큐란?
입력과 출력을 한 쪽 끝(front, rear)으로 제한

- FIFO (First In First Out, 선입선출) : 가장 먼저 들어온 것이 가장 먼저 나옴
- 큐의 가장 첫 원소를 front, 끝 원소를 rear라고 부름
- 큐는 들어올 때 rear로 들어오지만, 나올 때는 front부터 빠지는 특성을 가짐
- 접근방법은 가장 첫 원소와 끝 원소로만 가능
사용 예시
버퍼, 마구 입력된 것을 처리하지 못하고 있는 상황, BFS
함수
데이터 넣음 : enQueue()
데이터 뺌 : deQueue()
비어있는 지 확인 : isEmpty()
꽉차있는 지 확인 : isFull()
데이터를 넣고 뺄 때 해당 값의 위치를 기억해야 함 (스택에서 스택 포인터와 같은 역할)
이 위치를 기억하고 있는 게 front와 rear
front : deQueue 할 위치 기억
rear : enQueue 할 위치 기억
구현
//기본값
private int size = 0;
private int rear = -1;
private int front = -1;
Queue(int size) {
this.size = size;
this.queue = new Object[size];
}
//enQueue
public void enQueue(Object o) {
if(isFull()) {
return;
}
queue[++rear] = o;
}
enQueue 시, 가득 찼다면 꽉 차 있는 상태에서 enQueue를 했기 때문에
overflow 아니면 rear에 값 넣고 1 증가
//deQueue
public Object deQueue(Object o) {
if(isEmpty()) {
return null;
}
Object o = queue[front];
queue[front++] = null;
return o;
}
deQueue를 할 때 공백이면 underflow front에 위치한 값을 object에 꺼낸 후,
꺼낸 위치는 null로 채워줌
//isEmpty
public boolean isEmpty() {
return front == rear;
}
front와 rear가 같아지면 비어진 것
//isFull
public boolean isFull() {
return (rear == queueSize-1);
}
rear가 사이즈-1과 같아지면 가득찬 것일반 큐의 문제점
- 큐에 빈 메모리가 남아 있어도, 꽉 차있는것으로 판단할 수도 있음 (rear가 끝에 도달했을 때)
- 1차원 배열로 큐를 구현할 경우 삭제된 공간을 다시 사용하지 못함
이를 개선한 것이 '원형 큐'
논리적으로 배열의 처음과 끝이 연결되어 있는 것으로 간주함!
원형 큐는 초기 공백 상태일 때 front와 rear가 0
공백, 포화 상태를 쉽게 구분하기 위해 자리 하나를 항상 비워둠
(index + 1) % size로 순환시킨다.
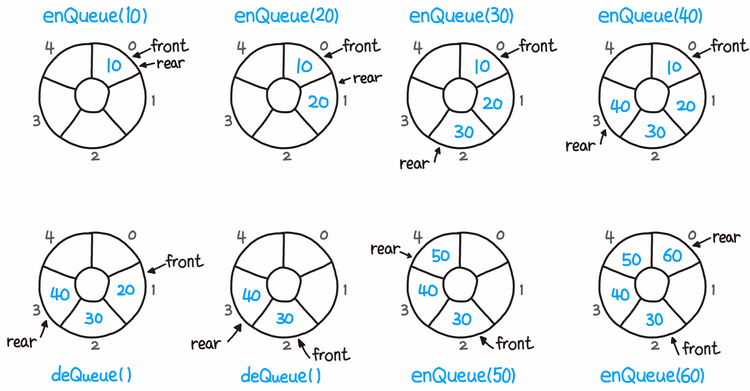
하지만, 이렇게 만든 원형 큐에서도 문제점이 발생한다.
원형 큐의 문제점
rear 다음이 front인 경우 문제가 발생한다. (즉, rear와 front의 위치가 같은 경우)
왜냐하면 꽉찬 상태와 텅빈 상태를 구분 할 수 없기 때문이다.
원형 큐의 문제 해결책
텅빈 상태와 꽉찬 상태를 구분해주면 된다.
텅빈 상태 : 초기화 상태로 rear와 front의 위치를 같을 때
꽉찬 상태 : rear 자리의 바로 다음자리가 front의 위치가 될 때
(즉, rear==front+1)
텅 비어있는 상태를 초기화 상태로 정의하고, 초기화 상태에서 F와 R은 같은 배열 index를 갖도록 설정
초기화 된 상태, 즉 F와 R이 같은 공간을 가리키는 상태를 Empty 상태로 정의
- 해당 상태에 해당 index에는 정보를 넣지 못함
- 메모리 손실!
- 하지만 일반적으로 배열의 길이가 매우 길어지므로 한 칸의 메모리 손실은 매우 적으며, 이로인한 코드상의 이점이 훨씬 크므로 의미있음!
R 바로 다음자리가 F가 되는 경우 Full 상태로 정의
원형 큐의 단점
메모리 공간은 잘 활용하지만, 배열로 구현되어 있기 때문에 큐의 크기가 제한
연결리스트 큐
연결리스트 큐는 크기가 제한이 없고 삽입, 삭제가 편리

# Node
class Node(object):
def __init__(self, data):
self.data = data
self.next = None
# Singly linked list
class SinglyLinkedList(object):
def __init__(self):
self.head = None
self.tail = None
# Add new node at the end of the linked list
def enqueue(self, node):
if self.head == None:
self.head = node
self.tail = node
else:
self.tail.next = node
self.tail = self.tail.next
def dequeue(self):
if self.head == None:
return -1
v = self.head.data
self.head = self.head.next
if self.head == None:
self.tail = None
return v
# 출력
def print(self):
curn = self.head
string = ""
while curn:
string += str(curn.data)
if curn.next:
string += "->"
curn = curn.next
print(string)
if __name__ == "__main__":
s = SinglyLinkedList()
# 원소 추가
s.enqueue(Node(1))
s.enqueue(Node(2))
s.enqueue(Node(3))
s.enqueue(Node(4))
s.print() # 1->2->3->4
# 원소 삭제
print(s.dequeue()) # 1
print(s.dequeue()) # 2
s.print() # 3->4
print(s.dequeue()) # 3
print(s.dequeue()) # 4