
배운 것
머신러닝?
인공지능의 연구 분야 중 하나로, 인간의 학습 능력과 같은 기능을 컴퓨터에서 실현하고자 하는 기술 및 기법이다.
[출처] 두산백과 doopedia
학습 방법에 따른 분류
- 지도학습: 학습 대상이 되는 데이터에 정답을 주어, 규칙성, 즉 데이터의 패턴을 배우게 하는 학습 방법
- 비지도 학습: 정답이 없는 데이터 만으로 배우게 하는 학습 방법
- 강화 학습: 선택한 결과에 대해 보상을 받아 행동을 개선하면서 배우게 하는 학습 방법
과제에 따른 분류
-
분류 문제 (Classification) : 이미 적절히 분류된 데이터를 학습하여 분류 규칙을 찾고, 그 규칙을 기반으로 새롭게 주어진 데이터를 적절히 분류하는 것을 목적으로 함(지도 학습)
-
회귀 문제 (Regression) : 이미 결과값이 있는 데이터를 학습하여 입력 값과 결과 값의
연관성을 찾고, 그 연관성을 기반으로 새롭게 주어진 데이터에 대한 값을 예측하는 것을 목적으로 함(지도 학습) -
클러스터링 (Clustering) :주어진 데이터를 학습하여 적절한 분류 규칙을 찾아 데이터를
분류함을 목적으로 함. 정답이 없으니 성능을 평가 하기 어려움 (비지도 학습)
이번 학습 에서 우리는 분류와 회귀만 다룬다!!
결과가 범주형인지 연속형인지에 따라서 분류와 회귀로 구분한다
- 회귀: 연속적인 숫자를 예측
- 연속적인 숫자 확인 방법
• 두 값 사이에 중간값이 의미가 있는 숫자인지
• 또는 두 값에 대한 연산 결과가 의미가 있는 숫자인지 등등
데이터의 분리
- 데이터 셋을 학습용, 검증용, 평가용 데이터로 분리 함
과대 적합 , 과소 적합
- 과대적합(Overfitting)
• 학습 데이터에서 점수가 매우 높았는데, 평가 데이터에서 점수가 매우 낮은 경우
• 학습 데이터에 대해서만 잘 맞는 모델 → 실전에서 예측 성능이 좋지 않음 - 과소적합(Underfitting)
• 학습 데이터보다 평가 데이터 점수가 더 높거나 두 점수 모두 너무 낮은 경우
• 모델이 너무 단순하여 학습 데이터에 적절히 훈련되지 않은 경우
EX)
학습 데이터를 너무 많이 공부시켜 실전에선 성능이 좋지 않음 : 과대 적합
학습 데이터가 너무 적어 공부량이 부족 : 과소 적합
모델링 코드 구조
- 불러오기: 사용할 라이브러리를 import
- 선언하기: 사용할 알고리즘을 모델로 선언
- 학습하기: 모델.fit(x_train,y_train) 형태로 학습 시키기
- 예측하기: 모델.predict(x_test) 형태로 예측 값 만들기
- 평가하기: 예측 값과 실제 값으로 평가
분류 모델 평가, 회귀 모델 평가
- 분류 모델 평가( 정확도를 높여라!!!! )
분류 모델은 0인지 1인지를 예측하는 것
실젯값도 0과 1이고 예측값도 0과 1임
하지만 0을 1로 예측하거나 1을 0으로 예측할 수 있음
예측값이 실젯값과 많이 같을 수록 좋은 모델이라 할 수 있음
→ 정확히 예측한 비율로 모델 성능을 평가 - 회귀 모델 평가( 오차를 줄여라!!)
회귀 모델이 정확한 값을 예측하기는 사실상 어려움
예측값과 실젯값에 차이(=오차)가 존재할 것이라 예상함
예측값이 실젯값에 가까울 수록 좋은 모델이라 할 수 있음
→ 예측값과 실젯값의 차이(=오차)로 모델 성능을 평가
알아 둘 기호
실제값:
– 우리가 실제로 예측하고 싶은 값, 목푯값
– 이 값과 비교해 머신러닝 알고리즘 성능을 평가할 것임
– 우리가 관심을 갖는 오차는 이 값과 예측값의 차이
예측값:
– 머신러닝 알고리즘으로 우리가 새롭게 예측한 값
– 이 예측값이 얼마나 정확한지 알고 싶은 상황
– 최소한, 아무리 못해도 평균값 보다는 좋아야 할 것임
– 평균값보다 얼마나 잘 예측했는지 궁금
평균값:
– 이미 알고 있는, 기존에 예측한 값
– 최소한 이 평균값 보다는 실젯값에 가까운 예측값을 원함
– 우리 예측값이 평균값보다 오차를 얼마나 더 줄였는지 궁금
정확도
정분류율 이라고 부르기도 함
전체 중에서 Positive와 Negative 로 정확히 예측한(TN + TP) 비율
Negative를 Negative로 예측한 경우도 옳은 예측임을 고려하는 평가 지표
가장 직관적으로 모델 성능을 확인할 수 있는 평가 지표
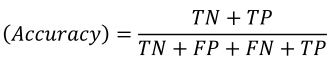
정밀도
Positive로 예측한 것(FP + TP) 중에서 실제 Positive(TP)인 비율
예) 비가 내릴 것으로 예측한 날 중에서 실제 비가 내린 날의 비율
예) 암이라 예측한 환자 중에서 실제 암인 환자의 비율
• 정밀도가 낮을 경우 발생하는 상황
비가 오지 않는데 비가 온다고 했으니 불필요한 우산을 챙기는 수고 발생
암이 아닌데 암이라 했으니 불필요한 치료 발생
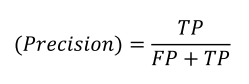
재현율
실제 Positive(FN + TP) 중에서 Positive로 예측한(TP) 비율
민감도(Sensitivity)라고 부르는 경우가 많음
예) 실제 비가 내린 날 중에서 비가 내릴 것으로 예측한 날의 비율
예) 실제 암인 환자 중에서 암이라고 예측한 환자의 비율
• 재현율이 낮을 경우 발생하는 문제
비가 내리는 날 내리지 않을 것이라 했으니 우산을 챙
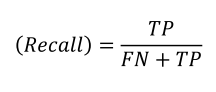
특이도
실제 Negative(TN + FP) 중에서 Negative로 예측한(TN) 비율
예) 실제 비가 내리지 않은 날 중에서 비가 내리지 않을 것으로 예측한 날의 비율
예) 실제 암이 아닌 환자 중에서 암이 아니라고 예측한 환자의 비율
• 특이도가 낮을 경우 발생하는 문제
비가 오지 않는데 비가 온다고 했으니 불필요한 우산을 챙기는 수고 발생
암이 아닌데 암이라 했으니 불필요한 치료 발생
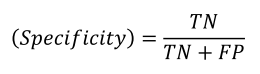
학습 소감
머신러닝을 오랜 시간동안 하고 공부할게 많다보니 너무 힘들었따.. 어렵고.. 그래도 장래강사님설명을 조금씩 따라가다 보니 이해가 조금씩 되기 시작했다:) 그리고 미니프로젝트를 조원들과 수행하고 서로 모르는 것을 묻고 하다보니 더 잘 이해가 되었다!!! 아직 개념 공부는 혼자서 조금 해야할 것 같다!! 화이팅
마지막은 조원들이랑 미프때 먹은 밥 사진 !! :)
