2-1. 0과 1로 숫자를 표현하는 방법
1. 정보 단위
- 비트 : 0과 1을 나타내는 가장 작은 정보 단위
- 바이트(byte) : 8비트, 비트보다 한 단계 큰 단위
- 1 킬로바이트(KB) : 1바이트 1,000개 묶은 단위
- 1 메가바이트(MB) : 1킬로바이트 1,000개 묶은 단위
- 1 기가바이트(GB) : 1메가바이트 1,000개 묶은 단위
- 1 테라바이트(TB) : 1기가바이트 1,000개 묶은 단위
2. 이진법
- 이진법 : 0과 1만으로 모든 숫자를 표현하는 방법
- 십진법 : 우리가 일상적으로 사용하는 방법
- 구별하는 방법 : 이진수 끝에 아래첨자 (2)를 붙이거나 이진수 앞에 0b를 붙임
+) 이진수의 음수 표현
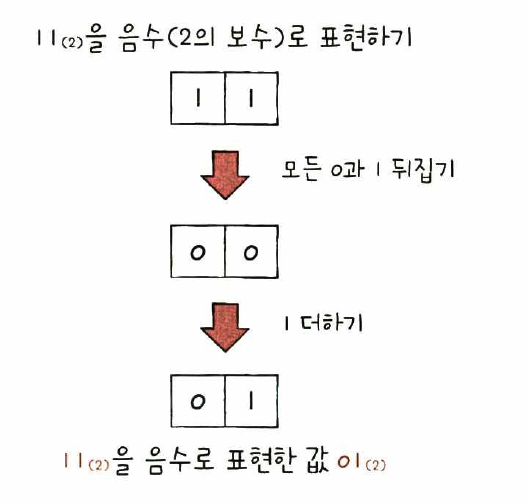
- 2의 보수(어떤 수를 구보다 큰 2^n에서 뺀 값)를 구해 이 값을 음수로 간주
- 11(2)의 보수 : 01(2)
- 2의 보수를 쉽게 표현 : 모든 0과 1을 뒤집고, 거기에 1을 더한 값
- 11(2) > 00(2) > 01(2)
- 컴퓨터 내부에서 어떤 수를 다룰 때 양수, 음수를 구별하기 위해 플래그 사용
3. 십육진법

-
십육진법 : 수가 15를 넘어가는 시점에 자리 올림을 하는 표현 방식
-
10부터 A, B, C, D, E, F(15)로 표현
-
구별 : 아래첨자(16)을 붙이거나(수학적) 숫자 앞에 0x를 붙여(코드상) 구분
-
십육진수를 이진수로 변환하기
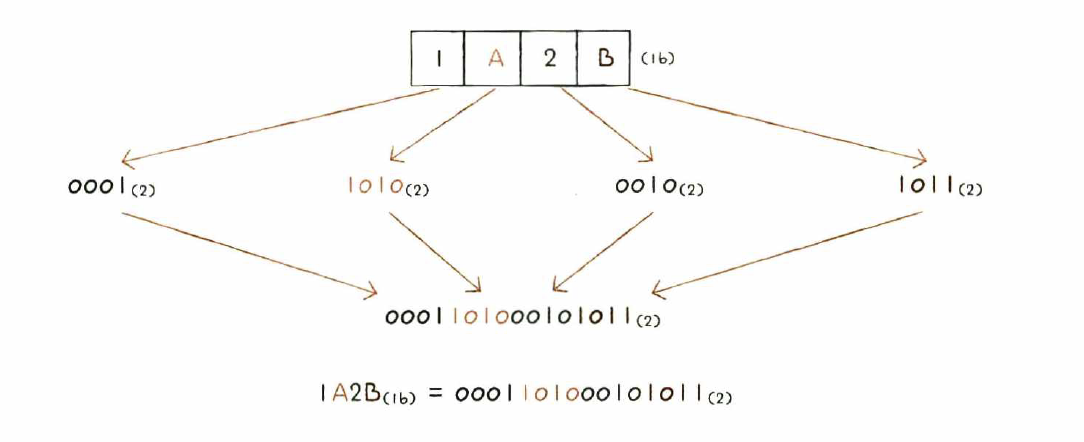
- 십육진수 한 글자를 4비트의 이진수로 간주
- 각 글자를 따로따로 이진수로 변환하고 이어 붙이기
-
이진수를 십육진수로 변환하기
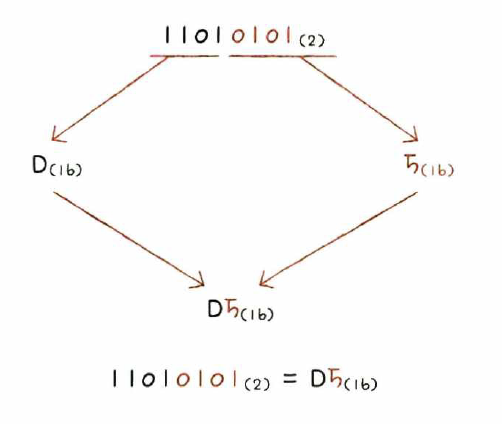
- 이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환하여 이어 붙이기
기본 과제 p.65 3번
Q. 1101(2)의 음수를 2의 보수 표현법으로 구해 보세요.
A. 1101 > 0010 > 0011(2)
- 이진수 숫자를 네 개씩 끊고, 끊어 준 네 개의 숫자를 하나의 십육진수로 변환하여 이어 붙이기
/
2-2. 0과 1로 문자를 표현하는 방법
1. 문자 집합과 인코딩
- 문자 집합 : 컴퓨터가 인식하고 표현할 수 있는 문자 모음
- 컴퓨터는 문자 집합에 속해 있는 문자 이해 할 수 있음
- 문자 집합에 속해 있지 않은 문자는 이해 불가
- 문자 인코딩 : 문자를 0과 1로 변환하는 과정
- 문자 디코딩 : 0과 1로 이루어진 문자 코드를 사람이 이해할 수 있는 문자로 변환하는 과정
2. 아스키 코드
-
아스키 : 초창기 문자 집합 중 하나. 영어, 아라비아 숫자, 일부 특수 문자를 포함. 아스키 문자 집합에 속한 문자들은 각각 7비트로 표현되어 총 128개 문자를 표현할 수 있음
-
아스키 코드표
-
아스키 코드 : 아스키 문자에 대응된 고유한 수
- 아스키 코드를 이진수로 표현함으로써 아스키 문자를 0과 1로 표현 가능
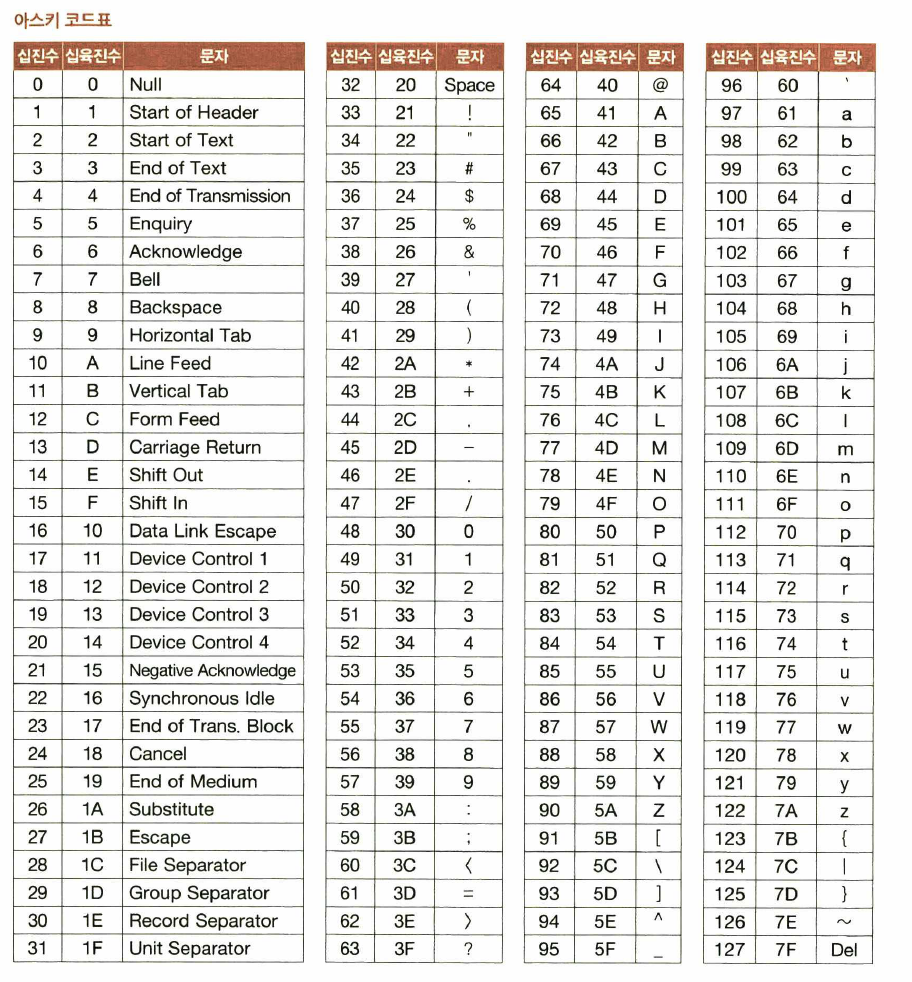
- 아스키 코드를 이진수로 표현함으로써 아스키 문자를 0과 1로 표현 가능
-
확장 아스키 : 아스키 코드에 1비트를 추가한 8비트
3. EUC-KR
-
한글 인코딩 방식
-
KS X 1001, KS X 1003이라는 문자 집합을 기반으로 하는 대표적인 완성형 인코딩 방식. EUC-KR 인코딩은 초성, 중성, 종성이 모두 결합된 한글 단어에 2바이트 크기의 코드를 부여
-
완성형(한글 완성형 인코딩) : 초성, 중성, 종성의 조합으로 이루어진 완성된 하나의 글자에 고유한 코드를 부여하는 방식
- ex) '가'는 1, '나'는 2, '다'는 3
-
조합형(한글 조합형 인코딩) : 초성, 중성, 종성을 위한 비트열을 할당해 그것들의 조합으로 하나의 글자 코드를 완성하는 인코딩 방식. 각 성에 해당하는 코드를 합해 하나의 글자 코드를 만드는 인코딩 방식.
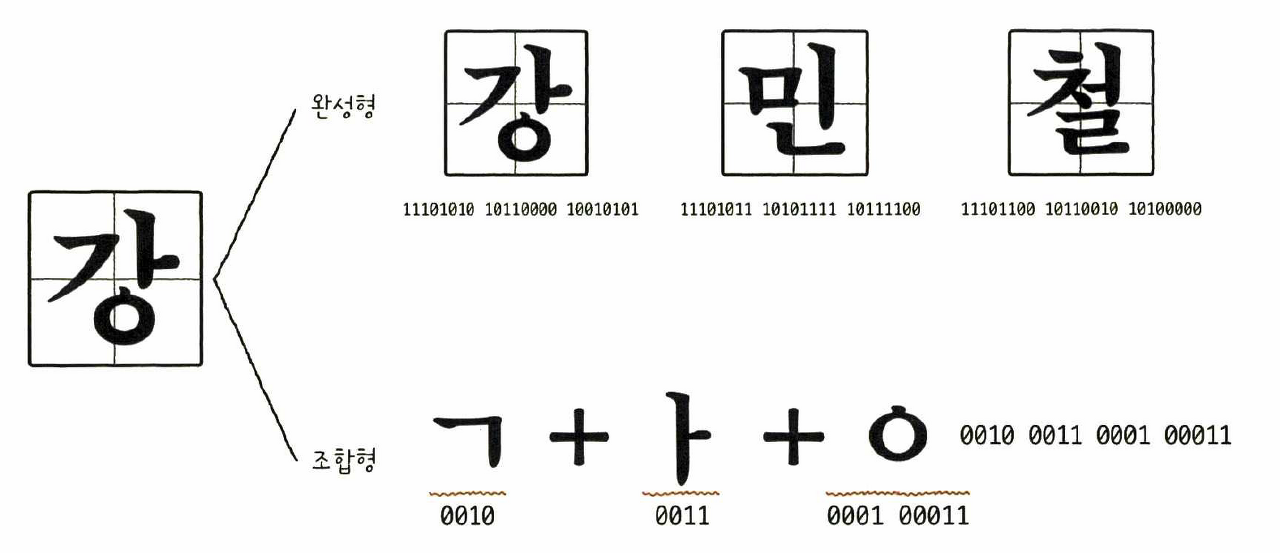
-
문제점 : 모든 한글을 표현할 수 없다는 것. 문자 집합에 정의되지 않은 쀍, 쀓, 믜 표현 불가.
-
해결 방안 : CP949(EUC-KR의 확장 버전, 하지만 한글 전체를 표현하기에 넉넉하진 않음)
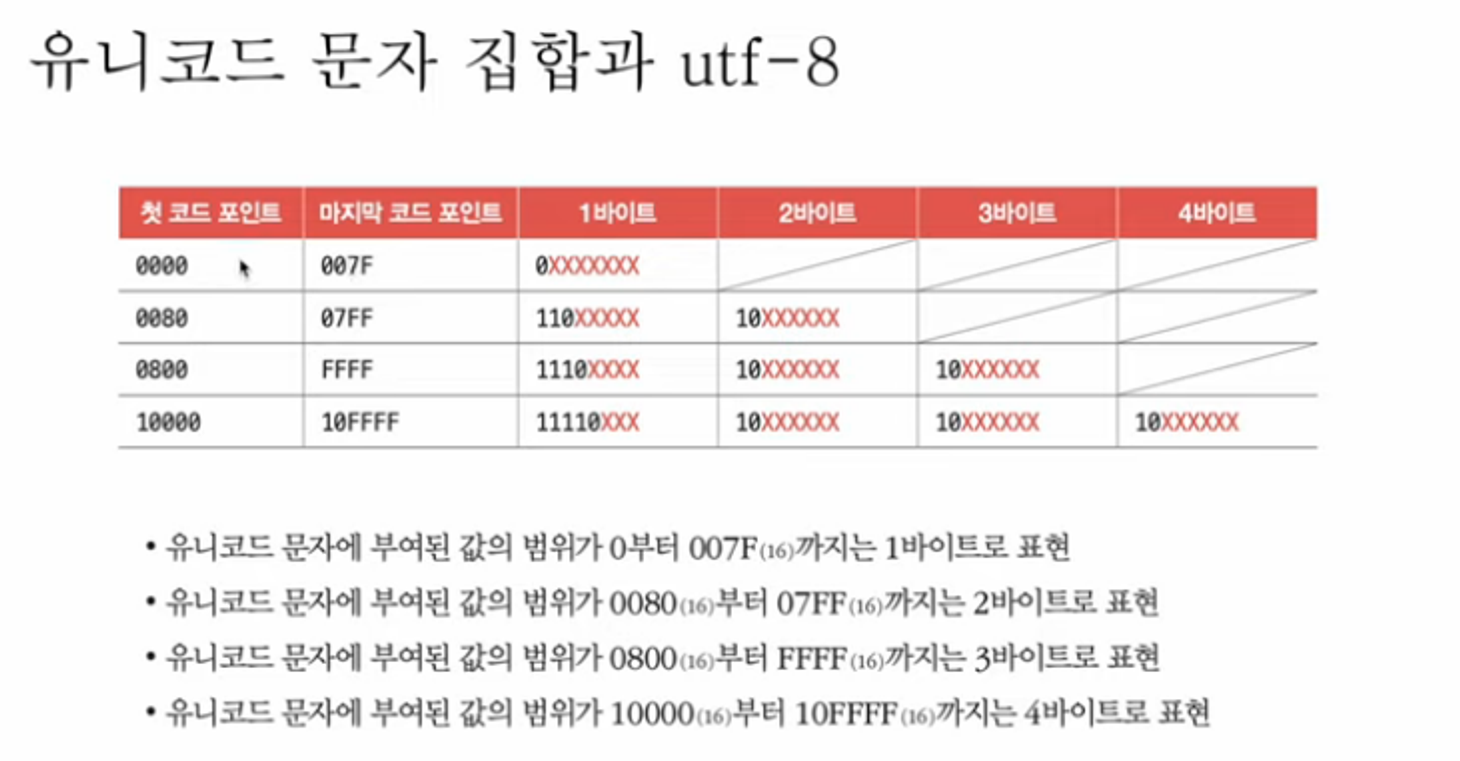
4. 유니코드와 UTF-8
-
유니코드 문자 집합 : EUC-KR보다 훨씬 다양한 한글을 포함해 대부분 나라의 문자, 특수문자, 이모티콘까지도 코드로 표현 가능한 통일된 문자 집합
-
사용 방식 : 글자에 부여된 값 자체를 인코딩된 값으로 삼지 않고 이 값을 다양한 방법으로 인코딩 함. 이런 방식에는 크게 UTF-8, -16, -32 등이 있음. 이는 유니코드 문자에 부여된 값을 인코딩하는 방식
-
UTF-8
- 1바이트부터 4바이트까지의 인코딩 결과를 만들어 냄
- UTF-8로 인코딩한 갑스이 결과는 1바이트가 될수도 2, 3, 4바이트가 될 수도 있음