🗺️ Map
키 : 값 의 쌍으로 이루어진 데이터를 저장하는 자료 구조.
List 와 마찬가지로 인터페이스. (IDE에서도 I 로 확인된다 !)
기본 문법 : Map<String, String> map = new HashMap<>();
Map<String, String> myMap = new HashMap<>();
myMap.put("basketball", "농구");
myMap.put("baseball", "야구");
myMap.put("soccer", "축구");
System.out.println(myMap);
myMap.put("baseball", "크리켓");
// baseball 을 map 에서 검색하는 복잡도 O(1)
System.out.println(myMap.get("baseball"));redis 와 비슷한 원리로, key:value 기반으로 빠른 성능을 보이는 것도 비슷하다 !
Map 인터페이스를 구현한 Map자료형에는 HashMap, LinkedHashMap, TreeMap(정렬의 성능이 좋음) 등이 있다.
- 일반 map 사용 시 출력에 순서가 없음에 주의 !
- index 사용이 불가하기 때문에 Enhanced for 문 및 iterator 사용.
- iterator
- 자바의 컬렉션 프레임워크는 컬렉션에 저장된 요소를 읽어오는 방법을 Iterator 인터페이스로 표준화
- Collection 인터페이스에서는 Iterator 인터페이스를 구현한 클래스의 인스턴스를 반환하는 iterator() 메소드를 정의
- hasNext() : 해당 이터레이션(iteration)이 다음 요소를 가지고 있으면 true를 반환
- while 이랑 같이 쓰인다 !
- next() : 이터레이션(iteration)의 다음 요소를 반환
// map은 인덱스가 없기 때문에 enhanced for 문을 활용해야 한다.
for(String a : myMap.keySet()){
System.out.println(a); // 키 값
System.out.println(myMap.get(a)); // value 값
}
for(int a : myMap.values()){
System.out.println(a);
}
// iterator 를 활용하여 key 값 하나씩 출력
Iterator<String> myIter = myMap.keySet().iterator();HashMap
HashMap 의 경우 순서가 없기에 index로 값을 구할 수 없다.
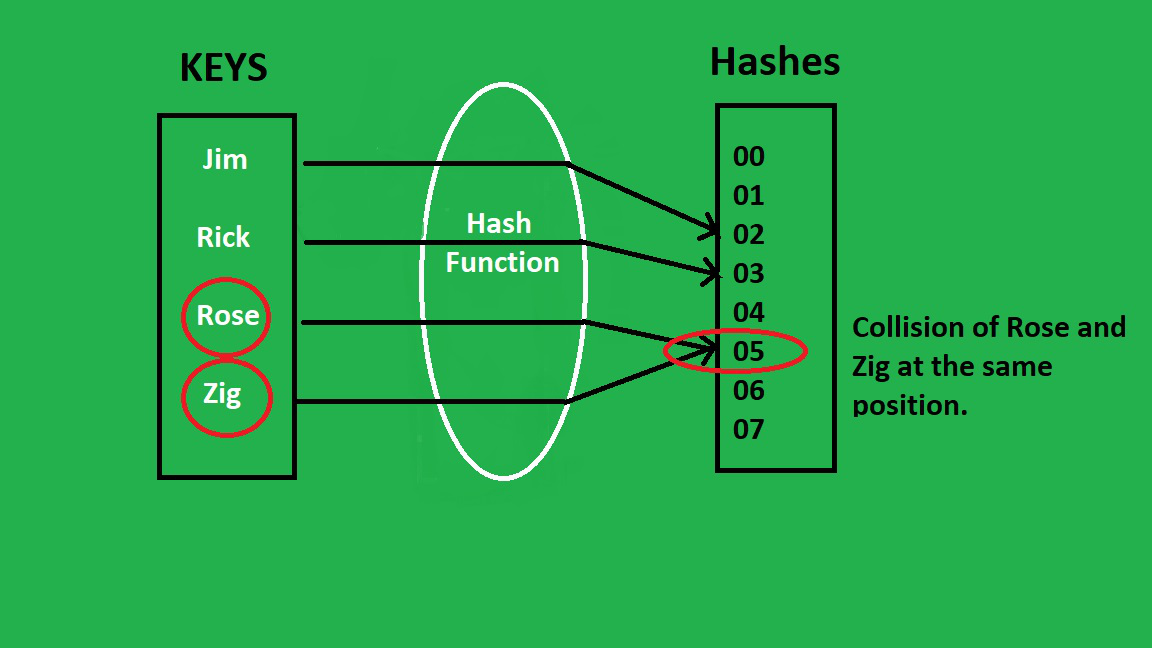
- 해시 테이블
map은 key를 일정한 길이를 갖는 임의의 숫자로 변환하는
해시함수를 통해 해시코드라는 정수 값을 반환하고,
해시함수를 통해 반환되는 값은 항상 일정하다 !
⇒ 해시코드 변환기로 확인 가능 !
ex ) "arorong" → 9D8A9B395 이라면, 새로고침 등으로도 값이 변하지 않는다 !
LinkedHashMap
삽입된 순서를 보장하는 LinkedHashMap.
하지만 index 로 값을 구할 수 없다는 것은 동일하다 !
// LinkedHashMap : 데이터 삽입 순서 유지
Map<String, Integer> linkedMap = new LinkedHashMap<>();
linkedMap.put("hello5", 1);
linkedMap.put("hello4", 1);
linkedMap.put("hello3", 1);
linkedMap.put("hello2", 1);
linkedMap.put("hello1", 1);
System.out.println(linkedMap); // 넣는 순서가 유지되는 것을 확인할 수 있다.TreeMap
정렬의 성능이 좋은 TreeMap.
키를 가지고 정렬이 된 상태로 삽입된다.
// TreeMap : key 를 통해 데이터를 정렬(최적화된 정렬 => log n 의 복잡도를 가짐)
Map<String, Integer> treeMap = new TreeMap<>();
treeMap.put("hello5", 1);
treeMap.put("hello4", 1);
treeMap.put("hello3", 1);
treeMap.put("hello2", 1);
treeMap.put("hello1", 1);
System.out.println(treeMap);🧮 Set
수학의 집합과 유사한 성질을 지닌 자료형. 중복 없음 ! 순서 없음 !
HashSet 이 대표적인 set 인터페이스 구현 자료형.
- map 과 마찬가지로 LinkedHashSet, TreeSet이 존재한다.
- map 과 마찬가지로 Enhanced for 문 및 iterator 사용.
기본 문법 :Set<String> set = new HashSet<>();
Set<String> mySet = new HashSet<>();
mySet.add("h");
mySet.add("h");
mySet.add("e");
mySet.add("l");
mySet.add("l");
mySet.add("o");
System.out.println(mySet); // {e, h, l, o} 로 중복X 순서X// 집합 관련 함수 : 교집합(retainAll) / 합집합(addAll) / 차집합(removeAll)
Set<String> set1 = new HashSet<>(Arrays.asList("java", "python", "javascript"));
Set<String> set2 = new HashSet<>(Arrays.asList("java", "html", "css"));
set1.retainAll(set2); // 교집합
set1.addAll(set2); // 합집합
set1.removeAll(set2); // 차집합
System.out.println(set1);🔢 Queue
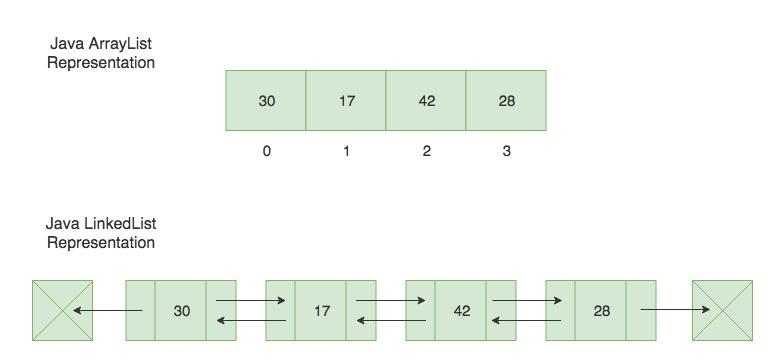
가장 먼저 저장(push)된 데이터가 가장 먼저 인출(pop)되는 선입선출 자료 구조 !
기본 문법 : Queue<Integer> q = new LinkedList<>();
- Queue를 구현한 LinkedList를 통한 선언이 가장 보편적.
LinkedList
LinkedList는 자신의 앞과 뒤 요소에 대한 참조를 가지고 이중 연결 리스트(Doubly Linked List)로 구현, 구조가 큐의 기본 동작에 매우 적합.
이중 연결 리스트(doubly linked list) : 각 노드가 이전 및 다음 노드에 대한 참조를 하므로, 큐의 주요 연산인 삽입(offer)과 삭제(poll)에 있어서 효율적인 성능을 제공.
다만 remove(0) 의 경우 O(n) 의 복잡도 발생! = 뒤에서 앞으로 모든 값이 땡겨온다.
⇒ 어떤 값이 어떤 index를 가지는지 내부적으로 가지고 있지 않기 때문.
ArrayList
동적배열로 구현됨.
ArrayList는 인덱스를 통한 요소의 접근에 있어서 매우 빠름 - (O(1)).
리스트의 중간에 요소를 추가하거나 제거하는 경우에는 뒤의 요소들을 이동시켜야 하기 때문에 더 많은 시간이 소요 - (O(n)).
🧱 Stack

queue 와 반대로 가장 나중에 저장(push)된 데이터가 가장 먼저 인출(pop)되는 후입선출 구조 !
기본 문법 : Stack<Integer> st = new Stack<Integer>(); // 스택의 생성
- 나중 데이터를 먼저 꺼내서 비교해야 하는 작업일경우 stack사용
- 페이지 뒤로 가기
- 괄호 짝 맞추기
🔄 Deque
양방향 큐 (Double Ended Queue) 를 의미하며, 양쪽 끝 모두 요소의 추가와 삭제가 가능한 자료 구조.
기본 문법 : Deque<DequeDemo> demo = new ArrayDeque<DequeDemo>();
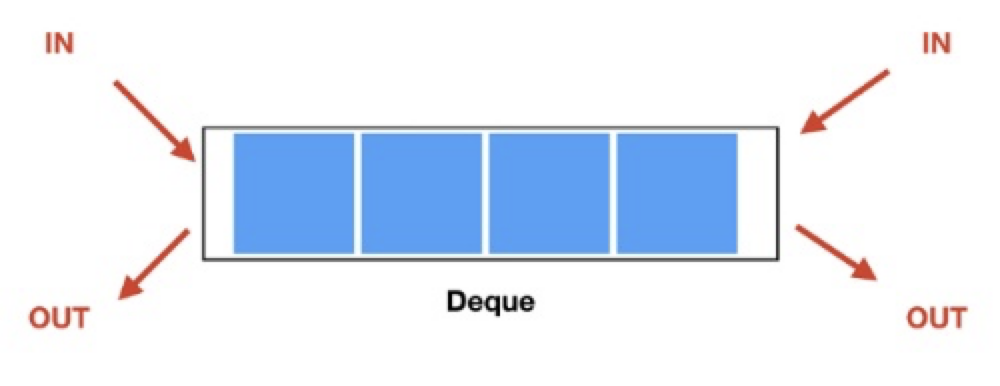
stack과 queue의 결합으로 성능이 더 좋다. java 에서 추천하는 방식 !

와.. 벌써 Deque 까지.. 정리 대박입니다 🚀