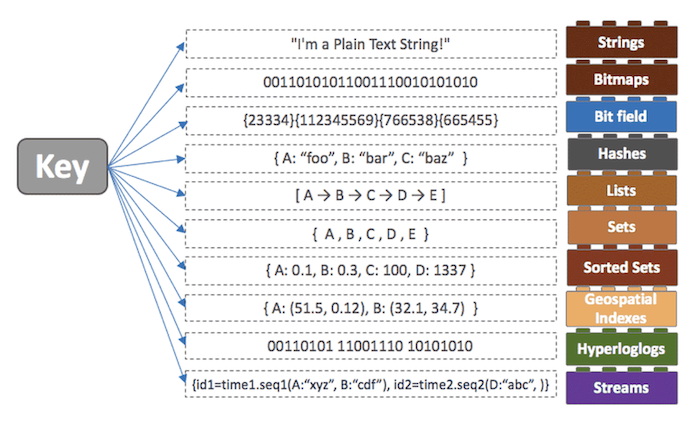
Redis의 다양한 자료구조
레디스는 다양한 collection(자료구조)를 제공하여 개발의 편의성을 높여주고 개발 난이도를 낮춰줍니다.
Redis 자료구조의 특징
- Redis의 자료구조는
atomic하기 때문에 경쟁 상태(timing 문제 등)를 피할 수 있습니다. - 다양한 자료구조를 제공하기 때문에 여러 개발시간을 단축하고 문제를 줄여줄 수 있습니다.
- Redis의 자료구조를 사용하게 되면 Redis 자료구조의 한계에 종속적이게 될 수 있습니다.
Redis사용을 고려해볼만한 사용 처
- 여러대의 서버에서 같은 데이터를 공유하는 remote data store
- 인증 토큰 저장, ranking 보드
Strings

- Key-value의 형태로 문자를 저장할 수 있는 자료구조
- 최대 512MB까지 저장 가능
- 거의 대부분의 커맨드가 O(1)의 시간 복잡도를 가지나
SUBSTR,GETRANGE,SETRAGNE등의 커맨드는 O(n)이다.
Lists

- 일반적인 링크드 리스트를 의미한다.
- 주로 앞 뒤로의 데이터 삽입 삭제에는 유리하지만 중간 데이터 삽입과 같은 동작에는 어울리지 않는다
- 리스트는 최대2^32 - 1개의 원소들을 저장할 수 있다.
Sets

- 중복되는 데이터를 허용하지 않는 자료구조
- 주로 빠르게 데이터를 찾을 때 사용한다.
SMEMBER커맨드는 O(n)임으로 사용할 때 주의가 필요하고 이를 대신해SSCAN커맨드를 사용할 수 있다.
Hashes

- key 밑에 여러 sub key들을 가질 수 있는 형태의 자료구조
- 객체를 저장하기에 좋고 개별 sub key안의 아이템들을 조작할 수 있다.
HKEY,HVALS,HGETALL등의 커맨드는 O(n)임으로 사용할때 주의가 필요하다.
Sorted Sets

- 중복되는 데이터를 허용하지 않는 자료구조 <- Sete의 특징
- 모든 score값으로 연결되어 있다. <- Hash의 특징
- score값을 통해 순서를 보장할 수 있다.
- 대부분의 명령어가 O(log(n))이다.
Streams
- Kafka에 영향을 받아 만들어진 자료구조
- append-only이며 로그를 저장하는데 적절하다.
Hyperloglogs
- 집합의 카디널리티(아이템 개수)를 계산하는 자료구조
- 데이터의 정보 보다 데이터가 저장되었는지 안되었는지가 중요한 자료구조로 대용량 데이터를 카운팅 할때 사용한다.(오차 약0.81%)
- 용량은 12KB 고정으로 매우 작다
그 이외에도 bitmaps, Geospatial, bitfields등의 자료구조를 제공한다.
Key
- 키를 설계하는 것 또한 Redis를 사용하는데에 있어 매우 중요한 영역이다.
- Key는 문자열 타입으로 가독성이 있으면서도 스키마를 유지하도록 설계해야 한다.
- 키의 길이는 적절히 설정해야 하며 너무 길 경우 그 값은 hash member로 저장하는 것이 더 좋다
- 캐시로 사용할 경우 timeout을 설정하는 것을 권장한다.
자료구조 사용시 주의사항
- 하나의 collection에 너무 많은 item들을 넣으면 성능에 문제가 생길 수 있다.(10000개 이하로 유지하는 것이 좋다.)
expire은 key들에게 시간 제한을 두어 메모리를 효율 적으로 관리하기 위해 사용하는 커맨드로 한 collection내의 개별 item들에게는 걸 수 없고 collection에 대해서만 걸 수 있다.
참고자료
https://meetup.nhncloud.com/posts/224
https://redis.io/docs/data-types/
https://www.youtube.com/watch?v=mPB2CZiAkKM

데이터를 탐구하는 개발자