Collection Framework
이제부터는 자바에서 주로 사용하는 라이브러리를 사용하여 자바의 디자인 패턴들을 배우는 시간이 진행된다.
Collection Framework : group of objects 라고 한다. 데이터들은 group으로 존재하기에 이 많은 데이터를 어떻게 저장하고 관리하고 꺼내오는지가 프로그래밍에서는 중요한 문제가 된다. 이때 자바프로그램이 이를 어떻게 관리하는지를 나타내 주는 것이 Collection Framework이다.
아래의 것들은 모두 interface로 구현이 되어 있다. 그래서 사용자가 Abstrace class를 받아와서 구현하는 형태로 되어 있다.
- List
Classes : ArrayList, LinkedList, Stack, Vector - Set
Set 은 List와 다르게 순서가 존재하지 않는다. 즉 어느것이 앞이고 뒤인지가 없다.
또한 중복이 불가능하다.
Classes : HashSet, TreeSet - Map
Key-Val 형식의 데이터 모음으로 중복은 불가능하다.
Classes : HashMap, TreeMap, Hashtable, Properties
1. Interfaces defined in the Collection Framework
Interface Collection<E>
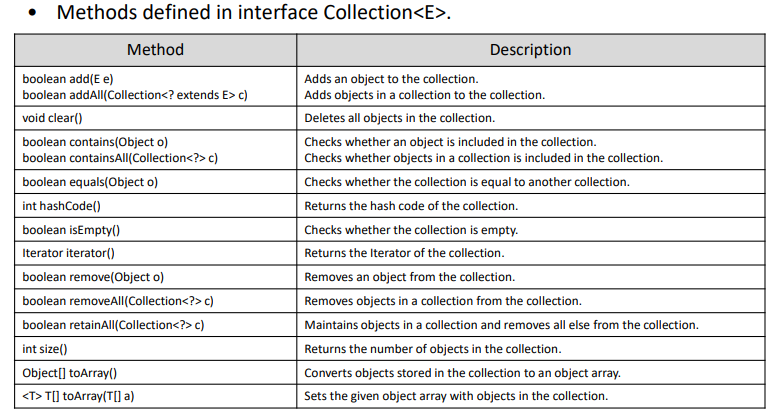
Method 클래스는 위와 같이 많은 함수들로 구성이 되어 있다.
- add : 특정 아이템 추가
- remove : 특정 오브젝트 삭제
- contains : 특정 오브젝트가 포함되었는지 확인
- equals : 두개의 오브젝트가 같은지 확인
- HashCode : 두개의 오브젝트가 같으면 해쉬코드 반환
- Clear : 삭다 없애는 거
- isEmpty : Collection이 비었는지 확인
- retainAll : 특정 object를 제외하고 모두 지워라
- size : Collection에 포함된 Object의 갯수 확인
- iterator : 반복문으로 Collection의 각 element들을 관리
- toArray : Collection을 Array로 변환
List

List interface를 받는 것에는 위의 4가지가 존재한다.
Interface List<E>

add와 remove를 제외하고 설명
- get : 특정 인덱스의 오브젝트를 가져옴
- indexOf : 특정 오브젝트가 있는지 확인
- listIterator : List에 최적화된 Iterator
- set : 특정 인덱스의 값을 set하는 것
- sort : List에 저장된 데이터들을 기준에 따라 정렬
- subList : List에 일부 데이터를 가지고 오기
Set
가장 많이 사용하는 HashSet과 TreeSet을 기억하자.
여기에서 규칙은
- 중복된 데이터가 들어갈 수 없다.
- set안에서 pair가 나올 수 없다.(중복이 안되니)
- null element도 단 하나만 존재
- element간의 순서가 존재하지 않음
Set은 interface Set<E> 형태임을 명시하자
Map
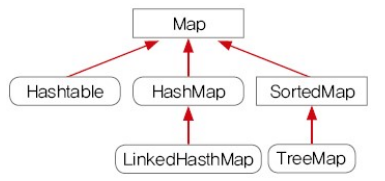
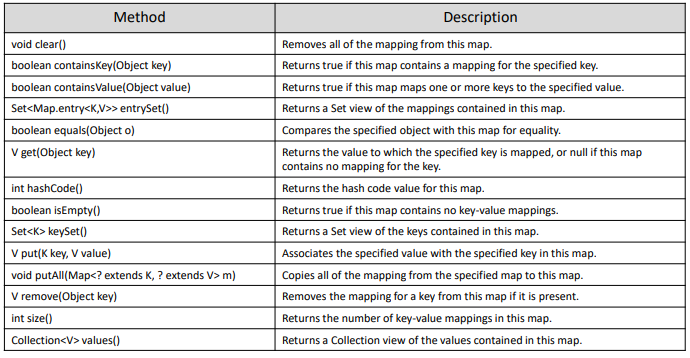
Map은 key와 value를 가지고 중복이 불가능한 자료형이다.
구조는 위와 같이 구성되며 훨씬 더 많은 종류의 Map이 존재한다.
우리는 HashMap과 TreeMap 중심으로 볼 예정이다.
Interface Map<K, V>
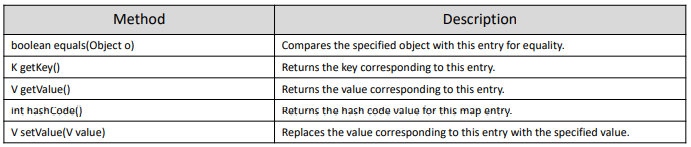
Map.Entry
Map.Entry는 Map 안에 정의된 inner interface이다. 그래서 Map.Entry<K,V> 형태로 사용할 수 있다.
그리고 이 안에도 여러가지 내장 함수가 존재한다. 그래서 위의 함수들을 사용하여서 자료를 관리한다.
2. ArrayList
- ArrayList
ArrayList는 순서가 존재하고 중복이 허용된다.
ArrayLists: Example 1
import java.util.ArrayList;
import java.util.Collections;
public class Lecture {
public static void main(String[] args) {
//타입 Variable과 10개의 element의 공간을 만든다.
ArrayList<Integer> list1 = new ArrayList<Integer>(10);
// Integer을 만드는 방식 : 5라는 값을 가지는 Integer 변수
list1.add(Integer.valueOf(5));
list1.add(Integer.valueOf(4));
list1.add(Integer.valueOf(2));
list1.add(Integer.valueOf(0));
list1.add(Integer.valueOf(1));
list1.add(Integer.valueOf(3));
// list1의 1번~3번까지의 성분을 가지고 리스트를 만든다.(이상, 미만)
ArrayList<Integer> list2 = new ArrayList<Integer>(list1.subList(1,4));
print(list1, list2);
// 정렬하는 부분
Collections.sort(list1);
Collections.sort(list2);
print(list1, list2);
// 앞에는 String 이고 뒤에는 value이다. containsAll은 list1가 list2를 모두 포함하고 있는지를 확인
System.out.println("list1.containsAll(list2):"+list1.containsAll(list2));
list2.add(Integer.valueOf(11));
list2.add(Integer.valueOf(12));
list2.add(Integer.valueOf(13));
print(list1, list2);
// set 함수는 특정 인덱스의 값을 어떤 것으로 바꾸라 라는 의미이다
list2.set(3, Integer.valueOf(21));
print(list1, list2);
// retainAll list2에 해당하는 내용을 남기고 list1에서 삭제하라
System.out.println("list1.retainAll(list2):"+list1.retainAll(list2));
// list2의 특정 인덱스 값이 list1에 존재하면 list2에서 지워주라
print(list1, list2);
// 반드시 뒤에서 부터 앞으로 진행해야 한다.
// 왜냐하면 앞에서 부터 진행할경우 list2의 데이터가 한 칸씩 앞으로 당기어져서 list1과 비교가 되지 않는 데이터가 존재할 수 있기 때문이다.
for(int i=list2.size()-1; i>=0; i--) {
if(list1.contains(list2.get(i)))
list2.remove(i);
}
print(list1, list2);
}
//print 함수는 list1과 list2의 값을 한 번에 출력한다.
static void print(ArrayList<Integer> list1, ArrayList<Integer> list2) {
System.out.println("list1:"+list1);
System.out.println("list2:"+list2);
System.out.println();
}
}ArrayLists: Example 2
import java.util.ArrayList;
import java.util.List;
public class Lecture {
public static void main(String[] args) {
final int LIMIT = 10;
String source = "0123456789abcdefghijABCDEFGHIJ!@#$%^&*()ZZZ";
int length = source.length();
List<String> list = new ArrayList<String>(length/LIMIT + 10);
// 긴 String을 10개 씩 잘라서 ArrayList에 삽입
for(int i=0; i<length; i+=LIMIT) {
if(i+LIMIT < length) list.add(source.substring(i, i+LIMIT));
else list.add(source.substring(i));
}
for(int i=0; i<list.size(); i++) {
System.out.println(list.get(i));
}
}
}ArrayLists: Example 3
Vector은 ArrayList와 유사하지만 Synchronized가 된다. 차후 멀티스레드를 배우게 되면서 깊게 이해할 수 있게 된다.
(* 멀티스테드란 동시에 vector에 접근하게 된다.)
import java.util.*;
public class Lecture {
public static void main(String[] args) {
Vector<String> v = new Vector<>(5);
v.add("1");
v.add("2");
v.add("3");
print(v);
v.trimToSize();
System.out.println("=== After trimToSize() ===");
print(v);
v.ensureCapacity(6);
System.out.println("=== After ensureCapacity(6) ===");
print(v);
v.setSize(7);
System.out.println("=== After setSize(7) ===");
print(v);
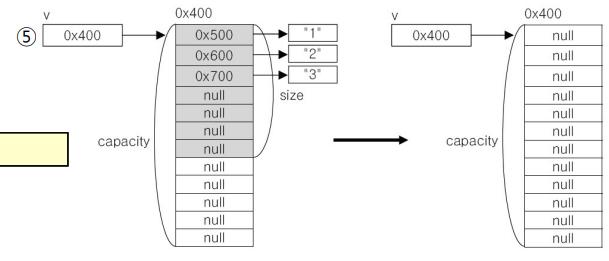
v.clear();
System.out.println("=== After clear() === ");
print(v);
}
// size : element의 갯수
// capacity : 벡터에 총 공간 수
public static void print(Vector<?> v) {
System.out.println(v);
System.out.println("size: " + v.size());
System.out.println("capacity: " + v.capacity());
}
}예제 3에서 어떠한 함수들이 사용되고 있는지 확인해 보도록 하겠다.
- capacity 5 짜리 벡터를 정의한다.
Vector<String> v = new Vector<>(5);
- Vector에 세개의 원소를 삽입한다.
v.add("1");
v.add("2");
v.add("3");- empty space 삭제
v.trimToSize();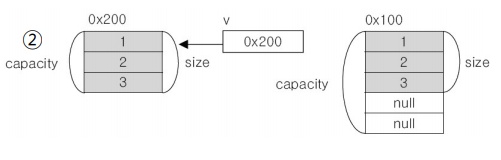
아예 새로운 공간을 만들어 버린다. 그리고 기존의 공간은 없앤다.
- Increase capacity
v.ensureCapacity(6);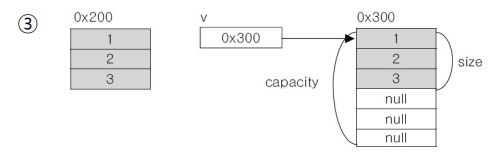
만약에 capacity가 6이면 아무일도 일어나지 않지만 그렇지 않다면 새로운 메모리 공간을 만든다.
- Make the size
size를 억지로 만든다. null값을 남은 공간에 삽입하여서 size를 원하는 숫자로 만든다.
만약 capacity가 원하는 숫자보다 아래라면 새로운 공간을 만듬과 동시에 capacity를 두배로 만들어 놓는다.
v.setSize(7);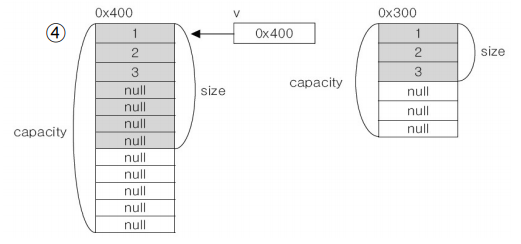
- list의 모든 데이터를 없애기
size는 0이 되고 capacity는 유지된다.
v.clear();