사용자의 구매 패턴이나 평점을 가지고 다른 사람들의 구매 패턴, 평점을 비교하여 추천하는 방법이다.
장점
- 도메인 지식이 필요하지 않다.(추가적인 사용자의 개인정보나 item의 정보가 없어도 추천할 수 있다.)
- 사용자의 새로운 흥미를 발견하기 좋다.
- 추가 문맥 정보 등이 필요 없기 때문에 시작단계의 모델로 선택하기 좋다.
- 2006 ~ 2009 Netflix Prize Competition에서 우승한 알고리즘이다.
단점
- 새로운 아이템에 대해서 다루기가 힘듬
- side features(개인정보, 추가정보)를 포함시키기 어려움
종류
- 최근접 이웃기반
- 잠재 요인기반
메모리 기반, 이웃 기반 ( Neighborhodd based Collaborative Filtering )
메모리 기반 알고리즘으로 협업 필터링을 위해 개발된 초기 알고리즘이다.
사용자 기반(User-based)와 상품 기반(Item-based) 협업 필터링 방식이 있다.
사용자의 평점이나 사용 여부를 바탕으로 패턴을 파악해 그 기록(메모리)를 바탕으로 추천을 진행한다.
- 사용자 기반 협업 필터링 : 사용자의 구매 패턴(평점)과 유사한 사용자를 찾아 추천 리스트 생성
- 상품 기반 협업 필터링 : 특정 사용자가 준 점수간의 유사한 상품을 찾아서 추천 리스트 생성
KNN ( K Nearest Neighbors )
가장 근접한 K명의 이웃 데이터를 통해 사용자가 어떤 Cluster에 속할지 예측하는 방식으로 사용자가 준 평점으로 유사한 user의 item을 찾거나 유사한 itme을 찾는다.
학습하는 대신 훈련 dataset을 메모리에 저장하기 때문에 lazy learner이라고도 부른다.
편향을 제거(평점을 후하게 주거나 적게 주는 경우 방지)하기 위해 비교군의 평점을 동일하게 해준다.
장점
- 간단하고 직관적인 접근 방식이다.
- 새로운 훈련 데이터에 즉시 적응할 수 있다.
- 추천하는 이유를 정당화하기 쉽고, 해석 가능성이 두드러진다.
- 새로운 item이나 user이 추가되어도 상대적으로 안정적이다.
알고리즘
1. 숫자 k와 거리 측정 기준을 선택
2. 분류하려는 샘플에서 k개의 최근접 이웃을 찾는다.
3. 가장 많이 속한 집단의 class label을 할당한다.(다수결 투표)
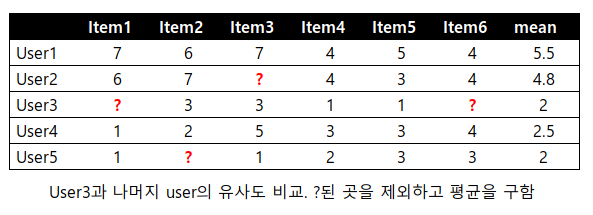
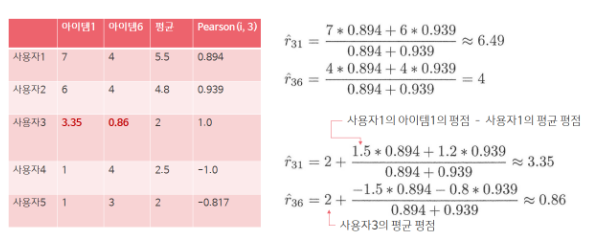
평점 데이터에 NULL(None) 값이 있는 경우 비슷한 유저를 유사도행렬을 통해 찾아 NULL값을 대체한다.
NULL값 채우기
- user 기반 협업 필터링일 경우 user3에 ?값을 채우기 위해 user3과 다른 user와의 유사도를 측정한다.
- user에 따른 data의 mean값을 구한다.
- 각 user에서 ?가 있는 값은 제외하고 코사인 유사도나 피어슨 유사도를 구한다.
- 유사도가 1에 근사한 (user의 평점-user의 평균평점) * 유사도값의 가중평균을 통해 ?값을 채운다.
- item 기반 협업필터링일 경우 위와 비슷하게 item을 통해서 ?를 채운다.

단점
1. resource가 많이 든다. 새로운 샘플을 분류하는 계산 복잡도가 크다.
2. 희소성 때문에 제한된 범위가 있다 : Top-K에만 관심이 있고, 아무도 평가하지 않은 item이 있다면 등급 예측을 제공할 수 없다.
code
00. Recommendation Algorithm Introduction.ipynb의 5. KNN 알고리즘
잠재 요인기반 ( Latent Factor Collaborative Filtering )
Rating Matrix에서 빈 공간을 채우기 위해서 user과 item을 잘 표현하는 차원(Latent Factor)을 찾는 방법이다.
Latent Factor을 찾기 위해서 Matrix 분해 알고리즘을 사용한다.
Matrix Factorization Principles
user-item 상호 작용 행렬을 두 개의 저차원 직사각형 행렬의 곱으로 분해하는 방법
고유값 분해와 같은 행렬을 대각화하는 방법으로 진행된다.
아래의 방법이 있다.
1. SVD : 고유값 분해와 같은 행렬을 대각화하는 방법
- 결측치가 없어야 가능하지만 대부분 현업 데이터는 sparse한 데이터이다.(적용하기 어렵다.)
- SGD : 임의로 User Latent와 Item Latent의 초기값을 둔 뒤 기울기 하강법을 통해 모든 평점에 대해 반복하여 두 행렬의 최적값을 동시에 찾아가는 방식.
- 장점 : 매우 유연하여 다른 Loss Function을 사용할 수 있고, 병렬화가 가능하다.
- 단점 : 수렴하기까지 속도가 매우 느리다.
- ALS : User Latent, Item Latent 중 하나를 고정시킨 후 다른 행렬을 최적화하고, 최적화된 행렬을 고정시킨 후 다른 행렬을 최적화하는 방식으로 convex형태로 바꿔 수렴된 행렬을 찾는 방식.
- 장점 : SGD보다 수렴속도가 빠르고 병렬화가 가능하다.
- 단점 : Loss Squares에서만 사용 가능하다.
- convex : 볼록한, convex함수에 대한 경사하강법은 local minima가 없기 때문에 최적의 해로 수렴할 수 있다.
딥러닝에서 convex란?
code
00. Recommendation Algorithm Introduction.ipynb의 6. SGD 알고리즘, 7. ALS 알고리즘
