
Table Compression
Basic Table Compression
- 주로 읽기 전용 데이터에 사용
- 테이블의 데이터를 블록 수준에서 압축
- 블록이 새로 생성되거나 다시 압축이 필요 없을 때까지는 수정되지 않는다는 전제하에 동작
- 압축 원리
- 반복 데이터 제거: 데이터를 압축할 때 동일한 값이 여러 번 반복되는 경우, 이 값을 한 번만 저장하고 참조하여 공간을 절약합니다.
- 고정 길이 감소: 데이터 블록 내에서 같은 값이 많이 사용되면, 해당 값을 고정된 길이로 저장하지 않고 더 짧은 형식으로 저장합니다.
- 특징:
- 데이터 삽입 시 블록 단위로 압축이 적용
- 압축된 블록은 읽기 전용 모드에서만 효율적으로 관리
- CPU 오버헤드가 적어 성능에 미치는 영향이 상대적으로 적음
Advanced row compression
- 데이터의 행 단위로 더 세밀하게 압축을 적용
- 데이터 작업에 대해 읽기 및 쓰기 성능을 최적화
- 압축 원리
- 데이터의 패턴을 분석하여 자주 사용되는 값을 찾아내고, 이를 더 짧은 형식으로 변환하여 저장합니다.
- 여러 가지 압축 기법을 결합하여 각 행의 데이터에 최적의 압축 방법을 적용합니다.
- 특징:
- 데이터가 삽입되거나 수정될 때도 실시간으로 압축이 적용
- CPU 사용량이 증가할 수 있으나, 데이터베이스 성능을 최적화하여 전체 성능을 유지
- 읽기/쓰기 작업 모두에서 효율적으로 작동
- OLTP(온라인 트랜잭션 처리) 환경에서 사용 가능
- 11g 이전까지는 벌크 로딩하면서 압축된 데이터에 대해 DML 작업이 발생하면 이후부터는 압축이 풀린 상태로 관리되었기 때문에 일반적인 데이터 작업에서는 압축을 활용할 수 없었다.
- 11g에 와서는 일반적인 DML 작업에 대해서도 압축이 가능해졌기 때문에, OLTP 시스템에서 데이터에 대한 변경이 발생하는 테이블에 대해서도 압축을 사용할 수 있게 되었다.
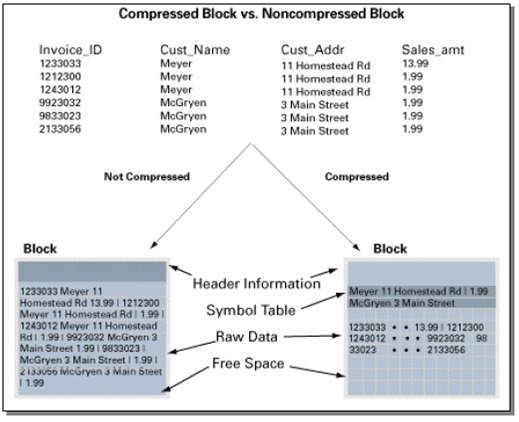
Compression 원리
sales테이블 데이터
2190,13770,25-NOV-00,S,9999,23,161
2225,15720,28-NOV-00,S,9999,25,1450
34005,120760,29-NOV-00,P,9999,44,2376
9425,4750,29-NOV-00,I,9999,11,979
1675,46750,29-NOV-00,S,9999,19,1121- 중복 값들을 기호 참조로 대체한다.
29-NOV-00→*
9999→%
2190,13770,25-NOV-00,S,%,23,161
2225,15720,28-NOV-00,S,%,25,1450
34005,120760,*,P,%,44,2376
9425,4750,*,I,%,11,979
1675,46750,*,S,%,19,1121- Symbol Table
| 기호 | 값 | 열 | 행 |
|---|---|---|---|
| * | 29-NOV-00 | 3 | 958-960 |
| % | 9999 | 5 | 956-960 |
Compressed table은 각 block에 symbol table이 존재
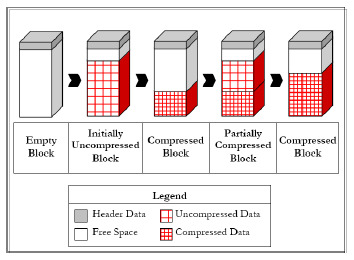
Hybrid Columnar Compression (HCC)
개요
- 전통적으로 데이터는 데이터베이스 블록 내에서 row 형식으로 구성: 특정 행에 대한 모든 열 데이터가 단일 데이터베이스 블록 내에 순차적으로 저장
- 서로 다른 데이터 유형을 가진 열 데이터가 가까이 저장되면 압축 기술로 달성할 수 있는 저장 공간 절감의 한계가 존재: 이에 대한 대안 접근 방식은 데이터를 column 형식으로 저장하는 것으로, 데이터가 열 단위로 구성되고 저장됨
- 그러나 이 방식으로 데이터를 저장하면 응용 프로그램 쿼리가 하나 이상의 열에 접근하거나, 소량의 행을 업데이트하거나 삽입할 때 데이터베이스 성능에 부정적인 영향을 미칠 수 있음
Compression Unit (CU)
HCC 압축 방식은 더 이상 row 단위로 데이터를 저장하지 않고 CU(Compression Unit) 단 위로 저장 된다.
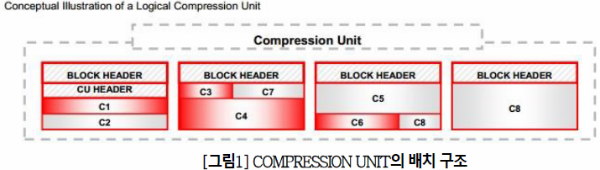
작동
-
데이터 수집
고객 테이블이 있다고 가정할 때, HCC는 여러 행의 고객 데이터를 하나의 CU로 수집합니다.예: 고객 ID, 이름, 나이, 주소 등의 데이터
보통은 테이블의 연속적인 데이터 블록들을 수집하여 CU를 형성한다.
예를 들어, 첫 번째 CU는 테이블의 처음 1000행, 두 번째 CU는 그 다음 1000행... -
압축
수집된 데이터는 각 열 단위로 압축된다. 동일한 열의 데이터는 서로 유사성이 높기 때문에 더 높은 압축률을 얻을 수 있다.예: 고객 ID는 1열, 이름은 2열, 나이는 3열, 주소는 4열
-
저장
압축된 데이터는 CU로 저장되며, 하나의 CU는 여러 데이터 블록을 포함할 수 있다.예: CU1에는 고객 테이블의 첫 1000행 데이터가 압축되어 저장
완전한 Column 압축과의 차이
완전한 열 기반 압축 방식의 단점
- 데이터 접근 성능 저하: 완전한 열 기반 압축은 특정 행에 접근할 때 여러 열의 데이터를 개별적으로 읽어야 하기 때문에 성능이 저하될 수 있습니다.
- 복잡한 쿼리 성능 저하: 다양한 열에 걸쳐 있는 복잡한 쿼리를 처리할 때, 여러 열을 동시에 읽고 처리하는 데 시간이 많이 걸릴 수 있습니다.
- 데이터 재구성 필요: 데이터 삽입, 업데이트, 삭제 시 열 기반 저장 구조를 유지하기 위해 데이터 재구성이 필요할 수 있습니다.
데이터 접근
-
순수 열 기반 접근
- 고객ID가 123인 고객의 데이터를 조회할 때, 각 열 파일(고객ID, 이름, 나이, 주소)을 개별적으로 읽어야 함
- 여러 I/O 작업이 필요하므로 접근 속도가 느려질 수 있다.
-
CU를 이용한 접근
- Oracle 데이터베이스는 각 CU에 대한 메타데이터를 유지한다. 이 메타데이터에는 각 CU가 포함하는 데이터 범위와 해당 데이터의 통계 정보가 포함된다.
- 인덱스를 사용하여 특정 행을 포함하는 CU를 빠르게 찾을 수 있다. 예를 들어, 고객ID 열에 인덱스가 설정되어 있으면, 인덱스를 통해 고객ID 123이 포함된 위치를 빠르게 조회할 수 있다.
- 고객ID가 123인 고객이 포함된 CU를 식별하고, 해당 CU를 한 번에 읽어 올 수 있다.
- CU 내에서 필요한 데이터를 빠르게 추출할 수 있으므로, 접근 속도가 빨라진다.

비전공 개발 공부 이야기