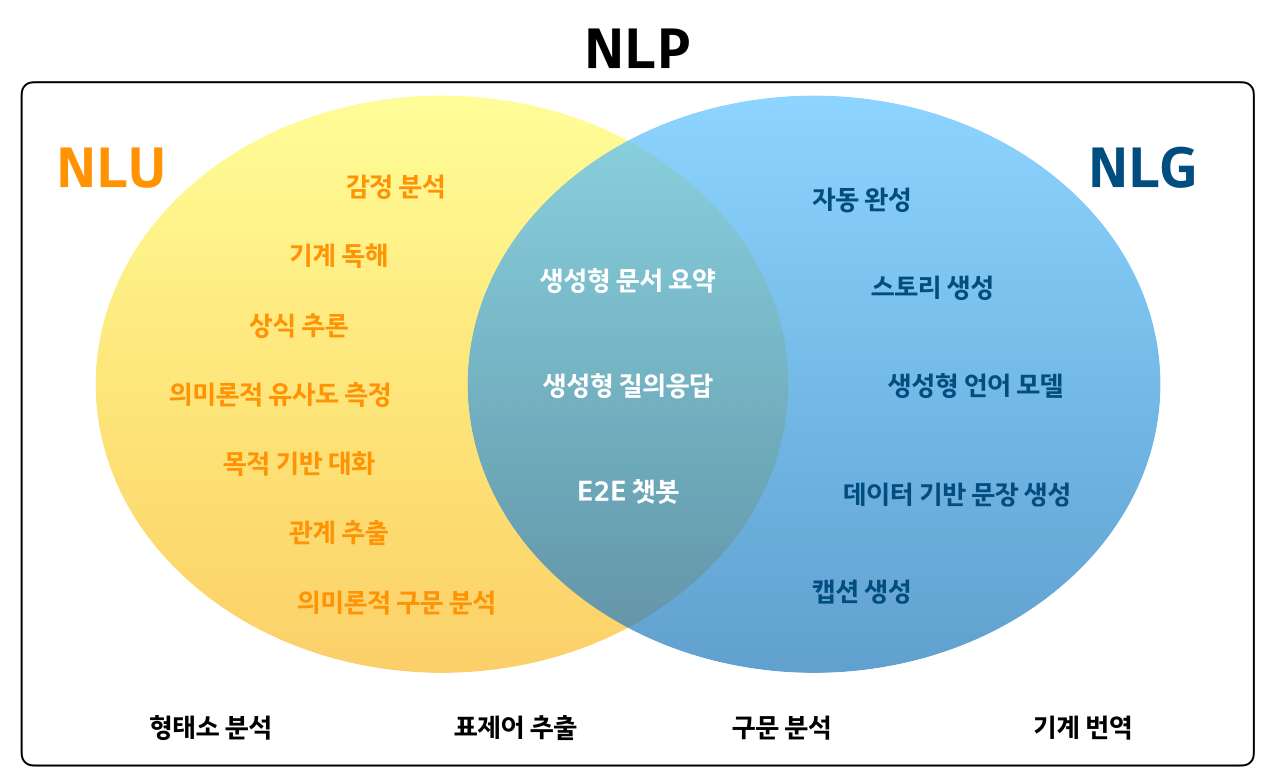
NLP sub task 3가지 간단 정리
01. NLI ( Natural-Language-Inference, 자연어 추론 )
-
전제가 주어졌을 때, 두 문장의 유사도를 통해 가설이 참(포함, 수반), 거짓(모순) 혹은 중립(결정되지 않음) 중 어떤 것인지 결정하는 작업이다.
-
해결 가능한 문제
- 같은 text내에 속하는지, 연결되는지, 같은 주제인지 파악할 수 있다.
- 답변 생성, 언어간 자연어 추론, 시각적 의미(이미지가 의미적으로 텍스트를 수반하는지 여부 예측), 앞뒤 문장 연결성
-
데이터 : 전제 문장, 가설 문장, label(참, 거짓, 중립 중 하나)

-
응용 서비스 : 답변 생성, 언어 간 자연어 추론, 시각적 의미
-
SOTA 모델 소개
-
EFL : text corpus를 수반 작업으로 재구성한 다음 8개 정도의 예제로 모델을 fine-tuning하는 것
-
EFL을 통해 자연스럽게 비지도 대조 학습 기반 데이터 증가 방법과 결합될 수 있고 다국어 few-shot Learning으로 쉽게 확장됩니다.
*few-shot Learning : "Learn to learn", 적은 데이터와 적은 연산으로 학습을 진행하는 것
-
data : 8 datasets from GLUE ( CoLA, SST-2, MPRC, QQP4, STS-B, MNLI, QNLI, RTE, IMDB, Yelp, AG News, SNLI )
-
평가 지표 : 정확도 ( Accuracy )
-
02. Topic modeling ( 토픽 모델링 )
- 문서에서 발생하는 추상적인 "topic"을 발견하기 위한 통계 모델로 텍스트 본문에서 숨겨진 의미 구조를 발견하기 위해 자주 사용되는 텍스트 마이닝 도구이다.
- Data : text corpus
- SOTA 모델 소개
- 베이지안 부분공간 다항식 모델(Bayesian SMM), 난해성 문제를 해결, 생성 가우스 선형 분류기를 제시, 과적합에 대해 강력
- data : arXiv, 20 Newsgroups, fashion 144K, COVID-19 Twitter Chatter Dataset, OpoSum
- 20 Newsgroups : 20개의 뉴스 그룹 데이터 세트는 20개의 다른 뉴스 그룹에 (거의) 균등하게 분할된 약 20,000개의 뉴스 그룹 문서 모음
- 평가 지표
- 정확도( Accuracy )
- CE ( Cross-Entropy ) : 분류기가 예측값에 대해서 얼마나 신뢰할 수 있는가, 잘 보정된 분류기는 더 낮은 CE를 갖는 경향이 있다.
03. Text Generation ( 텍스트 생성 )
-
사람이 작성한 텍스트와 구별할 수 없는 것처럼 보이도록 텍스트를 생성하는 작업으로 공식적으로 "natural language generation"으로 알려져있다.
-
Markov 프로세스 또는 LSTM과 같은 심층 생성 모델로 처리할 수 있고, 최근에는 BART, GPT, GAN 기반 접근 방식으로도 적용하고 있다.
-
METEOR, ROUGE, BLEU와 같은 사람의 평가 또는 자동 평가 메트릭을 통해 평가된다.
-
대화 생성, 데이터-텍스트 생성, 다중 문서 요약, 텍스트 스타일 전송, 스토리 생성, 시각적 스토리 텔링, 뉴스 생성 등의 다양한 작업을 할 수 있다.
-
Data : CNN/Daily Mail, DailyDialog, PERSONA-CHAT, BookCorpus, COCO Captions, VQG, Sentence Compression, WritiongPrompts, MTNT 등
-
SOTA 모델 소개
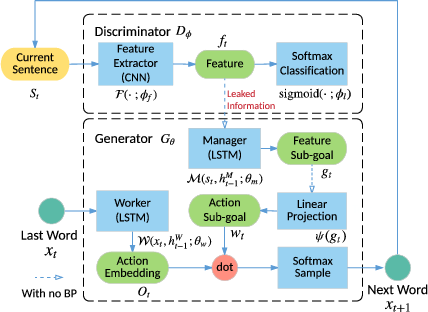
- LeakGAN : LSTM으로 구성된 Manager와 Worker간의 상호작용을 통해서 문장 구조를 암묵적으로 학습할 수 있고, 길고 짧은 텍스트 생성에서 모두 성능을 향상시킬 수 있다.
- Data
- COCO Image Captions : 330,000개 이상의 이미지를 설명하는 150만 개 이상의 캡션
- 평가 지표 : BLEU-2, human rating scores in the Turing test, p-value.


- 응용 서비스 : 기계 번역, 대화 시스템, 이미지 캡션
참고 사이트
wikidocs 19. 토픽 모델링(Topic Modeling)
paperswithcode
NLP 최신 트렌드
NLP


SOTA 모델소개 부분을 풀어서 쓴 점, 레퍼런스를 남긴 점 좋다고 생각합니다. 저는 과제양식 그대로 키워드만 적고 레퍼런스칸을 안만들었습니다.