
본 글은 Computer Networking: a Top Down Approach의 HTTP 1.0/1.1 챕터를 정리한 글입니다.
🟢 개요
-
HTTP(HyperText Transfer Protocol)는 웹 애플리케이션의 심장과도 같은 역할을 한다. -
HTTP는 클라이언트 프로그램과 서버 프로그램에서 사용된다. -
서로 다른 엔드 시스템끼리도
HTTP메시지를 통해 대화할 수 있다. -
HTTP는 이 메시지의 구조와, 클라이언트와 서버가 어떻게 메시지를 주고 받아야 하는지를 정의한다. -
Web Page
-
웹페이지는 다양한 객체로 구성된다. 객체란, 간단히 말해 파일이다. (HTML 파일, JPEG 이미지, JS 파일, CSS 스타일 시트 파일, 비디오 영상 등의 URL로 표현 가능한 것)
-
대부분의 웹페이지는 base HTML 파일과 몇몇 참조된 객체를 가진다.
-
예시로, 어떤 웹페이지가 HTML text와 5개의 이미지를 가진다면, 그 웹페이지는 6개의 객체를 가지는 것이다. 그리고 HTML text는 5개의 이미지의 URL을 참조한다.
-
🟢 HTTP 통신
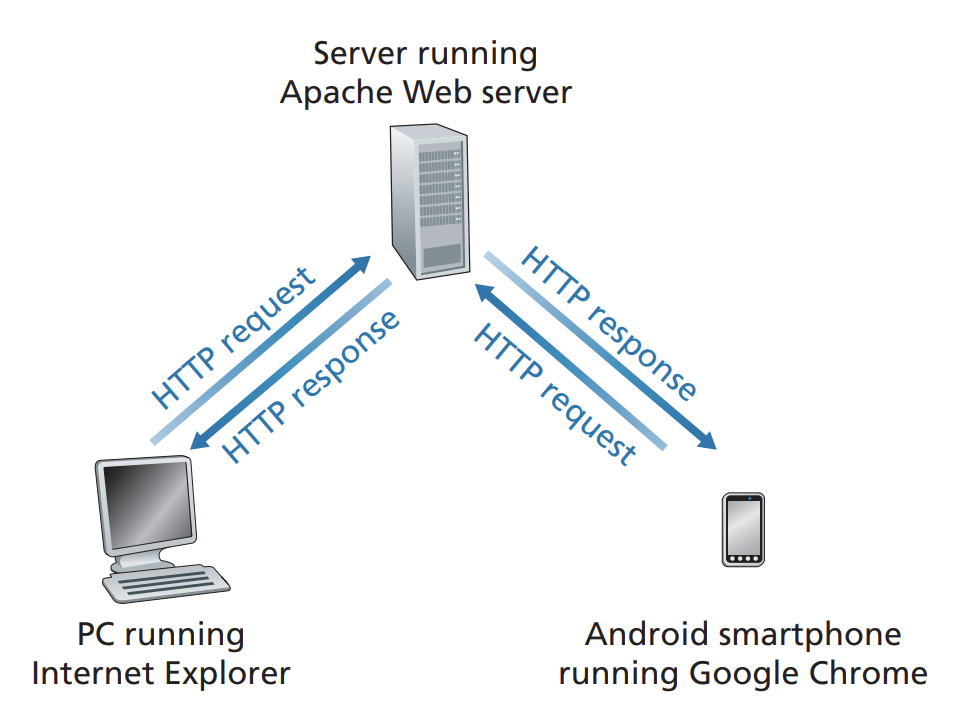
-
사용자가 웹페이지를 요청(하이퍼링크를 클릭하는 등)하면 브라우저는 해당 웹페이지의 객체를 얻기 위해 HTTP request 메시지를 서버에게 전송한다.
-
HTTP는 전송 프로토콜로TCP를 사용한다. -
HTTP클라이언트(브라우저)는 우선 서버와TCP연결을 구성한다. -
연결이 구성되면, 클라이언트-서버는 서로 소켓을 통해
TCP연결에 접속한다. 소켓에게HTTPrequest 메시지를 전달하고, 소켓으로부터HTTPresponse 메시지를 수신한다. -
TCP는 신뢰성을 보장하기 때문에,HTTPrequest 및 response 메시지는 온전하게 클라이언트/서버에게 도착한다는 것을 알 수 있다. 여기서 계층화된 아키텍처의 장점을 알 수 있을 것이다,TCP덕분에HTTP가 데이터 손실에 대해 걱정할 필요가 없어진다. -
서버가 클라이언트에 대한 상태 정보를 저장하지 않고, 요청 파일에 응답하는 것에 주의하자. 특정 클라이언트가 몇 초 동안 동일 객체를 중복 요청하는 경우, 서버는 중복 요청된 객체를 또 다시 전송한다. HTTP 서버는 클라이언트에 대한 정보를 유지하지 않기 때문에 Stateless 프로토콜이라고도 한다.
🟡 Non-Persistent and Persistent Connections
-
수많은 인터넷 애플리케이션의 클라이언트와 서버는 긴 시간 통신하고, 요청과 응답이 반복된다.
-
앱의 사용 방식에 따라 요청은 연속적이거나, 주기적이거나, 간헐적으로 이루어진다.
-
이럴 때 클라이언트-서버의 상호 작용이 TCP를 통해 이루어진다면, 앱 개발자는 각 요청/응답을 별도의 TCP 연결을 통해 전송할 것인지(비영구 연결), 동일한 TCP 연결로 전송할 것인지(영구 연결) 결정해야 한다.
🟠 예시: HTTP with Non-Persistent Connections
- 비영구 연결의 예시를 확인해보자.
-
HTTP 클라이언트가 포트 넘버 80(기본 넘버)으로 서버에
TCP연결을 생성한다. 그럼 클라이언트와 서버에 각각 소켓이 생성된다. -
HTTP 클라이언트는 HTTP request 메시지를 소켓을 통해 서버에게 보낸다. (메시지에는
/home.index와 같은 경로 정보가 포함된다.) -
HTTP 서버는 소켓을 통해 request 메시지를 받고, 저장소에 있는
/home.index객체를 HTTP response 메시지에 캡슐화하여 소켓을 통해 응답한다. -
HTTP 서버는
TCP에게TCP연결을 종료하라고 알린다. (물론TCP는 클라이언트가 응답을 받았다는 것을 확인하기 까지는 연결을 종료하지 않는다.) -
HTTP 클라이언트는 응답 메시지를 받고,
TCP연결은 끊어진다. 메시지는 캡슐화된 객체가 HTML 파일임을 알리고, 클라이언트가 해당 파일을 메시지에서 추출해낸다. 그리고 HTML 파일이 10개의 JPEG 파일을 참조하고 있음을 인식한다. -
JPEG 객체를 위해 1번부터 4번까지의 과정을 다시 반복한다.
-
서로 다른 두 브라우저는 웹페이지를 다른 방식으로 해석할 수 있다.
HTTP는 웹페이지가 클라이언트에 의해 어떻게 해석되던지 아무런 영향을 끼치지 않는다. 오직 클라이언트-서버 간의 소통 방식만 정의할 뿐이다. -
위와 같은 비영구 연결의 예시는
HTTP 1.0의TCP연결 방식이었다. 즉, 하나의TCP연결에 하나의 request와 하나의 response 만이 존재했다. -
이런 방식에서는 연결을 병렬 처리한다면 응답 시간이 단축될 것이다.
-
이제
RTT를 고려해보자.RTT란, 클라이언트가 요청을 보내고 응답을 받기까지의 시간을 의미한다. -
TCP연결에는 3-way handshake 과정이 포함된다.-
클라이언트가 서버에게
TCP세그먼트를 전송하고, 서버는 그에 대한 응답을 보낸다. 이것이 하나의RTT를 이룬다. -
첫
RTT를 소모하고, 클라이언트가 승인 정보와 함께 HTTP request 메시지를TCP연결을 통해 송신한다. -
그것이 서버에 도착하면 서버는 HTML 파일을
TCP연결로 보내고, 여기까지가 두번째RTT를 이룬다. -
즉, 대략적으로 본 총 시간은 두 개의
RTT+HTML파일의 서버 전송시간이다.
-
🟠 HTTP with Persistent Connections
-
비영구 연결의 단점에 대해서 생각해보자.
-
요청된 객체마다 새로운 연결을 설정하고,
TCP버퍼를 할당해야 한다. 이것은 서버에게 굉장한 부담이 된다. -
객체마다 새로운 연결을 설정하면 총 두 번의
RTT가 발생한다. 이것은 전송 딜레이의 원인이 된다.
-
-
그래서
HTTP 1.1는 영구 연결 방식으로 서버가 response를 보내도 연결이 제거되지 않는다. (keep-alive) -
위의 예시에 바로 적용하면, HTML 파일과 10개의 이미지를 단 하나의
TCP연결로 주고 받게 된다. -
일반적으로
HTTP서버는 일정 시간동안 request를 받지 않으면TCP연결을 제거한다.
🟡 HTTP Message 형식
🟠 HTTP Request 메시지
GET /somedir/page.html HTTP/1.1 # 메서드, URL, 버전
Host: www.someschool.edu # 웹 프록시 캐시를 위해 필요함
Connection: close # 객체 전송 후에 지속적인 연결이 필요 없음을 의미
User-agent: Mozilla/5.0 # 클라이언트의 유형
Accept-language: fr # 특정 언어 버전이 존재한다면 전송하도록 요청-
위의 간단한 예시를 통해 바로 확인할 수 있는 것은, 메시지가 ASCII로 기록되어 있다는 것이다. 그래서 인간 친화적이라는 특성을 가진다.
-
위 예시는 5줄로 구성되어 있지만, 그보다 더 많거나 적을 수도 있다.
HTTPrequest 메시지의 첫 줄은 request line이라고 부르며, 그 다음 줄들을 header lines라고 부른다.-
request line은 Method field, URL field, HTTP 버전 field 3가지 필드로 구성된다.
-
Method field는 GET, POST, PUT, DELETE 등의 여러가지 값이 사용된다.
-
-
대부분의
HTTPrequest 메시지는GET메서드를 사용하는데, 요청되는 객체는 URL 필드에서 식별되기 때문에, 위의 메시지 예시에서는/somedir/page.html을 요청한다.
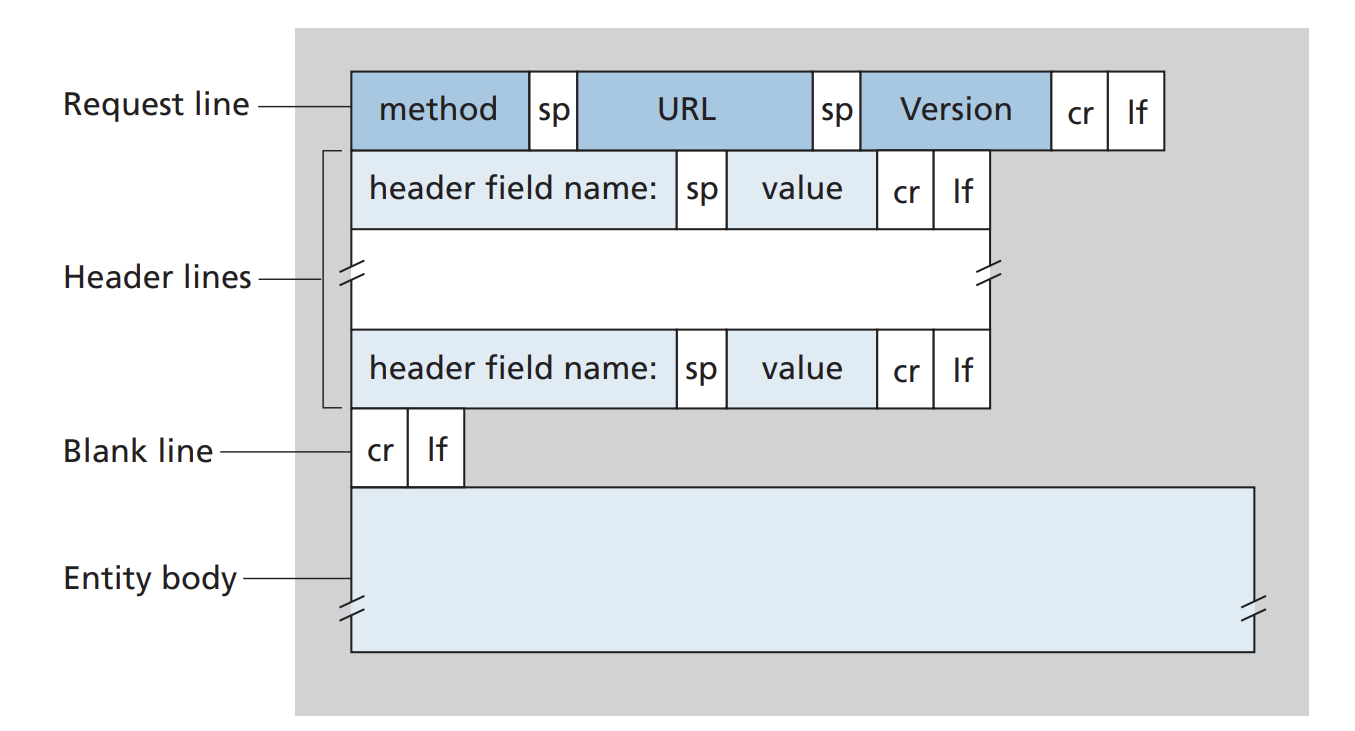
- 위 그림은 일반적인 request 메시지의 형태를 나타내고 있다.
🔴 Entity body
-
주목할 만한 곳은 헤더라인 이후의 Entity body 영역이다.
-
이 영역은
GET메서드를 사용할 때는 비어있지만,POST메서드를 사용할 때는 무언가로 채워져 있다. -
POST메서드는 유저가 설문지를 채우거나, 검색을 하는 등의 경우에 사용된다. 그런 경우에 유저가 입력한 정보들이 Entity body를 채우는 것이다. -
하지만 그런 경우에 무조건
POST메서드를 사용하지는 않는다. 종종GET메서드가 사용될 수도 있고, 유저가 입력한 데이터가 헤더에 포함된다.
🔴 Method field
-
HEAD메서드는GET메서드와 비슷한데, 서버가HEAD메서드 request를 받으면 response 메시지를 보내지만, 요청된 객체는 보내지 않는다. (그래서 개발자가 디버깅에 자주 사용하는 메서드이다.) -
PUT메서드는 웹 퍼블리싱 도구와 함께 사용되는 경우가 많고, 특정 경로에 객체를 업로드할 수 있다. -
DELETE메서드는 웹 서버에서 객체를 삭제할 수 있다.
🟠 HTTP Response 메시지

🔴 Status Code
-
200 OK: 요청이 성공했고, Response에 정보가 담겨있음. -
301 Moved Permanently: 요청된 객체가 다른 곳으로 이동되었고, 새로운 URL이 Response의Location헤더에 담겨져 있음. 보통 클라이언트에서 자동으로 새 URL에 재시도한다. -
400 Bad Request: 서버가 요청을 이해하지 못할 때의 일반적인 오류 코드 -
404 Not Found: 요청된 document가 서버에 존재하지 않음 -
505 HTTP Version Not Supported: 요청 HTTP 버전을 서버에서 지원하지 않음
🟢 쿠키
-
HTTP는 본질적으로 Stateless하다. -
하지만 사용자 접근을 제한하거나 사용자를 식별해야 되는 상황이 생긴다.
-
이럴 때 사용되는 것이 Cookies다. Cookies를 통해 사용자를 추적한다.
🟠 예시: 웹 접속
-
브라우저로
amazon.com에 접속한다. (이미 eBay에는 방문한 적이 있는 상태) -
Request가 amazon 웹서버에 오면, 서버가 ID 번호를 생성하고, 해당 ID 번호로 인덱싱한 Entry를 서버에 DB에 생성한다.
-
이후 amazon 웹서버는
Set-cookie헤더에 ID 번호를 포함하여 Response 메시지를 브라우저에게 송신한다.Set-cookie: 1678 -
브라우저는 Response 메시지의
Set-cookie헤더를 수신한 다음부터, 브라우저가 관리하는 특수 쿠키 파일에 서버 호스트명, ID 번호를 추가한다.
(앞서 말했듯이 eBay에는 이미 방문한 적이 있기에 eBay에 대한 정보도 특수 쿠키 파일에 기록되어 있다.)
-
사용자가 amazon 웹사이트를 탐색하며 Request를 보낼 때마다, 이 특수 쿠키 파일의 ID 번호가 추출되어 아래와 같은 헤더에 추가된다.
Cookie: 1678 -
덕분에 amazon 서버는 사용자가 어떤 페이지를 어떤 순서로, 언제 방문했는지 파악이 가능하며, 장바구니 서비스도 제공할 수 있다.
☑️ 요약
-
HTTP는 앱 계층 프로토콜로, 웹 앱의 심장이다. -
HTTP가 각 end system이 네트워크를 통해 통신하는 방법을 정의해준다. -
HTTP는 비영구 연결이라는 특성으로 시작하였으나, 서버에 큰 부담을 주고 연결 딜레이를 발생시켜 영구 연결 형태로 전환되었다. -
HTTP는TCP와 함께 사용되며, 덕분에 신뢰성 있는 데이터 전송이 가능하다. -
HTTP메시지는 첫 라인(request/status line)과 header lines, entity body로 이루어진다. -
HTTP는 본질적으로 Stateless라는 특성을 가지고 있기 때문에, 사용자 정보를 유지하기 위한 쿠키가 보편적으로 함께 사용된다.
