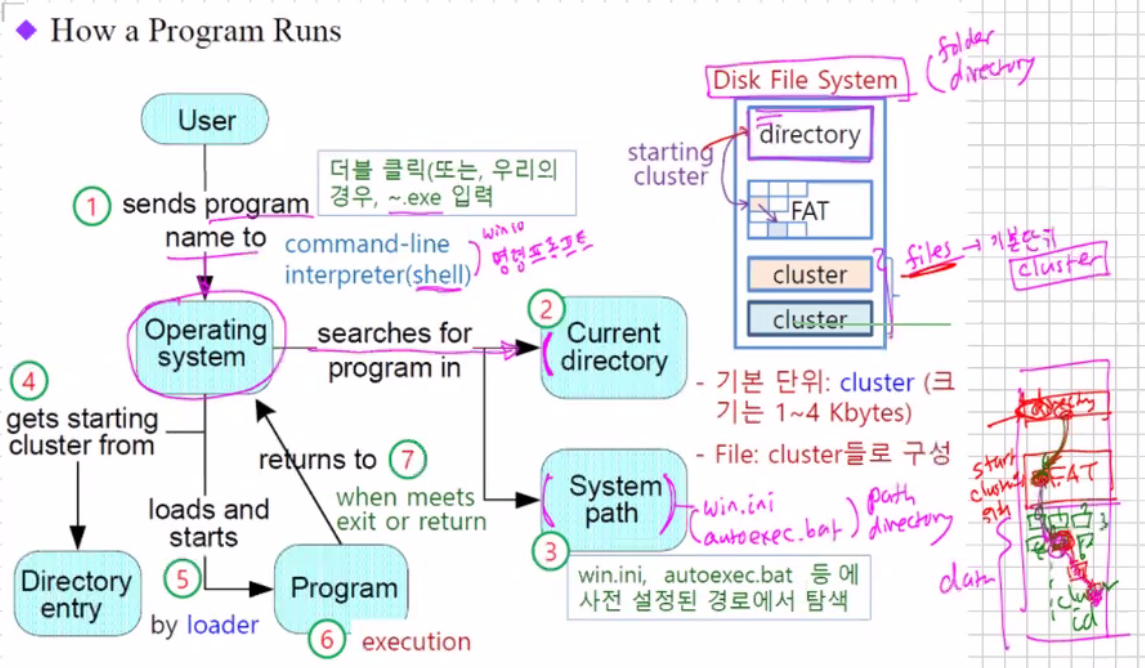
Clock
CPU를 동작하는 원동력으로 instruction 한개를 수행하는 기간 = Machine cycle은 1개 또는 그 이상의 clock cycle로 구성
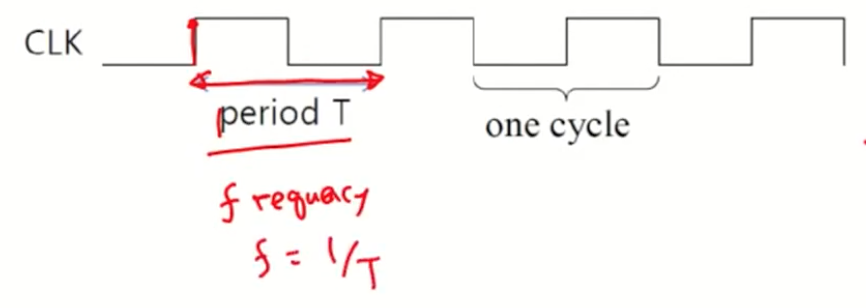
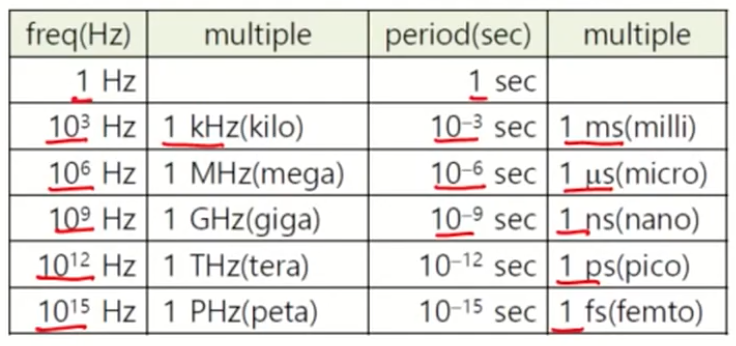
- Frequency : 초당 반복 회수 (f(Hz) = 1/T(sec))
Machine Instructions
- Machine Instructions : CPU가 해야 하는 일을 지정해주는 Statements

Op-cde : operation code. 실제 해야할 일
Operand : data 또는 데이터의 주소를 저장하고 있다.
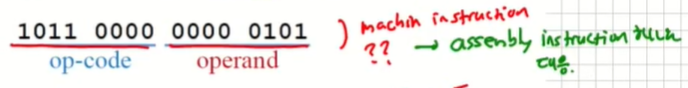
실제로 위와 같이 구성된다. 현재는 알아보기 힘들지만 나중에 assembly instruction 하나로 대응된다.
-
Program : A sequence of machine instructions 이다. 하지만 그냥 짜기가 힘들기 때문에 assembly instruction directive로 작성한다.
C program 또는 higher level program으로 작성한다면 compiler/interpreter가 직접 machine instruction으로 바꾸어 준다. -
Symbolization of Machine Instructions

위와 같이 machine instruction은 Mnemonic(네모닉)으로 변경되고 operand 부분도 변경된다. 이떄 al은 op code에 내재되어 있다.
Speed Up using a Pipelined System
- Pipelined System Comcept(by an Example)
공장자동화에서 분업과 개념이 같다.

- 성능 평가를 위한 정의
Latency : task 하나를 완료하는데 필요한 시간
Throughput : 단위 시간당 완료하는 task 개수
T를 5명의 일꾼들이 분담하여 처리하는 경우
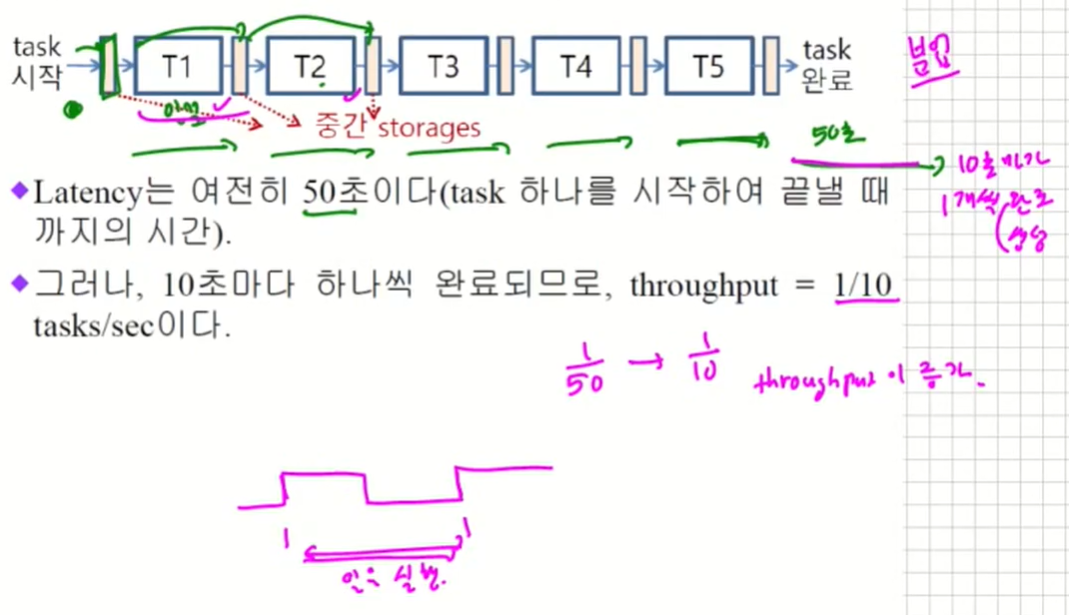
Multi-Stage Pipelined Instruction Processing
-
pipelining은 instruction의 실행을 병렬로 하기 때문에 보다 효율적으로 작동한다.
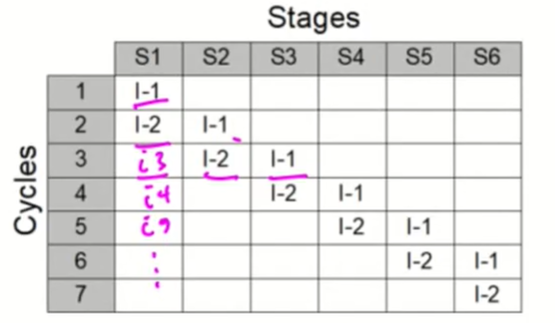
Latency는 여전히 6이지만
Throughput은 1이다.
총 k + (n - 1)의 사이클이 필요하게 된다. -
반면 non-pipelined processor은 많은 cycle을 낭비한다.
총 kn 시간이 걸리게 된다. -
Task를 작은 Stage로 나누어 수행할 때, 각각의 완료에 필요한 시간이 가능한 균등하게 배분되도록 나누어야 한다.
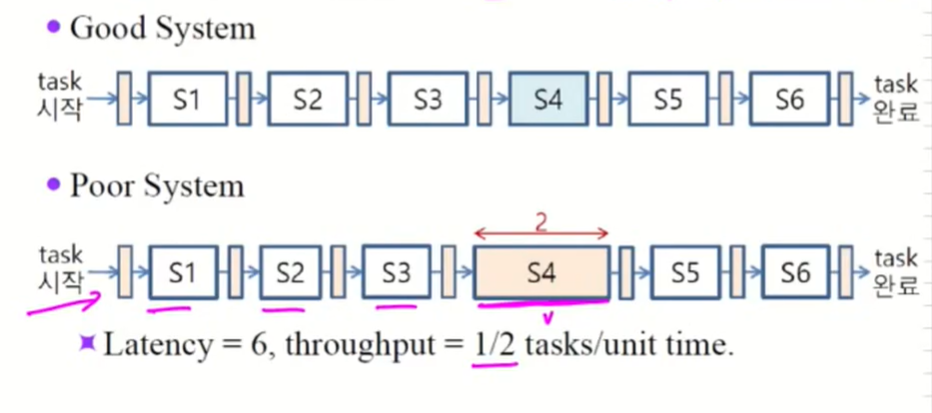
중간에 S4가 2가 걸리어 버리면 7, 1/2가 걸린다.
Wasted Cycle
만약 중간에 clock cycle을 많이 소모하면 전체 clock cycle이 버려지게 된다.
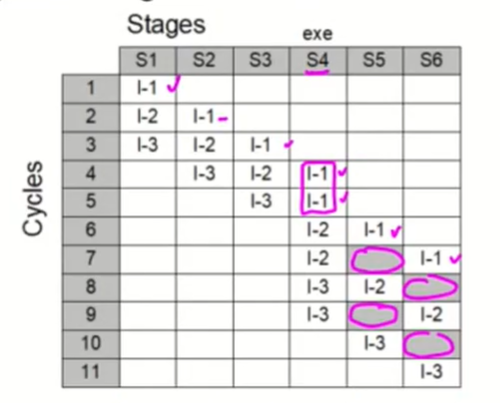
k+(2n-1)
Superscalar
위의 문제를 해결하기 위한 방법 : 모듈을 두개로 나누어서 사용한다.
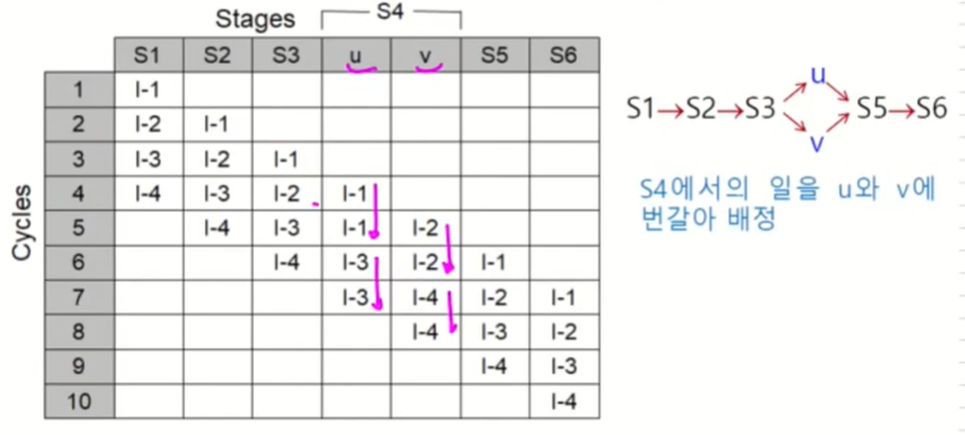
k+n의 시간이 걸린다.
Pipeline Hazard
Pipelined 시스템이 최고 성능을 발휘하기 위해 모든 stage가 멈춤 없이 계속 일을 수행하여야 한다.
그러나 resource 충돌(같은 자리에 write), branching 등의 이유로 pipeline이 연속으로 동작할 수 없는 경우를 pipeline hazard라고 한다.
이 문제는 컴퓨터의 성능을 저하시키므로 이에 대해 많은 해결 방법이 존재
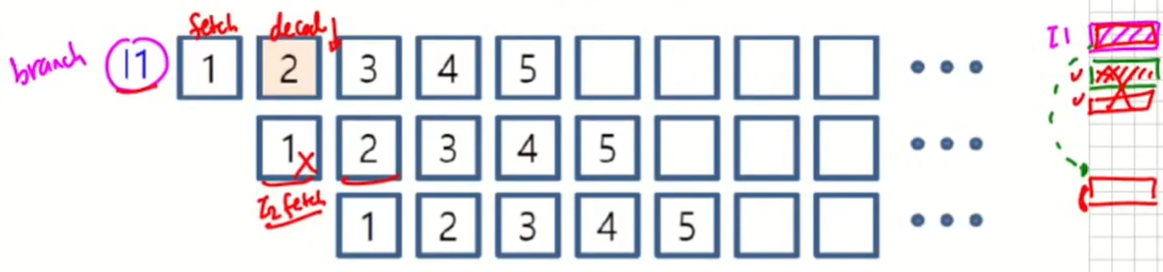
위와 같이 instruction을 fetch하여 decode 해보니 branch인 경우 그 다음 instruction이 의미가 없기 때문에 pipeline의 동작을 잠시 멈추고 I2 다음 instruction을 실행하게 한다.
More on Memory
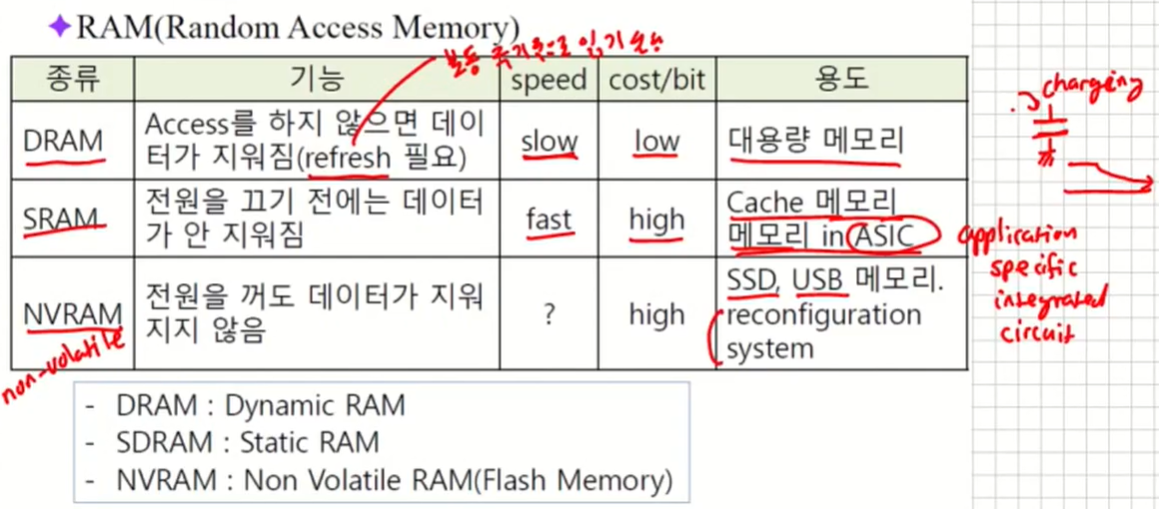
ROM(Read Only Memory)
읽기만 할 수 있는 메모리
PROM : Programmable ROM
EPROM : Erasable PROM(삭제 가능) - 자외선을 쐬면 지워진다.
EEPROM : Electrically Erasable PROM(전기적으로 삭제 가능한 PROM) - 지우는 속도가 상당히 느리다.
Single (Dual) Port Memory
- Single Port Memory : 읽기 쓰기 port가 한 개인 메모리
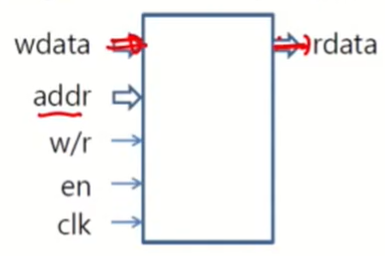
- Dual Port Memory : Port가 두 개인 메모리
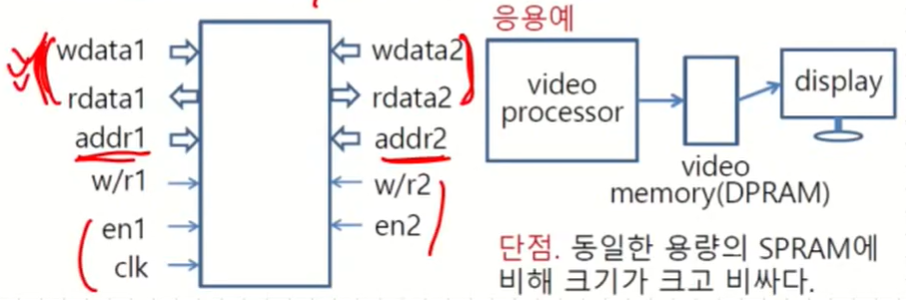
동시에 같은 장소에 data를 쓰고자 하는 경우 문제가 생긴다. 이때는 우선순위를 정한다.
Reading from Memory
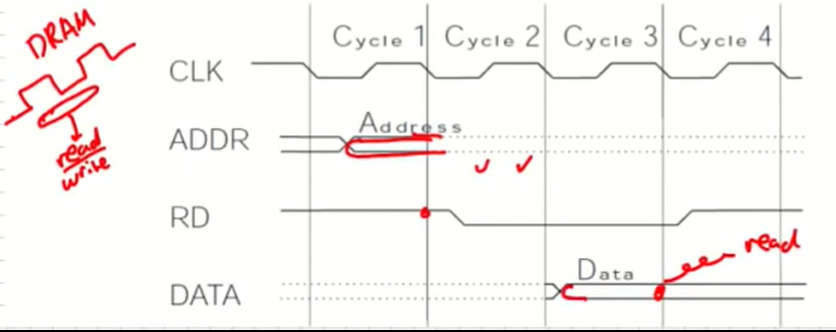
접근하더라도 waiting clock이 존재한다. 이때의 waiting clock이 컴퓨터 성능을 결정한다.
Locality of Reference (the Principle of Locality)
프로세스가 메모리에 있는 것을 fetch-execute 할때 일정 범위내에서 다음 instruction을 실행한다.
- reference locality
- Temporal locality : 최근에 읽은 아이템을 다시 읽는 경향이 크다.
- Spatial locality : 근처를 읽을 경향이 크다.
- Sequential locality : 데이터를 순서대로 읽을 경향이 크다.
- 90/10 rule
코드에서 10%로 되는 부분에서 90% 실행 시간소모한다.
비록 프로그램이 쭉 나열되어 있다고 하더라도 특정부분을 계속 access한다.
Cache Memory
principle of locality로 인해 일부분의 데이터만 가지고 있으면 된다는 것이다.
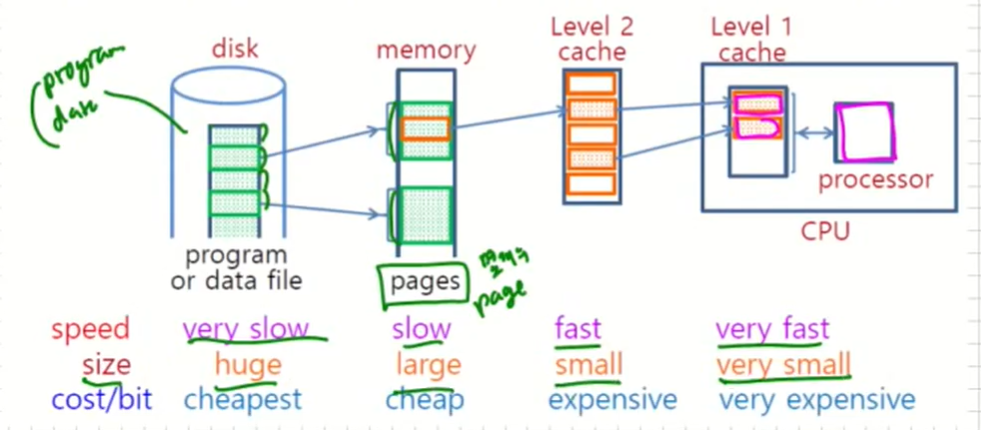
program을 작성할때 가급적 작은 loop에 작성해야 한다.
컴퓨터 기술은 느리고 빠른놈들 사이의 싸움이다.
Multitasking
scheduler utility가 CPU에 프로그램별 작동시간을 할당하여 반복 작업하도록 한다.

VLIW(Very Large Instruction Word) Processor
하나의 instruction 안에 sub-instructions들로 구성하여 동시에 작동하는 방법이다.
digital이나 multimedia processing에 유용하다.
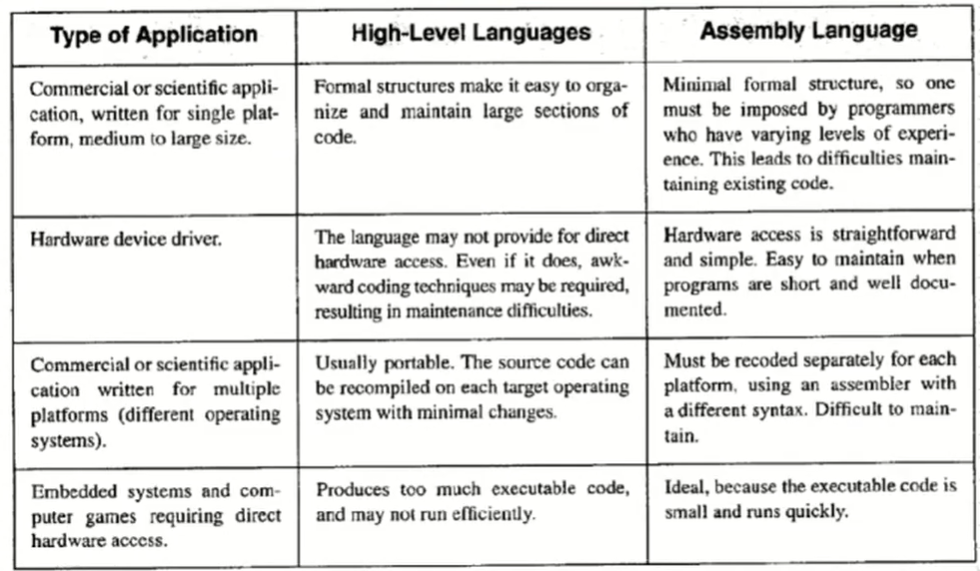
어셈블리 언어의 필요성을 이해하도록 하자
Number Representation
Numbers in Computer
항상 2진수를 사용한다.
이진수는 사전 약속에 의하여 여러 용도로 사용할 수 있다.
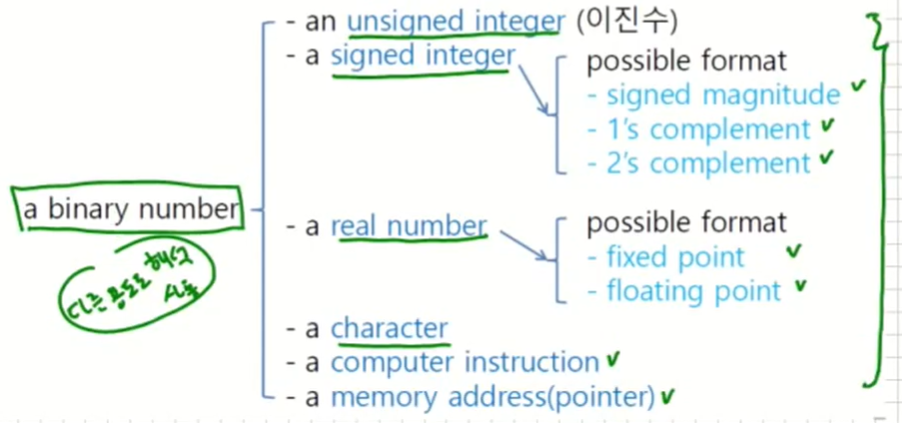
이진수 리스트 만으로는 아무런 의미가 없기 때문에 우리가 의미를 부여해야 한다.
Decimal Numbers(십진수)
radix 10 number라고도 부른다.
10,2,7 등을 radix 또는 base 라고 부른다.
자주 사용하는 용어
-
이진수의 경우
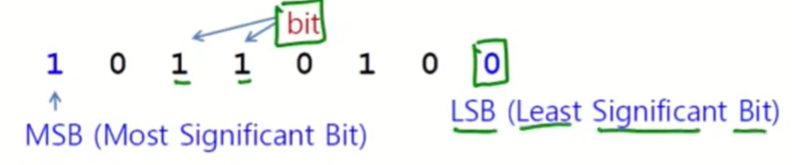
8bit : a byte(컴퓨터) or an octet(통신)
8 bit 이상 : 일반적을 word라고 부름(시스템에 따라 다름)

-
이진수가 아닌 경우
각 자리수를 digit라고 부른다.
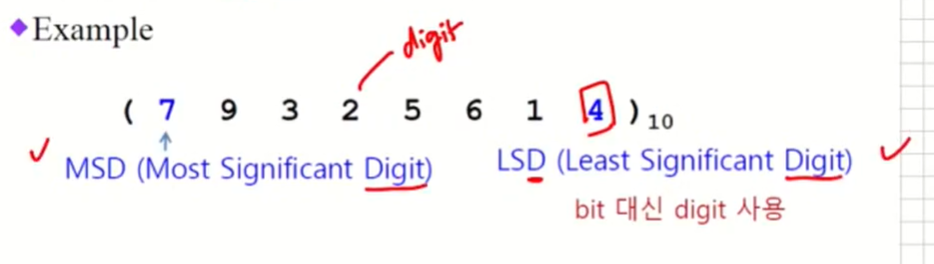
-
Hexadecimal Numbers(16진수)
Win32에서는 주소에 32비트가 필요하다. -> 이때 각각 4비트씩 묶어서 16진수로 표시한다.
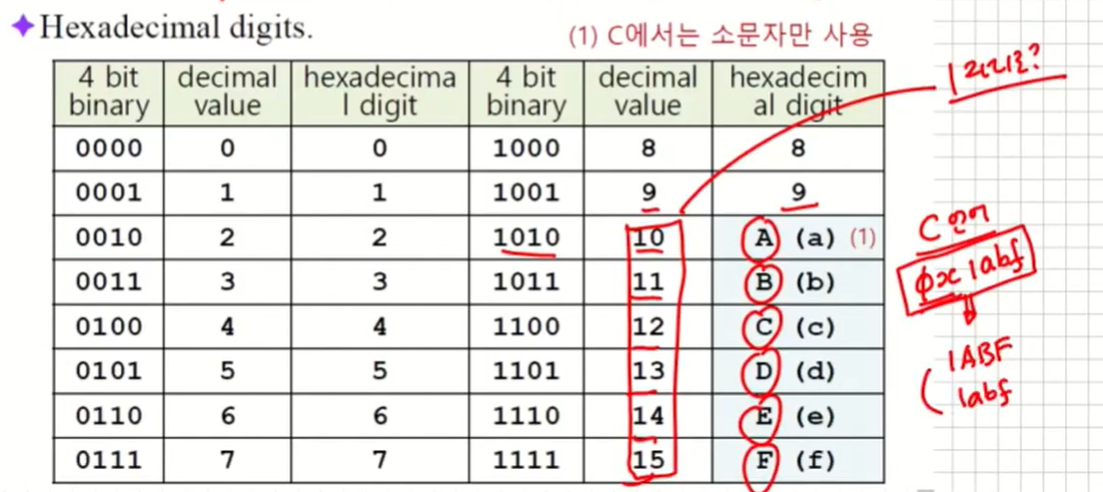
- c언어
또 한가지 C언어에서는 0x를 붙여서 사용해야 한다. - 어셈블리
반면 어셈블리에서는 h또는 H를 16진수 뒤에 붙인다. 16진수의 첫 digit가 알파벳일 경우 앞에 0을 붙인다.
비트 수를 명시할 필요가 있을 때는 수 앞에 모자란 자리를 0으로 채운다.


E와 2를 구분하기 어려우므로 E를 echo로 발음
O와 0을 구분하기 어려우므로 0을 Φ로 표기

- c언어
-
정리

-
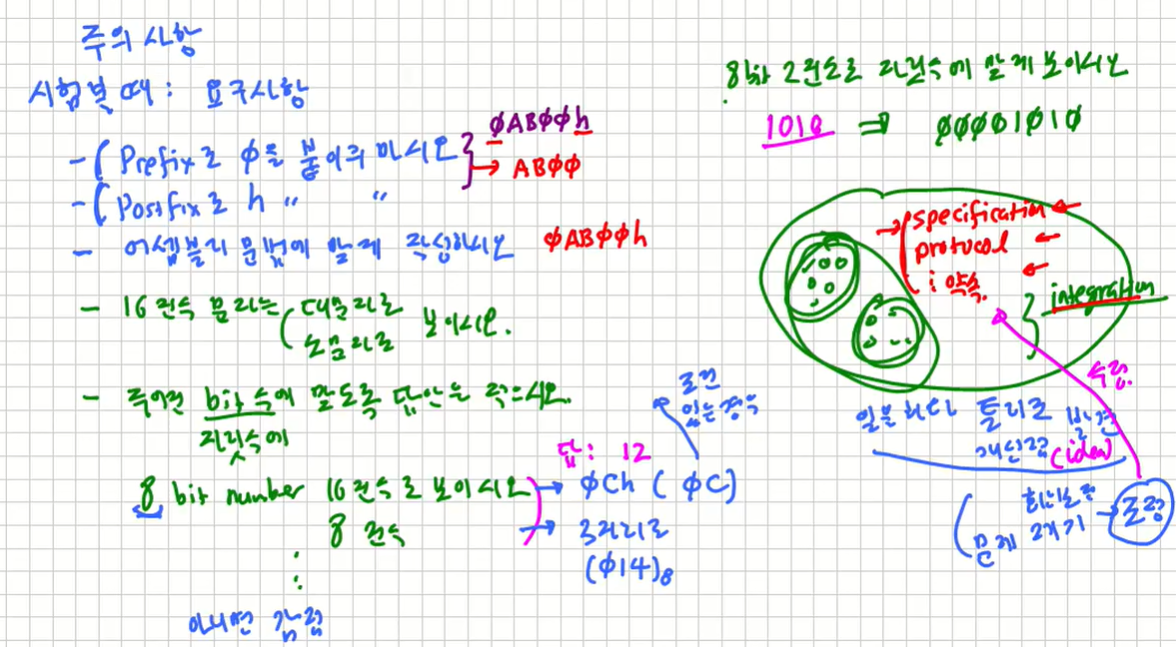
주의사항