기존방식의 문제점
현재 메인 페이지에서 metadata를 보여주는 방식입니다.
-
클라이언트가 서버로 api를 보내, 특정 프로젝트 내에 존재하는 모든 metadata 정보를 요청합니다.
-
서버는 findByProjectId 메서드로 읽어들인 모든 metadata 리스트를 클라이언트에 제공합니다.
-
그후, 클라이언트 단에서 모든 metadata를 가지고 페이징 기능을 제공하는 상황입니다.
이러한 방식의 문제점은 프로젝트 내에서 메타데이터의 개수가 증가함에따라 한번에 읽어들이는 데이터의 크기가 점점 증가하여 최종적으로는 Read 연산의 효율을 떨어뜨리는 것입니다..😭
실제로 200만개의 메타데이터를 가지는 프로젝트의 정보를 모두 가져오는데 걸리는 시간을 테스트 코드를 통해 측정해 보았습니다.

잘 보이시나요?!
200만개의 데이터를 읽어들이는데, 48286ms 즉, 48초 정도 소요됨을 확인했습니다!
이러한 속도는 확실히 사용자가 서비스를 이용하는데 굉장히 불편한 요소가 될 수 있겠죠?!
자 그럼 해결방안에 대해 고민해 보겠습니다🧐🧐
해결방안
어차피 모든 데이터를 한번에 다 보여주는 것이 아니라면, 굳이 모든 데이터를 다 찾아 가져올 필요가 없다는 것이 핵심 아이디어 입니다!
즉 페이지 내에 존재하는 페이지 사이즈 만큼의 데이터만을 읽어 들인다면?
네! 기존의 방식 대비 굉장히 효율적이게 데이터를 읽을수있습니다!
실제로 이 기능은 이미 스프링부트에서 Page, Pageable 인터페이스로 다양한 페이징 관련 기능이 제공되고 있습니다.👍👍


공식문서를 통해 확인하세요
https://docs.spring.io/spring-data/commons/docs/current/api/org/springframework/data/domain/Page.html
https://docs.spring.io/spring-data/commons/docs/current/api/org/springframework/data/domain/Pageable.html
네 이제 공식문서를 통해 개별적인 학습이 끝났다면, 실제 코드를 작성해야겠죠!?
import org.springframework.data.mongodb.core.query.Query;
위의 MongoDB Query 객체를 통해 페이징 기능을 직접 사용해 볼 수 있습니다.
@Override
public Page<MetaData> findByProjectIdWithPagingAndFiltering(String projectId,int page, int size, HashMap parmMap) {
Pageable pageable = PageRequest.of(page,size, Sort.unsorted());
Query query = new Query()
.with(pageable)
.skip(pageable.getPageSize() * pageable.getPageNumber()) // offset
.limit(pageable.getPageSize());
//Add Filtered
query.addCriteria(Criteria.where("projectId").is(projectId));
List<MetaData> filteredMetaData = mongoTemplate.find(query, MetaData.class, "metadata");
Page<MetaData> metaDataPage = PageableExecutionUtils.getPage(
filteredMetaData,
pageable,
() -> mongoTemplate.count(query.skip(-1).limit(-1),MetaData.class)
// query.skip(-1).limit(-1)의 이유는 현재 쿼리가 페이징 하려고 하는 offset 까지만 보기에 이를 맨 처음부터 끝까지로 set 해줘 정확한 도큐먼트 개수를 구한다.
);
return metaDataPage;
}Query 객체에서는, page객체의 page 사이즈 및 page 번호를 참조하여 특정 section외에는 skip하여 빠르게 section을 찾아갈 수 있습니다.
그 후 Query 조건을 추가하여, MongoTemplate의 find 함수를 통해 'filteredMetaData'의 리스트를 가져올 수 있습니다.
최종적으로 Page 객체에 content에 filteredMetaData를 그리고 pageable 정보,도큐먼트 count 정보를 Page 객체에 넣어 줍니다!
결과를 API TESTER로 확인하면, 아래와 같습니다😏

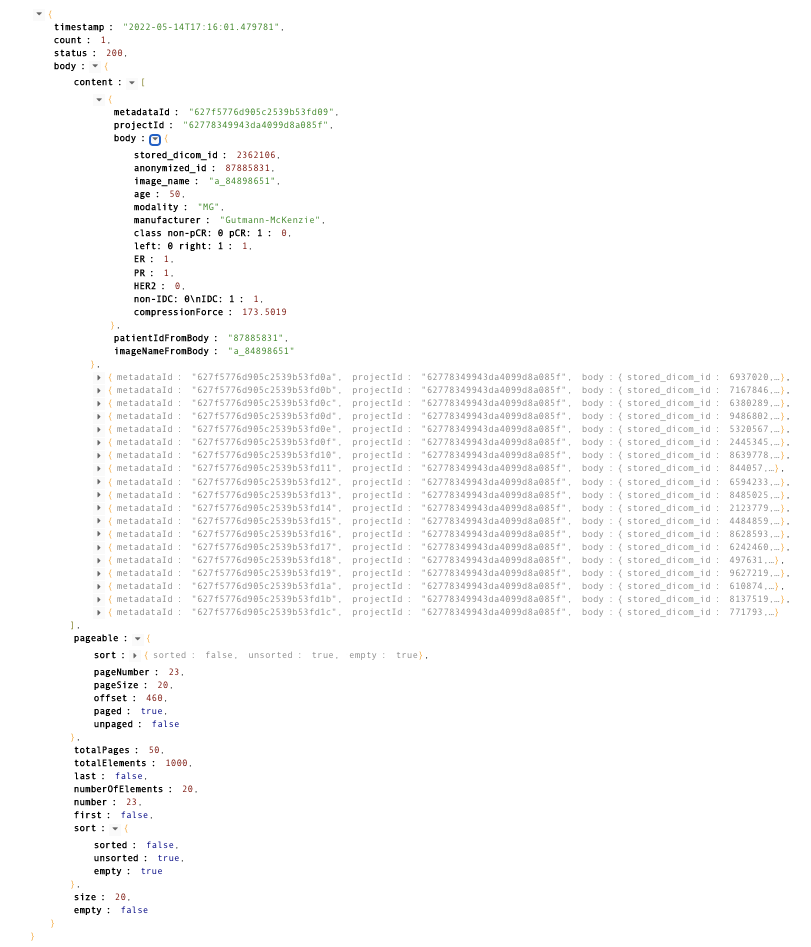
- body 내부 값이 Page 객체 정보입니다
결론

결론적으로, page size가 20개일때(default size로 20을 설정하였기 때문에 ㅎㅎ), 48초 가량 걸리던 페이지 로딩 시간을 2초 내로 끝낼 수 있었습니다.
페이지 로딩 시간만 봤을 때, 메인 페이지 로딩 속도가 2300% 개선됨을 확인했습니다 😅😅😅 기존의 방식이 얼마나 말도 안되는 방식이었음 알게되었네요 ㅎㅎ..
(튜닝 전 응답 속도 – 튜닝 후 응답 속도) x 100 / 튜닝 후 응답 속도 = 개선율(%)
흠..추가적으로 아마 ProjectId로 indexing을 정해준다면 좀 더 빠르게 읽어 들일 수 있을 듯합니다!
하지만 indexing은 읽기의 효율은 높아지지만, 삽입 및 업데이트시 indexing을 유지하기 위한 overhead가 발생하기 때문에 이에 대한 절충안은 추후 성능 검사를 통해 결정을 해야할 듯 합니다!
