ICML 2025 oral 입니다. 지립니다. 리뷰 시작하기 전에 잠시 감상하고 가시겠습니다.
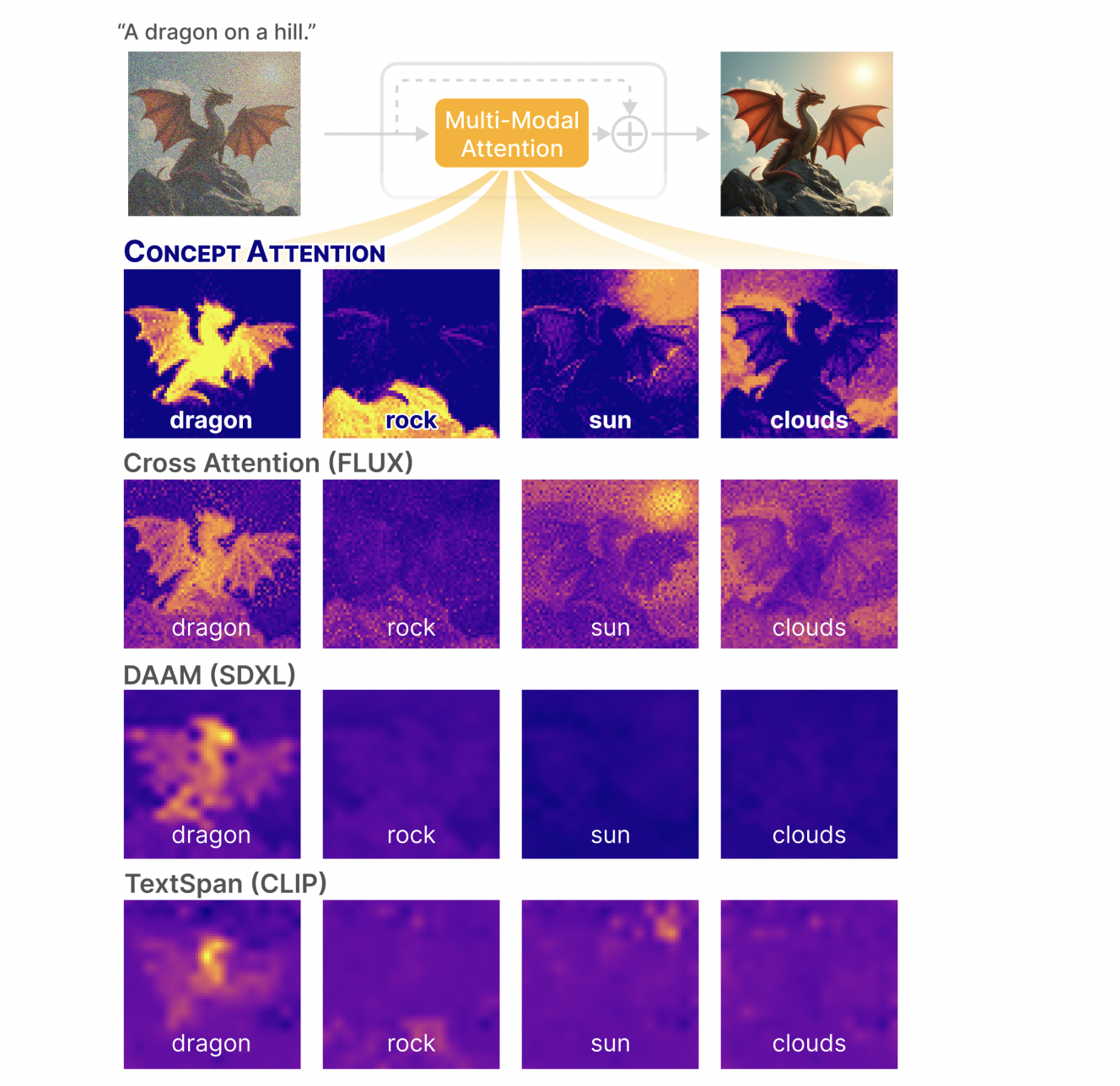
용 Attention map 깔끔한거 보이십니까? 그냥 예술입니다. 밑에 cross attention 도 resolution 에서는 그나마 선방하지만, contrast 가 비교가 안됩니다.
이야... 어케했노?
알아봅시다.
Methods
Concept Embedding
먼저, "고양이", "하늘" 같은 r 개의 토큰을 지정하고, 그 토큰을 T5 encoder 에 입력하여 concept embedding 을 생성합니다. 그 후, 각 multi-model attention (MMATTN) 레이어마다 text prompt 에 곱해졌던 projection matrix 를 재활용하여 concept embedding 을 로 projection 합니다. (이 때, text prompt 를 처리할 때도 T5 encoder 을 활용했기 때문에 dimension 의 문제는 없습니다!)
One-directional Attention Operation
위에서 생성한 concept embedding 을 image 에 영향을 주지 않으면서 update 를 하기 위해, concept 와 image 의 key 를 아래와 같이 concatenate 합니다.
- : number of concept tokens
- : image (즉, 는 image 의 key projection)
- : 사용자가 지정한 토큰의 초기 임베딩
마찬가지로 value 도 concatenate 하고 나면 attention operation 을 수행할 수 있습니다:
이 때 한가지 디테일이, 그냥 cross attention 의 식이 인데, 여기서는 key 와 value 에 image 뿐 만 아니라 concept token 을 다시 넣어줌으로써 segmentation 과 같은 downstream task 에서 성능을 끌어올렸다고 합니다. 그 근거로는 concept 의 embedding 의 중복 방지라고 하네요.
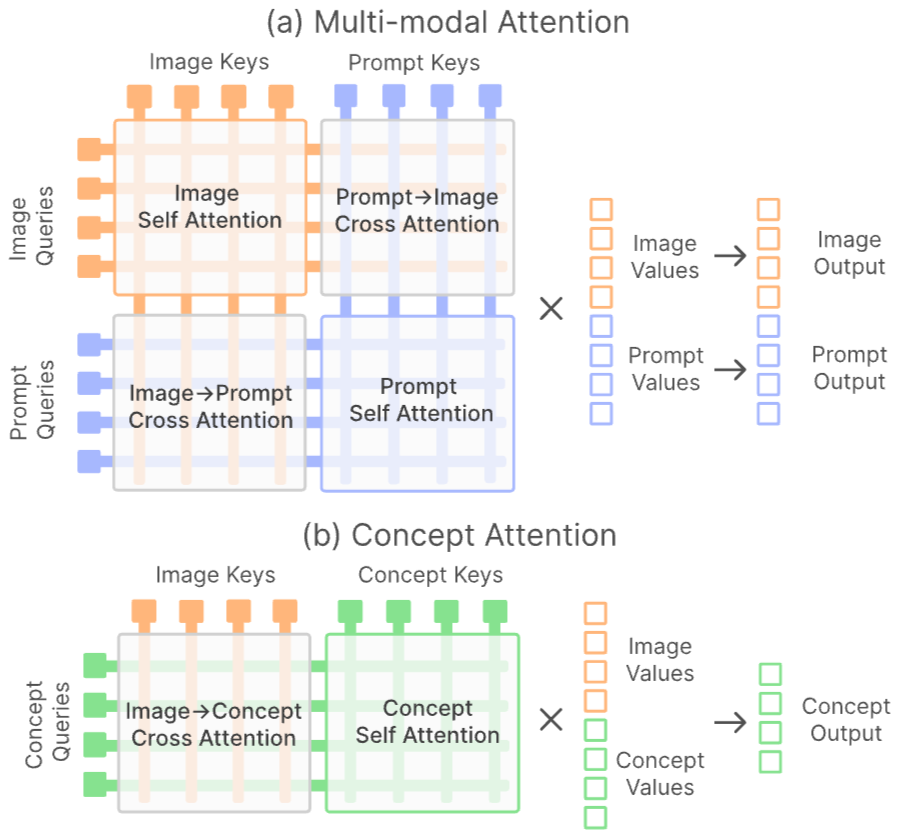 Figure 5. (a) MMATTN 에서 prompt 와 image 사이의 attention. (b) concept token 이 image token 에서 정보를 받아오는 방법
Figure 5. (a) MMATTN 에서 prompt 와 image 사이의 attention. (b) concept token 이 image token 에서 정보를 받아오는 방법
A concept residual stream
위에서 계산한 는 아래의 update 공식을 따라 layer (L) 마다 residual 로 더해집니다 (시작은 ).
이 때, 와 MLP 는 그 레이어에서 text prompt 에 활용되는 component 를 재활용합니다.
Saliency Maps in the Attention Output Space
이 논문의 핵심입니다. Concept embeddings 와 image patch embedding 의 dot product 로 saliency map 을 만들 수 있습니다.

XXX: 뭐? 그딴게 oral?
네 그게 답니다. 중요하니 한번 더 강조하겠습니다.
Concept embeddings 와 image patch embedding 의 dot product 로 saliency map 을 만들 수 있으며, 이는 아래 식으로 표현됩니다:
이 때, Softmax 는 saliency 값이 너무 튀지 않도록 0~1 로 보정해주는 역할입니다. 이 dot product 를 통해 우리는 특정 layer 의 saliency map 을 볼 수도 있고, 아니면 전체 layer 의 평균을 내도 됩니다.
기존 cross attention 과의 차이점을 한가지 짚고 넘어가자면, cross attention 은 결국 text prompt 를 활용해야 하기 때문에 prompt 이외의 단어에 대한 saliency map 을 만들 수 없습니다. 또한, 추후 결과에 나오겠지만, concept attention 이 성능이 더 좋습니다 (...)
Experiments
먼저, 대부분의 실험은 Flux DiT 를 활용했으며, 보조적으로 Stable Diffusion 3.5 Turbo 를 활용합니다. Concept Attention 이 (1) saliency map 을 잘 만들고, (2) DiT representation 을 downstream task 에 잘 활용하는지 보는 것이 목적이기 때문에, Zero-shot segmentation 데이터셋에서 성능을 평가합니다.
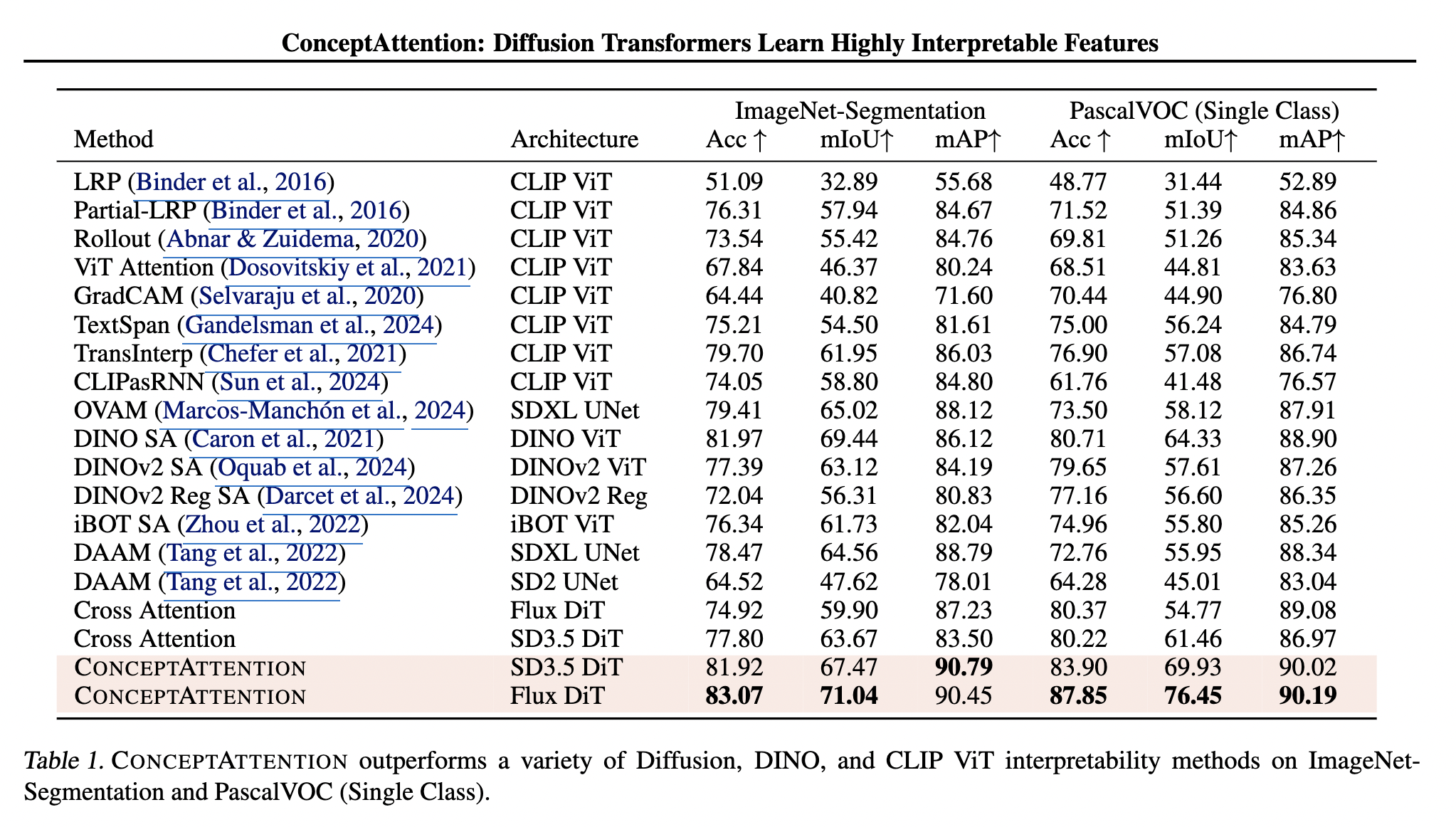
먼저 메인 실험결과입니다. ImageNet-Segmentation 과 PascalVOC 에서 제일 높은 accuracy 를 달성합니다. Cross Attention 보다 ImageNet 에서 5.27% 높네요. 특이한점은, cross attention 은 SD 3.5 DiT 보다 Flux DiT 가 accuracy 가 더 낮습니다 (mAP 는 더 높네요).
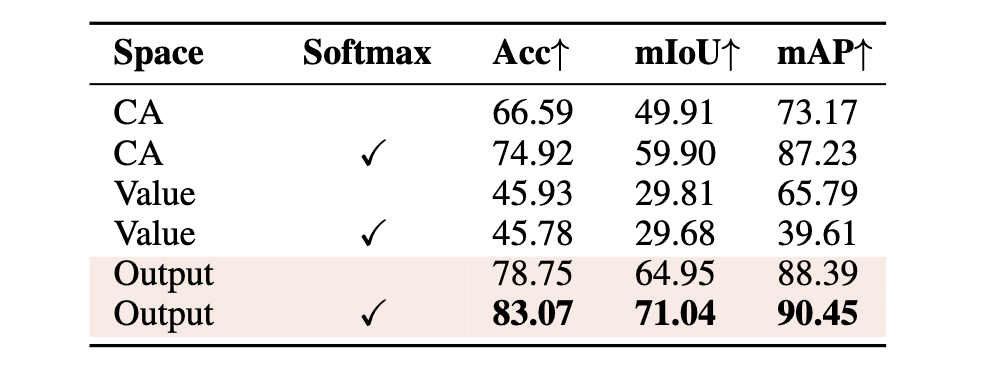
다음으로 볼 것은 cross attention 과의 비교입니다. 저자들은 CA 보다 output space 에서 downstream task 의 성능이 더 오른다고 합니다. Softmax 가 조금 더 성능을 올려주는건 덤이고요.
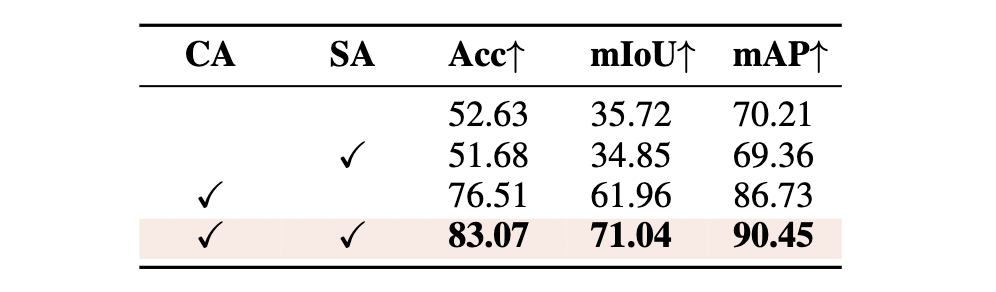 Table 4. Concept Attention performs best when we utilize
both cross and self attention.
Table 4. Concept Attention performs best when we utilize
both cross and self attention.
.. 이런식으로 concatenate 하는게 더 성능 좋다는 결과입니다. 단순히 cross attention 뿐만이 아니라 self attention 을 했을 때 무려 6.56% (!!) 나 올라간 것을 볼 수 있습니다.
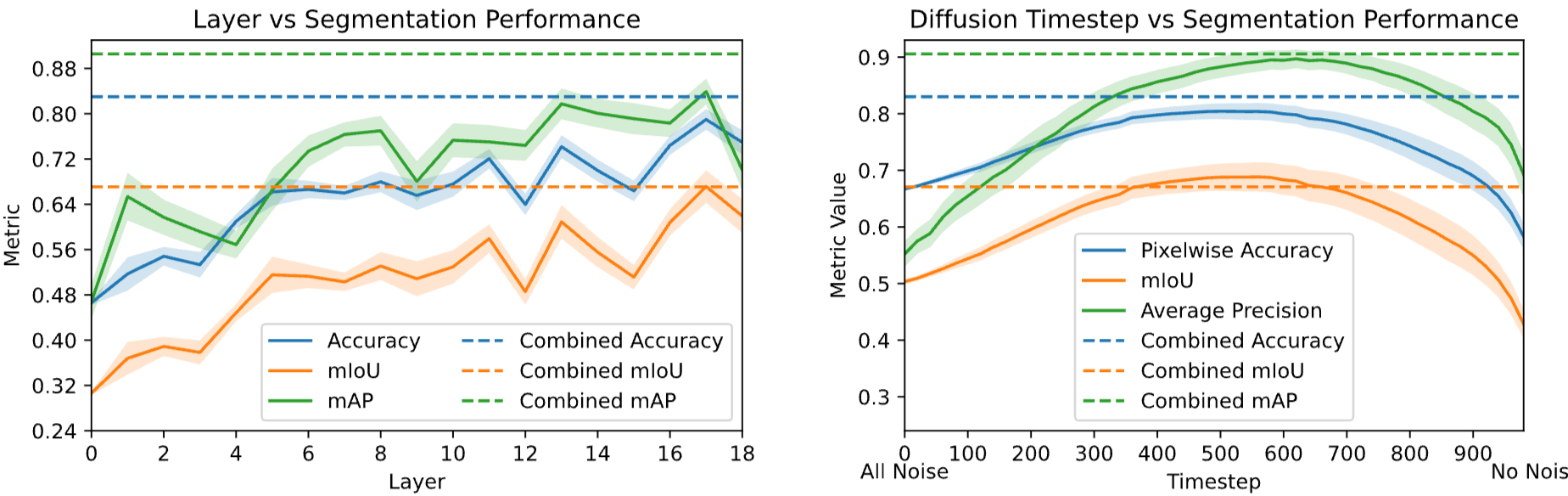
마지막으로, layer / diffusion timestep 별로 segmentation performance 를 plot 한 것입니다. 단일 layer 을 사용했을 떄는 뒤쪽의 layer 이 성능이 좋았습니다. 이 부분은 뒤쪽이 semantic 정보를 더 많이 가지고 있을테니 충분히 예상 가능합니다. 모든 layer 을 전부 combine 했을 때 가장 높은 성능이 나왔으며, 이는 ensemble 과 비슷한 개념입니다.
Timestep 은 놀랍게도 no noise 보다 500~700 구간에서 가장 높은 성능을 보였습니다. 모델이 어느정도 noise 가 있을 때 attention map 을 더 잘만들었다고 합니다.
마치며
이번 시간에는 ConceptAttention 을 알아보았습니다. 추가 training 없이 concept token 을 위한 "길" 을 만든 것 만으로도 굉장히 수준 높은 saliency map 을 만들어 낸 점이 굉장히 흥미롭습니다. 사실 preliminary 에서 rectified flow model 어쩌구 저쩌구 해서 잔뜩 쫄았는데, 그에 비해 아이디어는 굉장히 이해하기 직관적인 논문입니다.
