
🗣️ Intro
Android를 Kotlin으로 개발하는 입장에서 코루틴을 정말 자주 사용하게 됩니다. 비동기 처리에 코루틴을 사용하는 것이 당연시 되는 수준입니다.
최근 회사 일을 하다보니 병렬로 처리해야 되는 작업이 생겼고, 동시성에 초점을 맞추고 있는 코루틴이지만 병렬 처리에도 사용할 수 있지 않을까 하는 생각이 들었습니다.
그렇게 병렬 처리에 코루틴을 활용해보는 과정에서 제가 코루틴을 잘못 이해하고 있었던 부분을 발견하게 되었고, 다른 분들께도 공유드리고 싶어 글을 적게 되었습니다.
🟩 Coroutine
웹상의 많은 글에서도 나오는 내용이지만 코루틴은 코틀린에 한정된 개념이 아닙니다.
당장 위키피디아 문서만 확인해봐도 코루틴을 활용할 수 있는 언어는 정말 많습니다.
문서 아래로 내려가셔서 Native Support 항목만 보셔도 무수히 많은 언어가 리스팅되어 있습니다.
Kotlin에서는 kotlinx.coroutines 라이브러리로 코루틴 기능이 제공되고 있고,
어떤 부분에 초점을 맞추고 구현 됐는지는 아래 영상에서 확인해보실 수 있습니다.
40분이 넘어가는 영상이지만 처음부터 끝까지 보시는 걸 추천드립니다.
KotlinConf 2017 - Introduction to Coroutines by Roman Elizarov
위 영상에서도 언급되는 내용이지만 코루틴은 스레드 생성/소멸 오버헤드를 줄이기 위해 도입됐습니다.
10만개의 작업을 launch하는 단순한 코루틴 코드가 있다고 해봅시다.

위 작업은 1초의 딜레이 이후에 빠르게 처리됩니다.
이게 코루틴이 아니라 스레드였다면 어떻게 될까요. 우선 코드를 아래처럼 바꾸면 작업마다 스레드를 생성합니다.

실행하면 Out of memory error가 발생합니다.
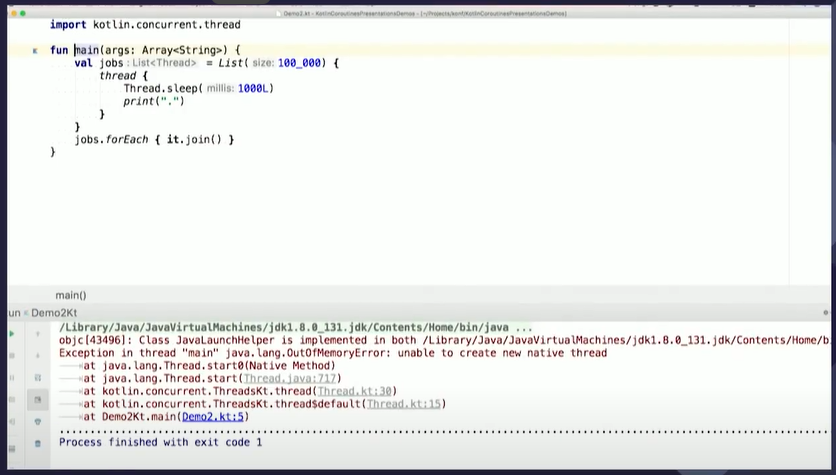
그만큼 수많은 스레드를 생성하면 그만한 대가를 치르게 됩니다.
하지만 코루틴은 작업마다 스레드를 생성하는 것이 아닌, 하나의 스레드가 여러 작업을 스위칭하면서 처리하기 때문에
스레드를 생성/소멸시키며 처리하는 것에 비해 굉장히 가볍습니다.
그래서 very light-weight threads라고 불립니다.
이걸 가능케 해주는 핵심 메커니즘이 일시 중단(suspension) 이라고 할 수 있습니다.
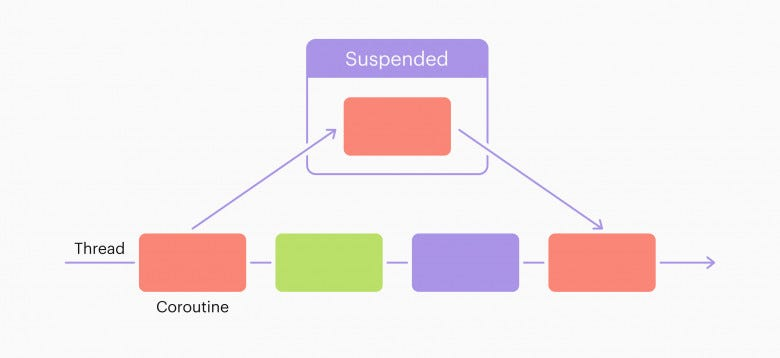
스레드가 작업(코루틴)을 일시 중단하고 다른 작업을 처리한 후에, 다시 돌아와서 남은 작업을 처리합니다.
이것이 동시성 프로그래밍입니다.
작업을 처리하는 스레드가 무조건 하나로 고정되지는 않지만,
코루틴을 잘 이해하고 코드를 작성한다면 thread switching overhead를 줄이고 메모리를 덜 낭비함으로써 작업을 효율적으로 처리하게 됩니다.
Continuation 등 Kotlin 코루틴을 파고들면 더욱 더 많은 정보들이 있지만
본 글에서는 이 일시 중단에 초점을 맞춰 글을 이어나가겠습니다.
🟩 Dispatcher
그 전에 Kotlin 코루틴을 사용한다면 빠질 수 없는 Dispatcher부터 되짚어 보겠습니다.
Dispatcher는 간단히 말하자면 코루틴을 실행할 스레드라고 할 수 있습니다.
아시다시피
- Main
- IO
- Default
- Unconfined
이렇게 4종류의 Dispatcher가 존재하고 있습니다.
보통 Dispatcher는 대충 어떤 용도로 쓰여지는지만 파악된 후 활용되는 경우가 많습니다. (제가 그랬습니다)
Dispatchers.IO가 몇개의 스레드를 가지고 있는지 알고 계셨나요? Dispatchers.Default는 어떨까요?
결론부터 말씀드리자면 IO는 최소 64개, Default는 디바이스 CPU 코어 개수 만큼의 스레드를 가집니다.
즉, Dispatcher는 본질적으로 스레드 풀인 것 입니다. (일반적인 스레드 풀보다 조금 더 복잡하지만)
◼️ Self-made Dispatcher
Dispatcher를 좀 더 쉽게 이해하기 위해 직접 만들어보겠습니다.
newSingleThreadContext와 newFixedThreadPoolContext 함수로 임의의 Dispatcher를 만들 수 있습니다.
두 함수는 CloseableCoroutineDispatcher를 리턴합니다. (아무튼 Dispatcher임)
val singleThreadDispatcher = newSingleThreadContext("SingleThread")
val fixedThreadDispatcher = newFixedThreadPoolContext(64, "FixedThread")함수 이름에서도 확인하실 수 있지만, Dispatcher는 본질적으로 스레드 풀이라는 걸 다시 한번 말씀드리겠습니다.
즉, 동시성 뿐만 아니라 병렬성도 활용할 수 있습니다.
◼️ 왜 Dispatchers.IO.. 등등을 사용해야 되나요?
Dispatcher를 만들 수 있게 되셨으니 의문이 들 수 있습니다.
그럼 Dispatcher를 만들어서 쓰면 되지 않나?
왜 Dispatchers.IO, Dispatchers.Default를 써야 되지?
그에 대한 답은 kotlinx-coroutines-1.6.0 업데이트 노트에서 찾을 수 있었습니다.
특정 작업을 병렬 처리하기 위해
newFixedThreadPoolContext를 사용해 Dispatcher를 만드는 것은 보편적입니다.하지만 다음과 같은 문제가 있습니다.
newFixedThreadPoolContext는 불필요한 스레드를 다수 생성하게 됩니다.
생성된 스레드의 대다수는 idle 상태에서 CPU 및 메모리 자원과 배터리를 낭비할 것입니다.- 직접 만든 디스패처에
withContext함수를 사용하면 스레드 스위칭이 발생합니다.
이것은 많은 리소스를 사용할 수도 있습니다.newFixedThreadPoolContext로 생성된 Dispatcher는 더이상 사용되지 않는 시점에 정리되어야만 합니다.
이것은 잊혀지기 쉬우며, 각종 문제를 발생시킵니다.- 여러 개의 스레드 풀을 만들어서 사용하면, 그것들은 스레드와 리소스를 공유하지 못합니다.
요약하자면 Dispatcher를 직접 만드는 것은 리소스를 쓸데없이 낭비할 가능성이 높다는 것입니다.
◼️ Dispatchers
그래서 우리는 Dispatchers 클래스를 통해 참조할 수 있는 Dispatcher를 사용하는 것이 좋습니다.
(다행히 대부분의 사람들이 이유를 알든 모르든 그렇게 하고 있습니다)
이제 다시 Dispatchers로 돌아와서 각 Dispatcher에 대해 알아 보겠습니다.
🔶 Dispatchers.Main
- 대부분 아는 사실이지만 Android 앱의 메인 스레드와 동일합니다.
- 고로 싱글 스레드입니다.
🔹 Dispatchers.Main.immediate
- Main Dispatcher와 근본은 동일하지만,
다른 점은 메인 스레드에서 이 Dispatcher를 사용하면 작업을 즉각적으로 처리합니다. (re-dispatch 되지 않습니다) lifecycleScope,viewModelScope가 이 Dispatcher를 기반으로 삼고 있습니다.
🔶 Dispatchers.IO
- IO 디스패처는 보통 네트워크 통신 처리 및 입출력에 사용합니다.
- 앞서 언급 드렸듯이 최소 64개의 스레드를 보유합니다. (만약 CPU 코어 개수가 64개보다 많다면 CPU 코어 개수가 스레드 수가 됩니다)
🔶 Dispatchers.Default
- CPU 코어 개수만큼의 스레드를 보유하는 Dispatcher 입니다. (싱글코어 CPU라도 최소 2개)
- 그래서 CPU-bound한 작업에 활용하기 좋습니다.
🔶 Dispatchers.Unconfined
- 일시 중단이 일어난 뒤에 아무 Dispatcher에서나 실행될 수 있도록 하는 Dispatcher입니다.
🟩 suspend function
Dispatcher에 대해 더 말씀드릴 게 있지만 그 전에 suspend에 대해 확실히 짚고 넘어가야될 부분이 있습니다.
말씀 드렸듯이 Coroutine의 핵심 메커니즘은 일시 중단이고,
그것을 달성하기 위해 Kotlin에서는 suspend라는 키워드를 활용하고 있습니다.
함수에 suspend 키워드를 붙이면 일시 중단 가능성이 있는 함수가 됩니다.
◼️ suspension이 발생하는 시점
그럼 suspend 키워드를 함수에 붙였을 때 suspension이 언제 발생하나요?
아래 코드는 어떨까요?
suspend fun doSomething() {
var num = 0L
while (num < Long.MAX_VALUE) {
num++
}
}num이라는 변수를 단순히 최댓값까지 증가시키는 코드입니다.
이 코드를 실행하면 언제 suspension이 발생할까요?
생각보다 많은 분들이 혼동하는 부분인데, 이 코드에서는 suspension이 절대로 발생하지 않습니다.
왜냐하면 suspension이 발생하기 위해서는 다른 suspend function을 호출해야 하기 때문입니다. (delay, yield 등)
그에 대한 설명은 다음 문서에서 확인하실 수 있습니다.
🟩 Dispatcher를 잘못 사용하게 되는 경우
만약 suspension이 언제 일어나는지 모르고 있었다면
Dispatcher를 잘못 활용할 가능성도 높습니다. 아래 코드를 살펴보겠습니다.
// 쿼드 코어에서 실행했다고 가정하겠습니다. (Dispatchers.Default의 스레드 개수 4개)
fun main() = runBlocking {
// 위에서 예시로 보여드린 함수를 5개의 코루틴으로 호출해보겠습니다.
// doSomething() 함수는 Default에서 처리되도록 합니다.
launch {
launch { launch(Dispatchers.Default) { doSomething() } } // j1
launch { launch(Dispatchers.Default) { doSomething() } } // j2
launch { launch(Dispatchers.Default) { doSomething() } } // j3
launch { launch(Dispatchers.Default) { doSomething() } } // j4
launch { launch(Dispatchers.Default) { doSomething() } } // j5
// j1 766ms
// j2 765ms
...
// j5는 몇초가 찍힐까요?
}
}기본 스레드에서 doSomething()을 호출하는 5개의 코루틴을 거의 동시에 시작합니다.
doSomething()을 처리하는 스레드는 Dispatchers.Default에 대기하고 있습니다.
그런데 Dispatchers.Default의 스레드 개수가 4개라면 어떤 일이 벌어질까요?
다섯 번째 코루틴은 대략 2배 더 소요됩니다.
만약 첫번째 코루틴에 766ms가 소모됐다면 다섯 번째 코루틴에는 대략 1500ms 정도가 소요된다는 것입니다.
◼️ suspension이 없다면 점유를 풀지 않는다
Dispatchers.Default에 존재하는 4개의 스레드는 각각의 코루틴을 처리하느라 바빴을 겁니다.
또한 doSomething() 함수 내부에는 중단 지점이 존재하지 않았기 때문에 일시 중단이 일어날 수 없습니다.
이렇게 존재하지 않는 동시성을 믿고 코루틴을 병렬 처리에 사용했다면 이유 모를 대기 시간이 발생할 수 있습니다.
◼️ 최악의 경우
이미지 처리 기능을 지원하는 앱이 존재한다고 가정 해보겠습니다.
고용량의 이미지를 압축하는데, 대략 30초가 소요되고
이미지를 압축하는 동안 다른 기능을 실행할 수 있다고 해봅시다.
이때 이미지 압축에 사용한 Dispatchers.Default를 프로필 사진 압축에도 사용한다고 가정 해보겠습니다.
그럼 이미지 압축이 완료될 때까지 프로필 사진 압축은 시작조차 할 수 없습니다.
압축 시간인 30초를 의미없이 기다리게 됩니다. 사용자는 왜 그런지 이유도 모를 겁니다.
같은 Dispatcher를 사용했을 때 스레드가 포화상태라면 쓸데없는 시간을 필연적으로 대기하게 됩니다.
🟩 Solutions
그럼 어떻게 해야 이 문제를 해결할 수 있을까요? 두가지 방법이 있습니다.
◼️ 중단 지점 만들기
doSomething() 함수를 다음과 같이 바꿔보겠습니다
suspend fun doSomething() {
var num = 0L
while (num < Long.MAX_VALUE) {
num++
if (num == Long.MAX_VALUE / 2)
yield()
}
}num이 목표 값의 절반이 됐을 때 yield()를 호출합니다.
이 함수는 suspend function으로, 같은 디스패처의 다른 스레드가 이 코루틴을 처리하도록 하는 함수입니다.
이렇게 중단 지점을 만들어 줌으로써 특정 코루틴이 대기만 하지 않고 스레드에게 처리될 기회를 갖게 됩니다.
하지만 문제가 있는데, 우선 적절한 중단 지점을 설정하는 게 개발자 입장에서 단순하지가 않습니다.
또한 suspend 키워드가 없는 함수를 코루틴으로 실행하게 되는 경우도 많습니다.
앞서 언급한 이미지 압축을 예시로 든다면, Bitmap 클래스의 compress 함수는 blocking 함수입니다.
이런 함수는 내부 코드를 건드릴 수 없기 때문에, 중단 지점을 만들 수도 없습니다.
◼️ 병렬성 제한하기
그래서 다른 방식으로 접근할 수 있는 방법은 병렬성 자체를 제한하는 것 입니다.
제한을 위해 limitedParallelism 함수를 활용할 수 있습니다.
이 함수는 Dispatcher에서 사용할 스레드 개수를 제한할 수 있도록 해줍니다.
// 4개의 스레드를 갖는 Default Dispatcher라면 그 중 3개만 사용합니다.
val limitedDefaultDispatchers = Dispatchers.Default.limitedParallelism(3)이렇게 스레드 개수를 제한하면 적어도 스레드 풀이 마비될 일은 없습니다.
🟩 Dispatchers 더 알아보기
◼️ 특별한 Dispatcher, Dispatchers.IO
사실 이 limitedParallelism은 이미 Dispatchers.IO의 내부 코드에서 호출되고 있습니다.
private val default = UnlimitedIoScheduler.limitedParallelism(
systemProp(
IO_PARALLELISM_PROPERTY_NAME,
64.coerceAtLeast(AVAILABLE_PROCESSORS)
)
)Dispatchers.IO는 무제한 스레드 풀을 부모로 두고 있고, 그걸 limitedParallelism으로 제한하고 있습니다.
🔶 Elasticity
또 그러한 점 때문에, Dispatchers.IO에 limitedParallelism을 호출하면 Dispatchers.IO보다 더 많은 수의 스레드를 설정할 수 있습니다.
// Dispatchers.IO의 스레드 개수는 일반적으로 64개입니다
// 하지만 이렇게 64개를 넘어서는 수를 설정할 수가 있습니다
val dbDispatcher = Dispatchers.IO.limitedParallelism(100)이것을 Elasticity라고 합니다.
◼️ Default & IO
또한 Dispatchers.IO와 Dispatchers.Default는 같은 스레드 풀을 공유한다고 합니다. 그래서 두 Dispatcher 간에는 withContext를 사용해도 스레드 스위칭이 발생하지 않을 확률이 높습니다.
(물론 아예 발생하지 않는 것은 아닙니다. 다음 글을 참고하세요)
🔚 마치며
코루틴은 동시성을 좀 더 강조하고 있는 기술입니다. 하지만 Dispatcher를 통해 병렬성도 충분히 달성할 수 있습니다.
오히려 Dispatcher를 이해하고 적절히 사용한다면 굳이 스레드를 추가 생성할 필요가 없습니다.
그러나 중단 메커니즘을 잘못 이해한다면 병렬성을 잘 활용하기 이전에 더 큰 문제가 생길 수 있습니다.
또한 병렬성 이전에 동시성을 달성하기 위해서는 적절한 중단 지점이 필요합니다.
보통 코루틴을 처음 접하시는 분들은 동시성, 일시 중단이라는 키워드에 매몰되기 쉬운데
코루틴 라이브러리를 이루는 클래스가 실질적으로 구현이 어떻게 되어 있는지,
또 어떻게 하면 더 다채롭게 활용될 수 있을 지에 대한 정보도 공유됐으면 하는 마음에 글을 남겨봅니다.
☑️ 요약
✅ suspend 키워드를 붙였다고 중단이 발생하지 않습니다. 명시적으로 중단 시점을 만들어 주어야 합니다.
✅ 코루틴으로도 병렬성을 달성할 수 있습니다.
✅ Dispatchers.IO의 뒤에는 무제한 스레드 풀이 있습니다.
✅ Dispatchers.IO는 Dispatchers.Default와 스레드 풀을 공유합니다. 그 덕에 스레드 스위칭 오버헤드를 줄일 수 있습니다.
참고 자료
Kotlin 공식 문서: 각각의 Dispatcher에 대한 설명
왜 내 코루틴은 느릴까?
JetBrains 업데이트 노트: limitedParellelism을 소개합니다
IO와 Default Dispatcher에 withContext를 사용했는데 Context switching이 발생했어요
IO와 Default Dispatcher는 태생부터 잘못 되었습니다 (반박 많음)
