
싸피의 특화 프로젝트를 진행하며 뉴스 기사를 조회할 일이 생겼다.
2023년 180만 건의 뉴스 기사 데이터를 가지고 있었는데 이것을 DB에 적재하고, 필요할 때 조회하는 방식으로 사용할 계획이었다.
처음에는, 이전 프로젝트에서 사용했던 RDB인 MySQL에 뉴스 데이터를 저장하려했지만 2가지의 고민을 하게 되었다.
- "Read"만을 위한 데이터
CRUD 중 Read만 하는 데이터를 굳이 관계형 데이터베이스에 저장할 필요가 있을까?- 일관적이지 않는 형식
A 기사는 5개의 필드를 가지고, B 기사는 6개의 필드를 가지는 일관적이지 않은 형식의 데이터는 어떤 데이터베이스가 어울릴까?
이러한 고민을 바탕으로 새롭게 NoSQL인 MongoDB를 사용하기로 했다.
MongoDB를 사용한 이유는 다음과 같다.
- JSON 형식으로 데이터를 저장하기 때문에 일관되지 않는 데이터도 쉽게 저장하고 관리할 수 있다.
- 읽기 작업에 최적화된 기능을 제공한다.
이를 고려하여 MongoDB를 사용하였고, FastAPI에서 특정 일자의 뉴스 기사를 불러오게 하였다.
문제발생
180만 건의 뉴스기사 중 딱 1년 전 데이터를 불러오는데 생각보다 시간이 오래 걸렸다.


위의 그림은 쿼리를 실행하고 FastAPI 서버까지 데이터를 가져오는데 걸리는 시간을 측정한 것이다.
7144개를 가져오는데 3.6초가 걸렸고, 1520개 정도만을 가져오는데도 2초가 걸렸다.
우리의 서비스는 첫 번째로 뉴스 기사를 조회, 두 번째로 키워드를 추출하여 화면에 뿌려줘야 하기에, 최대한 빠르게 처리해야 했다.
TF-IDF Tokenizer를 통해 키워드를 뽑는 작업을 진행하는데, 라이브러리를 가져다 쓴 것 이므로 이 작업의 시간을 줄이긴 힘들겠다고 판단하여 조회 속도의 개선에 집중하였다.
MongoDB는 index 기능이 매우 잘 되어있으므로 이를 적용해보고자 하였다.
index 걸기
기사 데이터는 모두 published 라는 필드를 가진다.

시간이 오래걸렸던 쿼리의 조회 기준인 published(기사 출간일)에 오름차순으로 단일 필드 인덱스를 생성했다.
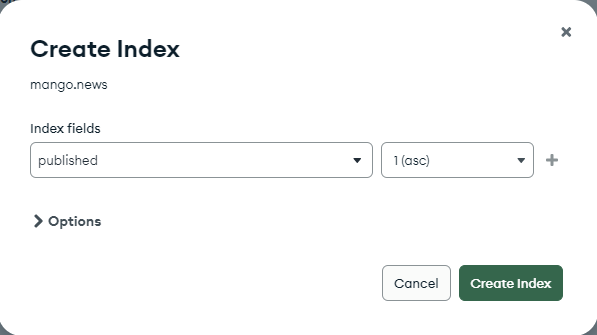
단일 필드 인덱스에서는 오름차순, 내림차순 어디를 기준으로해도 똑같으므로 오름차순으로 걸었다.
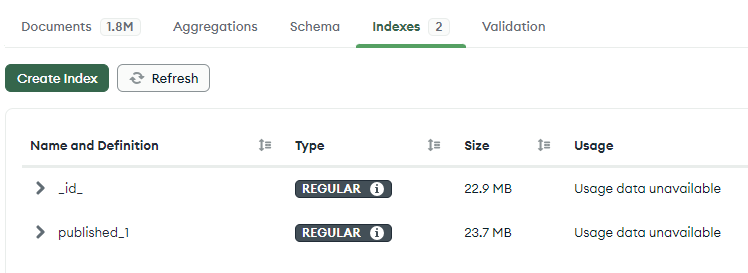
식별자인 _id 외의 published_1의 이름으로 인덱스가 생성되었다.
published에 인덱스를 적용시킨 후, 다시 조회 쿼리를 실행하고 시간을 측정해 보았다.
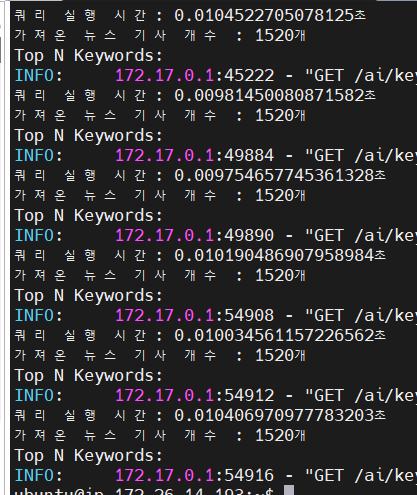
2초가 걸렸던 쿼리 실행시간이 0.01초로 줄어든 것을 확인할 수 있었다.
성능이 너무나 향상되었는데, 어떻게 이게 가능할까?
공식문서에 따르면 MongoDB의 index는 B-tree 방식을 사용한다고 한다.

B-Tree 란?
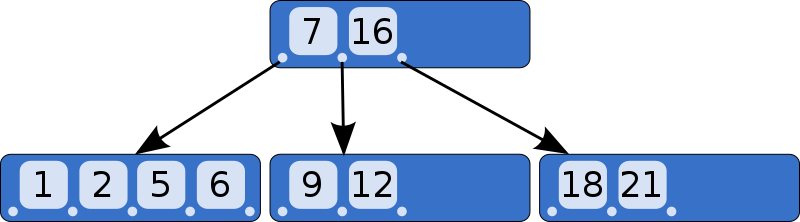
- B-Tree는 이진 트리를 확장해 하나의 노드가 가질 수 있는 자식 노드의 최대 숫자가 2보다 큰 트리구조.
- 부모 노드 데이터를 기준으로 작은 값들을 왼쪽 서브 트리에, 큰 값들은 오른쪽 서브 트리에 저장한다.
- 탐색에 O(logN)의 시간 복잡도를 가진다.
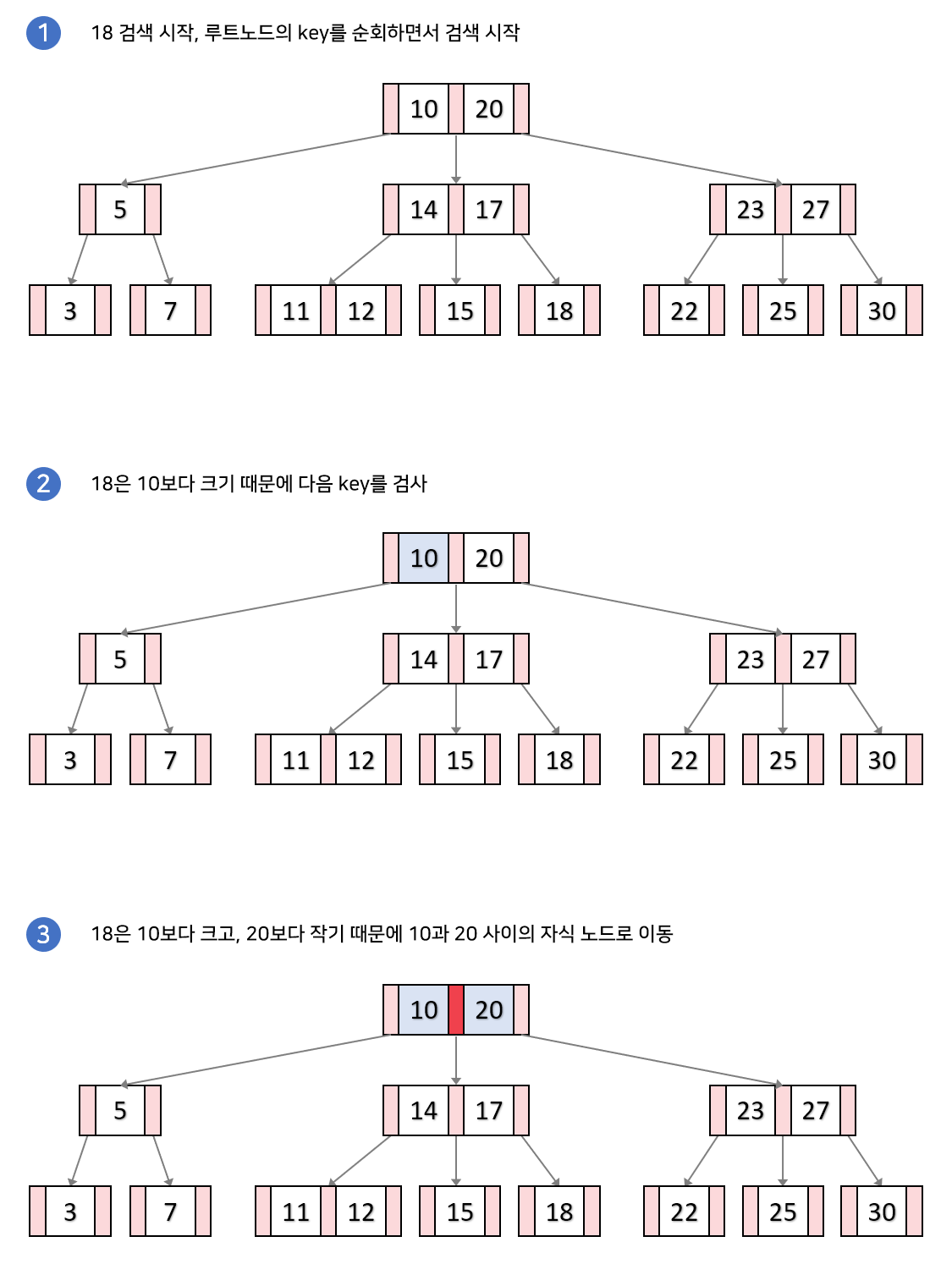
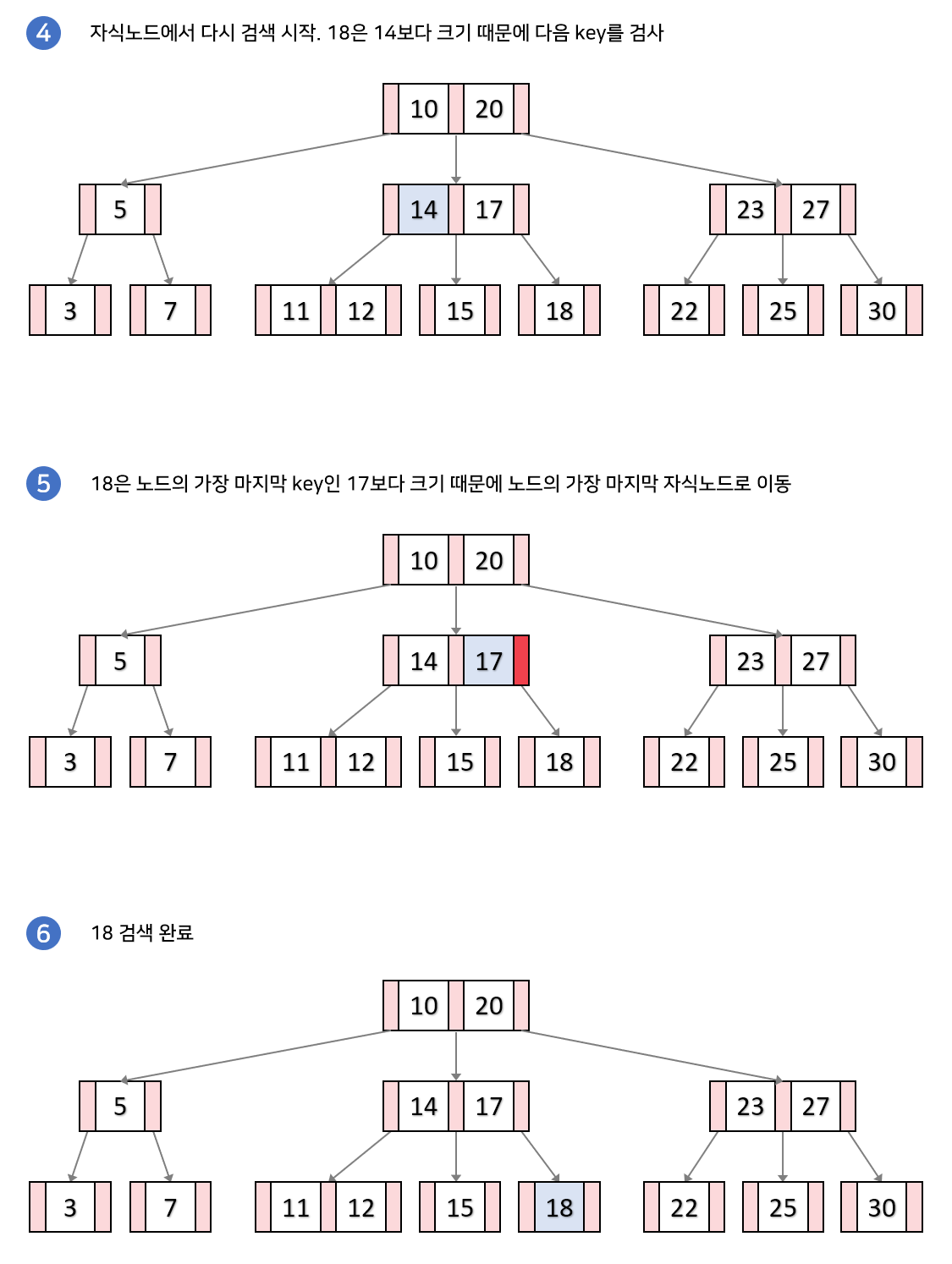
탐색과정
B-Tree는 루트 노드에서부터 하향식으로 탐색을 수행하게 된다.
- 루트 노드에서 시작하여 key들을 순회하면서 검사한다.
1-1. 만일 k(18)와 같은 key를 찾았다면 검색을 종료한다.
1-2. 검색하는 값과 key들의 대소관계를 비교한다. 어떠한 key들 사이에 k가 들어간다면 해당 key들 사이의 자식노드로 내려간다.
해당 과정을 리프노드에 도달할 때까지 반복하는데, 만약 리프노드에도 k와 같은 key가 없다면 검색을 실패하게된다.
마무리
처음으로 DB의 index 기능을 사용해서 조회 성능을 향상할 수 있었다.
다음엔, NoSQL이 아닌 RDB에서도 index 기능을 사용해서 조회 속도를 개선해보자.
참고
