군집화(clustering) 알고리즘
데이터를 유사한 것들끼리 모으는 것
군집 간의 유사도는 작게, 군집 내의 유사도는 크게
군집 간의 거리는 크게, 군집 내의 거리는 작게
계층적 군집화
군집화의 결과가 군집들이 계층적인 구조를 갖도록 하는 것
병합형 계층적 군집화(바텀 업 방식)
- 각데이터가 하나의 군집을 구성하는 상태에서 시작하여, 가까이에 있는 군집들을 결합하는 과정을 반복하여 계층적인 군집 형성
분리형 계층적 군집화(탑 다운 방식) - 모든 데이터를 포함한 군집에서 시작하여 유사성을 바탕으로 군집을 분리하여 점차 계층적인 구조를 갖도록 구성
분할 군집화
계층적 구조를 만들지 않고 전체 데이터를 유사한 것들끼리 나누어 묶는 것
ex) k-means 알고리즘
계층적 군집화와 덴드로그램

k-means 알고리즘
- 과정
- 군집의 중심위치(k개) 선정
- 군집 중심을 기준으로 군집 재구성
- 군집별 평균 위치 결정
- 군집 평균 위치로 군집 중심 조정
- 수렴할 때까지 2-4 과정 반복
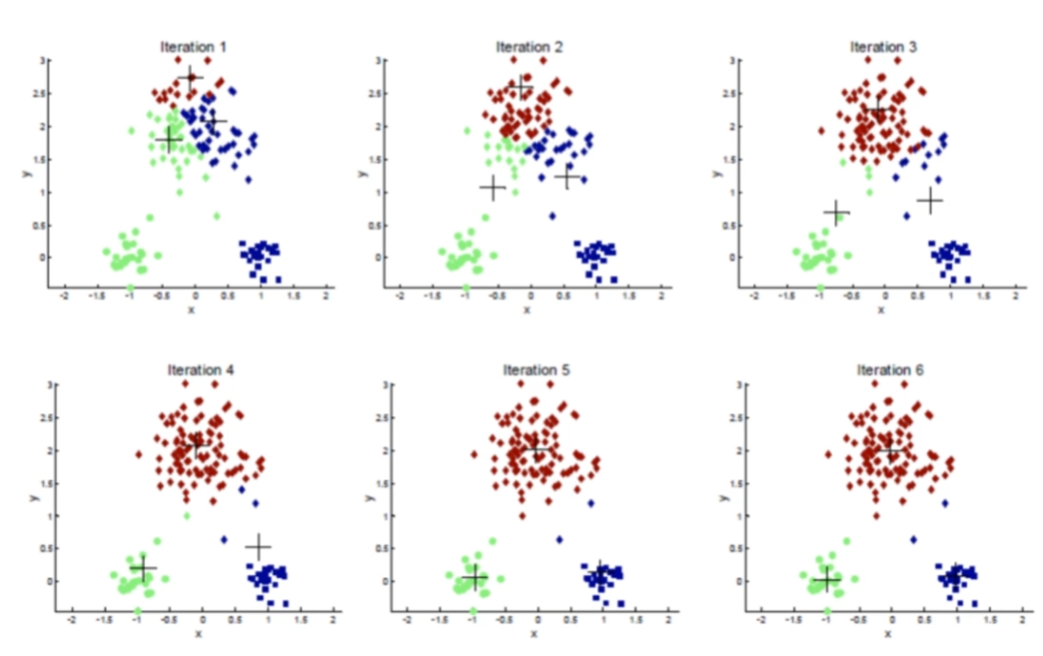
- i번째 클러스터의 중심을 , 클러스터에 속하는 점의 집합을 라고 할 때, 전체 분산
- 분산값 V을 최소화하는 를 찾는 것이 알고리즘의 목표
- 과정
- 우선 초기의 를 임의로 설정
- 다음 두 단계를 클러스터가 변하지 않을 때까지 반복
i. 클러스터 설정: 각 점에 대해, 그 점에서 가장 가까운 클러스터를 찾아 배당한다.
ii. 클러스터 중심 재조정: 를 각 클러스터에 있는 점들의 평균값으로 재설정해준다.
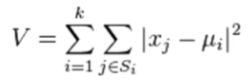
- 특성
- 군집의 개수 k는 미리 지정
- 초기 중심값(군집 위치)에 민감
초기 중심값에 대해 민감한 군집화 결과
초기 중심값에 민감하여 원하지 않는 결과가 나올 수 있다.
이때는 원하는 결과가 나오게 하기 위해 초기 중심값을 재설정한다.
단순 베이즈 분류기
- 부류 결정지식을 조건부 확률로 결정

- 베이즈 정리

- 가능도의 조건부 독립 가정 -> 단순 베이즈 분류기의 가정
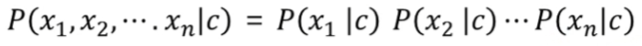
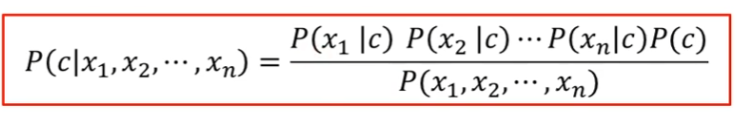

개발자로 공부하며 느낀 여러가지 경험들