
해당 논문은 2022년에 microsoft사에서 발표하였다.
https://arxiv.org/abs/2212.09058
먼저 간략히 요약 하자면
기존의 reconstruction loss를 사용하는 Audio SSL 모델과 달리 self-distilled tokenizer 를 이용하여 signal을 discrete labels로 변환하여 classic masking 기법과 조합하여 사전 학습 진행하였다.
Introduction
SSL에는 수많은 모델들이 있지만 오디오에서는 주로 reconstruction loss를 사용한다.
이러한 loss는 low-level time-frequency feature을 설명 하지만 high-level audio semantic abstraction은 무시한다는 문제가 있다.
그렇다면 과연 discrete 한 label로 예측 할 경우에는 다음과 같은 두 가지 문제가 있다.
1. 오디오 신호 특성 상 동일한 이벤트에 대해도 다양한 길이를 가지므로 BERT 처럼 오디오를 의미 있는 토큰으로 직접 분할이 어려움
2. background sound를 포함하므로 데이터 변화 량이 크므로 HuBERT와 같은 모델 사용이 힘듬
그렇다면 이러한 어려움이 있음에도 불구하고 사용하려는 이유는 다음과 같은 장점이 있다고 저자들이 애기한다.
- 인체공학적 : 인간은 높은 수준의 데이터를 추출하고 클러스터링
- 모델링 효율성 측면에서 reconstruction은 비 효율적임
Reconstruction loss는 의미론적으로 상관없는 것에 대해 학습할 수 있음 - 오디오에 국한 될 필요없이 Vision, NLP, Audio를 모두 사용한 통합 교육 모델 구축이 가능 함
저자들은 아래와 같은 방식으로 discrete label를 사용하여 학습할 수 있는 구조를 제안하였다.
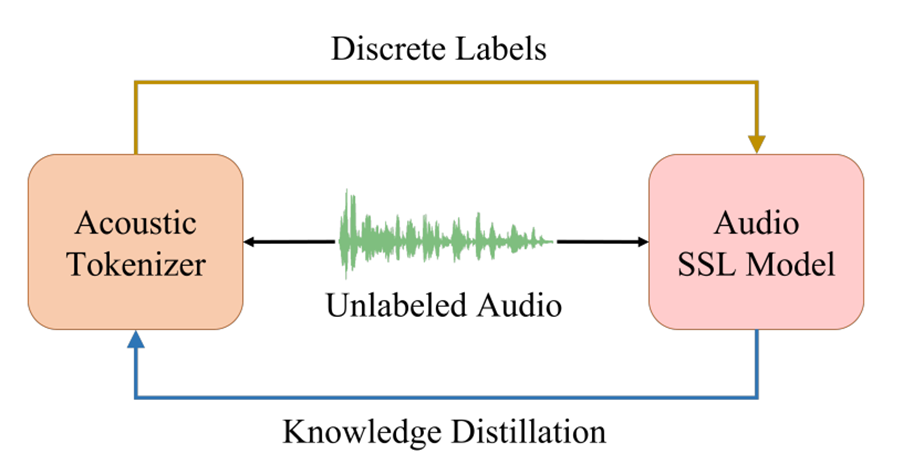
Tokenizer와 SSL 모델이 번갈아 가면서 학습하는 방식으로
그 과정은 다음과 같다.
- Tokenizer가 먼저 label 생성 (첫 iteration은 random-projection -> cold start)
- SSL 모델은 masking과 함께 discrete label prediction loss로 학습
- SSL model(VIT)이 수렴 후 teacher가 되어 tokenizer에게 KD 진행
- 위 과정을 수렴할 때 까지 진행함
Method
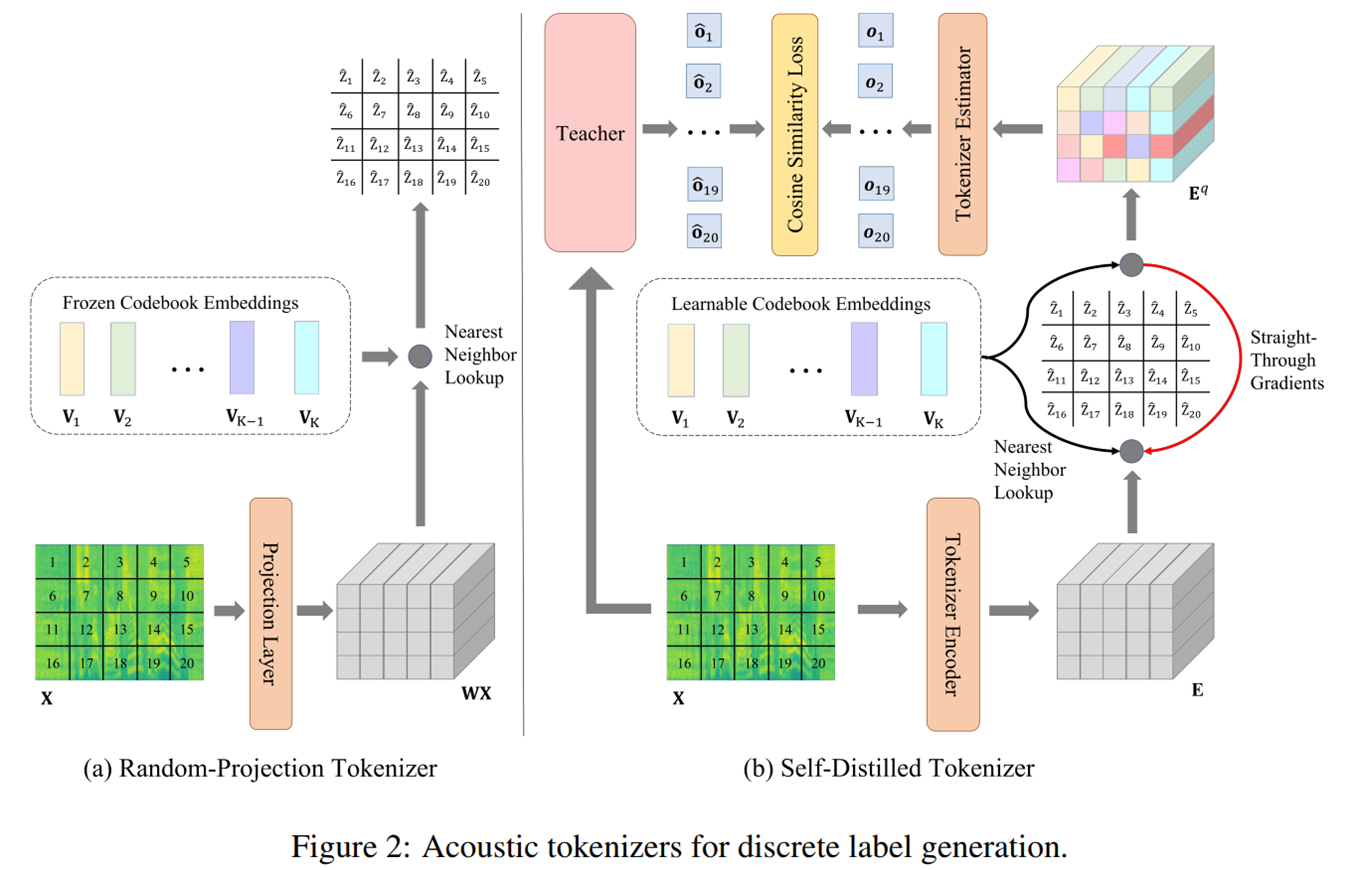
Tokenizer
(a) linear projection을 진행 한 후, Codebook Embedding 중에서 Neraest neighbor (NN) lookup을 통해 각각의 토큰과 가까운 embedding 을 찾고 NN의 index가 discrete label이 되게 된다.

(b) 이후 Self-distilled tokenizer에서 Teacher model을 tokenizer를 통해 학습하게 된다. 이 때, vector quantization을 미분 할 수 없는 문제 때문에 gradient를 copy해서 사용하게 된다.
여기서 Tokenizer Encoder 및 Estimator는 Transformer 구조를 사용한다.
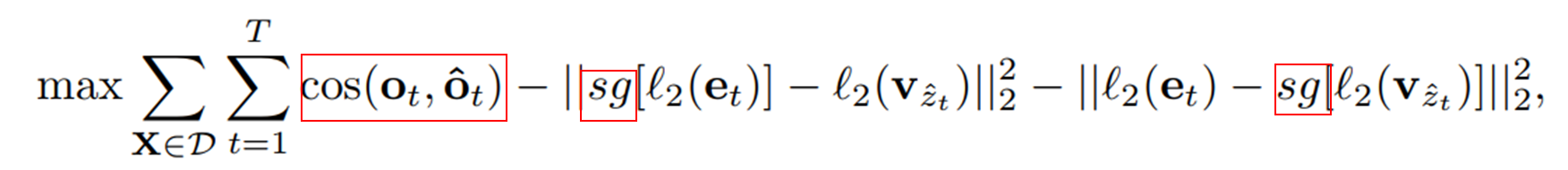
Audio SSL Model
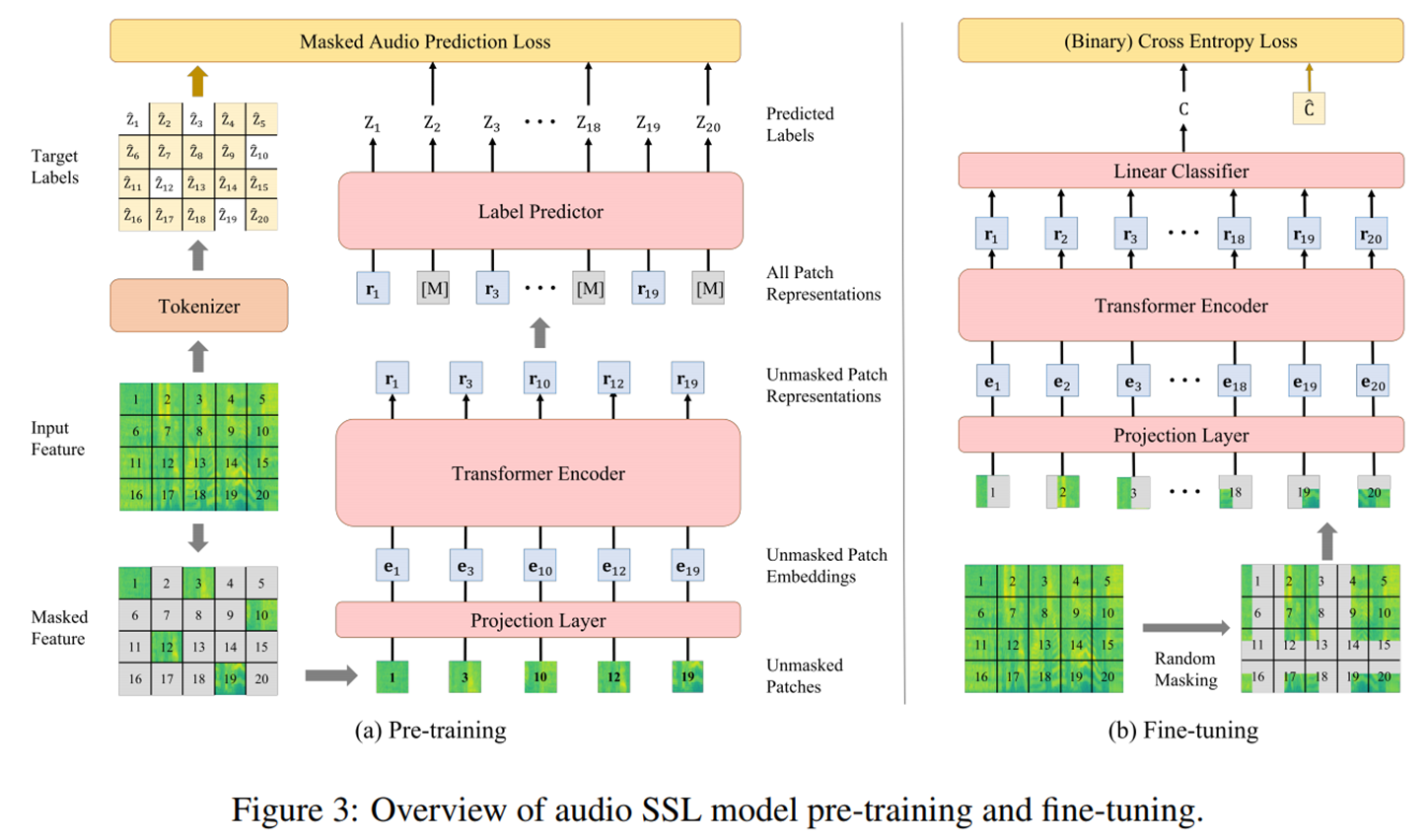
(a) Backbone은 ViT 구조를 기본적으로 사용하며 pre-training엔 Masked Audio Modeling (MAM) 방식을 사용하여 patch-label 예측을 통해 학습 된다.

(b) Fine-tuning에서는 Spec-augmentation 방식으로 masking하며 pre-training 때와 다르게 masking된 패츠를 포함하여 모델 입력으로 넣어준다.
Experiments
Dataset
- Pre-training : AudioSet
- Downstream
- Audio classification (AudioSet-2M , AudioSet-20k, mAP)
- Speech classification
- Environmental Sound Classification (ESC-50)
- Speech Commands V2 (KS2)
- Speech Commands V1 (KS1)
- IEMOCAP(ER)
- Audio classification (AudioSet-2M , AudioSet-20k, mAP)
Input Feature
- 16k sampling rate
- 128-dim mel filter bank, 25ms Povy window, 10ms shift
- Norm. : mean 0, std 0.5
- Patch size : 16 x 16
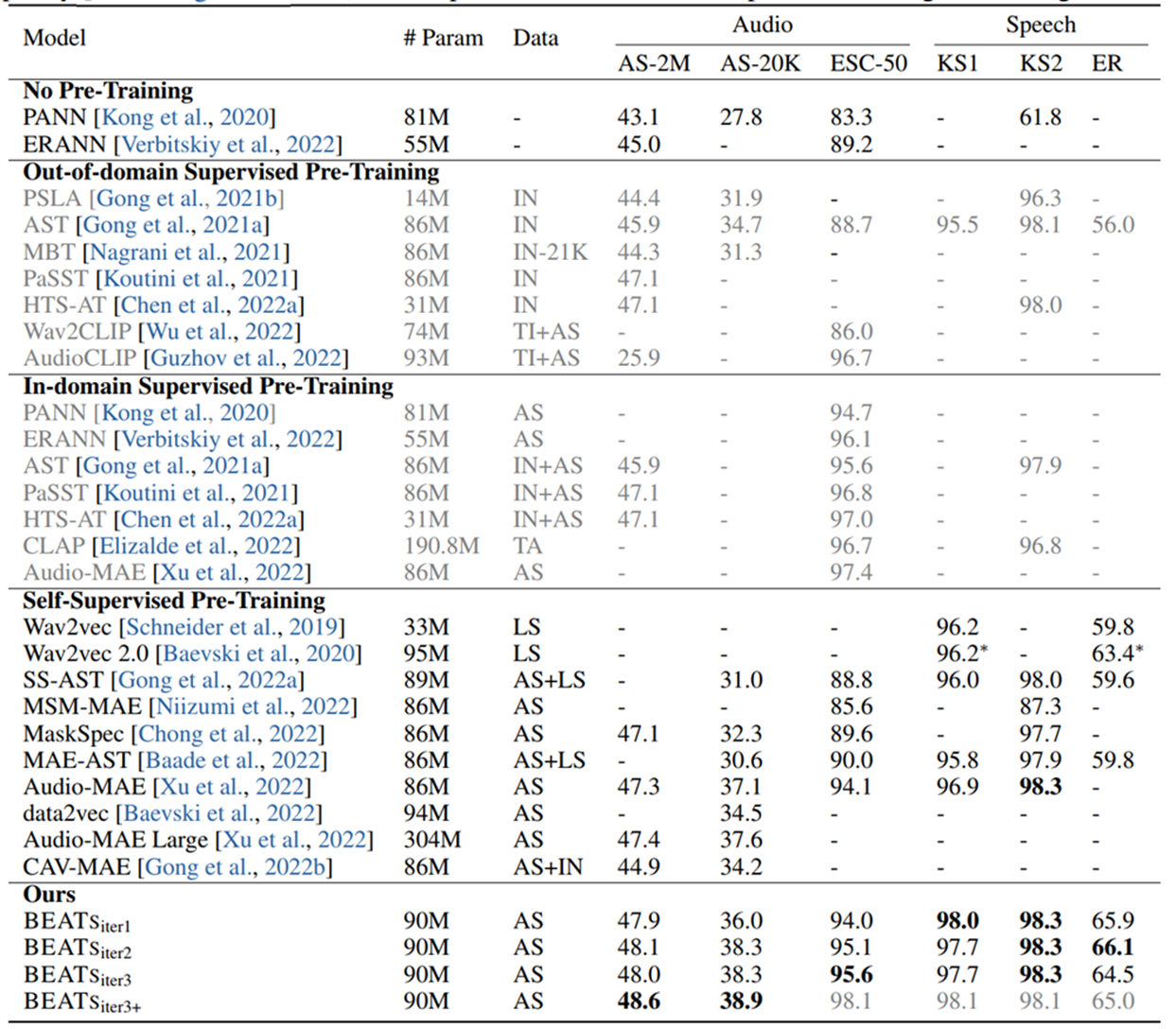
실험결과는 AudioSet에서 SOTA를 달성하였다.
특히 2번째 iteration에서 supervised fine-tune을 진행한 +모델이 성능이 높았다.
T-SNE 결과만 봐도 차이가 난다.

Conclusion
microsoft가 출판해서 그런지 futurework이 궁금해지는 논문이었다.
-
기존의 reconstruction loss를 사용하는 Audio SSL 모델과 달리 self-distilled tokenizer 를 이용하여 signal을 discrete labels로 변환하여 classic masking 기법과 조합하여 사전 학습 진행
-
논문에서 제시한 task들에서는 높은 성능을 달성 함
- 다른 task에 대해서는 어떨지 궁금함
-
현재 네트워크에서는 기존 사전 학습 네트워크와 공정 비교를 위해 네트워크를 스케일링 하였지만 scale-up 예정
-
Multi-modality field에서 Vision, NLP와 결합하여 학습 해볼 예정이라고 함
