equals를 재정의한 클래스 모두에서 hashcode도 재정의해야 한다.
그렇지 않으면 hashCode 일반 규약을 어기게 되어 해당 클래스의 인스턴스를 HashMap이나 HashSet 같은 컬렉션의 원소로 사용할 때 문제를 일으킬 것이다.
🔽 hashcode 재정의의 필요성
다음은 Object 명세의 일부이다.
equals비교에서 사용되는 정보가 "변경되지 않았다면", 어플리케이션이 실행되는 동안 그 객체의hashCode메서드는 몇 번을 호출해도 "일관된 값을 반환"해야함.equals(Object)가 두 객체를 같다고 판단했다면, 두 객체의hashCode는 같은 값을 반환해야한다.equals(Object)가 두 객체를 다르다고 판단했더라도, 두 객체의hashCode가 서로 다른 값을 반환할 필요는 없다. 단, 다른 객체에 대해서는 다른 값을 반환해야 해시테이블의 성능이 좋아진다.
hashCode를 재정의를 잘못했을 때 크게 문제가 되는 조항은 2번째 문항으로, "논리적으로 같은 객체는 같은 해시코드를 반환해야 한다."
예시로 PhoneNumber 클래스의 인스턴스를 HashMap의 원소로 사용한다고 가정해보자. 이 코드는 m.put 실행후 m.get을 실행한다.
Map<Phone, String> m = new HashMap<>();
m.put(new PhoneNumber(707, 867, 5309), "제니")
m.get(new PhoneNumber(707, 867, 5309))위 코드에서 m.get은 실제로 null을 반환한다.
이유는 아래와 같다.
위 코드는 2개의 PhoneNumber 인스턴스가 사용되었다.
- 하나는 HashMap에 "제니"를 넣을 때
- 다른 하나는 이를 꺼낼 때
PhoneNumber 클래스는 hashCode를 재정의하지 않았기 때문에 논리적 동치인 두 객체가 서로 다른 해시코드를 반환한다.
따라서 Object 명세에 적힌 두번째 조항을 위반한다.
심지어 두 인스턴스를 같은 해시 버킷에 담았더라고 m.get은 null을 반환한다.
HashMap은 해시코드가 같은 엔트리끼리는 동치성 비교 시도조차 하지 않게 최적화되어 있기 때문이다.
❗ hashCode() 재정의 방법
우선 좋지 않은 사례를 보겠다.
좋지 않은 hashCode() 작성법 💥
public class Person {
private String name;
private int age;
// Constructor and other methods omitted for brevity
@Override
public int hashCode() { //절대 사용 금지!!!
return 42;
}
}해시 테이블안에 저장하거나 해시맵 안의 키로서 사용하고 싶은 Person객체의 collection을 가지고 있다고 가정하자.
hashCode() 메소드는 각 객체를 위한 버킷 위치를 결정하기 위해 이 자료구조를 사용한다.
이제 person1, person2, person3 객체를 아래와 같이 선언했다고 하자.
일반적으로, 각 객체의 해시코드 값은 이름, 나이같은 각자만의 속성(attributes)에 기반하지만, 이 코드 예시에서는 객체의 속성에 상관없이 42만 반환한다.
Person person1 = new Person("Alice", 25);
Person person2 = new Person("Bob", 30);
Person person3 = new Person("Charlie", 35);위 코드는 사용할 수는 있으나 모든 클래스의 객체에 대해서 같은 같은 값만 내어준다.
따라서 모든 객체가 아래와 같이 해시테이블의 버킷 하나만 담겨 마치 연결 리스트 처럼 동작한다.
HashMap<Person, String> personMap = new HashMap<>();
personMap.put(person1, "Value 1");
personMap.put(person2, "Value 2");
personMap.put(person3, "Value 3");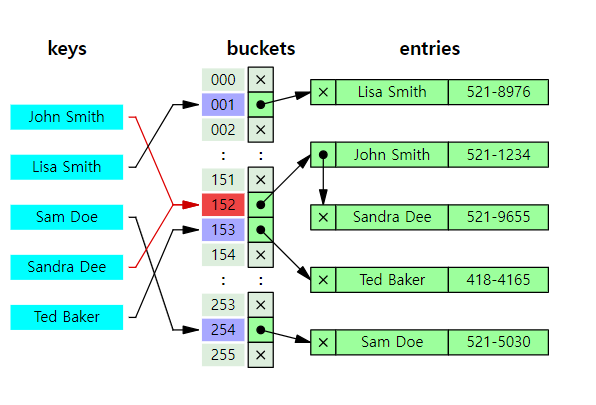
[그림 1]
[그림 1]에서 하나의 bucket만 있다고 상상해보라.
그럼 HashMap에서 모든 entries들이 연결되어 LinkedList처럼 동작한다...
그 결과 효율적인 해시테이클의 평균 수행시간이 O(1)에서 O(n)으로 늘어나 객체가 많아지면 감당되지 않는다...
[참고]
HashMap에서의 Key, Bucket, Entry
1.key
해시맵에서 데이터 저장,조회시 기준이 되는 값
2. hashcode()와 bucket
HashMap은 key의 hashcode()를 이용해 어떤 bucket에 저장할 지를 결정한다.
int hash = hash(key.hashCode()); // 보통 해시 함수를 한 번 더 가공
int bucketIndex = hash % table.length;3. Entry
- key-value를 저장하는 객체
- 하나의 bucket은 여러개의 Entry를 가질 수 있다.
상속을 사용할 때 equals()와 hashCode() 재정의발생 가능한 문제
상속을 사용할 경우, 부모 클래스와 자식 클래스 간의 equals() 비교에서 대칭성(symmetric)이나 추이성(transitive) 위반이 발생할 수 있습니다. 이러한 문제를 방지하기 위해 getClass()를 사용하거나, 상속보다는 구성을 사용하는 것이 바람직하다.
구성을 사용하면 equals()와 hashCode() 재정의가 어떻게 쉬워질까?
성을 사용하면 클래스 간의 결합도가 낮아지고, equals()와 hashCode()를 재정의할 때 상속 구조로 인한 복잡한 고려사항이 줄어듭니다. 이는 코드의 유지보수성과 확장성을 높이는 데 도움이 된다.
equals()와 hashCode()를 재정의하지 않을때 발생 가능한 문제
equals()와 hashCode()를 재정의하지 않으면, HashMap이나 HashSet과 같은 컬렉션에서 객체를 제대로 찾지 못하거나 중복 저장되는 등의 문제가 발생할 수 있다. 이는 프로그램의 버그로 이어질 수 있으므로, 두 메서드를 함께 재정의하는 것이 중요.
좋은 hashCode() 작성법 ❤
좋은 해시함수는 서로 다른 인스턴스에 대해 다른 해시함수를 반환한다.
"이상적인 해시함수" 는 주어진 (서로 다른) 인스턴스들을 32비트 정수 범위에 균일하게 분배해야한다.
다음은 이와 비슷하게 구현하는, 좋은 hashCode를 작성하는 요령이다.
- int 변수 result를 선언 후, 값 c로 초기화한다.
이때 c는 해당 객체의 첫번째 핵심 필드([item 10] equals 비교에 사용되는 필드)를 단계 2.a 방식으로 계산한 해시코드이다.
- 해당 객체 나머지 핵심 필드 f 각각에 대해 다음 작업을 수행한다.
a. 해당 필드의 해시 코드 c를 계산한다.
- <Case 1. 기본 타입 필드라면>,
Type.hashCode(f)를 수행한다. 여기서 Type은 해당 기본 타입의 박싱 클래스이다. - <Case 2. 참조 타입 필드면서 이 클래스의 equals()가 이 필드의 equals()를 재귀적으로 호출해 비교한다면>, 이 필드의 hashCode를 재귀적으로 호출한다.
import java.util.Objects;
public class Person {
private String name;
private int age;
// Constructors, getters, setters, etc.
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person person = (Person) o;
return age == person.age && Objects.equals(name, person.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}위 코드에서 Person 클래스는 name과 age라는 두 개의 필드를 가지고 있습니다.
equals() 메서드는 name과 age 필드를 "재귀적으로 호출"하여 두 객체가 동일한지 비교,
hashCode() 메서드는 name과 age 필드의 hashCode()를 재귀적으로 호출하여 해시 코드를 반환합니다.
- <Case 3. 필드가 배열이라면>
- 핵심 원소 각각을 필드처럼 다룸
- 이상의 규칙을 재귀적으로 적용
- 각 핵심 원소의 해시코드를 계산한 다음, 단계
2.b방식으로 갱신
(++ 각 배열의 핵심원소가 없다면 0, 모든 원소가 핵심 원소라면Arrays.hashCode()사용)
b. 단계 2.a에서 계산한 해시코드(c)로 아래와 같이 result를 갱신한다.
- result = 31 * result + c ;
- result 반환
위의 방식대로 hashCode()를 구현하였다면 동치인 인스턴스에 대해 똑같은 해시코드를 반환할지 단위 테스트를 짜는 것을 추천한다.
(단, 아래 코드과 같이 equals와 hashCode 메서드를 AutoValue로 설정했다면 건너뛰기.)
//AutoValue 예시
import com.google.auto.value.AutoValue;
@AutoValue
public abstract class Person {
public abstract String getName();
public abstract int getAge();
public static Person create(String name, int age) {
return new AutoValue_Person(name, age);
}
}계산 제외 대상
이러한 hashCode 메서드를 구현할 때 몇가지 제외대상이 있다.
- 파생필드(다른 필드로부터 계산 가능한 필드)
- equals 비교에 사용되지 않은 필드 (반드시 제외!!)
단계 2.b 에서 31을 곱하는 이유
이는 필드를 곱하는 순서에 따라 result값이 달라지게 하여 해시의 효과를 크게 높여주기 때문이다.
또한 31은 홀수이면서 소수(Prime)이다. 만약 곱하는 수가 짝수이고 오버플로우가 발생하면 시프트 연산과 같아져 정보는 소실된다.
마지막으로 시프트연산과 뺄셈을 대체해 최적화할 수 있다고도 한다.
추가로 chatgpt reference를 기재한다.
31을 사용하는 이유 (chatgpt)
Prime number: 31 is a prime number, and using a prime number as a multiplier helps reduce the likelihood of collisions, where different objects end up with the same hash code.
Bit spreading: Multiplying by 31 can be seen as a form of bit spreading. Each multiplication by 31 introduces a new factor into the computation, distributing the bits of the input value across the resulting hash code. This helps minimize clustering of hash codes and improves the probability of a uniform distribution.
Efficient multiplication: In terms of performance, multiplying by 31 can be more efficient compared to other multiplication factors. The compiler can optimize the multiplication by 31 using bit shifting and subtraction operations internally, resulting in efficient code execution.
아래는 PhoneNumber에 딱 맞게 구현한 코드예시이다.
// 모범사례 ^_^
@Override
public int hashCode(){
int result = Short.hashCode(areaCode);
result = 31*result + Short.hashCode(prefix);
result = 31*result + Short.hashCode(lineNum);
return result;
}-
PhoneNumber 인스턴스의 핵심 필드 3개(areaCode, prefic, lineNum)만을 사용해 간단히 계산만 수행한다.
추가로, 해시 충돌이 더욱 적은 방법을 꼭 써야한다면 구아바의 com.goole.common.hash.Hashing [Guava]을 참조하자!
hash 메서드 사용 시기
Object클래스에서 임의의 개수만큼 객체를 받아 해시코드를 작성해주는 정적 메서드인
hash메서드는 속도가 느리다.따라서 성능에 민감하지 않은 상황에서 사용을 권장한다.
// 한줄짜리 hashCode 메서드, 성능이 아쉽다... @Override public int hashCode(){ return Objects.hash(lineNum, prefix, areaCode); }Cashing을 고려해야 하는 상황
매번 새로 계산하기 보다 캐싱(cashing)을 고려해야하는 경우는 다음과 같다.
- 클래스가 불변
- 해시코드를 계산하는 비용이 큼 이 타입의 객체가 주로 해시의 키로 사용될 것 같다면 인스턴스가 만들어 질 때 해시코드를 반환해야 한다. 해시의 키로 사용되지 않을 때는
지연 초기화(lazy initialization, hashCode가 처음 불릴 때 계산)을 아래와 같이 생각해 볼 수도 있다. (굳이 이럴 필요는 없다...)// 쓰레드 안전성까지 고려하기! @Override public int hashCode(){ int result = hashCode; if (result == 0){ int result = Short.hashCode(areaCode); result = 31*result + Short.hashCode(prefix); result = 31*result + Short.hashCode(lineNum); hashCode = result; } return result; }
마무리
핵심은 성능을 높인답시고 해시코드를 계산할 때 핵심 필드를 생략해서는 안된다!
이는 해시 품질의 심각한 저하로 이어진다.
또한, 해당영역의 수많은 인스턴스가 단 몇개의 해시코드로 집중된다.
또, hashCode가 반환하는 값의 생성 규칙을 API 사용자에게 자세히 공표해, 클라이언트에게 신뢰를 주자!
