정렬 Sorting
데이터를 특정한 기준에 따라 순서대로 나열하는 것.
| 종류 | 정의 |
|---|---|
| 버블(bubble) | 데이터의 인접 요소끼리 비교하고, swap 연산을 수행하며 정렬 |
| 선택(selection) | 대상에서 가장 크거나 작은 데이터를 찾아가 선택을 반복하면서 정렬 |
| 삽입(insertion) | 대상을 선택해 정렬된 영역에서 선택 데이터의 적절한 위치를 찾아 삽입하면서 정렬 |
| 퀵(quick) | pivot 값을 선정해 해당 값을 기준으로 정렬 |
| 병합(merge) | 이미 정렬된 부분 집합들을 효율적으로 병합해 전체를 정렬 |
| 기수(radix) | 데이터의 자릿수를 바탕으로 비교해 데이터를 정렬 |
| 계수(counting) | 데이터의 값을 새로운 배열의 인덱스로 삼아서 횟수를 저장해 정렬 |
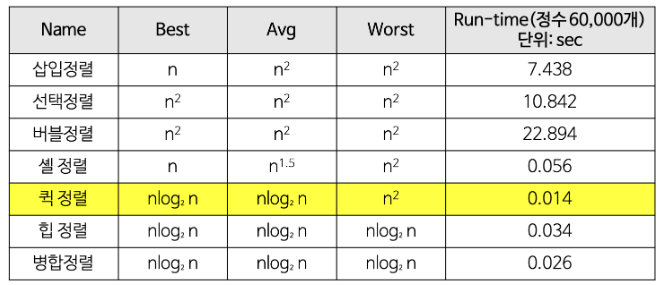
버블정렬 Bubble Sort
두 인접한 데이터의 크기를 비교해 정렬하는 방법
시간복잡도: , 속도 느림
- 비교 연산이 필요한 루프 범위를 설정한다.
- 인접(이웃)한 데이터 값을 비교한다.
- swap 조건에 부합하면 swqp 연산을 수행한다.
- 루프 범위가 끝날 때 까지 2~3을 반복한다.
- 정렬 영역을 새롭게 설정한다.
- 비교 대상이 없을 때 까지 1~5를 반복한다.
파란색 부분은 무조건 배열 중 가장 큰 값으로, 고정시킬 수 있다. 요소가 n개인 루프를 n번 돌면 n개의 요소가 정렬된다.(시간복잡도: )
swap이 한번도 발생하지 않는다면 데이터가 모두 정렬되었다는 뜻. n번 다 돌지않아도 프로세스 종료 가능.
public class Test {
private static void bubbleSort(int[] arr) {
bubbleSort(arr, arr.length -1);
}
private static void bubbleSort(int[] arr, int lastIdx) {
boolean terminate = true;
if (lastIdx > 0) {
for(int i = 1; i <= lastIdx; i++) {
if (arr[i-1] > arr[i]) {
swap(arr, i -1, i);
terminate = false;
}
}
if (terminate == true) return; // 조기 종료
bubbleSort(arr,lastIdx - 1);
}
}
private static void swap(int[] arr, int source, int target) {
int tmp = arr[source];
arr[source] = arr[target];
arr[target] = tmp;
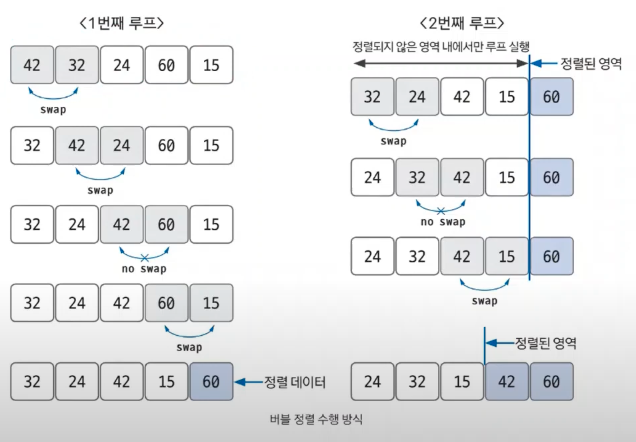
}선택 정렬 Selection Sorting
처리되지 않은 데이터 중에서 가장 작은(큰) 데이터를 선택해 맨 앞에 있는 데이터와 바꾸는 것을 반복
구현 방법이 복잡함.
시간 복잡도:
- 남은 정렬 부분에서 최솟값 또는 최댓값을 찾는다.
- 남은 정렬 부분에서 가장 앞에 있는 데이터와 선택된 데이터를 swap한다.
- 가장 앞에 있는 데이터의 위치를 변경(index+1)하고 남은 정렬 부분의 범위를 재정의한다.
- "전체 데이터 크기 == index" 가 될 때까지 반복한다.
선택 정렬은 N개의 요소가 있는 루프를 N번 가장 작은 수를 찾아서 맨 앞으로 보내야 함.
public class Test {
private static void selectionSort(int[] arr) {
selectionSort(arr, 0);
}
private static void selectionSort(int[] arr, int startIdx) {
if (startIdx < arr.length -1) {
int min_index = start;
for (int i = start; i < arr.length; i++) {
if (arr[i] < arr[min_index]) min_index = i;
}
swap(arr, start, min_index);
seslctionSort(arr, start + 1);
}
}
private static void swap(int[] arr, int source, int target) {
int tmp = arr[source];
arr[source] = arr[target];
arr[target] = tmp;
}
}import java.util.*;
public class Main {
public static void main(String[] args) {
// 입력
for (int i=0; i<n; i++) {
int minIndex = i;
for (int j=i+1; j<n; j++) {
if (arr[minIndex] > arr[j]) {
minIndex = j;
}
}
int temp = arr[i];
arr[i] = arr[minIndex];
arr[minIndex] = temp;
}
// 출력
}
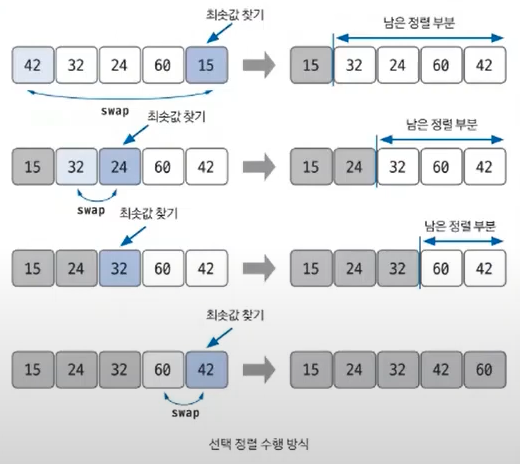
}삽입 정렬 Insertion Sorting
이미 정렬된 데이터 범위에 정렬되지 않은 데이터를 적절한 위치에 삽입시켜 정렬하는 방식.
시간복잡도: *이진탐색 이용시
- 현재 index의 값을 선택한다.
- 선택한 데이터가 삽입될 위치를 탐색한다. (binary search 사용시 효율적)
- 삽입 위치부터 index 위치까지 원소들을 shift 시킨다.
- 삽입 위치에 현재 선택한 데이터 삽입하고, index를 1증가 시킨다.
- 전체 데이터의 크기만큼 index가 커질 때까지 반복한다.
import java.util.*
public class Main {
public static void main(String[] args) {
// 입력
for (int i = 1; i < n; i++) {
for (int j = i; j > 0; j--) {
if (arr[j] < arr[j-1]) {
int temp = arr[j];
arr[j] = arr[j-1];
arr[j-1]=temp;
}
else break;
}
}
// 출력
}
}병합 정렬 Merge Sorting
데이터를 분할하고 분할한 집합을 정렬하며 합치는 알고리즘 *분할정복방식
시간복잡도: , N개의 데이터를 돌고 이 과정을 logN번 반복한다.
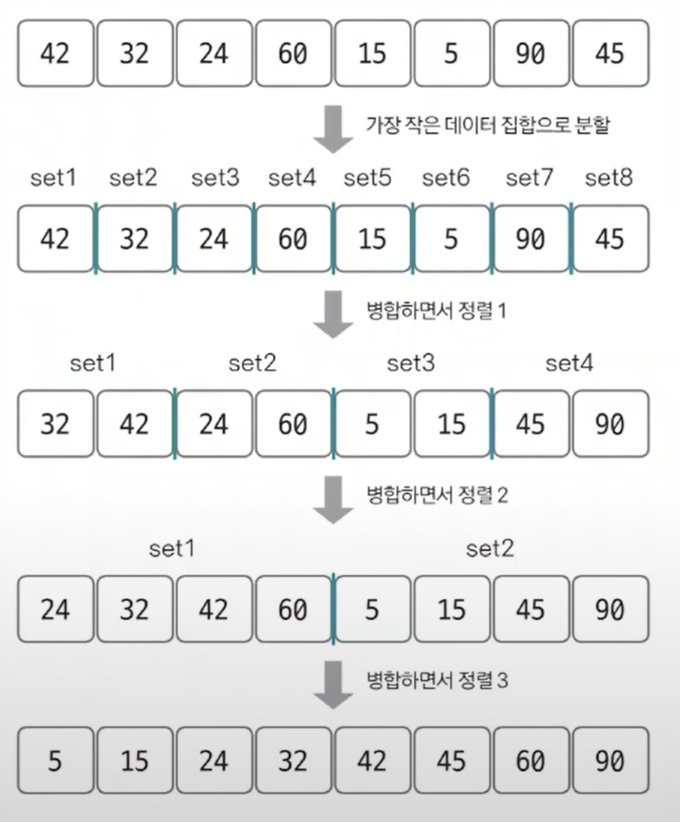
- 전체를 N개의 그룹으로 나눈다.
- 각 그룹을 2개씩 짝지어 정렬한다.(병합 정렬1)
- 정렬한 각 그룹을 2개씩 짝지어 정렬한다. (병합 정렬2)
- 하나의 큰 그룹이 남을 때까지 지속한다.
2개의 그룹을 병합하는 과정
두개의 인덱스를 사용하여 정렬되어있는 왼쪽 그룹과 오른쪽 그룹을 하나로 병합한다.
알고리즘 문제, 코딩테스트에서 자주 활용되는 아이디어이다. (ex. 자동차 경주 중 추월 횟수 = 원래 인덱스 - 현재 인덱스)
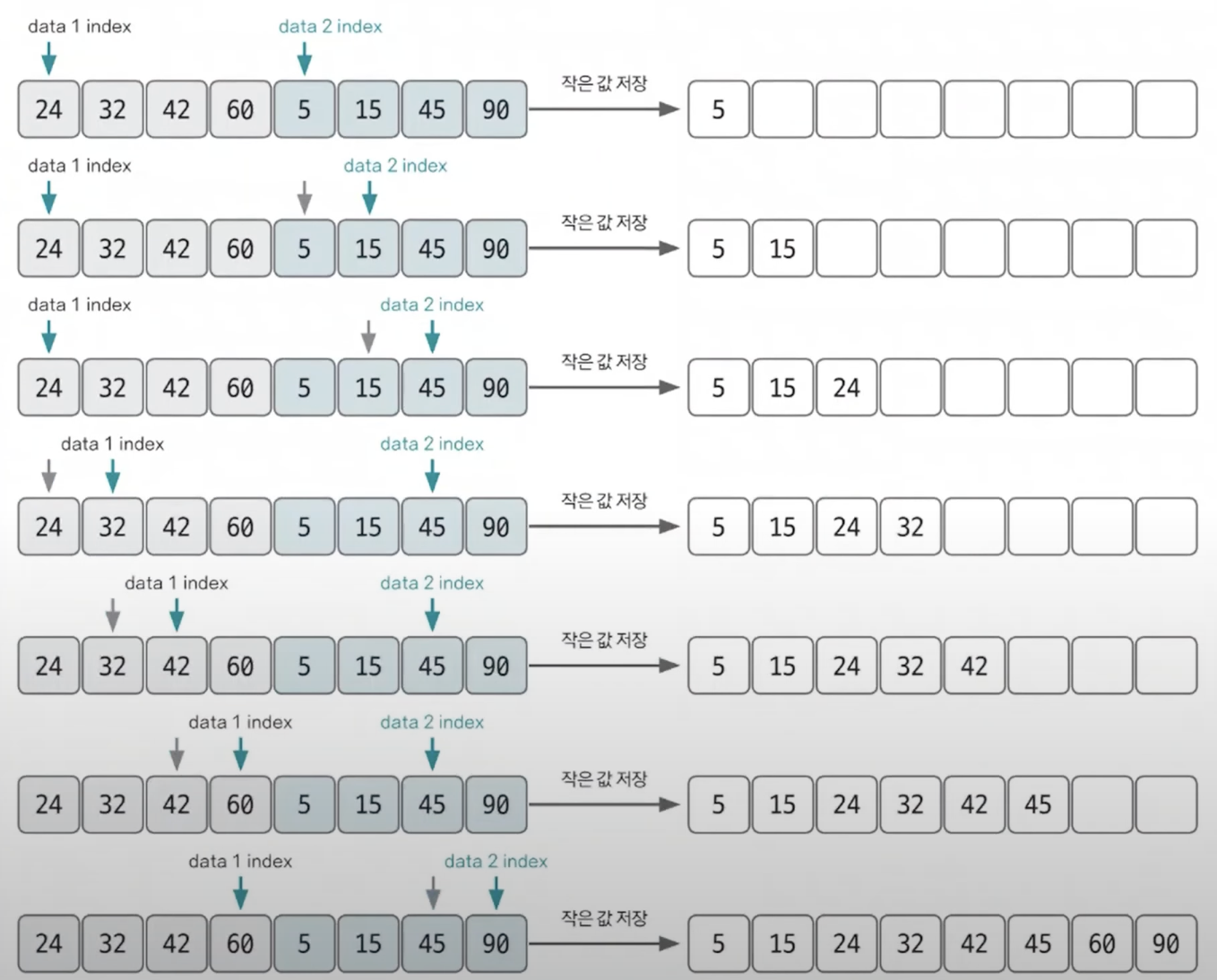
- 각 그룹의 맨 앞 값(작은 값)을 서로 비교한다.
- 둘 중 더 작은 값을 큰 배열에 저장한다.
- 그 그룹의 인덱스를 오른쪽으로 한칸 이동시킨다.
- 하나의 그룹의 값이 모두 옮겨질 때 까지 1-2를 반복한다.
- 남은 그룹은 큰 배열의 뒤에 그대로 저장한다.
public class Test {
private static void mergeSort(int[] arr) {
int[] tmp = new int[arr.length];
mergeSort(arr, temp, 0, arr.length - 1);
}
private static void mergeSort(int[] arr, int[] tmp, int start, int end) {
if (start < end) {
int mid = (start + end) / 2;
mergeSort(arr, tmp, start, mid);
mergeSort(arr, tmp, mid + 1, end);
merge(arr, tmp, start, mid, end);
}
}
private static void merge(int[] arr, int[] tmp, int start, int mid, int end) {
for (int i = start; i <= end; i++) {
tmp[i] = arr[i];
}
int part1 = start;
int part2 = mid + 1;
int index = start;
while (part1 <= mid && part2 <= end) {
if (tmp[part1] <= tmp[part2]) {
arr[index] = tmp[part1];
part1++;
}
else {
arr[index] = tmp[part2];
part2++;
}
index++;
}
for (int i = 0; i <= mid - part1; i++) {
arr[index + i] = tmp[part1 + i];
}
}
}퀵 정렬 Quick Sorting
기준 데이터(Pivot)를 설정하고 그 기준보다 큰 데이터와 작은 데이터의 위치를 바꾸는 방법.
병합정렬과 더불어 대부분의 프로그래밍 언어의 정렬 라이브러리의 기본이 된다. 가장 많이 쓰이는 정렬 알고리즘.
시간복잡도:
최악의 경우(이미 정렬된 배열):
표준 정렬 라이브러리는 를 보장한다.
시간 복잡도가 O(nlog₂n)를 가지는 다른 정렬 알고리즘과 비교했을 때도 가장 빠르다.
퀵 정렬이 불필요한 데이터의 이동을 줄이고 먼 거리의 데이터를 교환할 뿐만 아니라, 한 번 결정된 피벗들이 추후 연산에서 제외되는 특성 때문이다.
https://gmlwjd9405.github.io/2018/05/10/algorithm-quick-sort.html
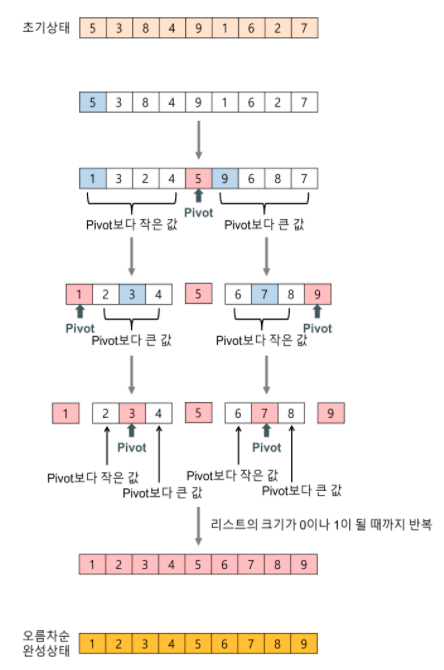
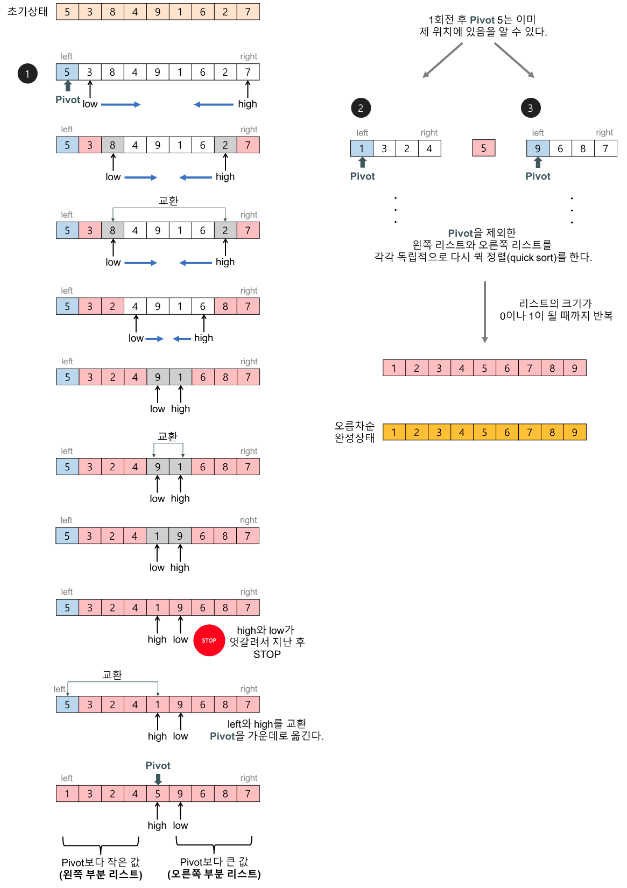
- 제일 앞의 값을 피벗으로 설정한다.
- 왼쪽부터는 피벗보다 큰 데이터, 오른쪽부터는 피벗보다 작은 데이터를 찾아 선택한다.
- 두 데이터의 위치를 바꾼다.
- 커서의 위치가 엇갈릴 때까지 3을 반복한다.
- 위치가 엇갈리면 피벗과 작은데이터의 위치를 바꾼다.
- 피벗 좌우의 배열에 대해서 전체과정을 반복한다.
public class Main {
public static void quickSort(int[] arr, int start, int end) {
if(start >= end) return; // 원소가 1개인 경우 종료
int pivot = start; //피벗은 첫번재 원소
int left = start + 1;
int right = end;
while (left<=right) {
while(left <=end && arr[left] <= arr[pivot]) left++; // 피벗보다 큰 데이터를 찾을 때 따지 반복
while(right > start && arr[right] >= arr[pivot]) right--; //피벗보다 작은 데이터를 찾을 때 까지 반복
if (left > right) { //엇갈렸다면 작은 데이터와 피벗을 교체
int temp = arr[pivot];
arr[pivot] = arr[right];
arr[right] = temp;
}
else {
int temp = arr[left];
arr[left] = arr[right];
arr[right] = temp;
}
}
// 분할 이후 왼쪽 부분과 오른쪽 부분에서 각각 정렬 수행
quickSort(arr, start, right -1);
quickSort(arr, right + 1, end);
}
}public class Test {
private static void quickSort(int[] arr) {
quickSort(arr, 0, arr.lenth -1);
}
private static void quickSort(int[] arr, int start, int end) {
int part2 = partition(arr, start, end);
if (start < part2 - 1) {
quickSort(arr, start, part2 - 1);
}
if (part2 < end) {
quickSort(arr, part2, end);
}
}
private static int partition(int[] arr, int start, int end) {
int pivot = arr[(start + end) / 2];
while (start <= end) {
while (arr[start] < pivot) start++;
while (arr[end] > pivot) end--;
if (start <= end) {
swap(arr, start, end);
start++;
end--;
}
}
return start;
}
private static void swap(int[] arr, int start, int end) {
int tmp = arr[start];
arr[start] = arr[end];
arr[end] = tmp;
}
}계수 정렬 Counting Sorting
데이터의 크기 범위가 제한되어 정수형태로 표현할 수 있을 때 사용 가능하다. 특정한 조건이 부합할 때만 사용할 수 있지만 매우 빠르게 동작하는 정렬 알고리즘이다. 데이터가 0, 999,999 단 두개만 존재할때는 매우 비효율적이나, 100점 만점(제한된 데이터크기)의 성적을 정렬하는 것에서는 효과적으로 쓰인다.
시간복잡도: (데이터의 개수 N, 데이터(양수) 중 최댓값 K)
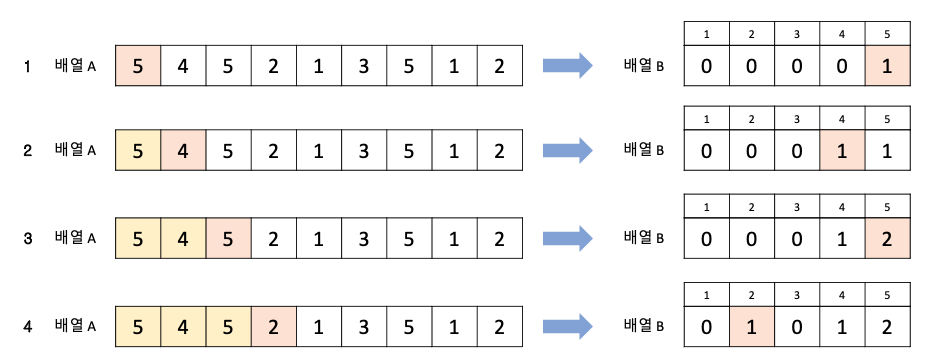
- 데이터의 범위가 모두 담길 수 있도록 리스트를 생성한다.
- 데이터를 하나씩 확인하며 데이터의 값과 동일한 인덱스의 데이터 1씩 증가시킨다.
- 결과적으로 최종 리스트에는 각 데이터가 등장한 횟수가 기록된다.
- 리스트의 인덱스를 그 횟수만큼 차례대로 출력한다.
import java.util.*;
public class Main {
public static final int MAX_VALUE = 9;
public static void main(String[] args) {
int n = 15;
int[] arr = {7,5,9,0,3,1,6,2,9,1,4,8,0,5,2]; // 모든 원소의 값이 0보다 크거나 같다고 가정
int[] cnt = new int[MAX_VALUE + 1]; // 모든 범위를 포함하는 배열 선언(모든 값은 0으로 초기화)
for (int i=0; i<n; i++) {
cnt[arr[i]] +=1; // 각 데이터에 해당하는 인덱스의 값 증가
}
for (int i=0; i<=MAXK_VALUE; i++) { // 배열에 기록된 정렬 정보 확인
for (int j=0; j<cnt[i]; j++) {
System.out.print(i + " "); // 띄어쓰기를 기준으로 등장한 횟수만큼 인덱스 출력
}
}
}
}