db에 저장되어 있는 아주 많은 데이터에서 특정 구간(아마도 시간)에 대해 sum(혹은 min, max 등등,,,) 값을 구하기 위해 어떤 방법이 생각나시나요?
아마 일반적으로 생각나는 방식은 인덱스를 활용하여 where절로 range 조건을 걸어 계산하는 방식일 것입니다.
sql문으로 표현하면 아래와 비슷하게 되겠죠.
SELECT SUM(column1) FROM table1 WHERE time > ${time1} AND time < ${time2};시간 칼럼에 인덱스를 걸어놓는다면 당연하게도 이 방식은 인덱스를 타기 때문에 효율적이라고 느껴집니다. 실제로 인덱스가 없을 때 풀스캔을 하는 것과는 비교가 안될 정도로 빠르기도 하고요.
그런데 과연 이게 최선의 방법이라고 생각할 수 있을까요?
이 글에서는 이러한 문제에 대해 고민하고, 직접 구현하여 성능을 비교해본 결과를 설명하려고 합니다.
range에 대해 sum을 구한다?!
저장소로써 db를 자주 사용하는 사람 입장에서는, 당연히 위에서 이미 설명한 방식이 생각날 것입니다.
하지만 저는 한때 ps를 하던 때가 있어서 그런지, 이 문제를 해결하는 가장 좋은 방법 중 하나는 segment tree를 활용하는 것이라고 생각했습니다.
하지만 저의 상황에서는 인메모리에서는 구현이 불가능할 정도로 사이즈가 크기 때문에(최소 1억 이상) 인메모리가 아닌 db에 구현을 하고자 했습니다. 그리고 db에서 range로 긁어오는 방법이 내부적으로 어느 정도까지 최적화가 되어있는지는 모르겠지만, 아무튼 범위 내의 모든 row를 들고 오긴 해야할테니 이 방법이 db에서도 더 효율적이라고 생각했고요.
그러면 db에서 세그먼트트리를 어떻게…?
보통 우리는 자료구조를 인메모리에서 구현합니다. 오픈소스나, 내장 라이브러리를 활용해서 구현하곤 하죠.
그래서 굳이 세그먼트 트리가 아니어도 자료구조를 db 상에서 구현하는 것은 너무나 생소했고 어렵게 느껴졌습니다.
결론적으로 일단 자료구조를 db 상에서 구현하는 경우가 있기도 한가 하고 구글링을 해봤습니다.
https://stackoverflow.com/questions/65205/linked-list-in-sql
놀랍게도(?) 많은 사람들이 db상에 자료구조를 구현하는 것에 대해 고민하고 있었습니다. 그리고 더 놀랍게도(?) 그 방법은 저의 상상과 크게 다르지 않았습니다. 구체적으로는 array base 자료구조(stack 등,,)는 array의 index를 의미하는 칼럼을 추가하고, node base 자료구조(linked list 등,,)는 필요한 요소들(next node id 등)을 의미하는 칼럼을 추가하는 방식이었습니다.
세그먼트 트리 역시 비슷하게 구현하면 되겠죠?
그런데 다른 조건이.....
세그먼트 트리는 기본적으로 array base입니다. 하지만 저의 상황이 조금 복잡했기에 array base로 쓰기에는 무리였습니다.
- 확장이 가능해야한다(데이터 사이즈가 커질 수 있다, 단 다행히도 시간순으로 입력된다)
- 구간이 연속하지 않을 수 있다.
일단 당장 확장 가능성에 대해서만 생각해봐도 총 데이터 수 n이 2^k (k는 임의의 정수) 를 넘어가는 순간 처리가 너무 어려워짐을 느낄 수 있었습니다. 그래서 node base로 구현을 진행하게 되었습니다.
그리고 node base로 구현하는 순간, 구간이 연속하지 않을 수 있는 문제에선 어느 정도 자유로워지게 됩니다.
구현 방법
사실 구현 방법 자체는 기본적으로 node base로 진행하겠다고 결정된 순간 그렇게 어려운 일은 아닙니다. 그래도 구현을 위한 스펙과 연산에 대해 조금(?) 서술하도록 하겠습니다.
- 테이블 스펙
CREATE TABLE example_tree(
id text primary key, -- root 노드일 경우 'root'
val numeric, -- 구간 sum value
is_full boolean, -- 좌우 child가 모두 꽉차있는지
left_id text,
right_id text,
start_time timestamptz,
end_time timestamptz
)- add 연산의 편의를 위해 트리는 perfect binary tree로 유지합니다(값이 없는 범위의 경우 값만 빈값으로 넣고 노드 자체는 유지합니다)
트리 모식도
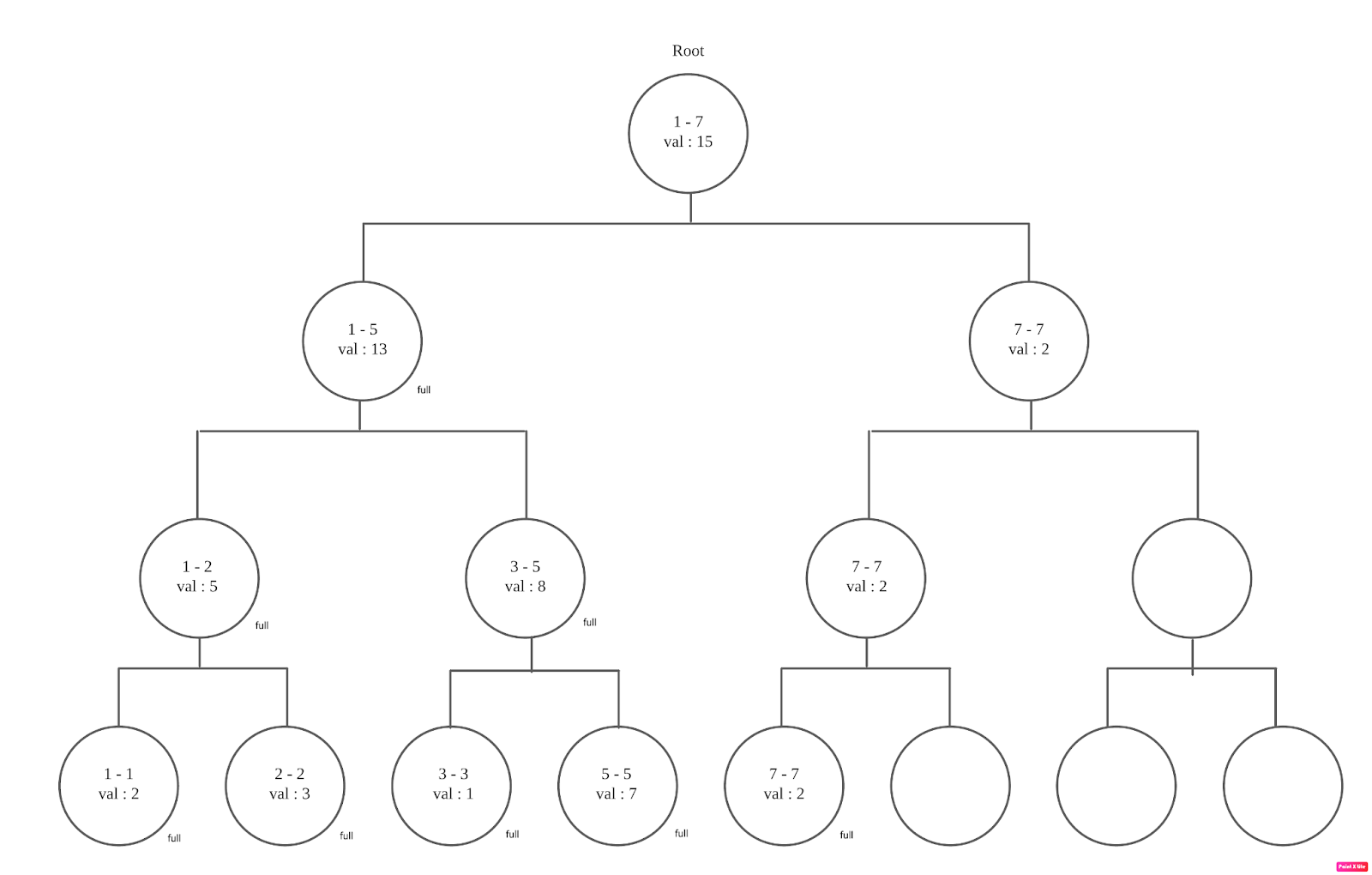
leaf노드는 정의상 left child와 right child가 null이고, val이 있을 경우 is_full = true입니다.
7개 데이터가 들어가있을 때 테이블 상태 예시
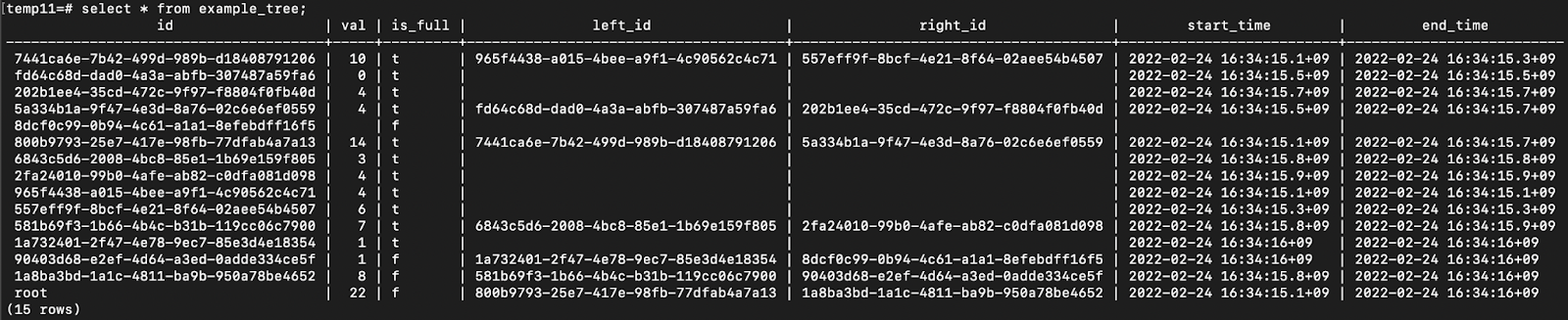
연산들
-
find root
세그먼트 트리를 노드 기반으로 구현하기 때문에 다른 연산에 필수적으로 필요한 부분입니다.
root노드는 매 연산마다 쓰일 것이므로 그 위치를 따로 가지고 있도록 합니다 (제 경우에는 id를 따로 root로 주고, 나중에 새로운 root를 추가해야 할 때는 따로 더 처리를 해주도록 했습니다) -
Add 연산
확장이 가능해야 한다는 조건을 만족시키기 위해 추가한 연산입니다. 크게 세가지로 나뉩니다.
-
Root가 없을때(빈 트리)
root를 생성합니다. -
tree가 모두 찼을 때(root의 is_full이 true일 때)
root를 새로 할당하고, 새로운 root의 left child는 기존 root로, right child는 빈 노드로 할당합니다. 그 후, 아래 연산을 진행합니다. -
이외
leaf노드 중에서 가장 왼쪽에 있는 비어있는 leaf를 찾아 값을 넣어주고, 트리를 업데이트 합니다.
구현은 아래를 참고해주세요(실제 코드와는 약간 다름)
addItem(item){
const root = getRootNode();
if(root === null){
initilizeRoot(item);
}else if(root.is_full || !root.left_id){
const newRoot = extendTree(root);
_addItem(newRoot, item);
}else{
_addItem(root, item);
}
}
_addItem(currentNode, item){
//leaf노드일 경우 value update하고 리턴
if(!currentNode.left_id && !currentNode.right_id){
const newNode = {
...currentNode,
...item,
is_full: true
};
updateDBNode(newNode);
return newNode;
}
//leaf노드가 아니면 좌우 child 확인하여 add
const leftNode = getDBNode(currentNode.left_id);
let newCurrentNode = {};
//왼쪽 child가 이미 다 찬 상황이 아니면 left child로 재귀호출 후 업데이트
if(leftNode.is_full === false){
const newLeftNode = _addItem(leftNode, item);
//left child가 full이 아니면 어차피 right child는 없으므로 왼쪽 기준으로 업데이트
newCurrentNode = {
...currentNode,
start_time: newLeftNode.start_time,
end_time: newLeftNode.end_time,
value: newLeftNode.value
};
}else{ //right child로 재귀호출 후 업데이트
const rightNode = getDBNode(currentNode.right_id);
const newRightNode = _addItem(rightNode, item);
newCurrentNode = {
...currentNode,
is_full: newRightNode.is_full,
end_time: newRightNode.end_time,
value: leftNode.value + newRightNode.value
};
}
updateDBNode(newCurrentNode);
return newCurrentNode;
}참고로 속도가 그냥 db insert와 비교했을 때 굉장히 느립니다. 하지만 삽입에 비해 검색 요청이 굉장히 많이 일어난다고 가정하고 넘어가도록 합시다.
- update 연산
우리가 흔히 생각하는 update 연산을 구현하면 됩니다.
updateItem(currentNode, item){ // item.start_time === item.end_time
if(currentNode === null){
return null;
}else if(item.start_time > currentNode.end_time || item.start_time < currentNode.start_time){
// 범위 밖이면 null 리턴
return null;
}else if(item.start_time === currentNode.start_time && item.start_time === currentNode.end_time){
// leaf노드일 때 그냥 덮어쓰워서 업데이트
const newCurrentNode = {
...currentNode,
value: item.value
};
updateDBNode(newCurrentNode);
return newCurrentNode;
}else{
const leftNode = getDBNode(currentNode.left_id);
const rightNode = getDBNode(currentNode.right_id);
// left node로 먼저 업데이트 시도
const leftResult = updateItem(leftNode, item);
if(leftResult){
//right Node의 값은 없을 수도 있으므로, 이를 고려하여 처리
const newCurrentNode = {
...currentNode,
value: rightNode.value?
leftResult.value + rightNode.value : leftResult.value,
};
updateDBNode(newCurrentNode);
return newCurrentNode;
}else{
const rightResult = updateItem(rightNode, item);
if(rightResult){
const newCurrentNode = {
...currentNode,
value: leftResult.value + rightNode.value,
};
updateNode(newCurrentNode);
return newCurrentNode;
}
}
//모두 실패
return null;
}
}- search 연산
update와 마찬가지로 우리가 흔히 생각하는대로 구현하면 됩니다.
searchRange(currentNode, startTime, endTime){
if(currentNode === null || currentNode.start_time === null){
return null;
}else if(currentNode.end_time <= startTime || currentNode.start_time >= endTime){
// 범위 밖이라면 null 리턴
return null;
}else if(startTime <= currentNode.start_time && currentNode.end_time <= endTime){
// 범위를 모두 포함하면, 이 노드의 정보 리턴
return {
value: currentNode.value
};
}else{
// 그 외엔 left child와 right child 방문하여 값들 결정
const leftNode = await this.dbConnector.getItemByID(currentNode.left_id);
const rightNode= await this.dbConnector.getItemByID(currentNode.right_id);
const leftResult = await this.searchRange(leftNode, startTime, endTime, marketID);
const rightResult = await this.searchRange(rightNode, startTime, endTime, marketID);
if(leftResult === null && rightResult === null){
return null;
}else if(leftResult === null){
return rightResult;
}else if(rightResult === null){
return leftResult;
}else{
return {
value: leftResult.value + rightResult.value,
};
}
}
}성능 비교
그렇게 구현을 마치고 예제 데이터를 무작위로 생성하여 일정 범위의 값을 조회하여 비교했습니다.
source 테이블 row 수 : 64713
tree 테이블 row 수 : 131071 (perfect binary tree를 유지하기 때문에 2^n - 1꼴임을 확인할 수 있음)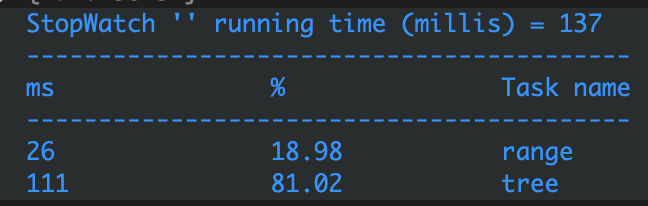
결과는…. 너무나도 슬펐습니다. 약 4배 가량이나 range로 쿼리하는 방식이 방식이 빠른게 보입니다.
왜 그럴까….. 대체 왜 그럴까… 고민하고 이것 저것 더 분석해봤습니다.
우선 두 방법의 구조를 다시 한번 간단하게 설명하면 다음과 같습니다.
-
세그먼트 트리
root부터 search 범위에 따라 child 노드를 방문하면서 검색
총 데이터의 개수를 n이라고 했을 때, db에는 최대 약 2 log n번 단순 쿼리(select * from table where id = ‘ID’)를 요청함 -
range query
db에 단 한번의 인덱스를 사용하는 range 쿼리를 요청함
세그먼트 트리의 경우, 2 log n번의 단순 쿼리가 대부분의 시간을 차지하고, range query의 경우 range query 자체가 대부분의 시간을 차지합니다. 이 둘의 시간을 비교하면 어떨까요? 과연 그래도 range query가 더 효율적일까요?
explain analyze select sum(val) from example where time > '2022-02-24 15:05:30.1+09' and time < '2022-02-24 15:35:30.1+09';
=> cost: 대략 3693 time: 대략 1.8ms
explain analyze select * from example_tree where id = '43cbd9aa-5e20-4bf3-a65f-cf5457d32fdd';
=> cost : 대략 8 time : 0.001ms 이하
=> tree leaf 노드 수 n = 10억이라고 가정하면 약 60번의 쿼리를 요청할 것이므로 총 cost: 480, time: 0.06ms 이하
!!!!! 역시 세그먼트 트리가 훨씬 효율적이었습니다!!!
사실 index는 데이터의 위치를 담고있기 때문에, index를 타고 스캔을 한다고 하더라도 index에 쓰이는 column의 max값을 구하는게 아니라면 한번 더 그 위치로 가서 데이터를 긁어와야 합니다. 그리고 이 비용들(범위에 따라 index 스캔하는 비용 + 데이터 긁어오는 비용)은 조회 범위에 따라 선형적으로 증가하게 되기 때문에 어떻게 보면 당연한 얘기입니다.
그렇다면 코드상에서는 왜 range query가 더 빠른 결과가 나왔던 것일까요?
저는 이에 대해 코드상에서 라이브러리를 이용하여 db 서버에 접속해서 쿼리할 때 생기는 오버헤드가 원인이라고 추측하고 있습니다. 실제로 코드에서 각 쿼리 소요시간을 측정해봤을 때 단순 쿼리의 경우 약 4~5ms, range query의 경우 약 25ms가 소요되고 있었습니다. 2 * log n번이라고 하지만, 애초에 오버헤드가 쿼리 효율의 차이보다 상대적으로 커서 의미가 없어지게 된 것이지요.
이 오버헤드를 없애는 것은 방법에 대해서만 간략하게 생각해보고, 미래의 숙제로 남기기로 했습니다.
- connection을 열고 닫는 데에걸리는 시간이 오래 걸릴 수 있습니다. 이에 따라 connection을 계속 열어두고 쿼리를 요청하는 방법을 생각할 수 있습니다. 하지만, 이는 보안 상의 문제로 좋은 해결 방법은 아닐 것입니다.
- 코드상에서 연산을 구현하지 않고, db 내에 stored procedure 형태로 저장하여 오버헤드를 개선할 수 있을 것이라 생각했습니다. 하지만 이는 코드 상에서 구현했던 내용을 그대로 반영하기는 굉장히 까다로울 것입니다(이것이 숙제로 남긴 이유이기도 합니다)
결론
range에 대해 sum값을 구해야 하는 상황을 해결하기 위해 일반적으로 사용하는 방법 외에 db 상에 세그먼트 트리를 구현하는 방법을 생각해냈고, 이에 대해 실제 상황에 맞게 세그먼트 트리를 직접 튜닝 후 구현하여 일반적인 방법과의 성능 분석까지 해봤습니다.
그 결과로 현재 코드상에서는 기존 방법의 효율이 더 좋게 나오지만, 구체적인 분석을 통해 코드 상에서 db에 접속할 때의 오버헤드를 개선할 경우 db상의 세그먼트 트리가 성능에 있어서 훨씬 더 효율적인 방법이 될 수 있다고 결론짓게 되었습니다.
물론 오버헤드 외에도 고려할 점들이 있긴 합니다. Add 연산의 효율이 기존 방식에 비해 굉장히 떨어진다는 점, 트리를 perfect binary tree로 유지하기 때문에 아무튼 그냥 저장하는 방식과 비교하여 공간을 최대 4배 정도 써야한다는 점이 그렇습니다.
하지만 이것은 (글에서 직접적으로 다루지는 않았지만), 서비스에서 사용할 최소 단위(1분 등)로 잘라서 (이 경우에 트리의 leaf노드에서도 범위에 대한 정보를 저장하게 됩니다) flush 해주는 방식을 사용하여 Add연산의 횟수를 줄이고, 공간 역시 (1분마다 한번씩 데이터가 들어오는 것처럼 최악의 경우에는 여전하겠지만) 대부분의 상황에서 기존보다 훨씬 줄일 수 있습니다.
그러면 애초에 서비스에서 사용하는 최소 단위로 잘라서 테이블 하나를 더 만들면 되는거 아니냐! 하는 생각이 들 수 있는데
결국 단위를 좀 더 크게 해도, 같은 단위라면 segment tree 방식과 range query 방식의 효율 차이는 여전히 발생할 것입니다
그렇기 때문에 db 오버헤드와 관련된 문제만 해결된다면 search의 비중이높은 서비스에서 이 방법을 직접 도입해봐도 좋을 것 같습니다.
또한 효율 뿐만 아니라, 각각 쿼리의 부담이 적어지기 때문에 long query 비중을 훨씬 줄일 수 있어 db 부하를 줄일 수 있다는 점에서도 괜찮은 방법이라고 느껴집니다.
그리고 세그먼트 트리의 경우 결국 여러번 db상의 노드에 접근해야하기 때문에 오버헤드가 문제가 되었지만, 다른 문제에 대해 상대적으로 데이터 접근이 적은 자료구조를 사용하게 될 경우에도 db상에 자료구조를 구현하는 방법에 대해 적극적으로 고려해봐도 좋을 것 같습니다.
그리고 이 글에서는 세그먼트 트리에 대해 다루고 있었지만, 다른 문제에 대해서도 일반적인 방법 뿐만 아니라 db상에 자료구조(linked list 등등,,)를 구현하는 것도 고려해보면 좋을 것 같습니다.
추후에는 라이브러리에서 제공하는 db client의 오버헤드를 개선하는 작업을 해보면 좋지 않을까 생각합니다.
