task의 목표 : 주어진 질문에 대한 단락에서 답을 추출하는 것
input : 질문(Q)-단락(paragraph) 쌍(question-paragraph pair)
Q : 면역 체계는 무엇입니까?
paragraph : 면역 체계는 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다. 제대로 기능하려면 .... 합니다.
output : 단락에서 응답에 해당하는 텍스트 범위(시작/끝 index)
A : 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다.
그렇다면 BERT를 어떻게 fine-tuning 해야할까?
BERT는
- 주어진 단락의 답을 포함하는 text 범위의 시작과 끝의 인덱스를 이해해야한다.
- 답을 포함하는 인덱스를 찾기 위해 단락 내 답의 시작과 끝 토큰(단어)이 될 확률을 각각 구하면 쉽게 답을 추출할 수 있을 것이다.
시작 벡터 S - 끝 벡터 E의 값을 학습한다.
단락 내 각 token(단어)이 응답의 시작 토큰이 될 확률(P)을 계산해보자.
Ri : 각 토큰 i에 대한 토큰 표현 벡터
S : 시작 벡터
E : 끝 벡터
S·Ri : 내적 계산
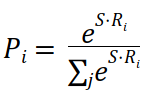
시작 token이 될 확률이 높은 token의 index를 선택해 시작 index를 구한다.
마찬가지로 단락의 각 token(단어)이 응답의 끝 token이 될 확률을 계산한다.
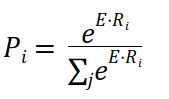
끝 token이 될 확률이 높은 token의 index를 선택해 끝 index를 구한다.
이제, 시작과 끝 index를 사용해 답을 포함하는 텍스트 범위를 선택할 수 있게 된다.
질문-단락 쌍을 토큰화하고, 토큰을 사전 학습된 BERT 모델에 입력해 모든 토큰의 임베딩을 반환
임베딩을 계산한 후 시작/끝 벡터로 내적을 계산한 뒤 softmax 함수를 적용, 단락의 각 토큰에 대해서 시작/끝 단어일 확률을 얻는다.
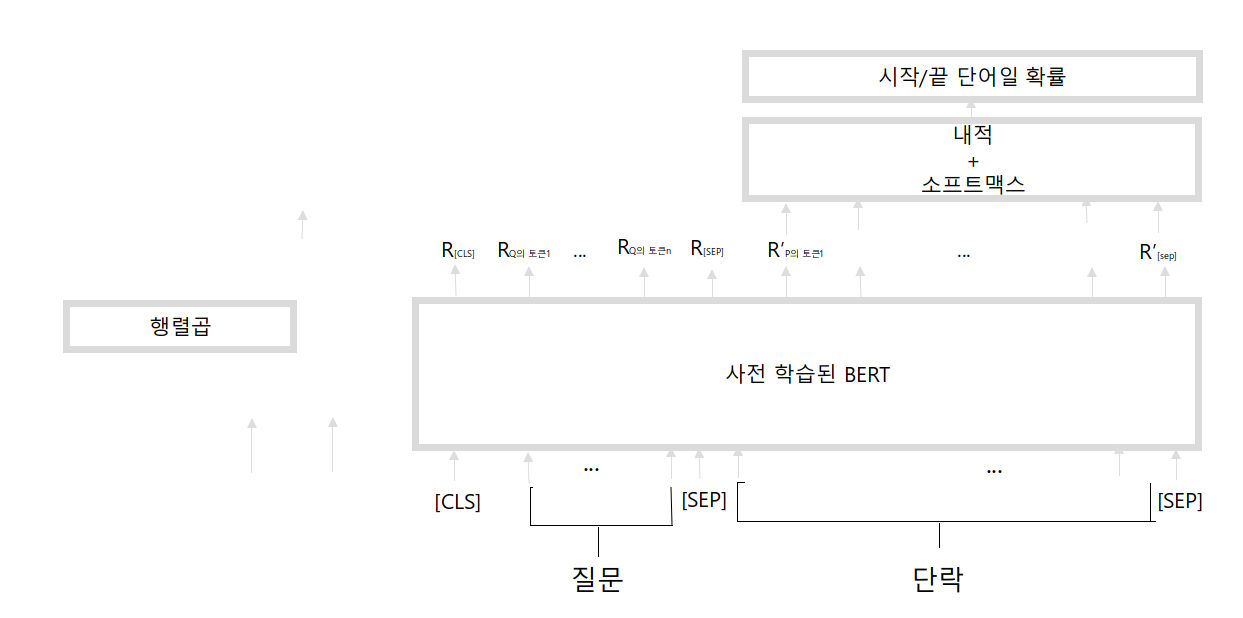
확률이 가장 높은 시작 및 끝 인덱스를 사용해 답을 포함하는 text 범위를 선택해야 한다.
practice
!pip install transformers # 패키지 설치from transformers import BertForQuestionAnswering, BertTokenizer
import torchmodel = BertForQuestionAnswering.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')
tokenizer = BertTokenizer.from_pretrained('bert-large-uncased-whole-word-masking-finetuned-squad')question = "What is the immune system?" #"면역 체계는 무엇입니까?"
paragraph = "The immune system is a system of various biological structures and processes within an organism that protects against disease. To function properly, the immune system must detect a variety of substances known as pathogens, from viruses to parasites, and distinguish them from the healthy tissue of an organism."
# "면역 체계는 질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템입니다. 제대로 기능하려면 면역 체계가 바이러스에서 기생충에 이르기까지 병원균으로 알려진 다양한 물질을 탐지하고 유기체의 건강한 조직과 구별해야 합니다."# 인코딩
question = '[CLS]' + question + '[SEP]'
paragraph = paragraph + '[SEP]'
question_tokens = tokenizer.tokenize(question)
paragraph_tokens = tokenizer.tokenize(paragraph)
tokens = question_tokens + paragraph_tokens
input_ids = tokenizer.convert_tokens_to_ids(tokens)
segment_ids = [0] * len(question_tokens)
segment_ids += [1] * len(paragraph_tokens)
print(len(input_ids), len(segment_ids)) # 같아야 한다.
input_ids = torch.tensor([input_ids])
segment_ids = torch.tensor([segment_ids])# 원문이 나오는지 확인
# 위의 모델에서는 영어로 학습되었기 때문에 한국어는 좋은 결과를 내지 못했다.
tokenizer.decode(input_ids)
# `[CLS] what is the immune system? [SEP] the immune ... [SEP]`Answer 얻기
output = model(input_ids, token_type_ids = segment_ids)
start_scores, end_scores = output['start_logits'], output['end_logits']
start_scores, end_scores # 각 index가 응답의 시작/끝 토큰이 될 확률start_index = torch.argmax(start_scores)
end_index = torch.argmax(end_scores)
start_index, end_index # tensor(n), tensor(m)이 나와야 한다. 여기서 n, m은 indexprint('Q :', question[5:-5])
print('A :', ' '.join(tokens[start_index:end_index+1]))Q : What is the immune system?
A : a system of various biological structures and processes within an organism that protects against disease
(질병으로부터 보호하는 유기체 내의 다양한 생물학적 구조와 과정의 시스템)
Reference
구글 BERT의 정석, Sudharsan Ravichandiran, 한빛미디어, 2021
