투데이 링크 메인페이지 소개 및 요약
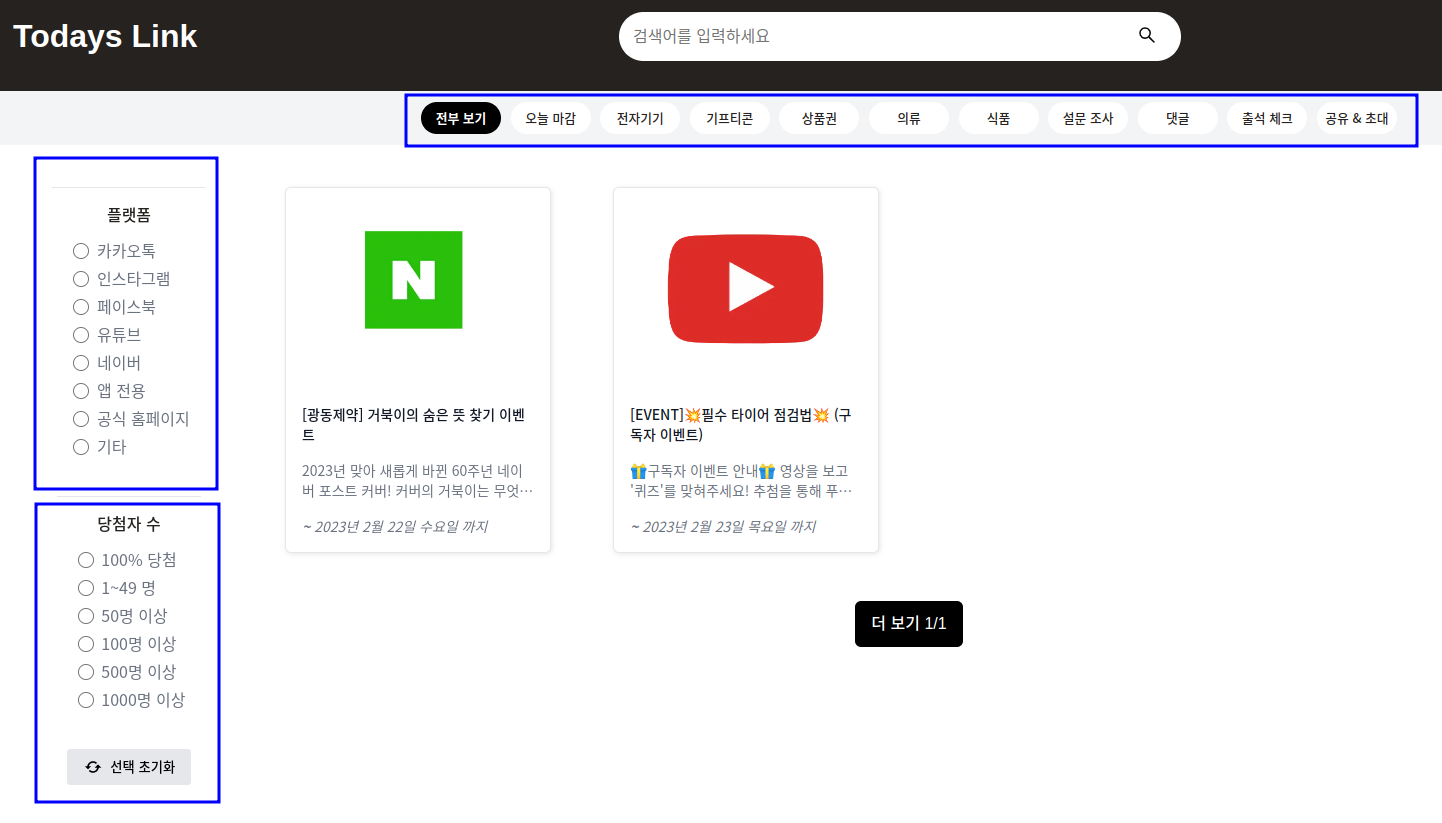
투데이 링크 메인 페이지는 위의 사진과 같이 총 3개의 조건(태그, 플랫폼, 당첨자 수)에 따라 데이터가 필터링되어 보여집니다.
또한 선택된 옵션의 상태를 관리하기 위해 Redux를 이용하고 있습니다.
(리덕스에서 관리하는 상태에 대한 코드)
그리고 메인페이지의 컴포넌트 구조는 대략 아래와 같습니다.
메인 페이지 사전 생성 (for SEO)
투데이 링크는 Next.js로 구축된 프로젝트였기 때문에 Next.js의 장점을 이용하는 것이 좋다고 생각했습니다.
Next.js의 장점 중 하나는 서버 사이드 함수를 통해 이미 데이터가 채워진 페이지를 사전 생성할 수 있다는 것입니다.
데이터가 채워진 페이지를 사전 생성한다면, SEO 향상에 도움이 되어 검색 엔진의 검색 결과에 제 사이트의 컨텐츠를 상위에 노출시킬 수 있습니다.
저는 이러한 점을 고려했고, 현재 투데이 링크의 메인 페이지를 서버 사이드 함수 중 하나인
getStaticProps를 이용해 페이지를 사전 생성하고 있습니다.
따라서, 메인 페이지에서 마우스 우 클릭 - 소스 보기를 클릭하면 아래와 같이 이미 데이터가 채워진 메인 페이지 코드를 볼 수 있습니다.

제가 서버 사이드 함수 중 getStaticProps를 선택한 이유는 투데이 링크에서 주로 다루고 있는
이벤트 정보에 대한 데이터는 자주 변경되지 않을 데이터라고 생각했기 때문입니다.
(보통 이벤트 짧게는 하루 길게는 몇 주일 동안 똑같은 정보을 유지합니다.)
따라서, 매 요청마다 최신의 데이터를 기반으로 페이지를 다시 생성하는 getServerSideProps 함수가 아닌 프로젝트 빌드 시점에 페이지를 생성하는 getStaticProps가 더 적합하다고 생각했습니다.
그리고, getStaticProps의 단점을 보완하기 위해 revailidate라는 속성을 3600으로 설정하여
페이지가 마지막으로 생성된 지 1시간이 지나면 다시 최신의 데이터를 받아와 페이지를 사전 생성하도록 했습니다.
페이지네이션에 대한 고민 (무한 스크롤? 더 보기 버튼? 번호 형태 페이지?)
아직, 투데이 링크에는 페이지네이션을 고민할 만큼의 데이터를 보유하고 있지는 않지만 나중을 위해서라도
현재 데이터를 보여주는 방식을 결정하는 것은 충분히 고민해 볼 만한 가치가 있다고 생각했습니다.
결론부터 말하자면, 저는 한 번에 모든 데이터를 받아오는 것보다는 페이지네이션을 통해 데이터를 나누어 받아 오는 것이 더 적합하다고 판단했습니다.
왜냐하면, 네트워크 요청 단 한 번으로 모든 데이터를 가져온다면 이후의 추가적인 네트워크 요청이 필요 없다는 장점이 있지만
그만큼 데이터의 양이 많아지게 되므로 요청 속도가 느려질 수도 있고, 사용자에게 필요하지 않은 데이터도 포함되어 있을 수 있습니다.
반면에, 데이터를 페이지화 시켜 나누어 보여준다면 네트워크 요청의 빈도는 많아질 순 있지만, 한 번에 받아오는 데이터의 양이 적어지므로 속도가 빠르고, 사용자가 보고 싶은 만큼의 데이터만 볼 수 있다는 장점을 얻을 수 있기 때문입니다.
따라서 저는 많은 데이터를 나누어 보여주는 방식을 선택했습니다.
그다음으로 "어떻게 페이지화 시킬 것인가?"에 대한 고민을 했습니다.
- 무한 스크롤
- 더 보기 버튼
그리고 저는 2번, 더 보기 버튼을 이용했습니다.
사실, 어떠한 방법을 이용해도 틀렸다고는 할 수 없었지만, 사용자 관점에서 바라보았을 때
현재 데이터가 얼만큼 보여지고 있는지(사용자 피드백)가 중요하다고 생각했기 때문에 2번 더 보기 버튼을 이용했습니다.
그래서 현재 메인 페이지 코드에서는 페이지 네이션을 위한 두 가지 상태를 관리하고 있습니다.
pageOffset: 다음 데이터를 받아오기 위한 기준 값totalLength: 전체 페이지 길이
결과적으로 아래의 더 보기 버튼의 사진처럼 현재 보고 있는 페이지 / 전체 페이지 정보를 확인할 수 있도록 구성했습니다.

맞닥뜨린 문제들
1. getStaticProps와 useEffect()
현재 투데이 링크의 메인 페이지는 서버 사이드 함수인 getStaticProps를 이용하여 데이터를 미리 패치해온 뒤,
클라이언트 측 컴포넌트에 props로 데이터를 전달하여 페이지를 사전 생성하고 있습니다.
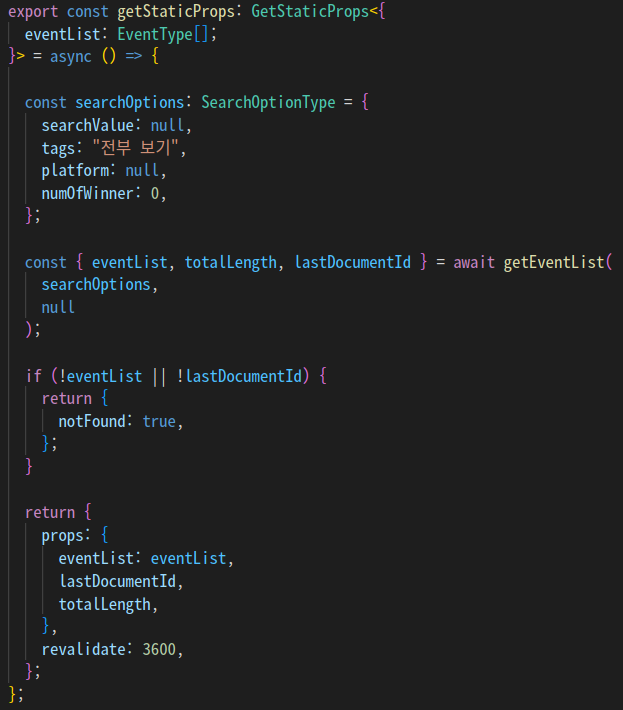
또한, 이후 검색 옵션이 바뀔 때마다 데이터를 새로 받아오기 위해 클라이언트 측(컴포넌트) 코드에서 useEffect 훅을 이용하고 의존성 배열로 검색 옵션을 넣어 주었습니다.
이때, 메인 페이지 첫 번째 렌더링 과정에서 문제가 발생했습니다.
첫 번째 렌더링 과정을 간략히 설명하자면,
getStaticProps로 초기 옵션 값에 해당하는 데이터를 패치해온 뒤,props로 컴포넌트에게 전달한다.- 클라이언트 측에서 이미 데이터가 채워진 페이지를 렌더링 한다.
- 컴포넌트가 렌더링 되고 난 뒤에
useEffect()를 실행한다.
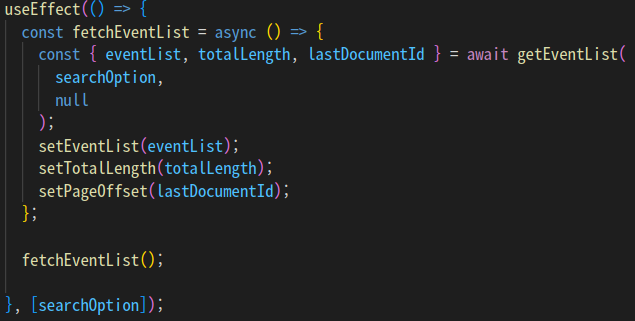
위에서 설명했듯이 3번의 useEffect() 또한 데이터를 패치해 오는 역할을 수행하고 있습니다.
이때, useEffect() 코드는 첫 페이지가 렌더링 된 직후에도 실행되므로 이때의 옵션 또한 초기 값으로 세팅된 옵션입니다.
즉, getStaticProps에 의해 이미 한 번의 데이터 패치를 수행하고 있고,
첫 번째 페이지가 렌더링 된 직후에도 useEffect()에 의해 또 한 번 똑같은 데이터가 패치되고 있었습니다.
즉 사용자가 메인 페이지에 처음으로 방문하는 시점에는 똑같은 데이터가 중복으로 보여지고 있었습니다.
저는 이 문제를 isFirstRendering이라는 변수를 선언하여 해결하였습니다.
그리고 이 변수의 위치는 컴포넌트 렌더링 주기와는 관련이 없는 함수 컴포넌트 바깥쪽에 선언하였습니다.
let isFirstRendering = true;
//컴포넌트 코드
const HomePage = (props: PropsType) => { ... return (...) }그리고 useEffect()에서는 이 변수를 기준으로 데이터를 요청하도록 변경했습니다.
useEffect(()=>{
if (isFirstRendering) {
isFirstRendering = false;
} else {
//데이터 요청
}
},[searchOption]);첫 번째 렌더링 시점이라면 useEffect는 데이터를 패치해오지 않고,
이후의 렌더링에서는 데이터를 패치해 오도록 하여 이 문제를 해결하였습니다.
2. Firestore Database 복합 쿼리를 구성하며 맞닥뜨린 문제
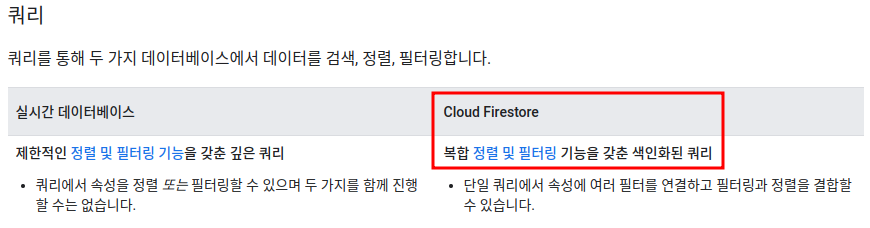
firebase는 클라이언트에서 쉽게 접근하여 사용할 수 있는 두 가지 클라우드 기반 데이터베이스 솔루션을 제공하고 있습니다.
RealTime DatabaseFirestore Database
투데이 링크에서는 두 가지 중에서 Firestore Database 서비스를 이용해 데이터를 관리하고 있습니다.
Firestore를 선택한 결정적인 이유는 다음의 사진처럼 RealTime Database와 비교해 복합적인 쿼리를 사용할 수 있었기 때문입니다.
그리고 투데이 링크는 다음과 같이 3가지 조건 (태그, 플랫폼, 당첨자 수)에 의해 데이터를 필터링하고 있습니다.
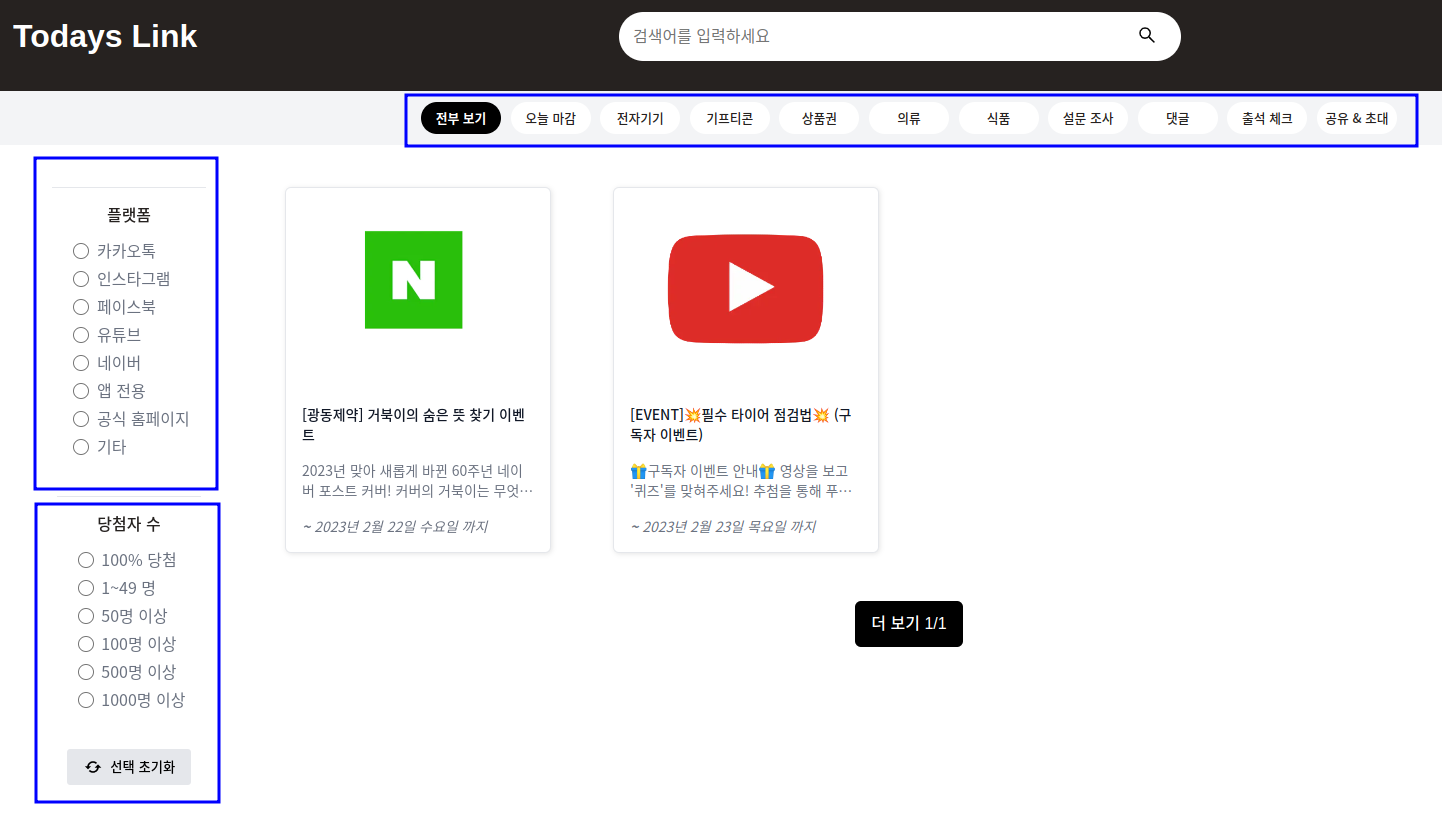
이 세 가지 조건 각각이 쿼리문에서 하나의 필드에 해당했고, 각 필드의 조건을 조합하여 하나의 쿼리를 구성해야 했습니다.
하지만, 복합적인 쿼리를 구성하는 데 있어서 Firestore는 지켜야 하는 제약들이 다음과 같이 존재했고,

이에 따라 처음에 계획했던 쿼리를 구성할 수가 없었습니다.
예를 들면, 프로젝트 초기의 플랫폼 필터와 태그 필터는 다음과 같은 형태로 데이터베이스에 저장되었습니다.
flatforms : ['KAKAO','INSTAGRAM','ONLY_APP']
tags:['전자기기','기프티콘','댓글']
즉, 배열 형태로 저장되어 있어 배열 형태를 다룰 수 있는 in,not-in,array-contains-any 절 등을 사용했어야 했습니다.
하지만, 제한사항에 나와있듯 하나의 쿼리 안에서 하나의 필드에서만 해당 절을 이용할 수 있었습니다.
따라서, 데이터를 저장하는 방법을 변경해야 했고, flatform 필드를 배열 형태가 아닌 하나의 플랫폼만(문자열) 저장할 수 있도록 변경했습니다.
또한, 쿼리 관련 두 번째 문제는 당첨자 수 필터와 오늘 마감 태그를 구성하는 곳에서 발생했습니다.
당첨자 수 태그는 특성상 비교 연산자를 사용해야 했고,
오늘 마감 태그 또한 데이터베이스에 타임테이블 형태로 저장되어 이벤트의 마감 날짜 >= 현재 시점 연산을 통해 통해 필터링하고 자 했습니다.
하지만 비교 연산자 또한 다음과 같이 지켜야 할 제약사항이 존재 했고,

동시에 두 필드에서 비교 연산자를 사용할 수 없었습니다.
따라서 저는 이벤트의 endDate 필드 형식을 기존 타임테이블 형식에서 다음과 같이 변경하여
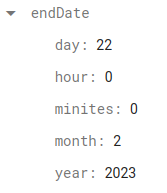
== 연산자를 통해 년도, 월, 일을 비교하여 오늘 마감 태그를 필터링 하여 문제를 해결했습니다.
