Colab을 통해 작성된 코드입니다.
파이썬 패키지에는 BeautilfulSoup, requests 등 웹 스크래핑을 위한 다양한 라이브러리가 존재한다. 이를 이용하여 네이버 증권 사이트의 급상승 주식 종목을 가져와보자.
1. 패키지 및 모듈 설치
!pip install bs4
!pip install requests먼저 BeautifulSoup 패키지를 설치해준다.
import requests as req
from bs4 import BeautifulSoup as bs설치된 bs4와 requests를 import해준다.
2. url 불러오기 및 html 텍스트 화
# 네이버 금융 url
url = "https://finance.naver.com/"
# requests 모듈을 이용해 url의 html을 text화한 후 변수로 저장
html = req.get(url)
html_txt = html.text
#print(html_txt)
#beautifulsoup를 이용해 html.parser로 보기 좋게 text 변환하기
soup = bs(html_txt, "html.parser")html_txt를 print하여 불러온 url의 html이 어떻게 구성되어 있는지 먼저 확인해준다. 난잡하게 정리되어 있을 것이다. 따라서 BeautifulSoup를 이용하여 html.parser를 이용하여 html code를 깔끔하게 정돈해준다.
3. Selector를 이용하여 정보 가져오기
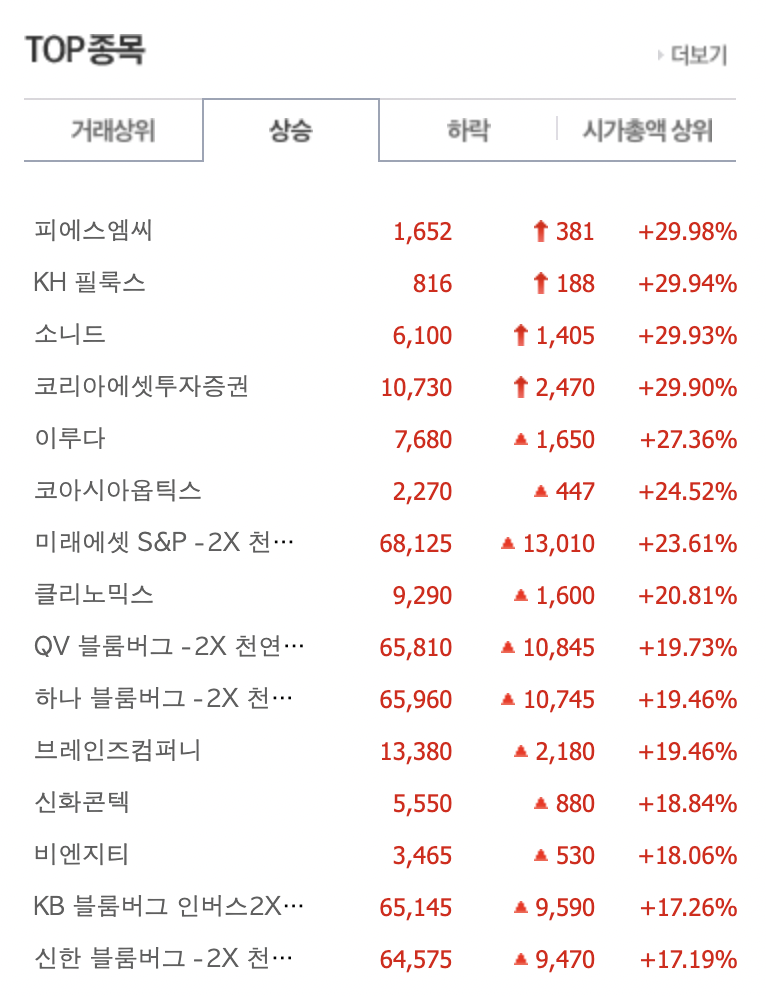
우리가 가져오고 싶은 부분은 네이버 증권 사이트의 이 부분이다. 따라서 개발자도구(F12)를 이용하여 이 부분의 selector를 가져와보자.
#_topItems2 > tr:nth-child(1)
#_topItems2 > tr:nth-child(2)
#_topItems2 > tr:nth-child(3)
...
각 종목의 selector가 다음과 같이 구성되어있음을 확인했다. 이를 BeautifulSoup를 통해 html코드를 제외한 문자 부분만 읽어오면,
increase_rank = soup.select_one("#_topItems2 > tr:nth-of-type(1)")
print(increase_rank)(왜인지는 모르겠지만, select_one 함수가 nth-child() 형태가 아닌 nth-of-type()을 지원한다고 하여 수정하였다.)
피에스엠씨
1,652
상한가 381
+29.98%
이런 식으로 결과가 나오는 걸 확인할 수 있었다. 문자열 사이에 줄바꿈이 있으니 나중에 리스트에 집어넣을 때 이를 기준으로 나누고, 공백도 삭제해줘야한다.
4. 스크래핑한 정보를 리스트화한 후 출력하기
# 빈 리스트 생성
share_list = []
# 주식명, url, 현재가격, 상승폭 데이터 수집 (Top 10)
for i in range(1,11):
selector = "#_topItems2 > tr:nth-of-type(%d)" % i
share_info = soup.select_one(selector).get_text().strip().split("\n")
share_list.append(share_info)먼저 주식 정보를 담을 리스트를 선언하고 초기화한다.
selector 변수에 추출해온 selector 정보를 넣어주고 반복문을 통해 다음 순위의 주식 정보를 담을 수 있는 selector를 담을 수 있게 하였다.
그 다음 select_one 함수를 통해 가져온 문자 정보를 공백을 제거한 뒤 줄바꿈을 기준으로 split하여 리스트화 하였다. 각 share_info는 다음과 같이 나타났다.
['피에스엠씨', '1,652', '상한가 381 ', ' +29.98%']
['KH 필룩스', '816', '상한가 188 ', ' +29.94%']
['소니드', '6,100', '상한가 1,405 ', ' +29.93%']
['코리아에셋투자증권', '10,730', '상한가 2,470 ', ' +29.90%']
['이루다', '7,680', '상승 1,650 ', ' +27.36%']
['코아시아옵틱스', '2,270', '상승 447 ', ' +24.52%']
['미래에셋 S&P -2X 천연가스 선물 ETN(H)', '68,125', '상승 13,010 ', ' +23.61%']
['클리노믹스', '9,290', '상승 1,600 ', ' +20.81%']
['QV 블룸버그 -2X 천연가스 선물 ETN(H)', '65,810', '상승 10,845 ', ' +19.73%']
['하나 블룸버그 -2X 천연가스 선물 ETN(H)', '65,960', '상승 10,745 ', ' +19.46%']
share_info를 미리 생성한 share_list에 넣어주어 출력할 때 사용할 수 있게 하였다.
여기서 주식 종목명과 현재가격, 상승폭만 추출해보았다.
# 주식 데이터 출력
for rank, value in enumerate(share_list, start=1):
print("%d위 : %s" % (rank, value[0]))
print("현재 가격 : %10s 상승폭 : %10s\n" % (value[1], value[3].strip()))
다음과 같이 성공적으로 출력되는 걸 확인할 수 있었다.
