이 포스트는 카카오 IF 컨퍼런스 발표 내용을 관심있는 부분만 정리한 것입니다.
Ref. Batch Performance 극한으로 끌어올리기: 1억건 처리하기
📌 배치로 개발하는 경우의 작업들
1. 일괄 생성
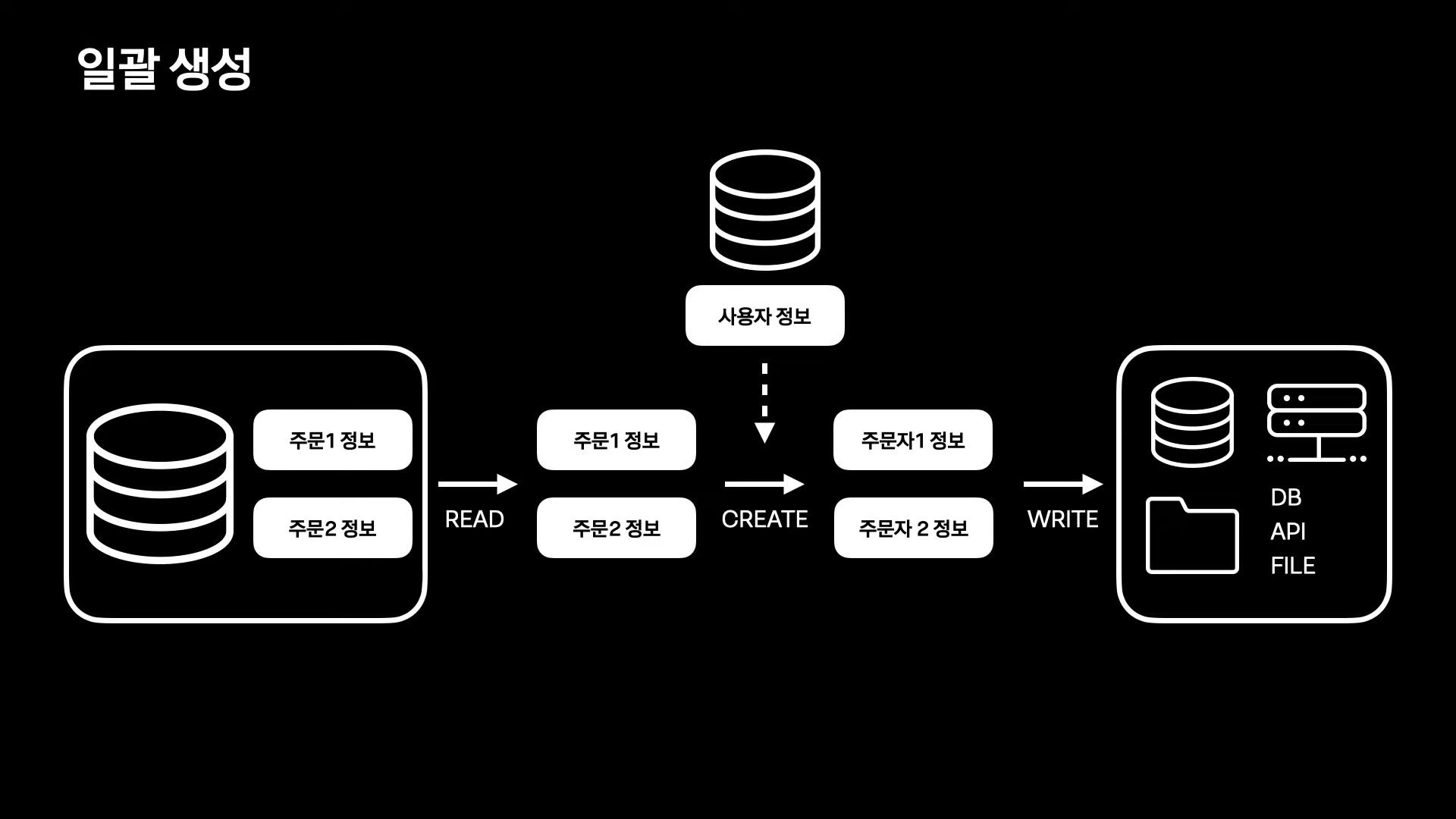
READ - CREATE - WRITE 구조
1) 주문 정보 read
2) 주문 정보에 사용자 정보를 더해 주문자 정보 careate
3) DB, API, FILE 등에 write
2. 일괄 수정
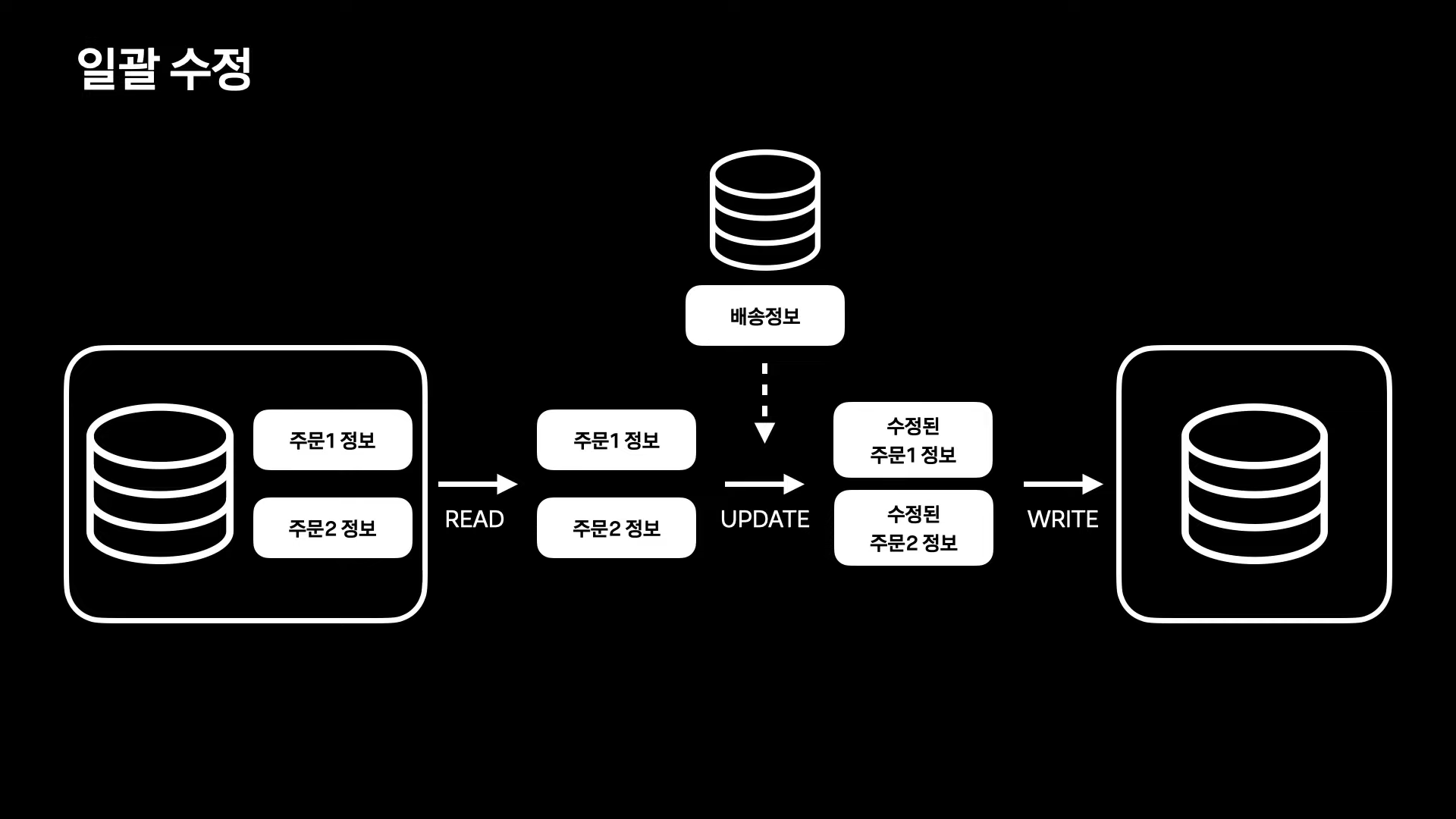
READ - UPDATE- WRITE 구조
1) 주문 정보 read
2) 주문 정보에 배송 정보를 더해 주문 정보 update
3) DB, API, FILE 등에 write
3. 통계
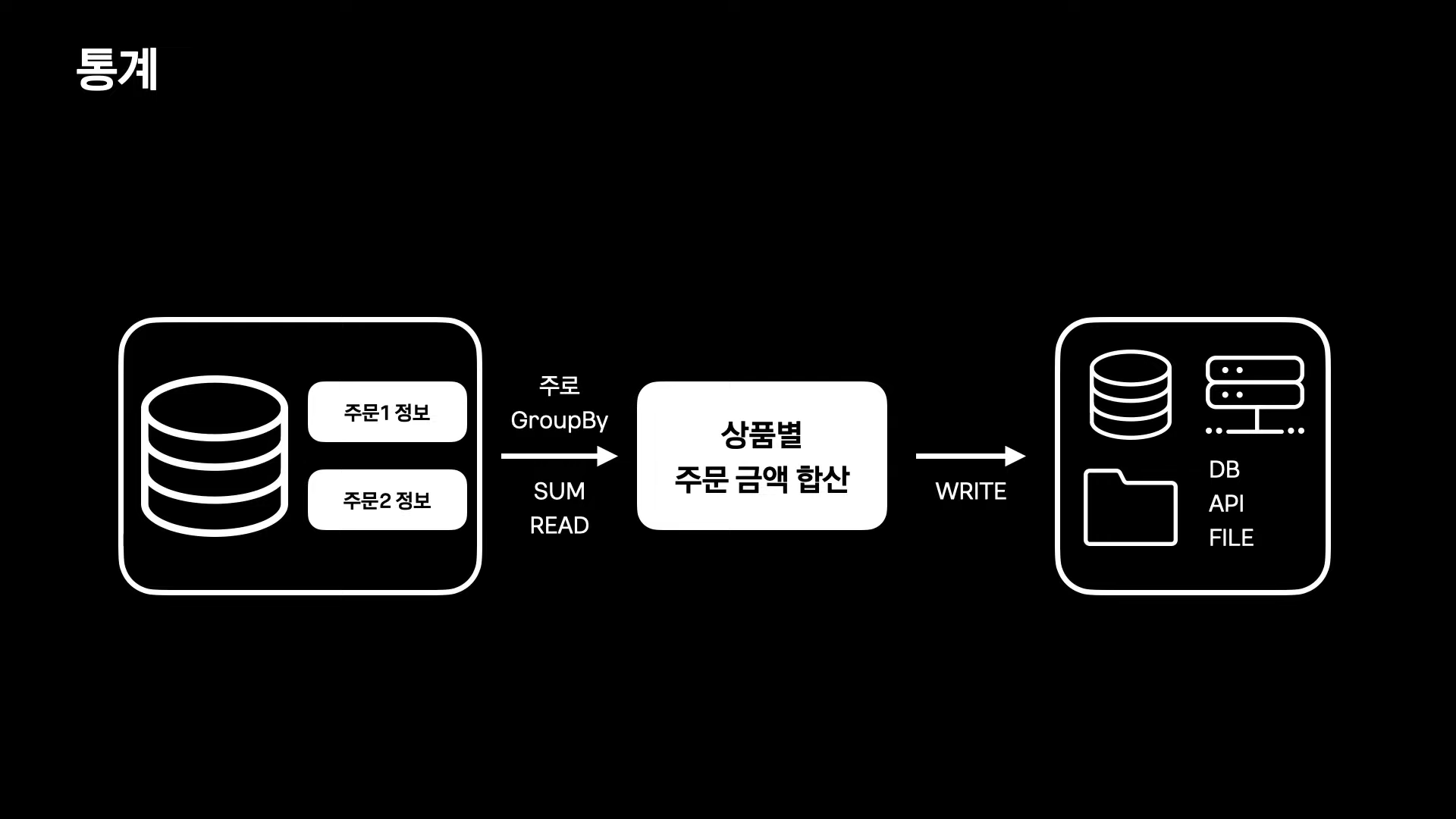
SUM READ - CREATE - WRITE 구조
1) 주로 Group By를 사용해 정보를 sum read
2) 통계 집계 데이터 create
3) DB, API, FILE 등에 write
📌 대형 데이터 READ
Batch 성능 개선의 첫걸음 = Reader 개선
Reader에서 복잡한 조회 조건을 사용하여 데이터를 조회하기 때문에 일반적으로 writer보다 Batch 성능에 많은 영향을 미치는 경우가 많다.
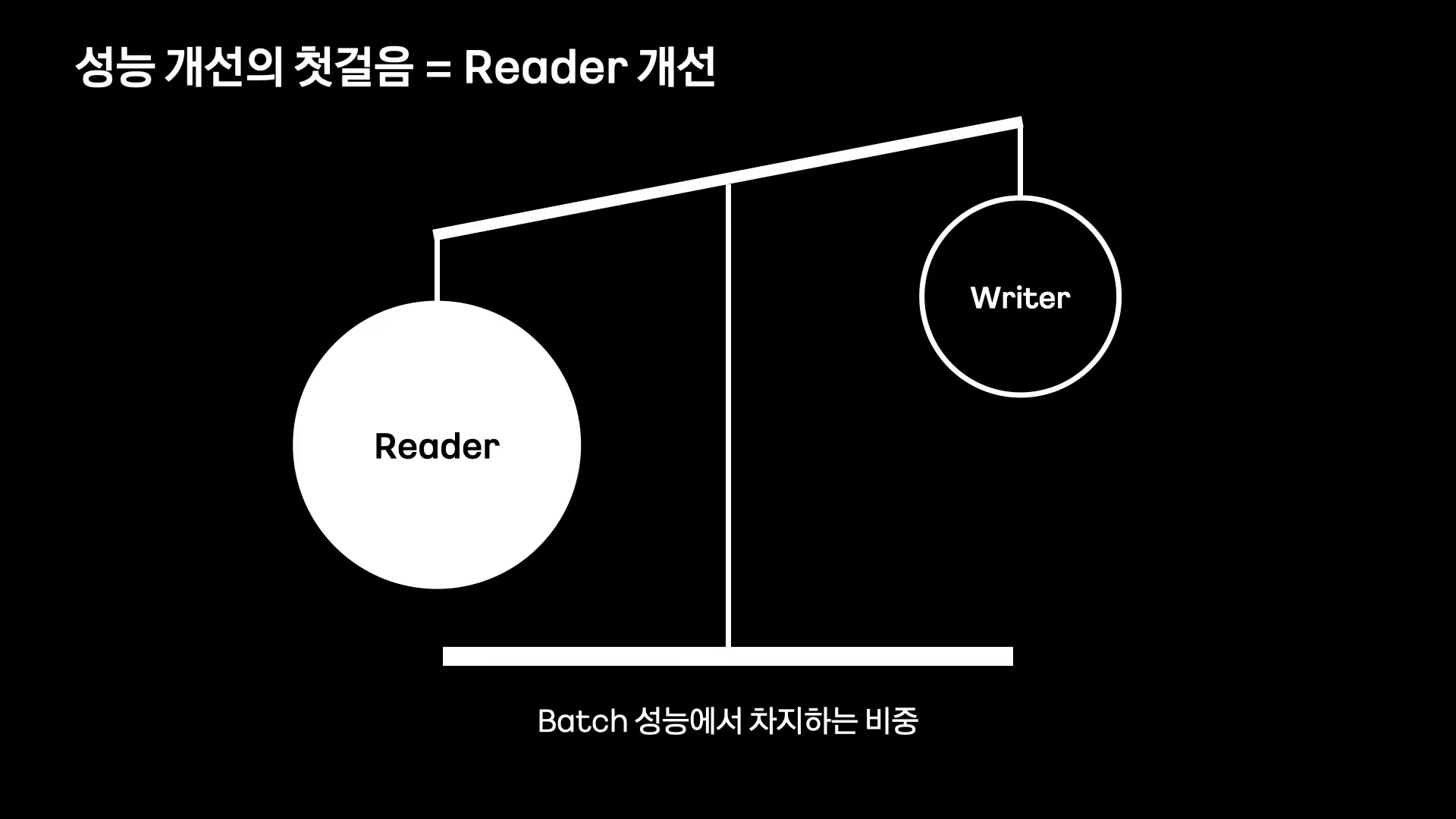
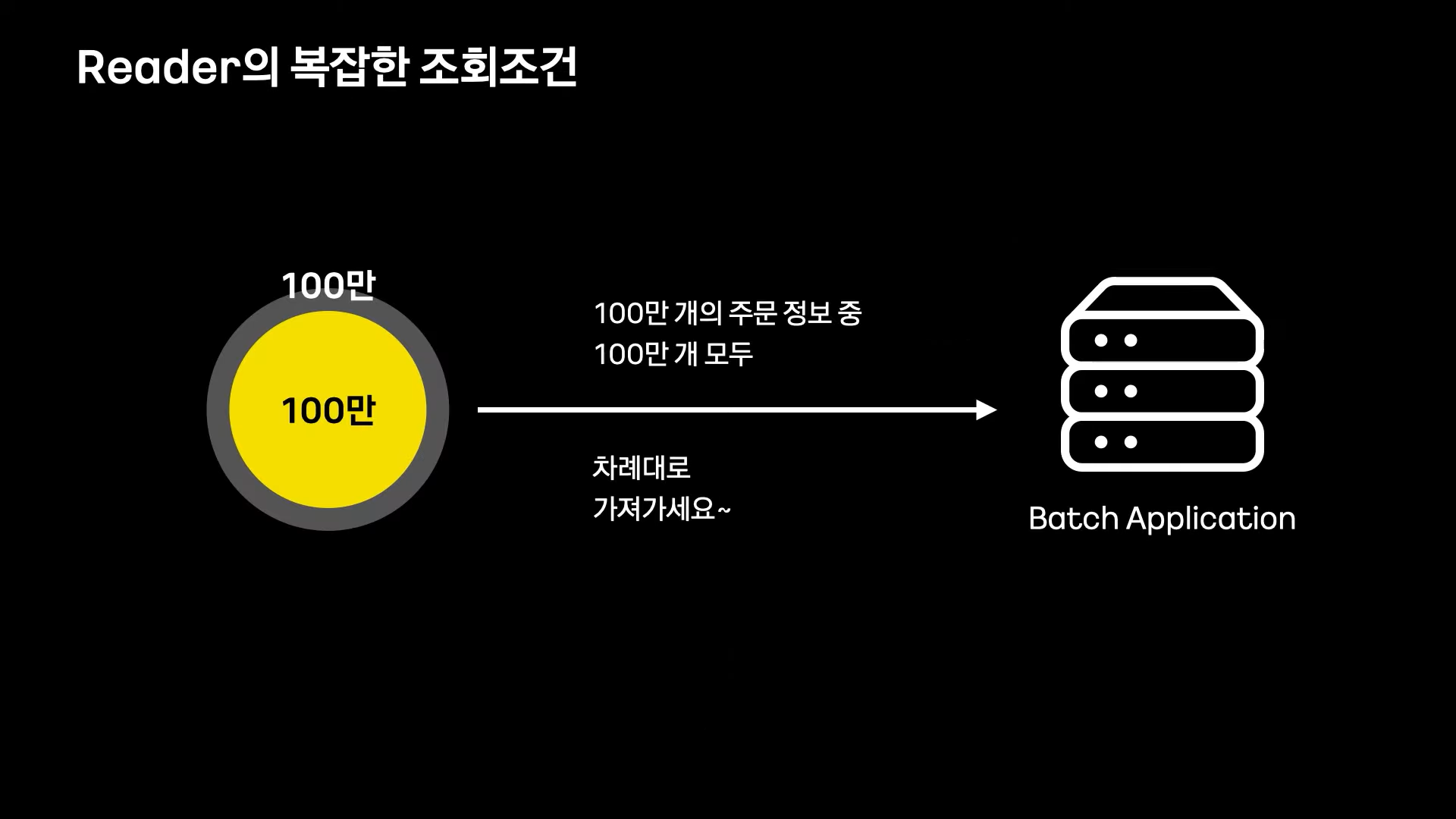
Reader의 복잡한 조회 조건
아래 그림과 같이 100만건의 데이터중 100만건을 처리하는 경우 그냥 처음부터 끝까지 1회 처리하면 됨으로 많은 시간이 소요되지 않는다.
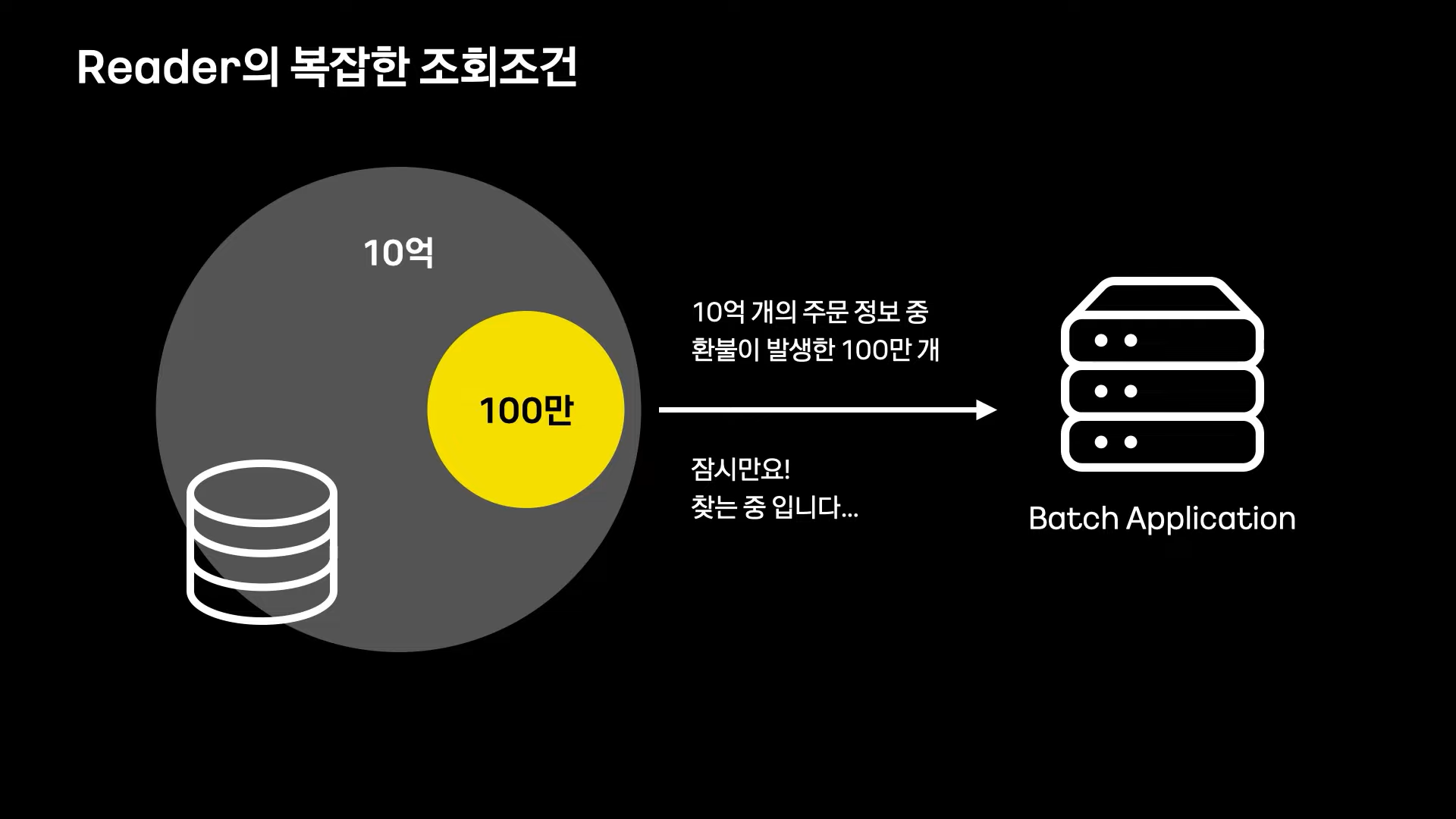
그러나 대부분의 경우 상황은 그렇지 않고, 보통 아래의 예시와 같이 10억개의 많은 데이터 중에 100만건을 추려 처리해야한다.
이때 이 100만건을 찾아 내는 작업이 배치 성능에 큰 영향을 미친다.
간단하게 select 쿼리를 튜닝하는 것 많으로도 큰 성능 향상을 이룰 수 있다.
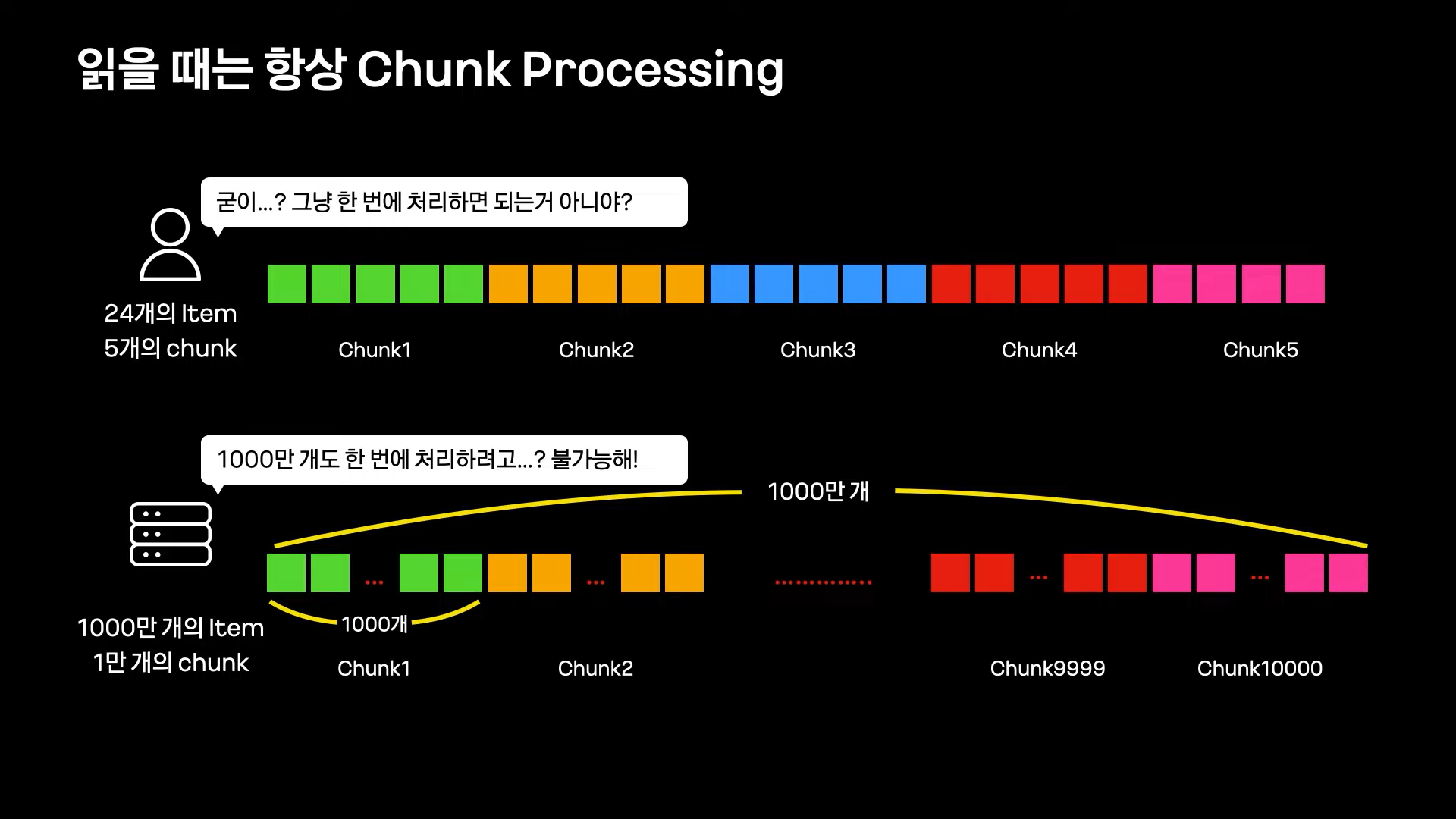
Batch에서 데이터를 읽는 절대적인 방법: Chunk Processing
Chunk Processing:
일반적으로 대량 데이터를 한번에 처리하기는 어려움으로, 부분 단위로 나누어 조금씩 처리하는 방식이다. 이때 그 부분 단위를 Chunk라 정의한다.
Chunk Processing의 짝꿍, Pagination Reader
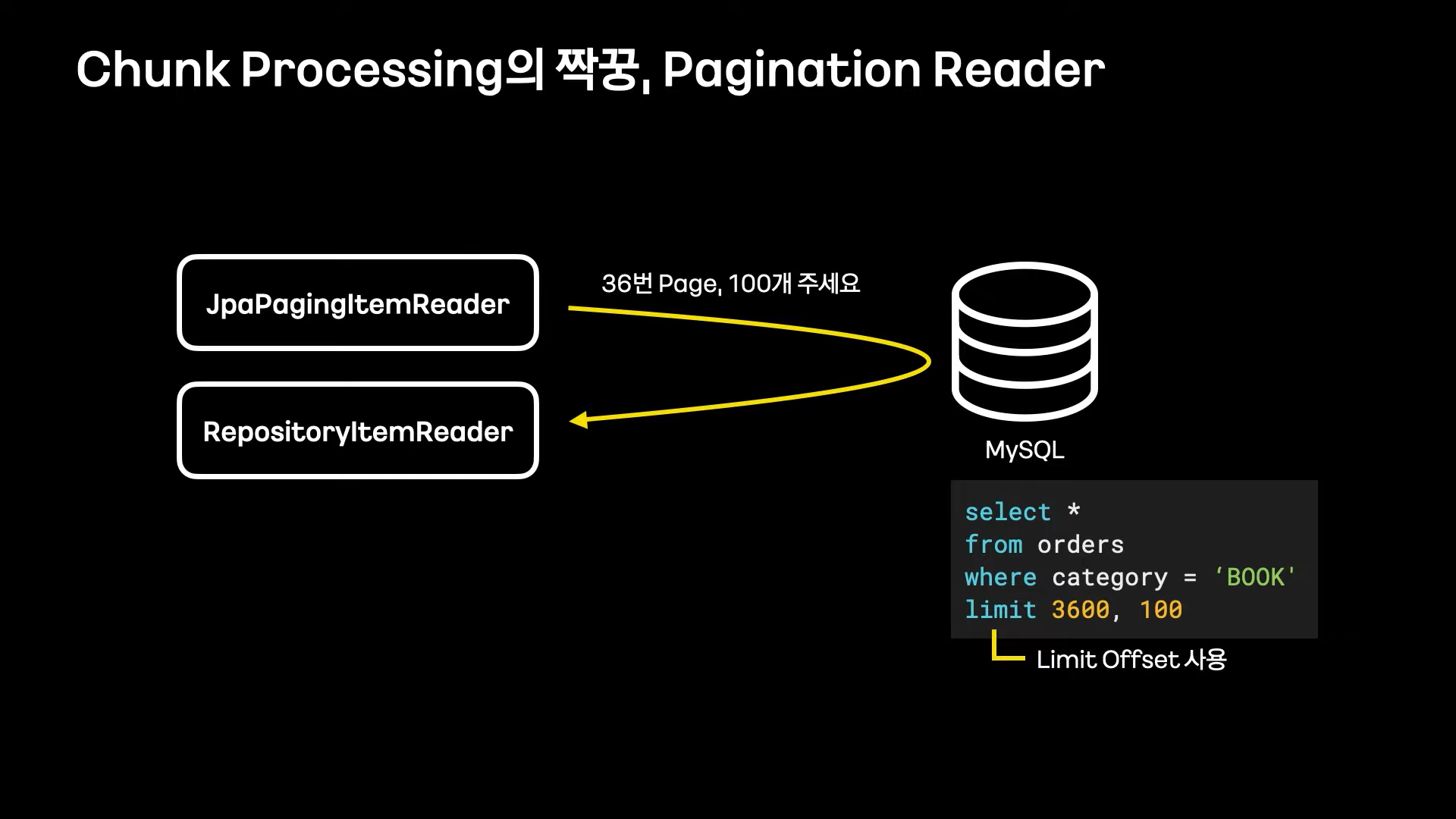
Chunk Processing 처리를 위해 Pagination Reader 객체를 많이 사용한다.
limit offset을 사용하여 직접 Chunk processing을 구현하거나, 이를 사용하는 Reader를 사용하는 것은 대량 처리에 매우 부적합하다.
그 이유는 Limit Offset이 가지는 태생적인 한계 때문이다.
SELECT count(1) FROM orders WHERE category = 'BOOK'
-- 조회 결과: 1억건
SELECT * FROM orders WHERE category = 'BOOK' limit 0, 100
-- 조회 결과: 100건, 조회속도: 매우 빠름
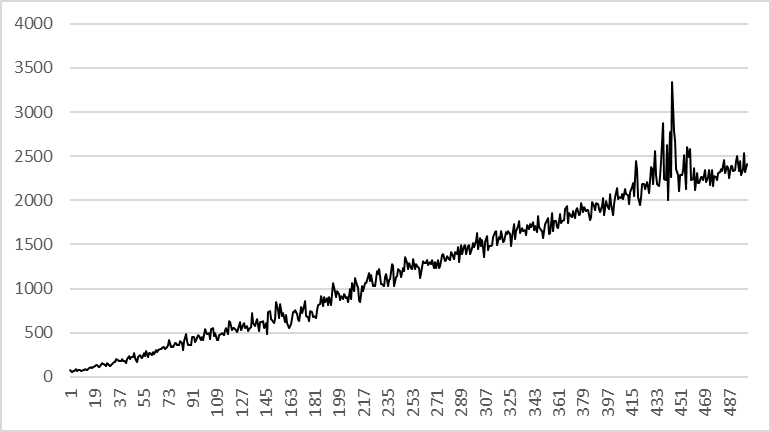
SELECT * FROM orders WHERE category = 'BOOK' limit 50000000, 100
-- 조회 결과: 100건, 조회속도: 매우 느림orders 테이블에 약 1억건의 데이터가 존재한다고 가정해보자.
두번째 쿼리는 매우 빠르게 처리되지만 세번째 쿼리는 조회 조건이 복잡하지도 않고, 조회양 또한 100건밖에 되지 않음에도 불구하고 limit offset 처리에 큰 부하가 걸리면서 전체적인 속도가 매우 느려진다.
이 현상은 offset이 커지면 커질수록 심해지는데, 그 이유는 MySQL이 5천만번째 offset을 찾는데 많은 시간이 소요되기 때문이다.
이러한 문제를 해결하는 방법은 어떤게 있을까?
1. ZeroOffsetItemReader
ZeroOffsetItemReader의 기본 개념은 offset을 항상 0로 유지하는 것.
우선 id와 같은 칼럼으로 대상을 정렬한 후, 동적으로 id 조건을 추가해줘서 offset이 아니라 where id 조건으로 시작지점을 결정하는 방식이다.
SELECT count(1) FROM orders WHERE category = 'BOOK'
-- 조회 결과: 1억건
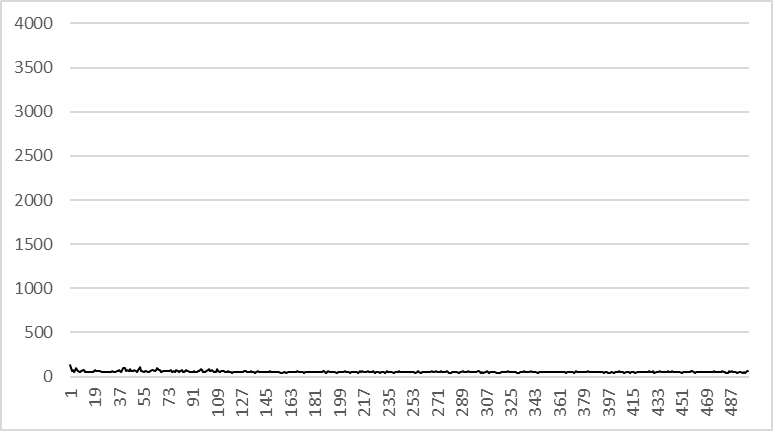
SELECT * FROM orders WHERE category = 'BOOK' and id > 0 limit 0, 100
-- 조회 결과: 100건, 조회속도: 매우 빠름
SELECT * FROM orders WHERE category = 'BOOK' id > 50000000 limit 0, 100
-- 조회 결과: 100건, 조회속도: 매우 빠름이전과 달리 이번 경우에는 세번째 쿼리에서 마찬가지로 50,000,000번 째 부터 100개의 데이터를 조회하였으나 offset을 0로 유지해 두번째 쿼리와 같은 속도로 데이터 조회가 가능하다.
예제
실습코드를 만들어 500만건에 대한 테스트를 해보았습니다.
public void selectByLimit() {
StopWatch stopWatch = new StopWatch();
for(int i = 0; i < 500; i++) {
StringBuffer sb = new StringBuffer();
sb.append("SELECT * FROM zero_off_set ");
sb.append("limit ");
sb.append(String.valueOf(i * 10000));
sb.append(", ");
sb.append("10000");
stopWatch.start();
zeroOffSetDao.selectWithLimit(sb.toString());
stopWatch.stop();
System.out.println("limit select Time : " + stopWatch.getLastTaskTimeMillis() + " millisec");
}
}
public void zeroOffSetLimit() {
StopWatch stopWatch = new StopWatch();
for(int i = 0; i < 500; i++) {
StringBuffer sb = new StringBuffer();
sb.append("SELECT * FROM zero_off_set where id >= ");
sb.append(String.valueOf(i * 10000));
sb.append(" order by id ");
sb.append("limit ");
sb.append("0");
sb.append(", ");
sb.append("10000");
stopWatch.start();
zeroOffSetDao.selectWithLimit(sb.toString());
stopWatch.stop();
System.out.println("zeroOffLemit select Time : " + stopWatch.getLastTaskTimeMillis() + " millisec");
}
}테스트 결과
Limit Offset
Zero Limit Offset
2. 데이터를 조금씩 가져오는 Cursor를 사용하자
애초에 Limit을 사용하지 않는 방식을 사용한다.
MySQL Cursor는 데이터가 없을 때 까지 반복해서 데이터를 가져오는 방식이다.
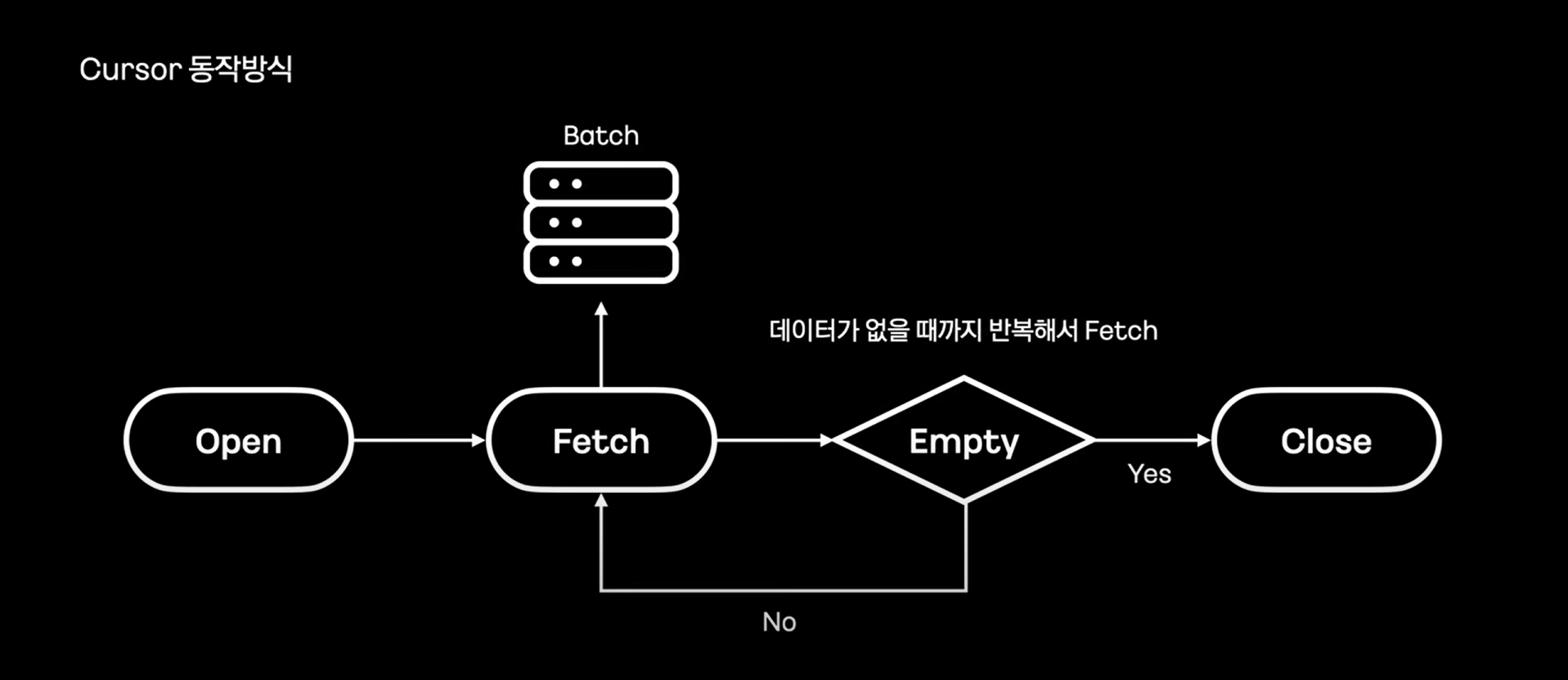
Cursor를 지원하는 스프링 ItemReader
JpaCursorItemReader :
1) MySQL Cursor 방식❌
2) 데이터를 모두 읽고 서버에서 직접 Cursor하는 방식 (OOM 유발).
JdbcCursorItemReader, HibernateCursorItemReader:
1) MySQL Cursor 방식⭕
2) MySQL의 Cursor 를 사용하여 일정 개수만큼 Fetch한다.
📌 데이터 Aggregation 처리
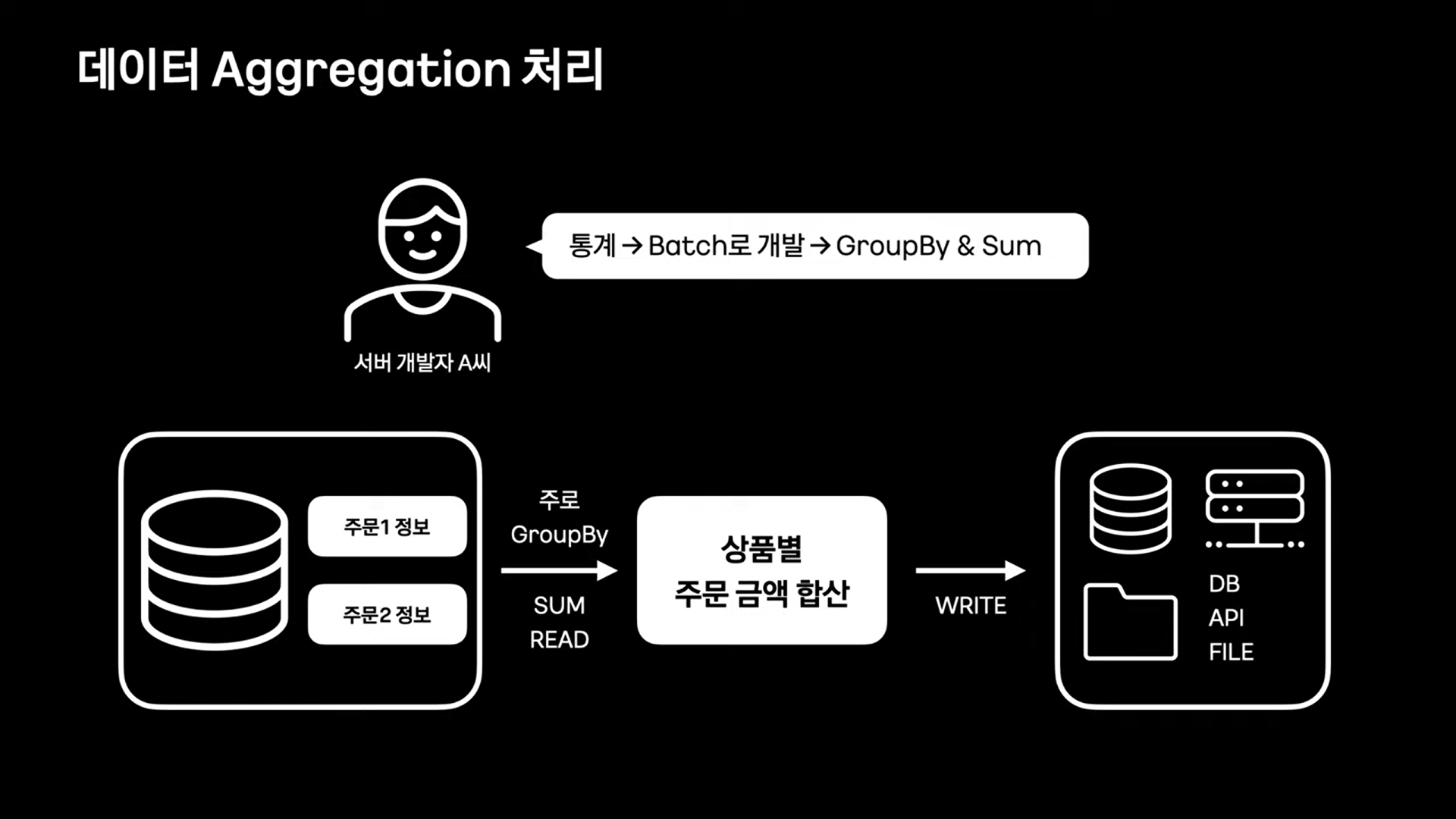
개발자들이 일반적으로 통계를 만드려 할 때 위와 같은 구조를 사용한다.
이러한 구조는 데이터가 적을 경우 매우 합리적이고 개발도 간단하다.
그러나 많은 테이블이 join과 Group by는 잘못된 쿼리 실행 계획을 세우고, 쿼리 튜닝을 까다롭게 만든다.
대부분 fileSort를 한다거나 temporary table을 만들게 되는데, 이런경우 쿼리 속도가 매우 느려진다.
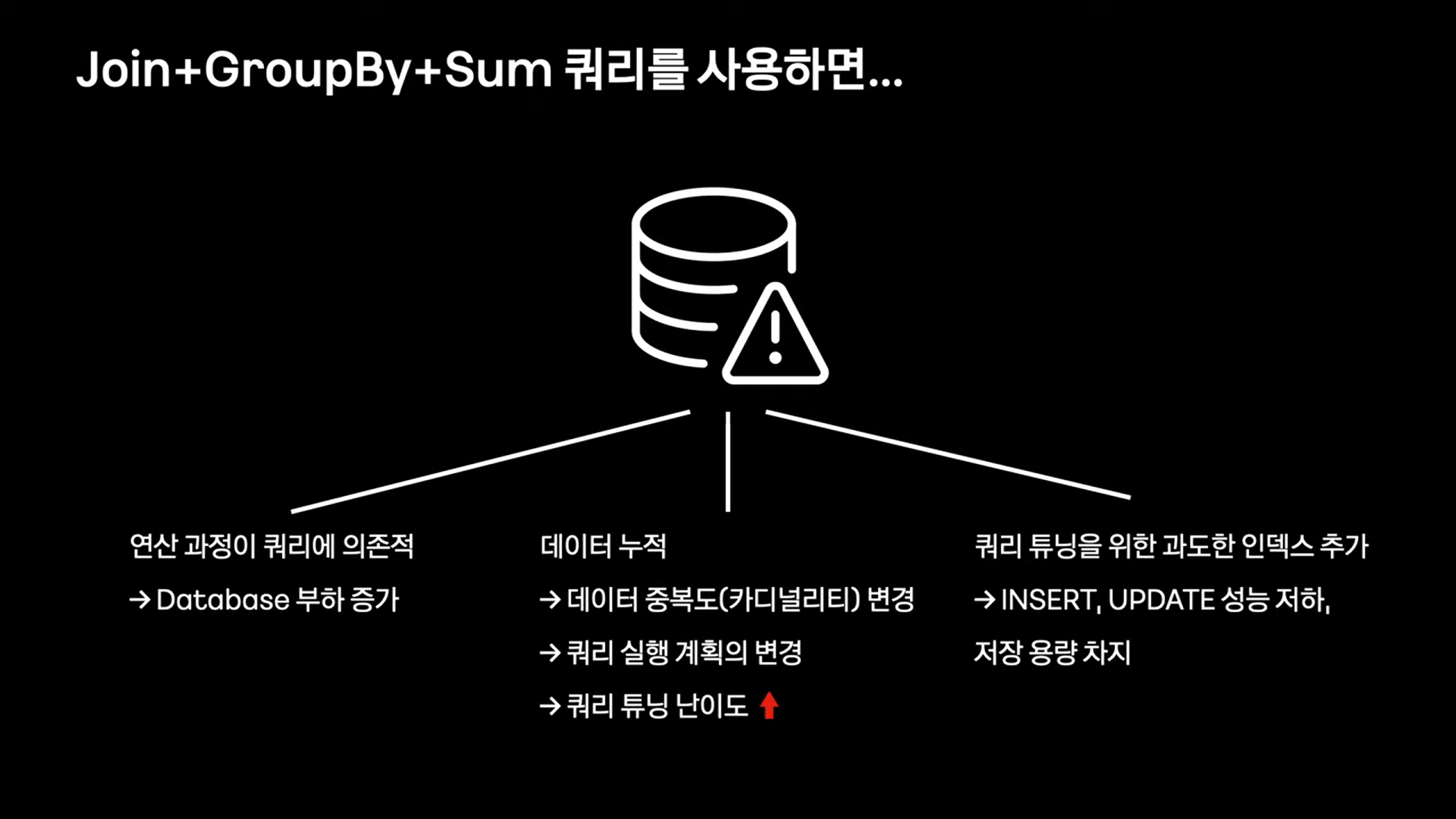
Group By를 포기한다.
쿼리는 단순하게! Group By, SUM을 사용하지 않고 직접 Aggregation한다.
그러나 어플리케이션 내부에서 Aggregation을 하는데 필요한 메모리 공간을 마련하는 것은 불가능하다.
새로운 Architecture
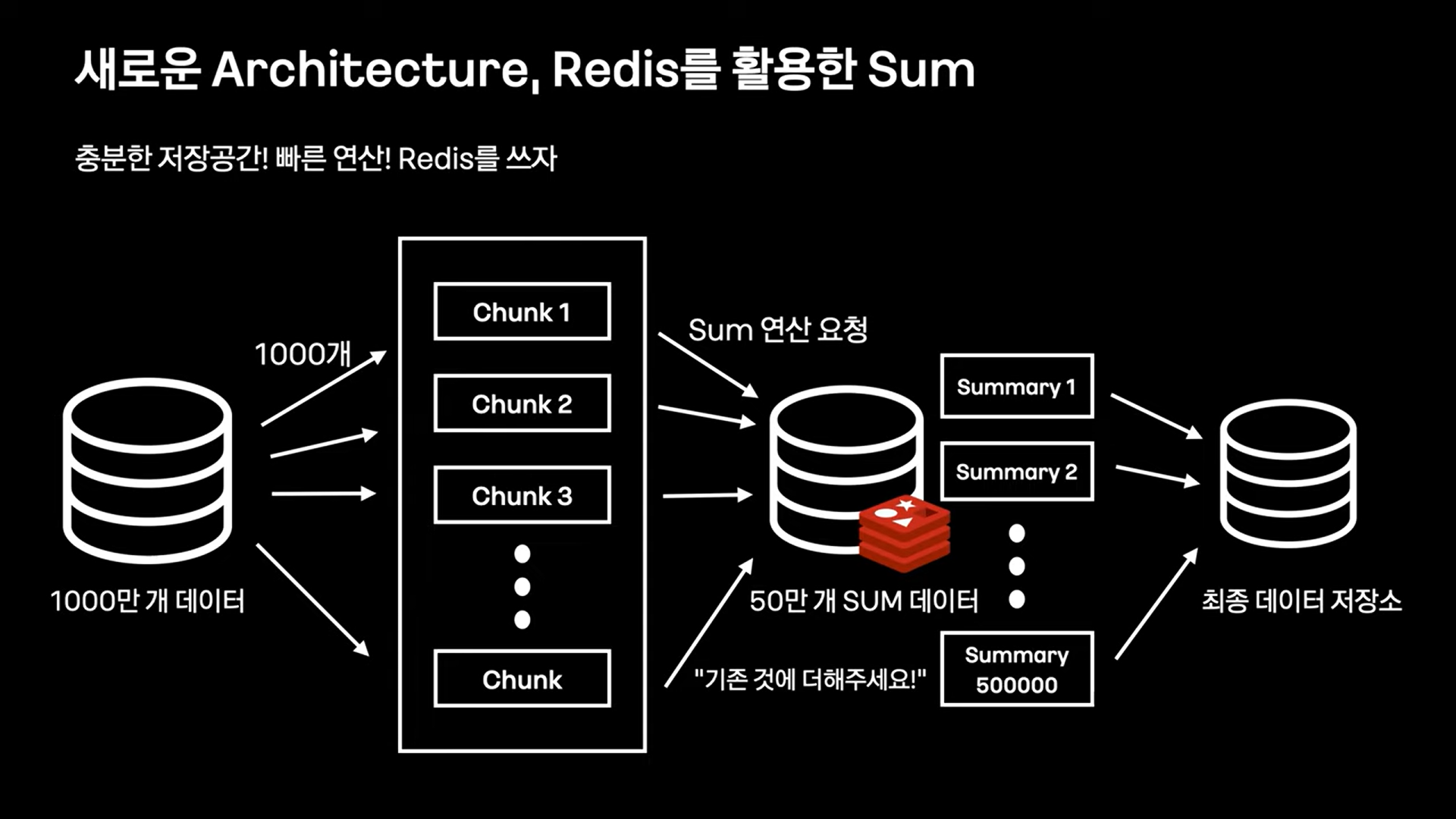
DB에서 Chunk를 받아와 어플리케이션 내부에서 redis로 Sum 연산을 요청한다.
Aggregation이 끝나면 마지막으로 redis에 저장된 집계 결과를 조회해 최종 데이터 저장소에 저장한다.
why redis?
1) 연산 명령어 hincrbym hincrbyfloat 지원 - 메모리 수준에서 합산
2) 넉넉한 메모리 용량
3) In-Memory DB 빠른 저장! 영구 저장X!
redis에 Sum 요청에 드는 비용은 어떻게 처리하는가?
redis pipline을 이용한다.
pipline : 여러 redis command를 묶어 한번에 요청할 수 있는 벌크형 명령어.
예제
간단하게 위 조건을 가진 architecture를 구현해보자.
public void noGroupByRedisArchi(){
StopWatch stopWatch = new StopWatch();
Jedis jedis = new Jedis("localhost", 6379);
jedis.getClient().setTimeoutInfinite();
stopWatch.start();
StringBuffer sb = new StringBuffer();
for(int i = 0; i < 500; i++) {
StringBuffer sql = new StringBuffer();
sql.append("SELECT * FROM zero_off_set where id >= ");
sql.append(String.valueOf(i * 10000));
sql.append(" order by id ");
sql.append("limit ");
sql.append("0");
sql.append(", ");
sql.append("10000");
// zeroOffset으로 1만건씩 데이터 조회
List<ZeroOffSet> zeroOffSets = zeroOffSetDao.selectWithLimit(sql.toString());
// redis pipeline을 사용해 1만건당 한번씩 요청
Transaction pipeline = jedis.multi();
for(ZeroOffSet dto: zeroOffSets){
sb.delete(0, sb.length());
sb.append("dw,");
sb.append(dto.getReqDt());
sb.append(",");
sb.append(dto.getSvcId());
sb.append(",");
sb.append(dto.getUserId());
String key = sb.toString();
pipeline.incrBy(key, 1);
}
pipeline.exec();
}
// redis에 집계된 데이터 조회하여 AggregationDto 객체 생성
Set<String> keys = jedis.keys("dw,*");
for(String key: keys){
String[] split = key.split(",");
Long listSize = Long.valueOf(jedis.get(key));
AggregationDto build = AggregationDto.builder()
.reqDt(split[1])
.svcId(split[2])
.userId(split[3])
.cnt(listSize)
.build();
}
stopWatch.stop();
System.out.println("no-group-by-redis-archi turnaround time " + stopWatch.getTotalTimeSeconds() + "seconds");
}group by

Redis Architecture

위 처럼 간단한 쿼리의 경우 오히려 group by가 더 좋은 퍼포먼스를 보여주었지만, group by는 group by에 사용하는 column 수에 영향을 받는 반면 Redis 구조는 그렇지 않기 때문에 쿼리가 조금만 더 복잡해 지거나 그룹핑하는 칼럼수가 많아지면 Redis 구조가 훨씬 좋은 퍼모먼스를 낼 것으로 생각된다.
📌 대량 데이터 WRITE
안정적인 Write 성능을 보장하려면 Batch Insert, 명시적 쿼리 이 두가지 원칙을 지켜주어야 한다.
이를 위해서 JPA를 사용하는 것을 권장하지 않는데, 그 이유는 다음과 같다.
안녕 JPA...
Batch 환경에서 JPA가 잘 맞지 않는 이유에 대해 알아보자.
Dirty Checking과 영속성 관리
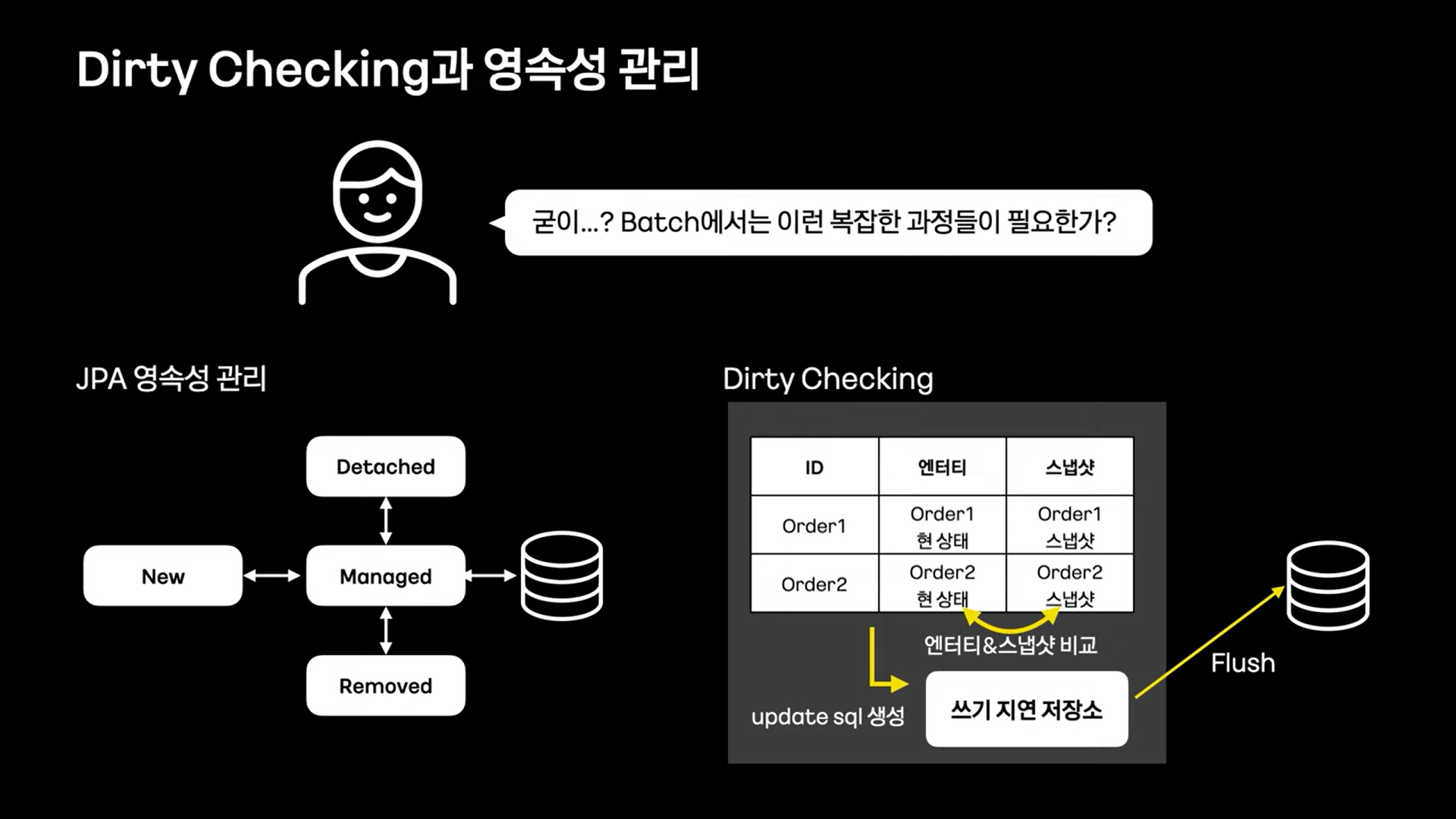
JPA에서는 작은 객체 하나라 할 지라도, 위 그림과 같이 복잡한 영속성 관리를 받는다.
Batch 환경에서는 데이터는 read하는 부분과 write 하는 부분이 명확한데, 이러한 환경에서 dirty checking은 불필요한 로직 체크로 인해 큰 성능 낭비가 될 수 있다.
UPDATE시 불필요한 칼럼도 UPDATE

JPA가 업데이트 할 때 필요한 칼럼 뿐만아니라 불필요한 부분도 함께 업데이트한다.
배치의 특성상 원하는 업데이트 쿼리가 있는데 궂이 다른 부분에 손을 대는 것도 리스크가 있다.
물론 JPA에는 Dynamic UPDATE가 있어 필요한 부분만 업데이트가 가능하지만, 이는 쿼리를 동적으로 생성해 오히려 더 큰 성능 저하를 유발 할 수 있다.
JPA Batch Insert 지원이 어려운 부분
JPA에서는 Batch Insert를 지원하긴 하지만, ID 생성 전략을 IDENTITY로 하게 되면 JPA의 사상과 맞지 않는 다는 이유로 Batch Insert를 지원하지 않는다.
JPA 사용시 대부분의 전략을 IDENTITY로 하다보니 JPA에서 Batch Insert는 거의 사용이 불가능하다.

Batch Insert
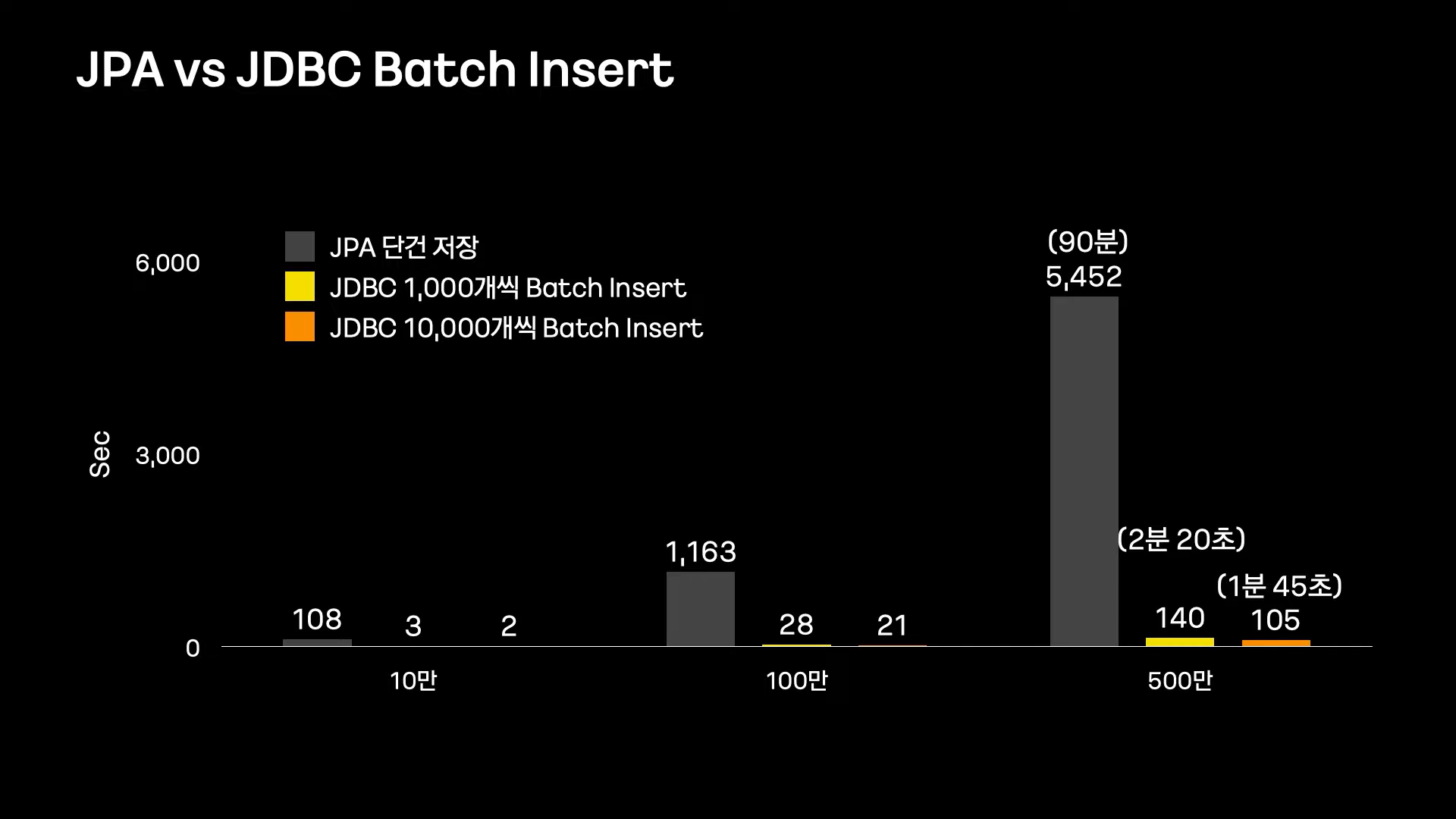
JPA 단건 저장과 Batch Insert의 성능비교
명시적 쿼리

일반적인 JDBC Batch Insert 구현 방식
