패러다임의 불일치
데이터를 다룰 때 애플리케이션은 객체를, 관계형DB는 테이블을 사용한다.
이 두 유닛에는 아래와 같은 차이가 존재한다.
1. 연관관계의 차이
Member 객체
class Member {
int id;
Team team;
Group group;
String username;
}Member 테이블
MEMBER
id int,
teamId int,
groupId int,
username varchar
객체는 연관맺은 다른 객체를 참조하고있다. ( 통째로 갖고 있다. )
이와 다르게 테이블은 외래키를 통해 연관관계를 맺는다.
2. 상속
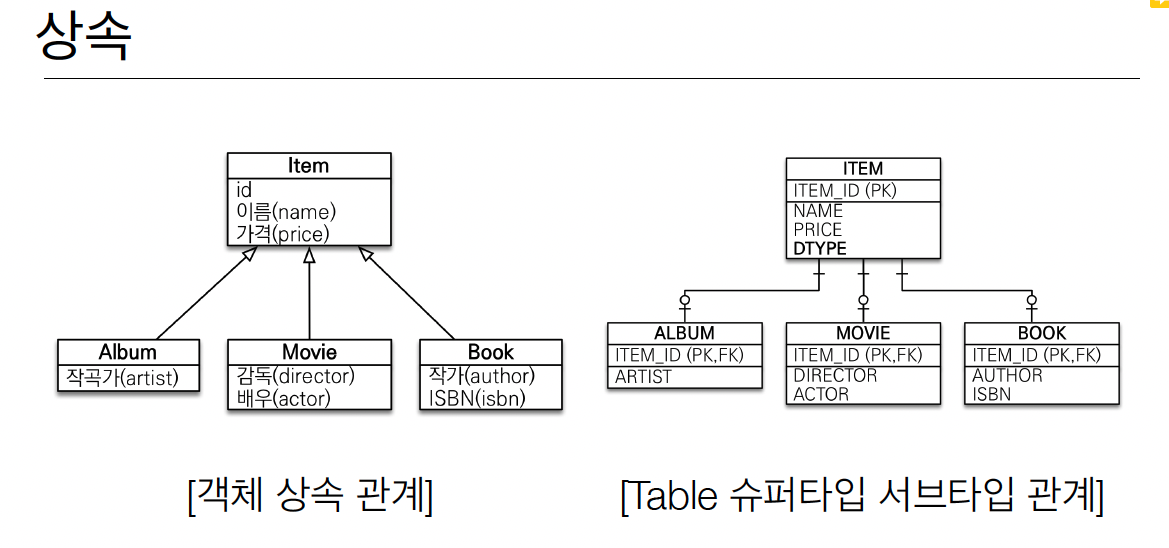
테이블에서는 상속의 개념이 없어 이와 비슷한 구조를 설계하게되면 거의 항상 다른 테이블과 조인을 해야한다. 또 데이터를 추가하기도 복잡해 애초에 DB에 저장할 데이터는 상속관계를 사용하지 않는다.
이 때문에 애플리케이션도 결국은 SQL중심적으로 개발되는 경우가 많다.
패러다임 차이가 낳은 문제점
이러한 패러다임의 차이 때문에 여러가지 한계점이 발생한다.
1. SQL 중심적 개발
테이블로 저장된 데이터를 객체로 바꿔 애플리케이션에서 사용하는 것이 가장 좋겠지만, 이를 구현하는 것은 상당한 비용을 필요로한다.
때문에 지금까지 많은 경우 객체 설계 자체를 테이블에 맞춰 SQL 중심적 개발을 하는 경우가 많았다.
Member 객체
class Member {
int id;
int teamId; // **
int groupId; // **
String username;
}Member 테이블
MEMBER
id int,
teamId int,
groupId int,
username varchar이런 경우 개발은 좀 더 간단 할 수 있으나, 좋은 객체지향 애플리케이션이라 부르기 어렵고 유지보수에 들어가는 비용또한 증가한다.
2. 탐색
연관관계를 갖는 객체들은 자유로운 탐색이 가능하다.
아래 코드 처럼 member객체와 관계를 맺는 team객체와 class객체를 언제든 탐색할 수 있다.
Team team = member.getTema();
Group gourp = member.getGroup();이와달리 테이블에서 받아온 객체는 처음 SQL에 의해 탐색 범위가 제한된다.
아래 쿼리처럼 team 객체만 조인하는 경우 member객체에서 class 객체를 탐색할 수 없다.
SELECT * FROM MEMBER m JOIN GROUP t ON (m.teamId = t.id);Team team = member.getTeam();
Group group = member.getGroup(); // Null3. 엔티티 신뢰
SQL에 의해 객체간 탐색이 제한되므로, SQL을 열어보지 않는 한 연관관계를 맺고있는 다른 객체를 신뢰할 수 없다.
Team team = member.getTeam(); // Null?
Group group = member.getGroup(); // Null?📖 ~ ~ ~ ~
지금 회사 프로젝트에서 개발하는 애플리케이션에서 위에서 이야기한 한계들을 많이 느낄 수 있었다.
모든 객체들이 테이블 형태로 설계되어있어 조금만 다른 값을 조회하려면 대부분 새로운 쿼리가 필요했다.
또 연관을 맺고있는 객체들을 한번에 컨트롤하기 어려워 3 테이블이 합쳐진 슈퍼 dto도 정말 많이 사용했다. ( 물론 MyBatis을 잘 사용한다면 이러지 않을 수 있다. )
제일 싫었던 것은, 다른 테이블의 칼럼 한개를 추가로 가져오기 위해 새로운 vo를 사용하는게 번잡스러워 그냥 원래 vo에 다른 테이블의 필드를 추가하는 경우였다.
귀찮아 SQL을 보지 않고 사용한 get 메서드 때문에 nullPointException도 심심치 않게 만날 수 있었다.
~ ~ ~ ~ 📖
패러다임의 극복
MyBatis를 비롯한 많은 기술에서는 이러한 문제를 해결하기 위해 다양한 편의 기능을 제공하고 있지만, 근본적인 해결책이라고 하기에는 무리가있다.
한번은 데이터를 테이블이 아닌 객체 형태로 저장하려는 시도로 객체-지향 데이터베이스(OODB)가 개발되었지만 일단 망했다고 한다.
JAP는 애플리케이션과 DB사이에 위치하여 데이터를 애플리케이션에서는 객체, DB에서는 테이블로 사용할 수 있도록 매핑하는 기술이다.
JPA의 핵심 기술
앞서 언급했듯, 테이블 구조의 데이터를 객체 구조로 매핑하는 작업은 상당한 비용을 필요로한다. 이 때문에 언듯 보면 JPA는 불필요하게 많은 리소스를 낭비하는 것처럼 보인다.
JPA에서는 크게 2가지 기술을 사용해 이런 문제를 해결했는데, 이 두 기술을 제대로 적용한다면, 단순히 리소스를 절약하는 것을 넘어 오히려 더 좋은 성능을 내는 것도 가능하다.
1. 캐싱과 버퍼링
애플리케이션이 DB에 접속하는 것은 비교적 무거운 작업이다.
캐싱과 버퍼링 기술은 가능한 애플리케이션이 DB에 접속하는 빈도를 낮춰 성능 향상을 도모한다.
-
캐싱 : DB에서 한번 조회했던 객체를 메모리에 저장하여, 같은 데이터를 재 조회 할 경우 DB가 아닌 메모리에서 가져오는 기술.
-
버퍼링 : 반복적인 INSERT 혹은 UPDATE 작업이 필요한 경우, 여러 쿼리를 메모리에 모아 한번에 DB로 전송하는 기술.
2. 지연로딩과 즉시로딩
class Member{
String id;
Team team;
Group group;
}위 Member 클래스는 객체이므로 언제든 team, group 객체를 참조해 사용할 수 있어야한다.
이를 위해서는 DB에서 Member 객체를 조회할 때 항상 team과 group 객체를 함께 가져와야하는데, 이는 큰 리소스 낭비다.
JPA는 이를 위해 지연로딩이란 기술을 지원한다.
지연 로딩이란, DB에서 Member객체를 조회할 그 당시에는 Team, Group 객체를 가져오지 않지만, member.getTeam(), member.getGourp()으로 하위 객체를 사용하는 그 즉시 Team, Group 객체를 조회하는 방식이다.
앞서 애플리케이션이 DB에 접속하는 작업이 무겁다고 이야기 했는데, 이렇게 매번 DB를 조회하는 경우 오히려 성능이 저하될 것만 같다.
이를 위해 JPA에서는 즉시로딩을 지원한다.
즉시로딩이란 Member를 조회할 때 Team과 Group 객체를 한꺼번에 모두 조회하는 방식이다.
