종류
MSSQL 인덱스는 B-Tree 구조
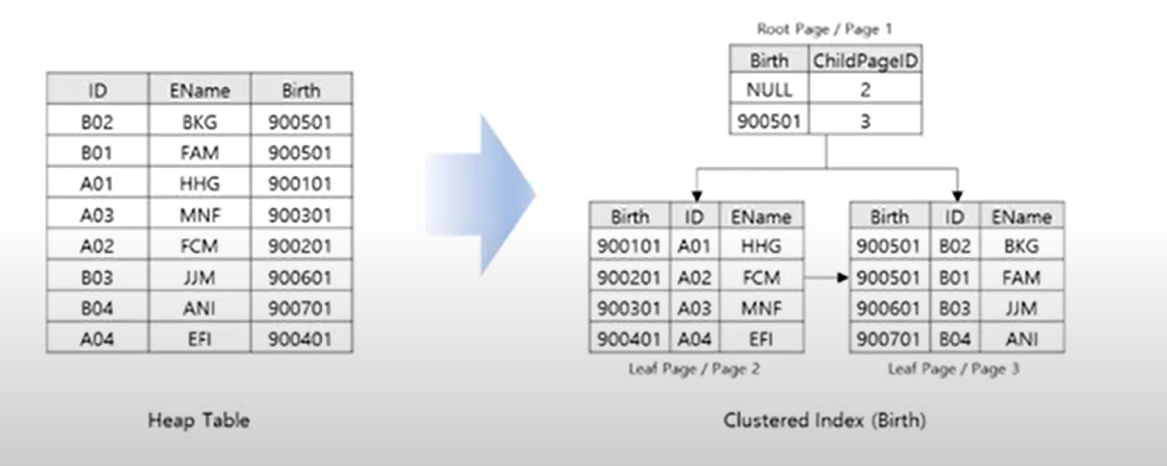
1. 클러스터형 인덱스 (Clustered Index)
- 인덱스 Leaf Node에 실제 데이터를 가짐.
( 📢 흔히 클러스터형 인 덱스를 키워드 아래에 바로 모든 설명이 있는 사전과 비교한다. )
-
인덱스 키 값을 기준으로 데이터를 상시 정렬. (통상적으로 PK로 인덱스 키를 잡는다.)
= Insert가 발생하면 전체 정렬 필요 -
테이블 당 1개만 생성가능. (데이터 테이블과 인덱스 테이블이 물리적으로 같음)
-
클러스터형 인덱스를 생성하는 순간 해당 테이블의 데이터는 Heap 방식이 아닌 B-Tree 구조로 저장된다.
create clustered index 이름 on 테이블 (칼럼)
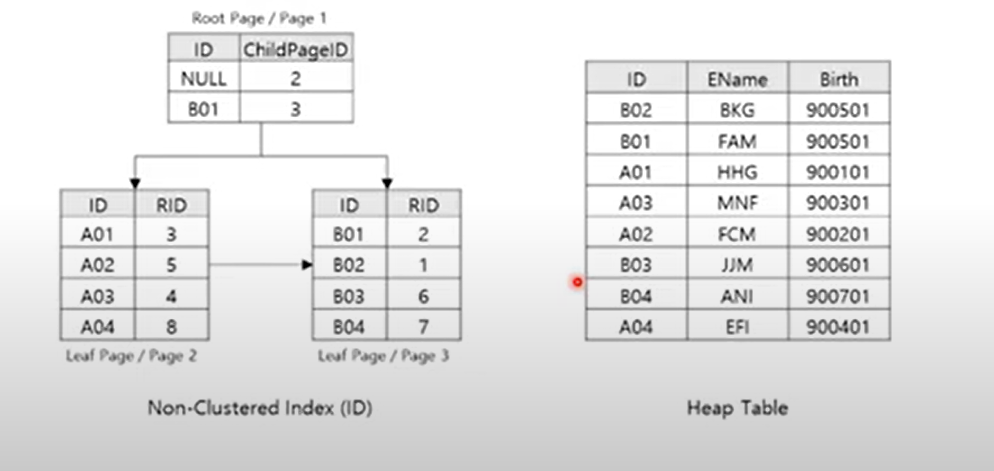
2. 비 클러스터형 인덱스 (Non-Clistered Index) [DEFAULT]
-
Leaf Node에 실제 데이터가 아닌 데이터의 키값을 저장 (=RID)
-
데이터 테이블과 독립적으로 생성
-
테이블당 최대 999개 생성가능
create nonclustered index 이름 on 테이블 (칼럼)
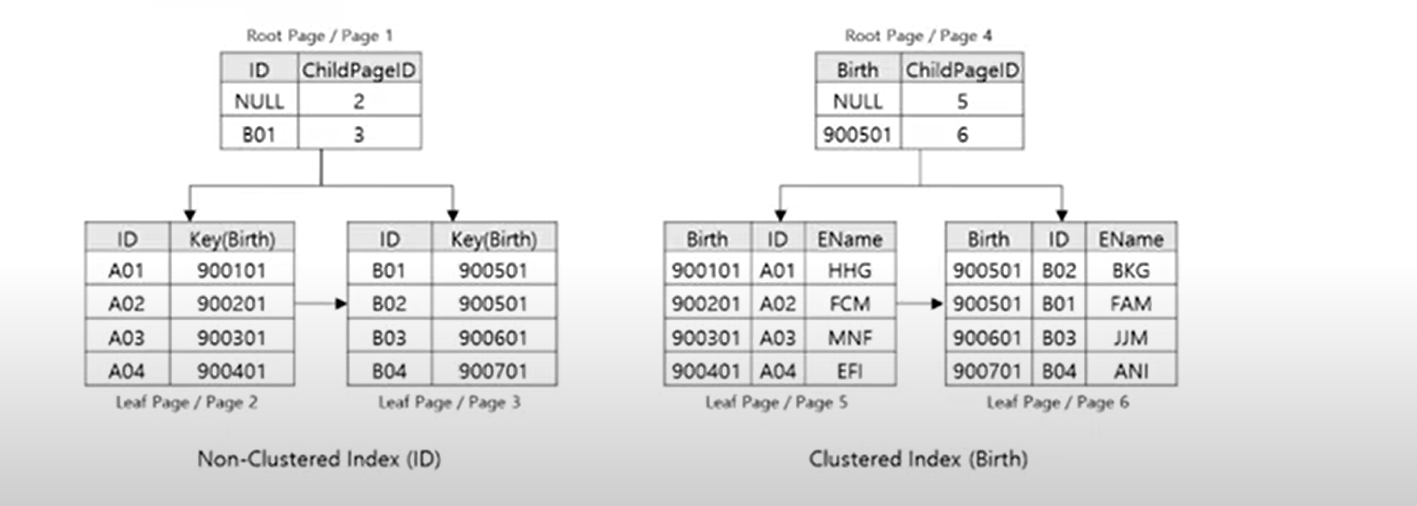
3. 클러스터 + 비 클러스터형 복합형 인덱스
- 인덱스의 RID 값 대신 Clustered Index 키 값을 가지고있다.
- Clustered Index의 Root Node 부터 탐색
4. 힙테이블
- 인덱스가 아닌 일반적인 데이터 저장 테이블로 데이터 추가시 맨 아래에 저장된다.
📢 Clustered-Index가 없는 테이블 저장방식.
= 때문에 인덱스가 추가될 때와 달리 데이터 재정렬이 발생하지 않음.
인덱스를 통한 스캔 방식
1. Table Scan
-
인덱스를 타지 않고 힙테이블의 모든 데이터를 스캔.
-
Clustered Index가 존재한다면 Clustered Index Scan으로 변경됨.
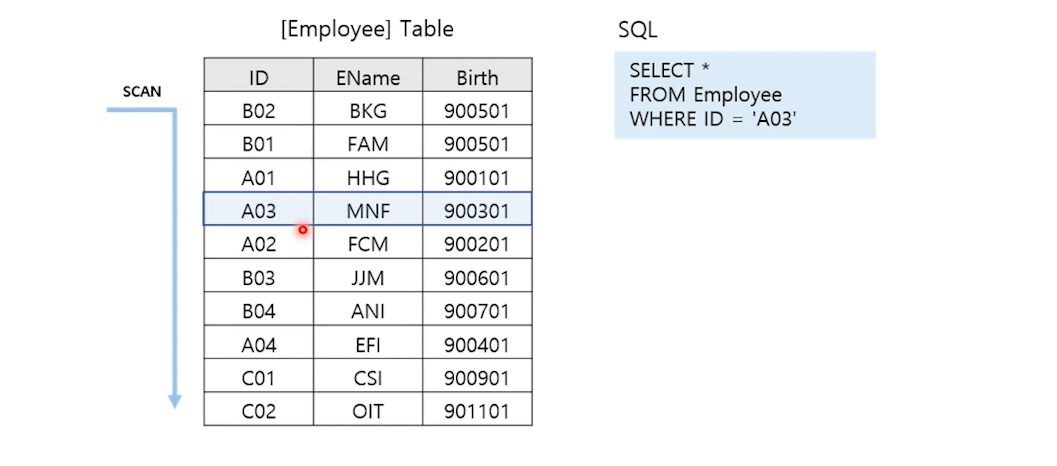
→ 처음부터 모든 데이터를 스캔하며 탐색한다.
2. Clustered Index Scan
-
클러스터드 인덱스의 Leaf 페이지를 모두 탐색
(✏️ B-tree 구조로 이루어진 테이블의 모든 데이터를 스캔) -
인데스 칼럼을 가공 하거나 조건에 제시된 칼럼이 Clustered Index에 포함되지 않는 경우 발생
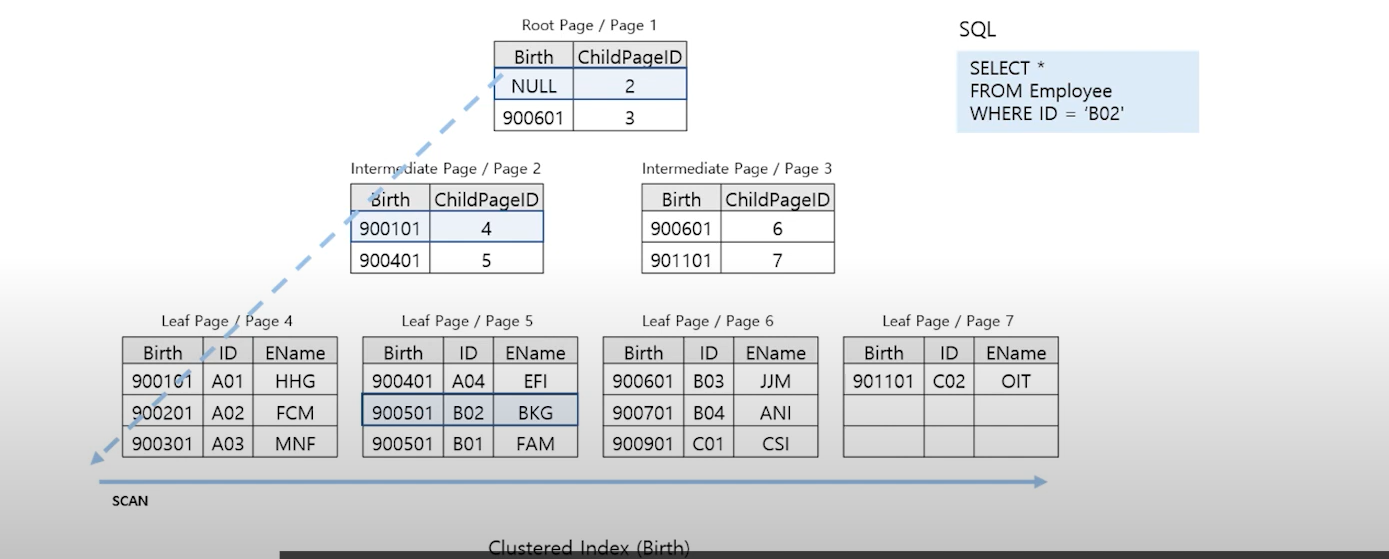
→ 인덱스키에 포함되어있지 않은 ID 칼럼을 조건으로 사용했으므로 모든 leaf page를 탐색한다. 단, 물리적으로 정렬되어있는 데이터 이므로 Table Scan와 차이가있음.
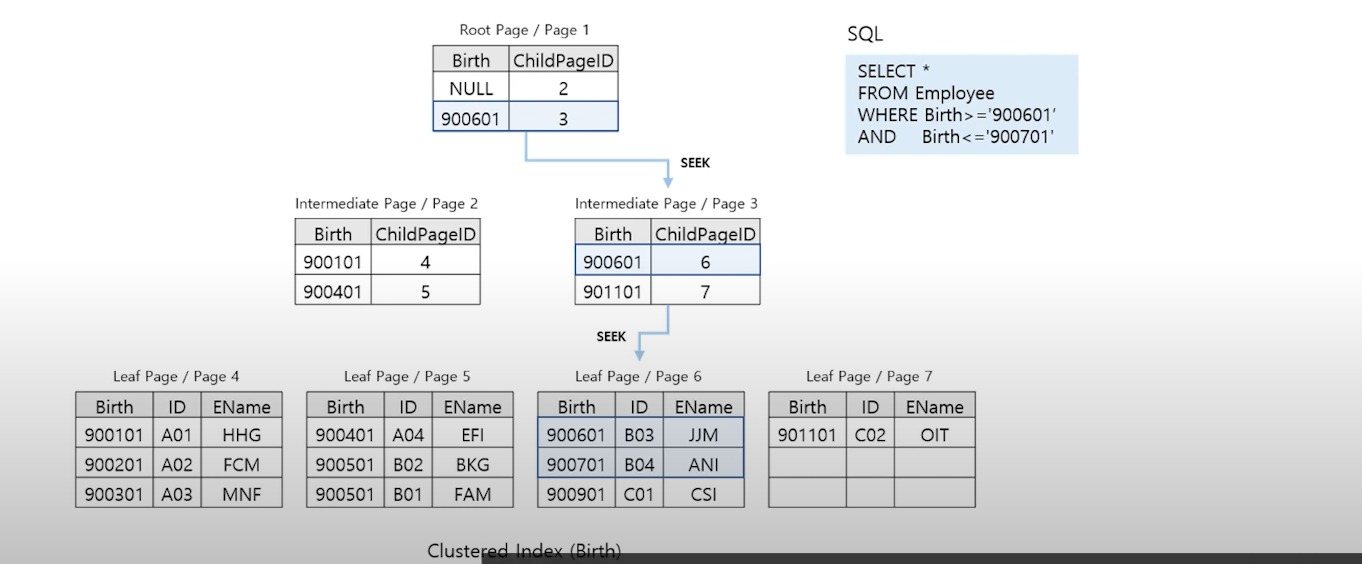
3. Clusetered Index Seek
-
인데스의 Root 부터 Leaf까지 필요한 페이지만 수직적으로 탐색
-
WHERE 조건에 제시된 칼럼이 Clustered Index에 포함되는 경우 발생.
4. Non-Clustered Index Scan
-
Non-clustered Index의 Leaf 모든 페이지 탐색
-
인데스 칼럼을 가공(or 데이터 타입을 변경)하거나 선두 칼럼에 대한 검색조건이 없을 때 발생
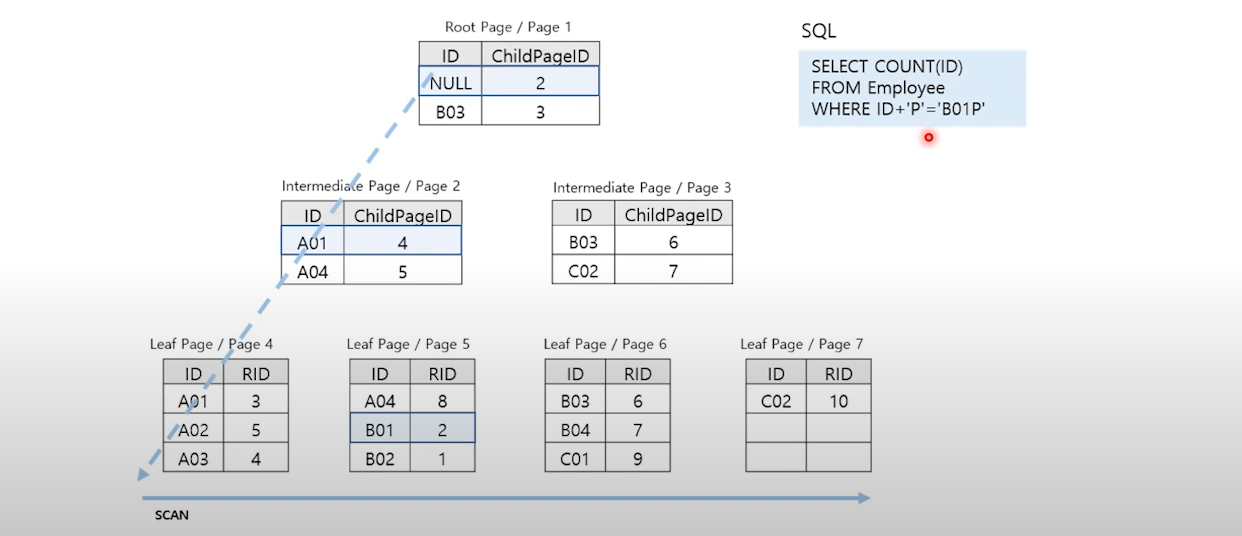
→ 비 클러스터드 인덱스 키를 사용하였으나, 가공되어 모든 leaf page를 탐색
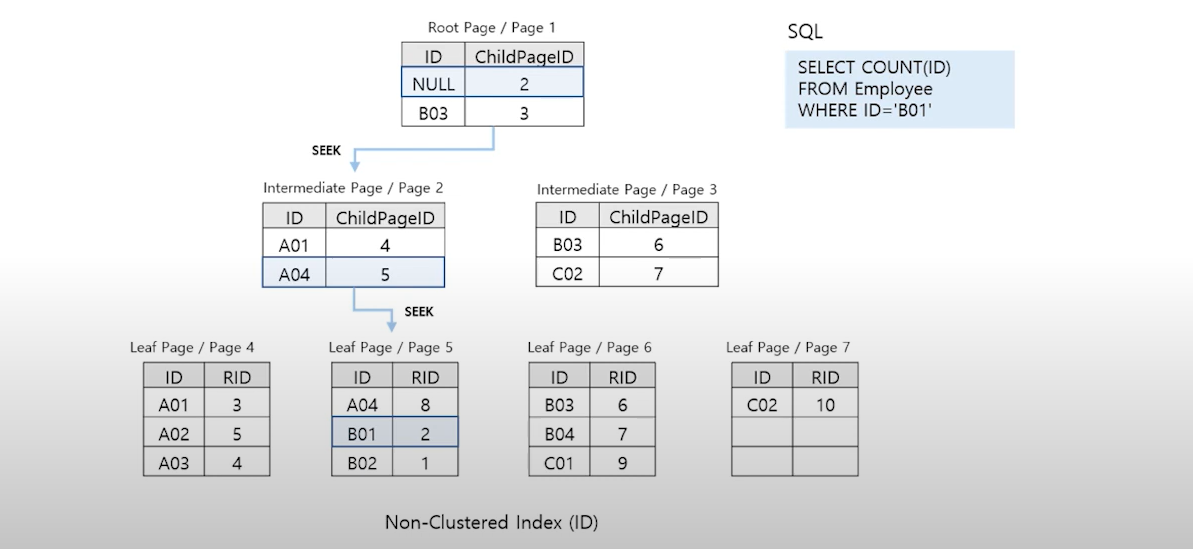
5. Non-Clustered Index Seek
-
인덱스의 Root 부터 Leaf 까지 필요한 페이지만 수직적으로 탐색
-
Non-Clustered Index에 포함된 열만 조회할 경우 발생
6. RID Lookup : Non-Clustered Index + Heap Table
-
Non-Clustered Index Seek을 통해 해당 데이터의 주소값(RID)을 조회한 후 해당 주소를 Heap 테이블에서 조회
-
SELECT e_name FROM EMPLOYEE WHERE id = 'C02' 처럼 인덱스의 Key값이 아닌 데이터 e_name을 조회할 때 발생.
-
Non-Clustered Index + Heap 일경우 RID Lookup 발생
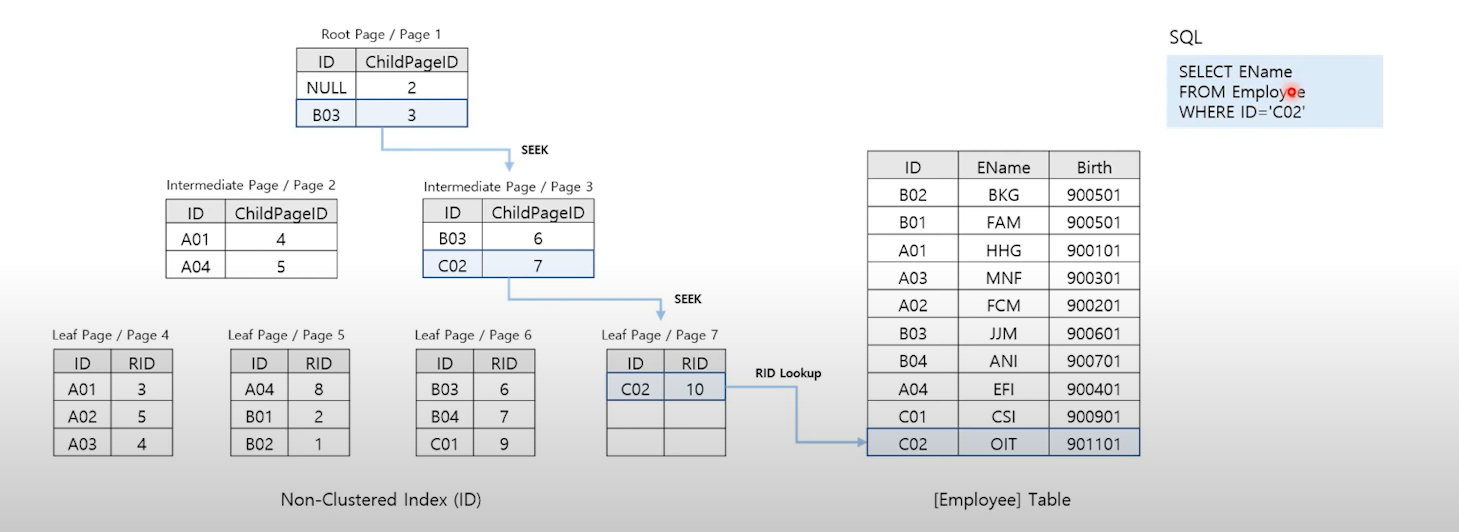
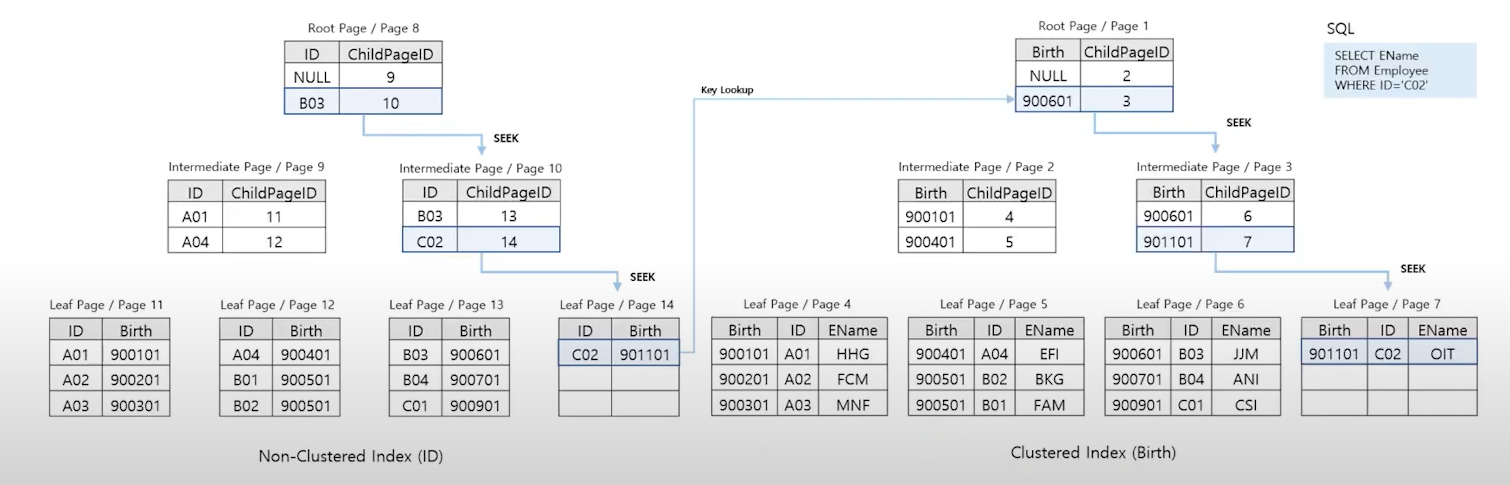
7. Key Lookup : Non-Clustered Index + Clustered Index
-
Non-Clustered Index Seek을 통해 Clustered-Index key값을 조회한 후 그 key값으로 Clustered-Index(데이터 테이블)을 조회한다.
-
RID-Lookup 처럼 Non-Clustered Index에 포함된 열 이외 데이터까지 조회하는 경우 발생
포괄 열이 있는 인덱스
정의
Non-Clustered Index에 키가 아닌 칼럼을 포함하는 인덱스.
특징
- 키가 아닌 칼럼을 포함하는 Non-Clustered Index
- INCLUDE 칼럼은 Leaf 페이지에만 저장
- 검색 조건으로 사용되지 않으면서 조회 시 필요한 칼럼을 포함하는 것이 적합.
- 키 열과는 다르게 Text, ntext, image 데이터 타입을 제외한 모든 열을 정의할 수 있음.
기대효과
- Page Split, 조각화 발생을 축소시킬 수 있다.
- 조회 과정에서 RID Lookup, Key Lookup의 비용을 절약
인덱스 디자인 전략
1. Where / Join 컬럼 분석
Where 조건에 걸리거나 Join에 사용되는 칼럼에 Index가 있는지, 또 그 인덱스의 선택도를 확인한다.
(인덱스 후보)
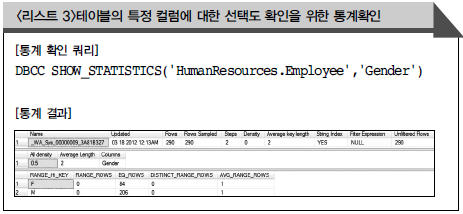
2. 칼럼의 선택도(Uniquencess)를 고려한다.
- 성별과 같은경우 남, 여 두 종류의 데이터로 이루어져 인덱스로 사용시 전혀 성능에 도움되지 않음 (이 경우 옵티마이져는 인덱스를 Seek 보다, Scan이 더 비용이 적다고 판단할 수 있다.)
→ 따라서 선택도를 고려하여 인덱스 후보를 산정한다. 특히 인덱스 키가 두개 이상인 경우 칼럼의 순서 또한 중요하므로 선택도가 높은 칼럼을 앞세운다.
- 선택도 확인 : DBCC SHOW_STATISTICS(’db.table’, ‘column’)
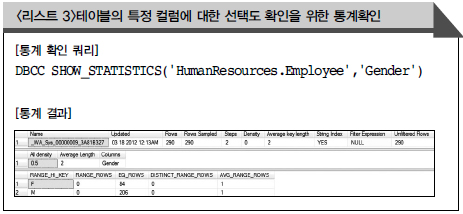
- 일반적으로 Density가 낮을 수록 선택도는 높다할 수 있으나, 반드시 그렇 지는 않다.
→ 데이터 종류는 많으나 한 가지 값에 집중되는경우 선택도가 높지 않을 수 있다.
3. 칼럼 데이터 타입을 고려한다.
- 인덱스 키가 INT(BIGINT, SMALLINT, TIN YINT) 타입인 경우 탐색속도가 매우 빠르다.
- String 타입의 경우 string match 연산이 필요해 상대적으로 비용이높다.
- 인덱스 키가 두개 이상인 경우 첫번 쨰 키 칼럼을 기준으로 정렬하고, 그 안에서 두 번째 칼럼을 정렬한다. 따라서 첫 인덱스 키가 리딩 에지(Leading edge)로 자주 요청된다.
4. 인덱스 타입을 고려한다.
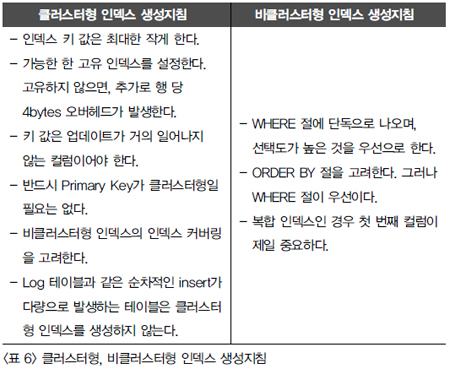
인덱스 사용 전략
-
LIKE 문
%로 시작하는 like문은 index를 타지 않음.
ex)
index Y: SELECT FROM name LIKE '홍%'
index N: SELECT FROM name LIKE '%동' -
NULL
IS NULL, IS NOT NULL 값은 인덱스를 타지 않음.
ex)
SELECT * FROM name IS NULL
-
부정 연산자
!=, NOT IN 등등 부정 연산자는 인덱스를 타지 않음. -
형 혹은 데이터 타입 변환
데이터 형 혹은 타입을 변경할 경우 인덱스를 타지 않음.
ex)
index Y: SELECT FROM name = '홍길동'
index N: SELECT FROM name + '님' = '홍길동님'
index Y: SELECT FROM age = 25 -- age 칼럼 데이터 타입은 int
index N: SELECT FROM age = '25' -
Where 절 왼쪽
WHERE A.name = B.name 일 경우 왼쪽, 즉 A테이블에 대한 인덱스만 사용하고 B 테이블에 대한 인덱스는 사용하지 않는다.
ref.
