수집한 데이터
수집한 데이터: investing.com에서 BTC 종목에 대한 뉴스 제목들
수집한 사이트: investing.com BTC 뉴스
참고로 url에서
https://www.investing.com/crypto/bitcoin/news/2
맨 끝의 '2'에 잠깐 주목해주시고 이제 잊어도 됩니다.
우선 뉴스 제목을 한 페이지만 수집해보고, 여러 페이지의 뉴스 제목들도 수집해보겠습니다.
사용 라이브러리:
import requests
from bs4 import BeautifulSoup
수집 과정
뉴스 제목 한 페이지만 수집하기
1. 목표 데이터 정하기
저는 이번에 목표 데이터로, investing.com 홈페이지에서 BTC 종목에 대한 뉴스들의 제목을 수집하려고 했습니다.
해당 사이트에서 news 카테고리를 따로 클릭하면
investing.com BTC 뉴스 사이트가 실행됩니다.
해당 페이지에서 뉴스 제목들만 가져오는 것이 목표입니다.
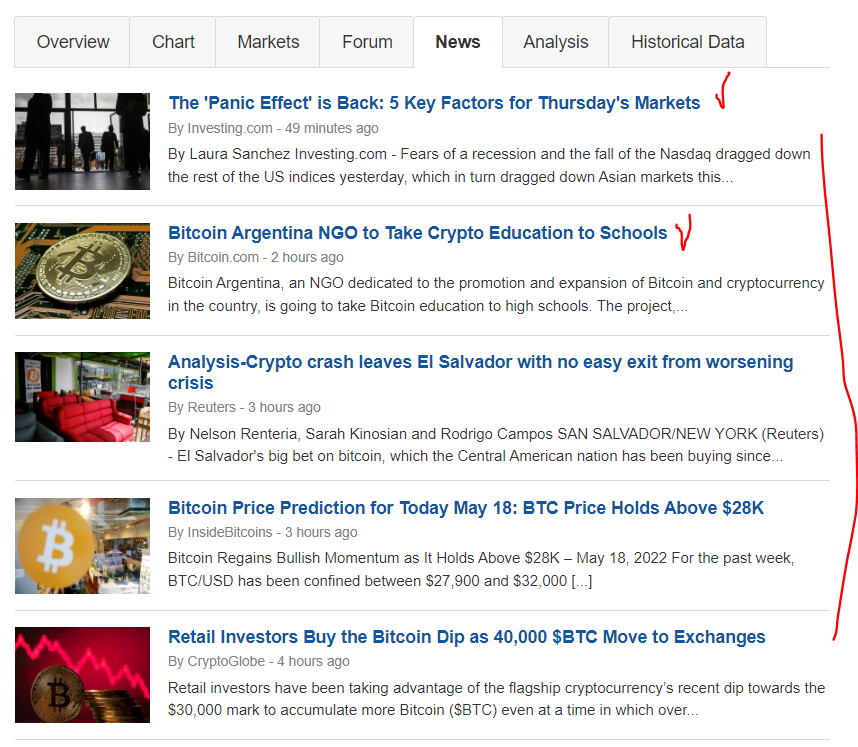
2. 크롤링 설정 세팅하기
아래와 같이 url 문자열과 headers를 작성해주시고, beautifulsoup과 requests를 import해서 크롤링 기초 세팅을 합니다.
headers는 복사붙여넣기 하시면 됩니다!
import requests
from bs4 import BeautifulSoup
# html 정보 가져오기 및 headers 세팅
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
# 뉴스 제목 url
url = "https://www.investing.com/crypto/bitcoin/news"
# http 요청 받기
response = requests.get(url,headers=headers)
# url에 대한 정보를 받을 수 있는 soup 생성
soup = BeautifulSoup(response.text,'lxml')3. 뉴스 제목에 대한 html 정보 파악하기
- 뉴스사이트에 접속합니다.
- F12 눌러서 빨간 동그라미 표시 부분 클릭하고 뉴스 제목을 클릭하면 뉴스 제목에 대한 html 정보를 알 수 있습니다.
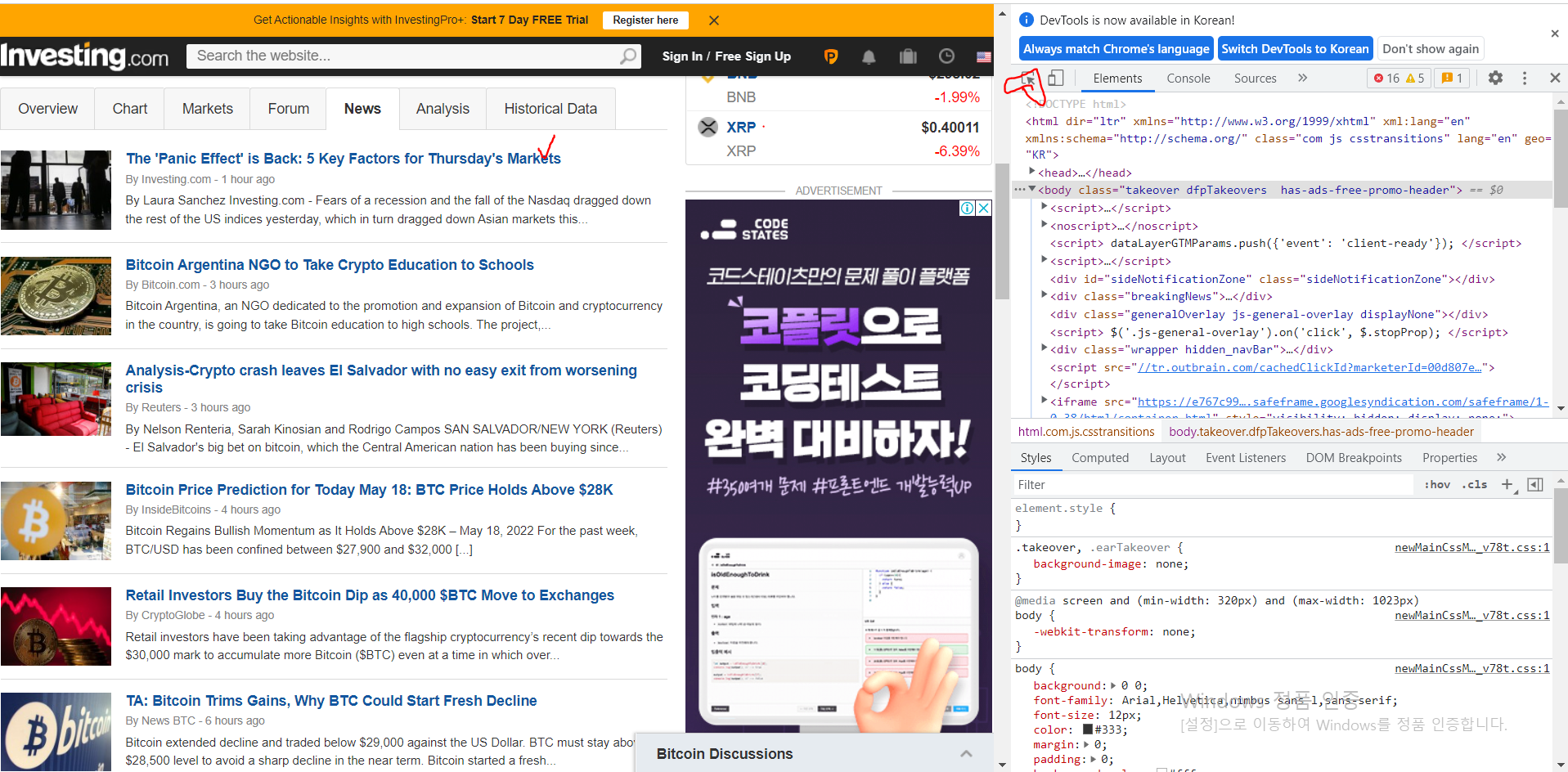
- class='title' 임을 알 수 있습니다.

4. 첫 페이지의 뉴스 제목 수집하기
3번에서 파악한 뉴스 제목의 html 정보를 기반으로 첫 페이지의 뉴스 제목을 수집해보겠습니다.
파이썬의 리스트 컴프리헨션 기법을 사용해서 다음 코드를 추가하면 끝입니다.
news_title 리스트에는 해당 페이지의 뉴스 제목들의 문자열이 담겨져 있게 됩니다.
주목할 점은 soup.select('title') 이 아니라 soup.select('.title') 입니다. '.'에 주의하세요.
news_title=[title.get('title') for title in soup.select('.title')]5. 임시 출력 결과
아래 사진처럼, 뭔가 none이 껴있네요.
아마도 soup.select('.title')을 하면서,
이름이 중복되는 다른 html 요소랑 겹쳐서 이와 같이 나오는 것 같습니다.
none을 없애는 코드도 추가하죠.

none 을 처리하는 코드입니다.
news_title=[title.get('title') for title in soup.select('.title') if title.get('title') != None]6. 최종 코드 및 최종 출력 결과
최종 코드:
import requests
from bs4 import BeautifulSoup
# html 정보 가져오기 및 headers 세팅
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
# 뉴스 제목 url
url = "https://www.investing.com/crypto/bitcoin/news"
# http 요청 받기
response = requests.get(url,headers=headers)
# url에 대한 정보를 받을 수 있는 soup 생성
soup = BeautifulSoup(response.text,'lxml')
news_title=[title.get('title') for title in soup.select('.title') if title.get('title') != None]
print(news_title)출력 결과:
none이 좀 많았던 것 같습니다.

뉴스 제목 여러 페이지만 수집하기
1. 목표 데이터 정하기
이번에는 2022년 3월 15일부터 2022년 6월 15일까지의 뉴스 제목들을 수집해보겠습니다.
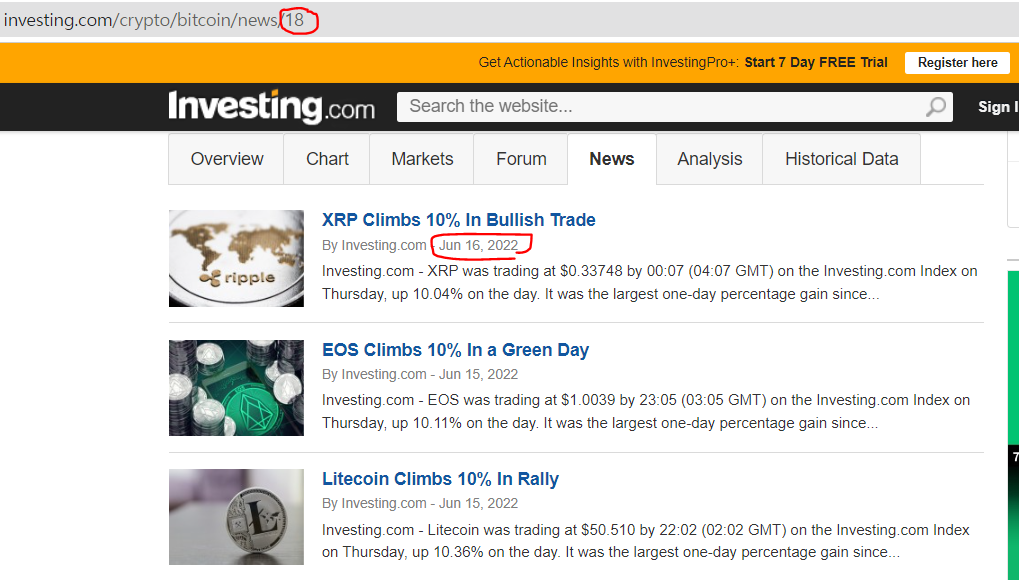
2022년 6월 26일 기준으로, 18페이지에서부터 6월 15일 뉴스 제목이 등장했습니다. 3월 14일 날짜가 발견되면 break하는 형식으로 수집해보겠습니다.
2. 크롤링 설정 및 기초 코드
# html 정보 가져오기 및 headers 세팅
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
def get_url_info(iter):
if iter==1:
url = "https://www.investing.com/crypto/bitcoin/news"
else:
url = f"https://www.investing.com/crypto/bitcoin/news/{iter}"
response = requests.get(url,headers=headers)
return BeautifulSoup(response.text,'lxml')
import requests
from bs4 import BeautifulSoup
import re
# 종료시키는 finish bool형 변수
finish=False
for iter in range(18,99999):
soup = get_url_info(iter)
news_title_list, news_date_list=[], []
for i,title in enumerate(soup.select(".title")):
title_string = title.get('title')
if title_string != None:
print(i,title_string,sep=' ')
print('\n')위 코드의 결과:
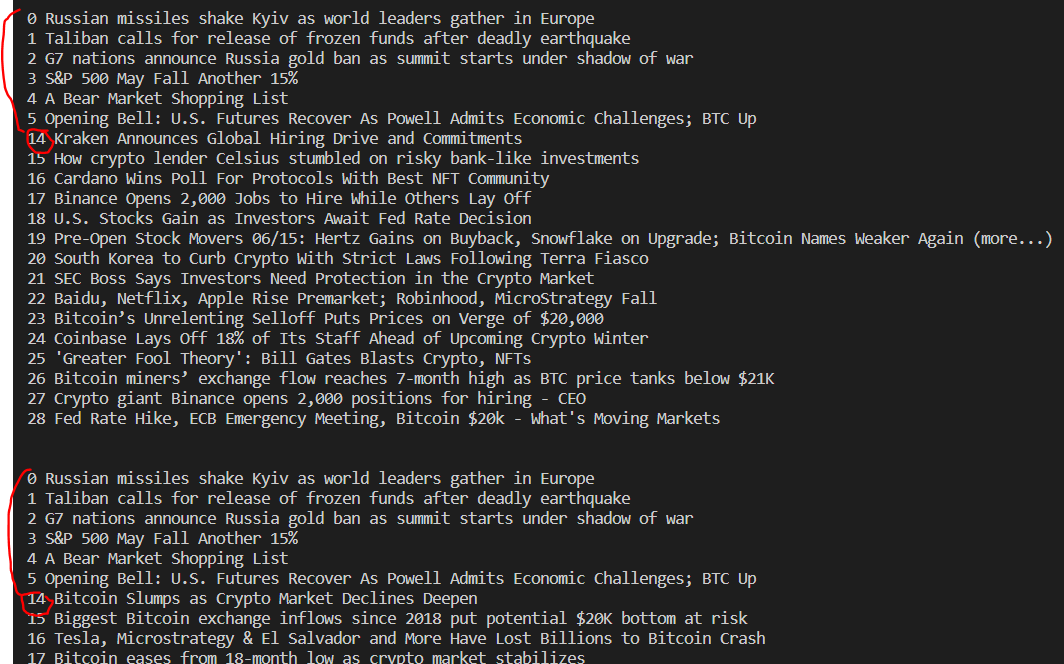
이 사이트 뉴스 기사 크롤링할 때마다 이상한 점이, 0~13까지의 인덱스의 뉴스 기사들은 none이거나 다른 기사랑 중복됐습니다. 중복을 피하기 위해 인덱스 번호가 14 이상일 때만 수집해야겠습니다.
따라서 크롤링 조건이 두 가지입니다.
1. enumerate를 통한 반복문에서 인덱스 번호가 14이상일 때 저장한다.
2. none이 아닐 때만 저장한다.
최종적으로 완성할 함수는 다음의 매개변수를 갖습니다.
1. 수집할 마지막 날짜를 포함하는 페이지의 번호를 매개변수로 갖는다.
2. 포함시킬 날짜의 제일 과거 날짜의 전날을 'Mar 14, 2022'형식으로 입력합니다.
3. 크롤링할 첫 페이지에 원하지 않는 날짜가 포함하지 않기 위해, 포함시킬 날짜의 마지막 날짜의 바로 다음 날을 'Jun 16, 2022'형식으로 입력합니다.
완성 코드입니다:
# html 정보 가져오기 및 headers 세팅
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36',
'accept':'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9'}
def get_url_info(iter):
if iter==1:
url = "https://www.investing.com/crypto/bitcoin/news"
else:
url = f"https://www.investing.com/crypto/bitcoin/news/{iter}"
response = requests.get(url,headers=headers)
return BeautifulSoup(response.text,'lxml')
import requests
from bs4 import BeautifulSoup
def get_news_data_with_date(page_number:int,first_date:str,exculde_date:str):
date_error = '\nERROR: Date is not in proper form.\n'
month = ['Jan','Feb','Mar','Apr','May','Jun','Jul','Aug','Sep','Oct','Nov','Dec']
if first_date[:3] not in month or exculde_date[:3] not in month:
print(date_error)
return {}
elif len(first_date) != 12 or first_date[3] != ' ' or first_date[6:8] != ', ' or len(exculde_date) != 12 or exculde_date[3] != ' ' or exculde_date[6:8] != ', ':
print(date_error)
return {}
finish=False
news_date_title_dictionary = {}
for page_num in range(page_number,9999999999):
soup = get_url_info(page_num)
news_title_list, news_date_list=[], []
for i,title in enumerate(soup.select(".title")):
title_string = title.get('title')
if title_string != None:
news_title_list.append(title_string)
for date in soup.select(".date"):
date_string = str(date.get_text())
if exculde_date != date_string[3:]:
if (first_date) == date_string[3:]:
finish = True
else:
news_date_list.append(date_string)
for date, title in zip(news_date_list, news_title_list):
if date in news_date_title_dictionary:
news_date_title_dictionary[date].append(title)
else:
news_date_title_dictionary[date]=[title]
if finish:
break
return news_date_title_dictionary
news_date_title_dictionary = get_news_data_with_date(18,'Mar 14, 2022','Jun 16, 2022')
f = open('nlp_preprocessing.txt','w',-1, 'utf-8')
for date,title in news_date_title_dictionary.items():
f.write(f"기사 작성 날짜:{date}\n기사 제목들:{title}\n\n")
f.close최종적으로 완성한 결과물을 txt형식으로 저장합니다.
결과물을 깃허브에 올렸습니다.
https://github.com/tree-jhk/get_bitcoinprice_news_data_with_sentiment_analysis/blob/main/bitcoin_news_2022_Mar_15_2022_Jun_15.txt
다음 포스트
2 - 작성 날짜 받아오기
3 - 여러 작성 날짜 - 뉴스 제목 딕셔너리로 이어주기
4 - 뉴스 제목 전처리해주기(소문자 만들기, 특수문자 제거, 무의미한 한 글자 제거) 정규식을 통해
5 - 비트코인 날짜별 종가 정보 받아오고, 여러 작성 날짜 - 뉴스 제목 - 비트코인 날짜별 종가 정보 로 최종 데이터 완성하기
