
💡 엔지니어링 노트 7: Spring JDBC 성능 문제, 네트워크 분석으로 파악하기
엔지니어링 노트 시리즈는 토스페이먼츠 개발자들이 제품을 개발하면서 겪은 기술적 문제와 해결 방법을 직접 다룹니다. 이번에는 토스페이먼츠 정산 플랫폼에서 많은 양의 정산 데이터 처리 과정에서 생긴 지연 이슈를 처리한 방법을 소개해요.
토스페이먼츠 정산 플랫폼에서는 가맹점의 모든 정산 거래 건을 처리하고 있는데요. 많은 양의 정산 데이터 처리를 위해 스프링 배치(Spring Batch)와 JDBC(Java Database Connectivity)를 사용해요. 최근 신규 정산 시스템을 구현하는 과정에서 문제가 있었는데요. 스프링 배치 내에서 JDBC로 대량의 데이터 insert가 이루어질 때 속도가 지연되는 현상이었어요. 문제 현상의 원인을 찾고 해결한 과정을 공유합니다.
bulk insert 성능 저하 발견
JDBC 템플릿은 스프링에서 제공하는 데이터베이스 연결 및 작업을 쉽게 할 수 있도록 하는 도구인데요. 템플릿에서 제공하는 batchUpdate()는 여러 개의 데이터베이스 업데이트(예: insert, update) 명령을 한 번에 묶어서 처리합니다. 이를 'bulk insert'라고 부르는데요. 많은 양의 데이터를 데이터베이스에 삽입하는 작업이에요.
JDBC를 이용해 bulk insert를 하기 위해 다음처럼 Repository 코드를 작성합니다.
@Component
class SettlementStepRepository(
@Qualifier("settlementJdbcTemplate")
private val jdbc: NamedParameterJdbcTemplate,
) {
@Transactional
fun insertAll(steps: List<SettlementStep>) {
val namedParameters = steps.map { it.toSqlParam() }
jdbc.batchUpdate(
"""
INSERT INTO SETTLEMENT_STEP
(....)
VALUES
(....)
""".trimIndent(),
namedParameters.toTypedArray(),
)
}
//...정말 흔하게 볼 수 있는 batchUpdate를 활용한 대량 insert 구현체에요. 그런데 이 Repository를 이용해 구현한 스프링 배치 ItemWriter에서 5000개의 객체를 삽입할 때 무려 1분 이상이 걸리는 현상을 발견했습니다.
문제 원인 찾기
1. TCP 패킷 분석
처음에는 지연 원인을 찾기가 어려웠습니다. 다른 로직 없이 단순히 데이터를 삽입하는 Writer 단계였기 때문이죠. 막연하게 데이터 삽입 작업을 블로킹하는 로직이 배치 내에서 돌고 있다는 느낌은 있었지만, 내부 어플리케이션 로그에서는 문제를 발견할 수 없었어요. 그래서 JDBC에서 실행되는 쿼리를 확인하기 위해 로그 레벨을 변경해 봤어요. 데이터베이스와의 상호작용 중에 발생하는 모든 쿼리를 기록해 본 거죠. 하지만 이 방법으로도 insert 쿼리 외에 다른 쿼리는 발견되지 않았어요. 즉, 지연의 원인이 insert 쿼리 자체는 아닌 것 같았어요.
복잡한 로직이 없는데도 지연 문제가 발생한다면 데이터베이스와의 통신 중에 어떤 블로킹이 발생한 게 아닐까 추측했어요. 그래서 TCP 패킷 캡쳐(네트워크를 통해 전송되는 데이터 패킷을 포착하여 분석하는 것)를 하기로 했어요. 데이터베이스와 배치 프로그램 간에 실제로 어떤 쿼리를 주고받는지 확인하기 위해서였죠.
WireShark라는 프로그램을 통해 로컬 데이터베이스 호스트에 연결하면, 해당 호스트를 통해 주고받는 모든 TCP 패킷을 확인할 수 있습니다. 캡쳐링한 TCP 패킷은 follow TCP Stream 기능을 사용하면 쉽게 읽을 수 있는 형태로 스트림을 재조립해 줘요.
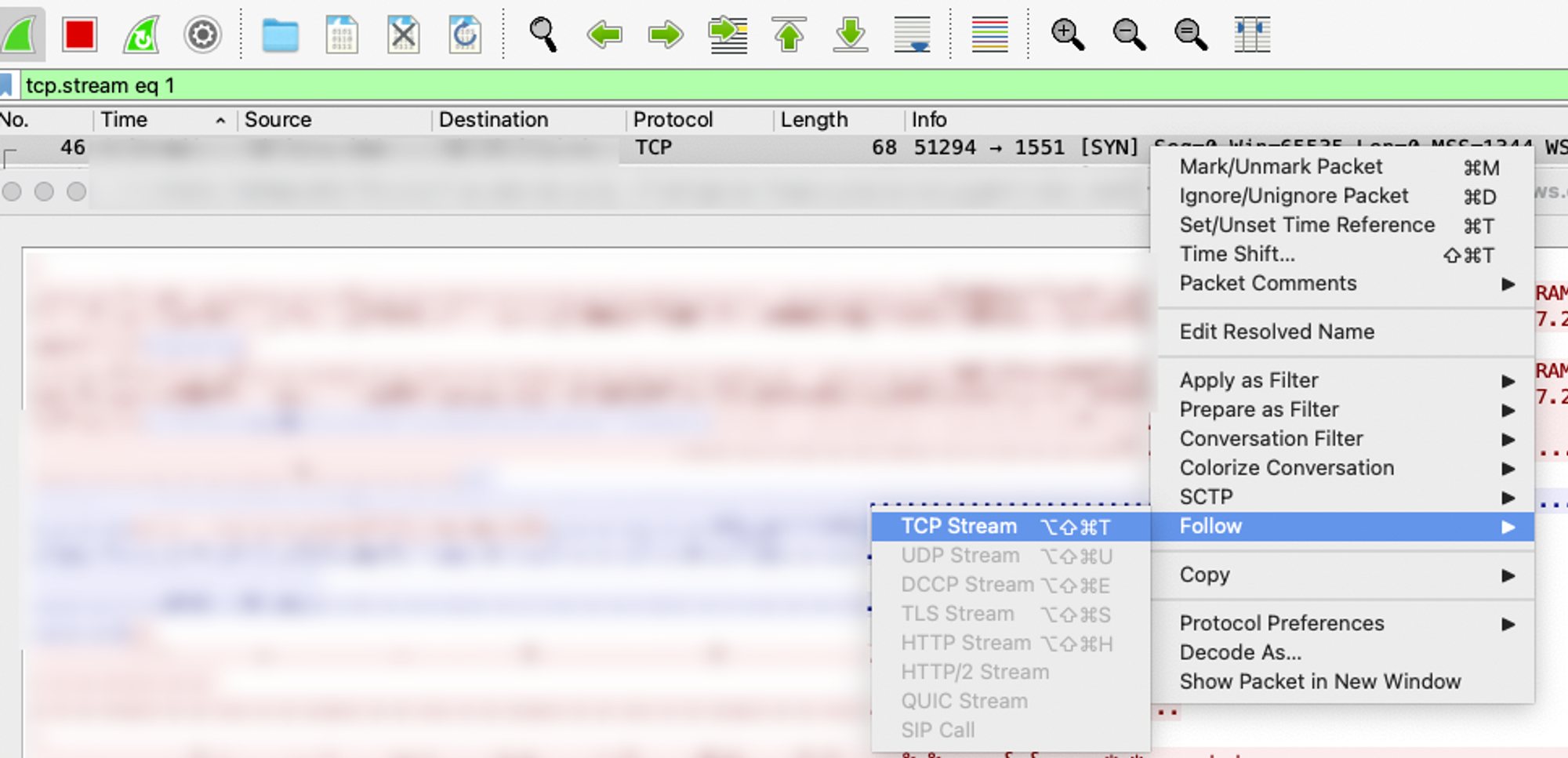
Wireshark를 세팅한 후 배치를 실행해 보니, 놀라운 결과가 나왔습니다. bulk insert 쿼리가 실행되기 전에 해당 데이터베이스 테이블에 대한 select 쿼리가 다량으로, 계속해서 실행되고 있었거든요.
2. JDBC 코드 디버깅
select 쿼리가 실행된 이유를 알아내기 위해 JDBC의 NamedJdbcTemplate 클래스의 batchUpdate 함수를 디버깅 해봤어요. 전체 디버깅 흐름은 아래와 같아요.
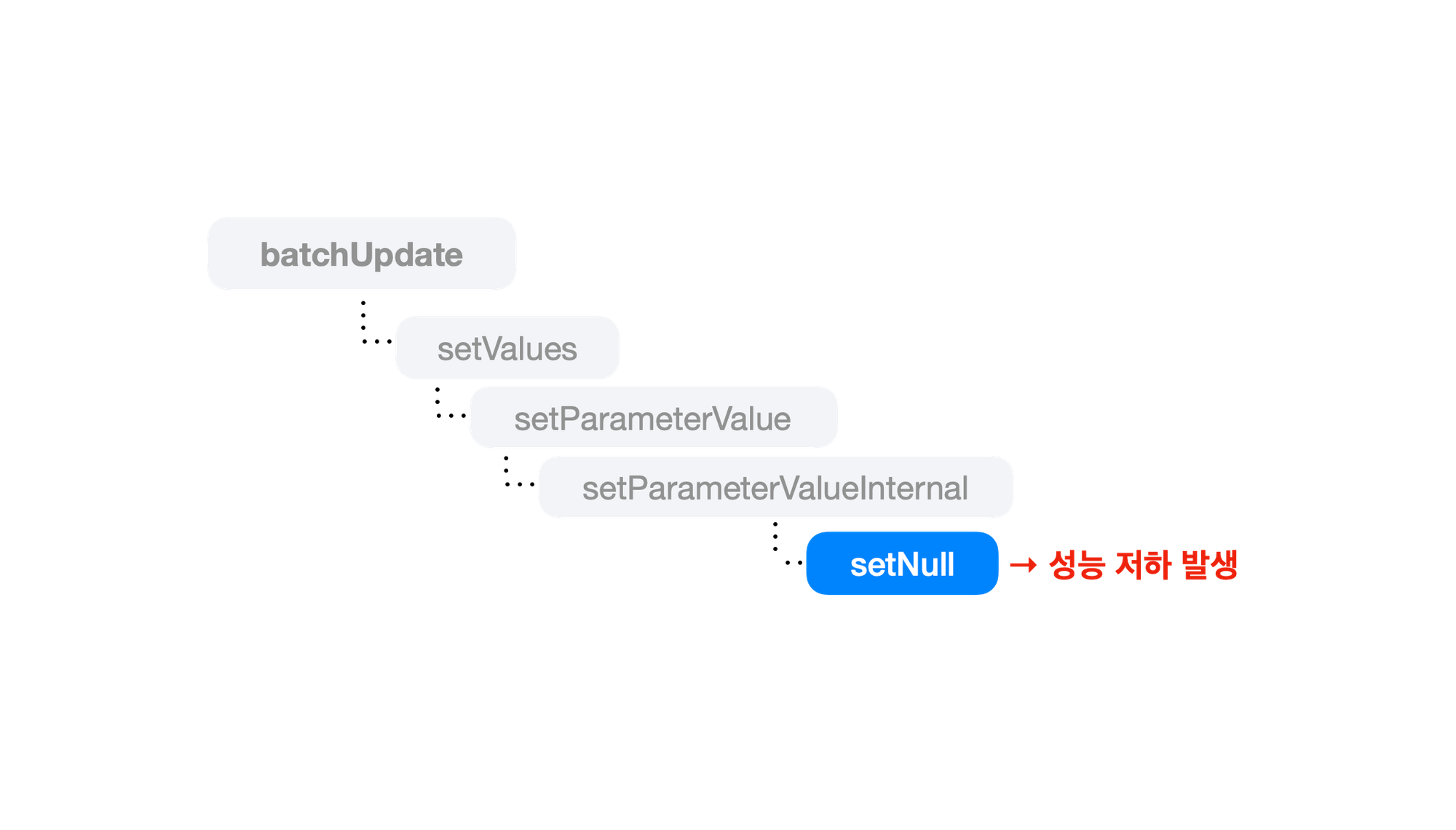
- 구현할 때 사용한
batchUpdate()는 JdbcTemplate 내setValues()을 오버라이딩 해서JdbcTemplate.batchUpdate()를 그대로 호출합니다. - 오버라이딩한
setValue()를 살펴보니PreparedStatementCreatorFactory의setValues()에서 문제가 발생하고 있었어요. PreparedStatementCreatorFactory의setValues()내부에서는StatementCreatorUtils의setParameterValue()메서드를 실행하고 있었습니다.
// NamedJdbcTemplate.java
@Override
public int[] batchUpdate(String sql, SqlParameterSource[] batchArgs) {
if (batchArgs.length == 0) {
return new int[0];
}
ParsedSql parsedSql = getParsedSql(sql);
PreparedStatementCreatorFactory pscf = getPreparedStatementCreatorFactory(parsedSql, batchArgs[0]);
// 여기서 this.getJdbcOperations()은 JdbcTemplate 객체를 반환
return getJdbcOperations().batchUpdate(
pscf.getSql(),
new BatchPreparedStatementSetter() {
@Override
public void setValues(PreparedStatement ps, int i) throws SQLException {
Object[] values = NamedParameterUtils.buildValueArray(parsedSql, batchArgs[i], null);
pscf.newPreparedStatementSetter(values).setValues(ps);
}
@Override
public int getBatchSize() {
return batchArgs.length;
}
});
}// PreparedStatementCreatorFactory.java
@Override
public void setValues(PreparedStatement ps) throws SQLException {
// Set arguments: Does nothing if there are no parameters.
int sqlColIndx = 1;
for (int i = 0; i < this.parameters.size(); i++) {
Object in = this.parameters.get(i);
SqlParameter declaredParameter;
// ...
if (in instanceof Iterable && declaredParameter.getSqlType() != Types.ARRAY) {
// ...
} else {
StatementCreatorUtils.setParameterValue(ps, sqlColIndx++, declaredParameter, in);
}
}
}StatementCreatorUtils의 setParameterValue()는 내부에서 setParameterValueInternal()를 호출하는데, 이 함수는 PreparedStatement에 인자로 넘긴 값을 어떻게 세팅할지 결정하는 로직을 담고 있습니다.
PreparedStatement는 데이터베이스에 SQL 쿼리를 보내기 전에 SQL 문을 미리 준비하고 매개변수화하는 객체에요.
// StatementCreatorUtils.java
private static void setParameterValueInternal(PreparedStatement ps, int paramIndex, int sqlType,
@Nullable String typeName, @Nullable Integer scale, @Nullable Object inValue) throws SQLException {
String typeNameToUse = typeName;
int sqlTypeToUse = sqlType;
Object inValueToUse = inValue;
// override type info?
if (inValue instanceof SqlParameterValue) {
//..
inValueToUse = parameterValue.getValue();
}
if (logger.isTraceEnabled()) {
logger.trace("Setting SQL statement parameter value: column index " + paramIndex +
", parameter value [" + inValueToUse +
"], value class [" + (inValueToUse != null ? inValueToUse.getClass().getName() : "null") +
"], SQL type " + (sqlTypeToUse == SqlTypeValue.TYPE_UNKNOWN ? "unknown" : Integer.toString(sqlTypeToUse)));
}
if (inValueToUse == null) {
setNull(ps, paramIndex, sqlTypeToUse, typeNameToUse);
} else {
setValue(ps, paramIndex, sqlTypeToUse, typeNameToUse, scale, inValueToUse);
}
}문제는 넘긴 값으로 null이 들어갈 때였어요. 만약 인자로 들어가는 값이 null이면, 해당 값은 inValueToUse라는 지역 변수를 null로 설정하고, setNull() 이라는 내부 함수를 실행해요.
setNull() 함수 내에서 문제가 된 부분은 세팅하는 값이 null일 때 이 값에 대응하는 SqlType을 JDBC가 알 수 없다는 거였어요. SqlType은 JDBC에서 사용하는 데이터 타입을 정의하는데요. PreparedStatement에서 해당 값을 어떻게 세팅할지 알 수 없어서 직접 데이터베이스로부터 타입 정보를 가져오려고 시도한 거죠.
즉, null 값을 처리할 때 필요한 데이터 타입 정보를 데이터베이스로부터 가져오는 이 추가 작업이 성능 저하를 일으켰던 거예요.
setNull 함수가 성능에 미치는 영향
아래 코드를 보면서 setNull 함수를 좀 더 자세히 살펴볼게요. 함수 내에서 shouldIgnoreGetParameterType 조건에 따라 다른 작업이 실행되는데요. 만약 이 값이 false면 SqlType을 찾아오기 위해서 getParameterMetaData()를 호출합니다. getParameterMetaData()는 사용하는 데이터베이스의 드라이버 구현체에 정의된 함수로, PreparedStatemenet에 설정된 파라미터의 타입 정보(ParameterType)를 가져오는 역할을 하죠.
private static void setNull(PreparedStatement ps, int paramIndex, int sqlType, @Nullable String typeName)
throws SQLException {
if (sqlType == SqlTypeValue.TYPE_UNKNOWN || (sqlType == Types.OTHER && typeName == null)) {
boolean useSetObject = false;
Integer sqlTypeToUse = null;
if (!shouldIgnoreGetParameterType) {
try {
sqlTypeToUse = ps.getParameterMetaData().getParameterType(paramIndex);
}
catch (SQLException ex) {
if (logger.isDebugEnabled()) {
logger.debug("JDBC getParameterType call failed - using fallback method instead: " + ex);
}
}
}
//...
}getParameterMetadata 함수가 SQLException을 내려줄 수 있는 것을 보니, 실제로 데이터베이스와 직접 커넥션을 맺어 쿼리 한다는 것을 유추할 수 있어요.
저는 Oracle에 있는 테이블에 데이터를 insert하고 있는 상황이었기 때문에 JDBC 내에서는 OracleParameterMetaData 라는 구현 객체를 사용하고 있었는데요. 이 클래스의 구현을 보니, 실제 해당 PreparedStatement에 대한 메타데이터를 조회하는 쿼리를 직접 생성해서 요청을 데이터베이스에 보내고 있습니다.
// OracleParameterMetaData.class
static final ParameterMetaData getParameterMetaData(OracleSql var0, Connection var1, OraclePreparedStatement var2) throws SQLException {
OracleParameterMetaData var3 = null;
String var4 = var0.getSql(true, true);
int var5 = var0.getParameterCount();
OracleParameterMetaDataParser var6 = null;
String var7 = null;
if (!var0.sqlKind.isPlsqlOrCall() && var0.getReturnParameterCount() < 1 && var5 > 0 && !BAD_SQL.contains(var4.hashCode())) {
var6 = new OracleParameterMetaDataParser();
var6.initialize(var4, var0.sqlKind, var5);
try {
var7 = var6.getParameterMetaDataSql(); // metadata를 가져오기 위한 sql 생성
} catch (Exception var14) {
var7 = null;
}
}
if (var7 == null) {
var3 = new OracleParameterMetaData(var5);
} else {
PreparedStatement var8 = null;
try {
var8 = var1.prepareStatement(var7); // 쿼리 실행
ResultSetMetaData var9 = var8.getMetaData();
}
// ...
// ...해결하기: 파라미터 타입 명시
위 내용을 바탕으로 해결 방법은 2가지로 추려질 수 있었는데요.
-
shouldIgnoreGetParameterType의 설정 변경하기첫 번째 방법은
shouldIgnoreGetParameterType설정을 변경하는 거예요.getParameterType을 무시하는 설정을 하면 타입을 지정하기 위해 추가 쿼리를 실행하는 대신, Spring JDBC가 내부적으로null값을 어떻게 설정할지 결정할 수 있어요. 이는 데이터베이스 벤더에 따라 다르게 처리되거나, 처리가 불가능하면 각 데이터베이스 드라이버의 구현체로 이 문제를 위임합니다. 이 설정은 Spring 내에서spring.jdbc.getParameterType.ignore를true로 설정해서 적용할 수 있어요. -
파라미터를 넘길 때 타입 명시하기
두 번째 방법은 파라미터를 전달할 때 파라미터의
SqlType을 명시하는 방법이에요. 값이null이어도 해당 파라미터에 대한 SQL 타입을 명확히 알고 있다면,setNull()이 메타데이터를 조회하기 위해 쿼리를 실행하지 않을 수 있어요.
저는 이 두 가지 방법 중에서 두 번째 방법을 선택했어요. 먼저 전체 시스템에 영향을 줄 수 있는 Spring 설정을 바꾸는 것이 좋은 방법 같지 않았어요. 그리고 특정 값이 null로 설정될 수 있는 경우가 제한적이고 예외적이라고 판단해서 타입 명시로 충분하다고 생각했습니다. 그래서 다음과 같이 직접 해당 파라미터의 SqlType을 선언하는 방식으로 문제를 해결했어요.
return MapSqlParameterSource()
.addValue("originId", internalOriginId)
.addValue("authDate", authDate)
.addValue("cancelDate", cancelDate, Types.NULL)
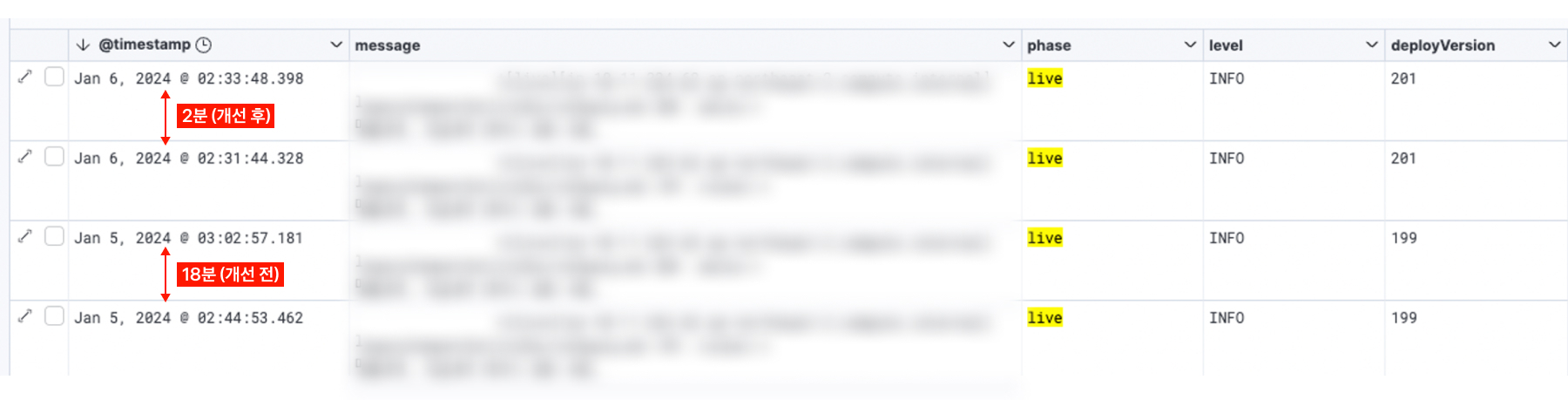
...이렇게 파라미터 타입을 명시하는 개선 작업을 한 뒤, 100만 건 내외의 거래 데이터를 insert 하는 데 18분 소요되던 배치가 2분으로 줄어들었습니다.
다른 데이터베이스에서는 문제가 없을까?
앞서 살펴본 것처럼 Oracle은 타입이 null로 설정될 때마다 메타데이터를 조회해주는 쿼리를 실행하는 것을 알 수 있는데요. 다른 데이터베이스에도 비슷한 문제가 발생할지 궁금했어요. 그래서 MySQL의 드라이버인 mysql-connector에서 PreparedStatement의 구현을 살펴봤습니다. MySQL은 parameterMetaData를 한 번 초기화한 후에는 이 객체를 계속 재사용해서 결과를 제공하고 있었습니다. 즉, 같은 PreparedStatement를 사용한다면, 이미 가져온 parameterMetaData를 재사용해서 결과를 제공하는 것이죠.
// ClientPreparedStatement.java
@Override
public ParameterMetaData getParameterMetaData() throws SQLException {
synchronized (checkClosed().getConnectionMutex()) {
if (this.parameterMetaData == null) {
if (this.session.getPropertySet().getBooleanProperty(PropertyKey.generateSimpleParameterMetadata).getValue()) {
this.parameterMetaData = new MysqlParameterMetadata(((PreparedQuery) this.query).getParameterCount());
} else {
this.parameterMetaData = new MysqlParameterMetadata(this.session, null, ((PreparedQuery) this.query).getParameterCount(),
this.exceptionInterceptor);
}
}
return this.parameterMetaData; // 한번 가져온 parameterMetaData를 재사용
}
}Oracle과 MySQL의 드라이버 구현체 차이가 여기서 확연히 드러나는 것을 확인할 수 있었는데요. MySQL은 ParameterMetaData라는 객체를 PreparedStatement 내부에서 직접 관리하고 있어서 같은 Statement에 대한 메타데이터를 재사용할 수 있는 구조였어요. 반면 Oracle 구현체는 PreparedStatement와 ParameterMetadata 객체 간의 직접적인 연관 없이 별개의 객체로 구성되어 있고, 필요할 때마다 sqlObject를 넘겨 쿼리에 대한 메타데이터를 가지고 오고 있었어요.
이런 구조적 차이가 있어서 Oracle에서는 하나의 PreparedStatement에 null 값을 가진 요청이 있을 때마다 매번 ParameterMetaData 값을 조회하기 위해 관련 함수를 호출했던 것이죠. 이 과정이 성능에 영향을 미쳤고요.
// OraclePreparedStatement.class
public ParameterMetaData getParameterMetaData() throws SQLException {
this.connection.beginNonRequestCalls();
ParameterMetaData var1;
try {
this.ensureOpen();
// PreparedStatement와 별도로 ParameterMetaData를 관리
var1 = OracleParameterMetaData.getParameterMetaData(this.sqlObject, this.connection, this);
} finally {
this.connection.endNonRequestCalls();
}
return var1;
}이번 성능 저하 현상을 해결하면서 저에게 두 가지 중요한 경험이 남았는데요. 첫 번째는 성능 이슈를 진단하기 위해 네트워크 패킷을 직접 분석하는 새로운 접근 방식을 시도한 거예요. 이 방법은 단순히 로그 분석만으로는 알 수 없었던, 문제의 근본 원인이 되는 부분을 파악하는 데 매우 효과적이었어요. 두 번째는 Spring JDBC와 각각의 데이터베이스 드라이버 구현체가 어떻게 상호 작용하고 실행되는지에 대한 깊이 있는 이해를 얻었다는 것이고요.
처음에는 이해하기 어려웠던 성능 문제를 깊이 파악하고 해결해 볼 수 있어 의미 있는 시간이었습니다. 이런 문제 해결에 관심이 있는 분이라면 토스페이먼츠 서버 챕터에 합류해서 함께 도전해 봐요!
Write 강민주 Review 황진성, 박동호 Edit 한주연 Graphic 이은호, 이나눔
토스페이먼츠 Twitter를 팔로우하시면 더욱 빠르게 블로그 업데이트 소식을 만나보실 수 있어요.
