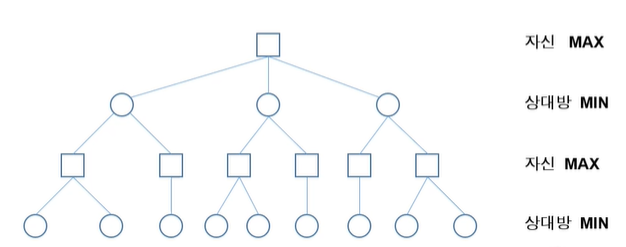
게임 트리(game tree)
- 상대가 있는 게임에서 자신과 상대방의 가능한 게임 상태를 나타낸 트리
- 게임의 결과는 마지막에 결정
- 많은 수(lookahead)를 볼 수록 유리
Mini-max 알고리즘
수치가 클수록 자신에게 유리해지고, 작을수록 상대방에게 유리해진다.
MAX 노드: 자신에 해당하는 노드로 자기에게 유리한 최대값 선택
MIN 노드: 상대방에 해당하는 노드로 최소값 선택
단말 노드부터 위로 올라가면서 최소(minimum)-최대(maximum) 연산을 반복하여 자신이 선택할 수 있는 방법 중 가장 좋은 값을 결정
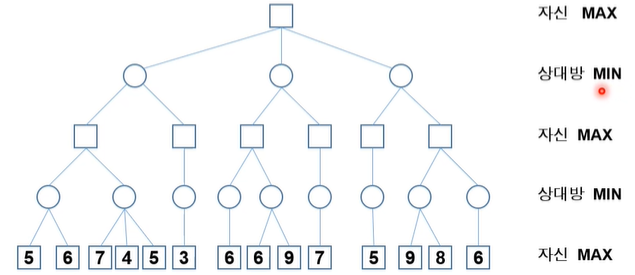
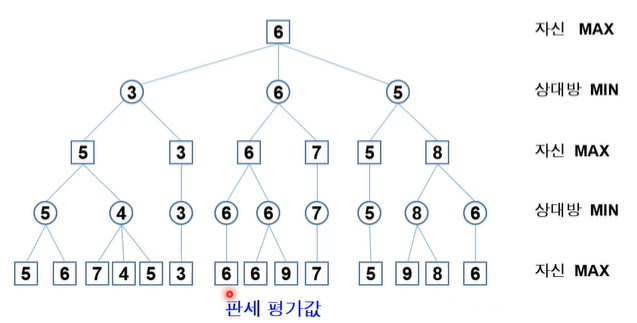
α-β 가지치기(prunning)
α : MAX 노드에 대해서 정의되는 값(탐색된 노드 중에서 제일 큰 자식 노드)
β : MIN 노드에 대해서 정의되는 값(탐색된 노드 중에서 제일 작은 자식 노드)
- 검토해 볼 필요가 없는 부분을 탐색하지 않도록 하는 기법
- 깊이 우선 탐색으로 제한 깊이까지 탐색을 하면서, MAX 노드와 MIN노드의 값을 결정
- 두가지의 컷오프(cut-off) 발생한다
α-자르기 : MIN 노드의 현재 값이 부모 노드의 현재 값보다 작거나 같으면, 나머지 자식 노드 탐색 중지
β-자르기 : MAX 노드의 현재값이 부모 노드의 현재 값보다 같거나 크면, 나머지 자식 노드 탐색 중지
몬테카를로 시뮬레이션(Monte Carlo Simulation)
특정 확률 분포로 부터 무작위 표본을 생성하고, 이 표본에 따라 행동하는 과정을 반복하여
결과를 확인하고 이러한 결과확인 과정을 반복하여 최종 결정을 하는 것
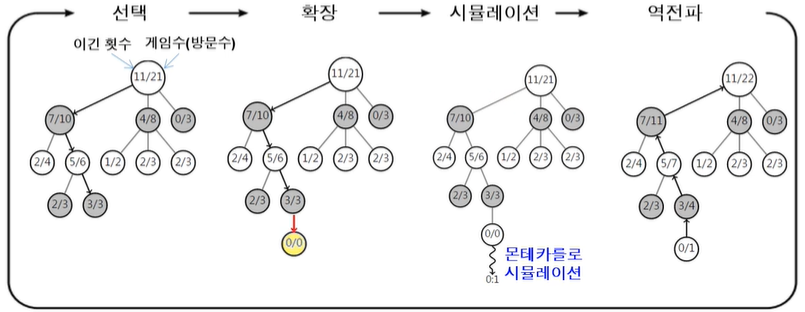
몬테카를로 트리 탐색(MCTS)
탐색 공간(search space)을 무작위 표본추출(random sampling)을 하면서,
탐색트리를 확장하여 가장 좋아 보이는 것을 선택하는 휴리스틱 탐색 방법
- 4개 단계를 반복하여 시간이 허용하는 동안 트리 확장 및 시뮬레이션
선택 -> 확장 -> 시뮬레이션(MCS) -> 역전파(back propagation) - 선택(selection) : 트리 정책(tree policy) 적용
- 루트노드에서 시작
- 정책에 따라 자식 노드를 선택하여 단말노드까지 내려 감
- 승률과 노드 방문횟수 고려하여 선택
- 많이 쓰이는 방법 : UCB(Upper Confidence Bound) 정책 : UCB가 큰 것 선택

- 확장(expansion)
- 단말노드에서 트리 정책에 따라 노드 추가
- ex. 일정 횟수이상 시도된 수(move)가 잇으면 해당 수에 대한 노드 추가
- 단말노드에서 트리 정책에 따라 노드 추가
- 시뮬레이션(simulation)
- 기본 정책(default policy)에 의한 몬테카를로 시뮬레이션 적용
- 무작위 선택(random moves) 또는 약간 똑똑한 방법으로 게임 끝날 때까지 진행
- 역전파(back propagation)
- 단말 노드에서 루트 노드까지 올라가면서 승점 반영
- 판의 형세판단을 위해 휴리스틱을 사용하는 대신, 가능한 많은 수의 몬테카를로 시뮬레이션 수행
- 일정 조건을 만족하는 부분은 트리로 구성하고, 나머지 부분은 몬테카를로 시뮬레이션
- 가능성이 높은 수(move)들에 대해서 노드를 생성하여 트리의 탐색 폭을 줄이고, 트리 깊이를 늘리지 않기 위해 몬테카를로 시뮬레이션을 적용
- 탐색 공간 축소
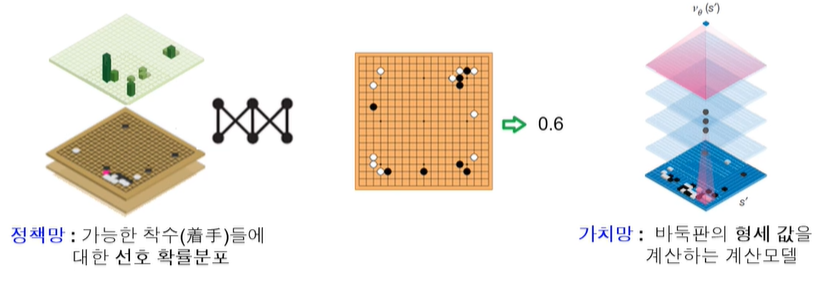
알파고의 몬테카를로 트리 검색
바둑판 형세 판단을 위한 한가지 방법으로 몬테카를 트리 검색 사용
무작위로 두는 것이 아니라, 프로 바둑기사들의 기보를 학습한 확장 정책망(rollout policy network)이라는 계산모델을 사용
확률에 따라 착수를 하여 몬테카를로 시뮬레이션을 반복하여 해당 바둑판에 대한 형세판단값 계산
별도로 학습된 딥러닝 신경망인 가치망(value network)을 사용하여 형세 판단값을 계산하여 함께 하용
개발자로 공부하며 느낀 여러가지 경험들