DFS(Depth First Search)
깊이를 우선으로 탐색을 수행하는 알고리즘
맹목적으로 각 노드를 탐색할 때 주로 사용
ex) 미로를 탐색할 때 한 방향으로 갈 수 있을 때까지 계속 가다가 더 이상 갈 수 없게되면 다시 가장 가까운 갈림길로 돌아와 다른 방향으로 다시 탐색하는 방법과 유사
<특징>
- stack을 사용하여 탐색
- 순환 알고리즘의 형태를 가진다
<장점>
- 현재 경로상의 노드들만 기억하면 되므로, 저장 공간의 수요가 비교적 적다
- 목표 노드가 깊은 단계에 있는 경우 해를 빨리 구할 수 있다
- 구현이 너비 우선 탐색(BFS)보다 간단하다
<단점>
- 단순 검색 속도는 BFS 보다 느리다
- 해가 없는 경우에 빠질 가능성이 있다
- 깊이 우선 탐색은 해를 구하면 탐색이 종료되므로, 구한 해가 최단 경로가 된다는 보장이 없다
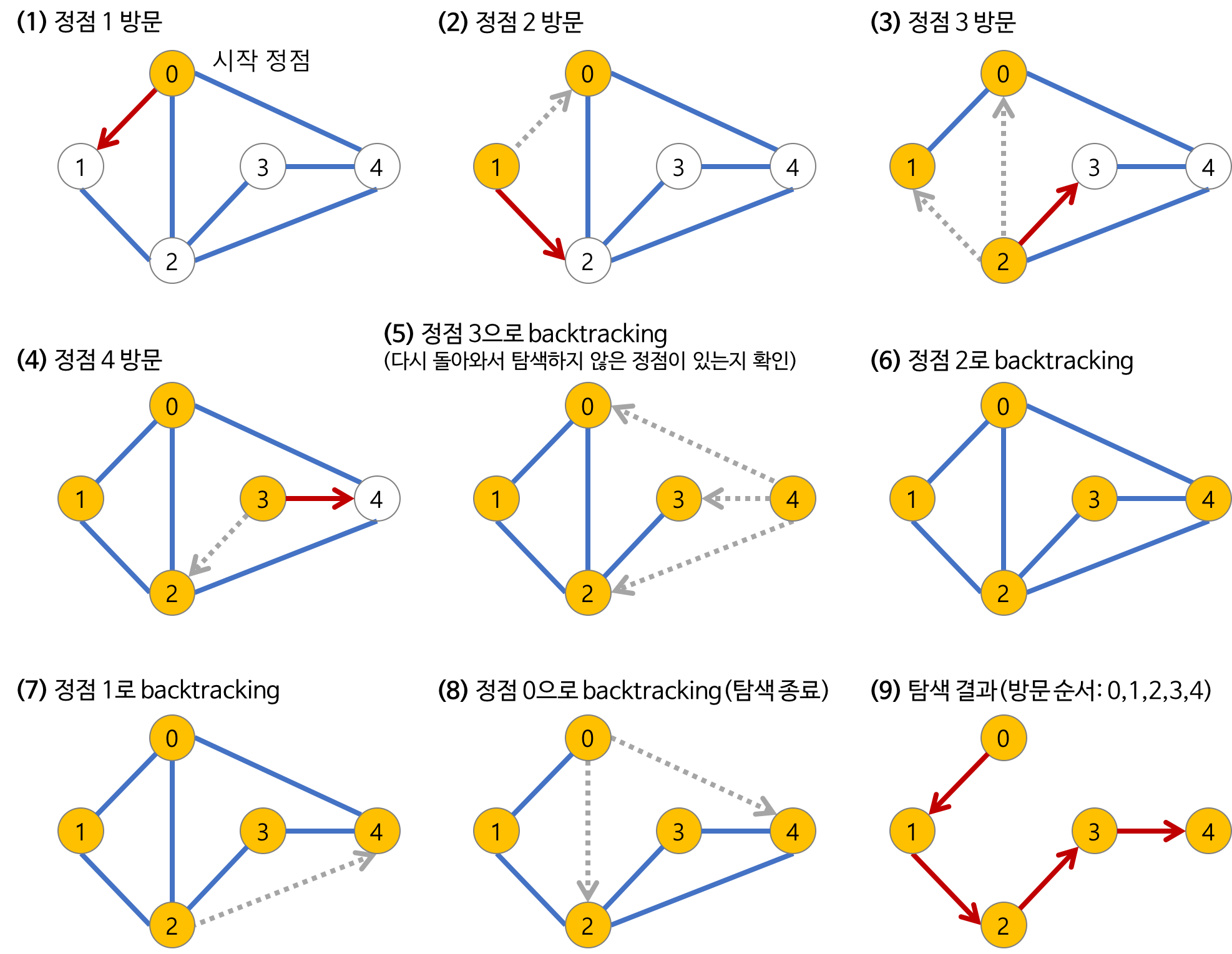
1. a 노드(시작 노드)를 방문한다.
- 방문한 노드는 방문했다고 표시한다.
- a와 인접한 노드들을 차례로 순회한다.
- a와 인접한 노드가 없다면 종료한다.
- a와 이웃한 노드 b를 방문했다면, a와 인접한 또 다른 노드를 방문하기 전에 b의 이웃 노드들을 전부 방문해야 한다.
- b를 시작 정점으로 DFS를 다시 시작하여 b의 이웃 노드들을 방문한다.
- b의 분기를 전부 완벽하게 탐색했다면 다시 a에 인접한 정점들 중에서 아직 방문이 안 된 정점을 찾는다.
- 즉, b의 분기를 전부 완벽하게 탐색한 뒤에야 a의 다른 이웃 노드를 방문할 수 있다는 뜻이다.
- 아직 방문이 안 된 정점이 없으면 종료한다.
- 있으면 다시 그 정점을 시작 정점으로 DFS를 시작한다.
작동 원리를 스택에 담기는 순서를 생각하며 다시 생각해보자
1. 루트 노드 1에서 시작하며 방문한 노드는 스택에 넣어준다 그리고 1과 연결된 노드 중 방문하지 않은 노드가 있는지 확인한다
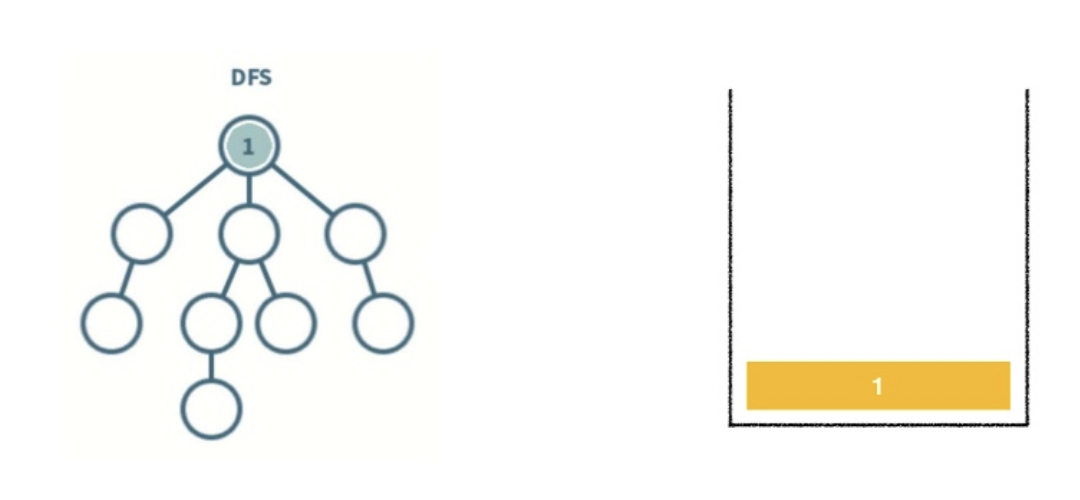
2. 아직 방문하지 않은 노드 2를 스택에 넣어준다 다시 2와 연결된 노드 중 방문하지 않은 노드가 있는지 확인한다

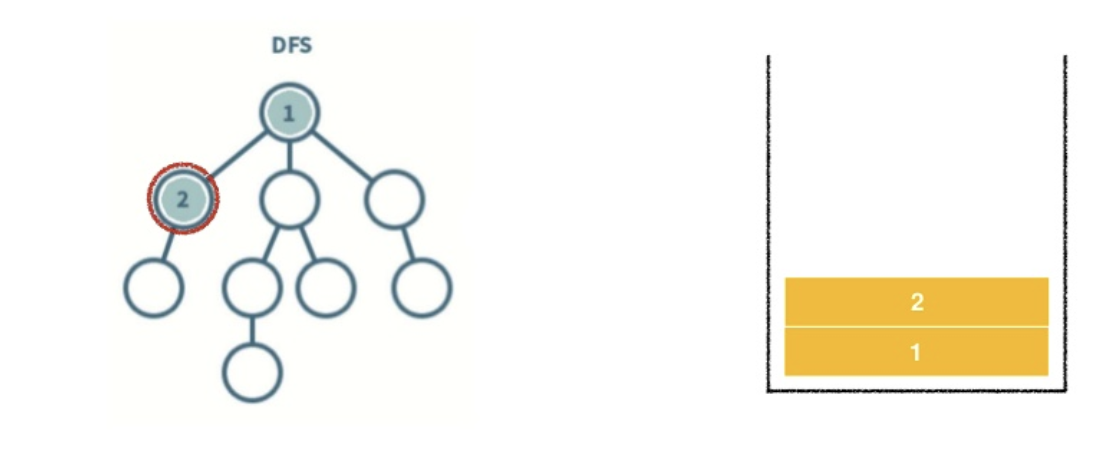
3. 노드 3을 스택에 넣어주고 방문하지 않는 노드가 있는지 확인한다
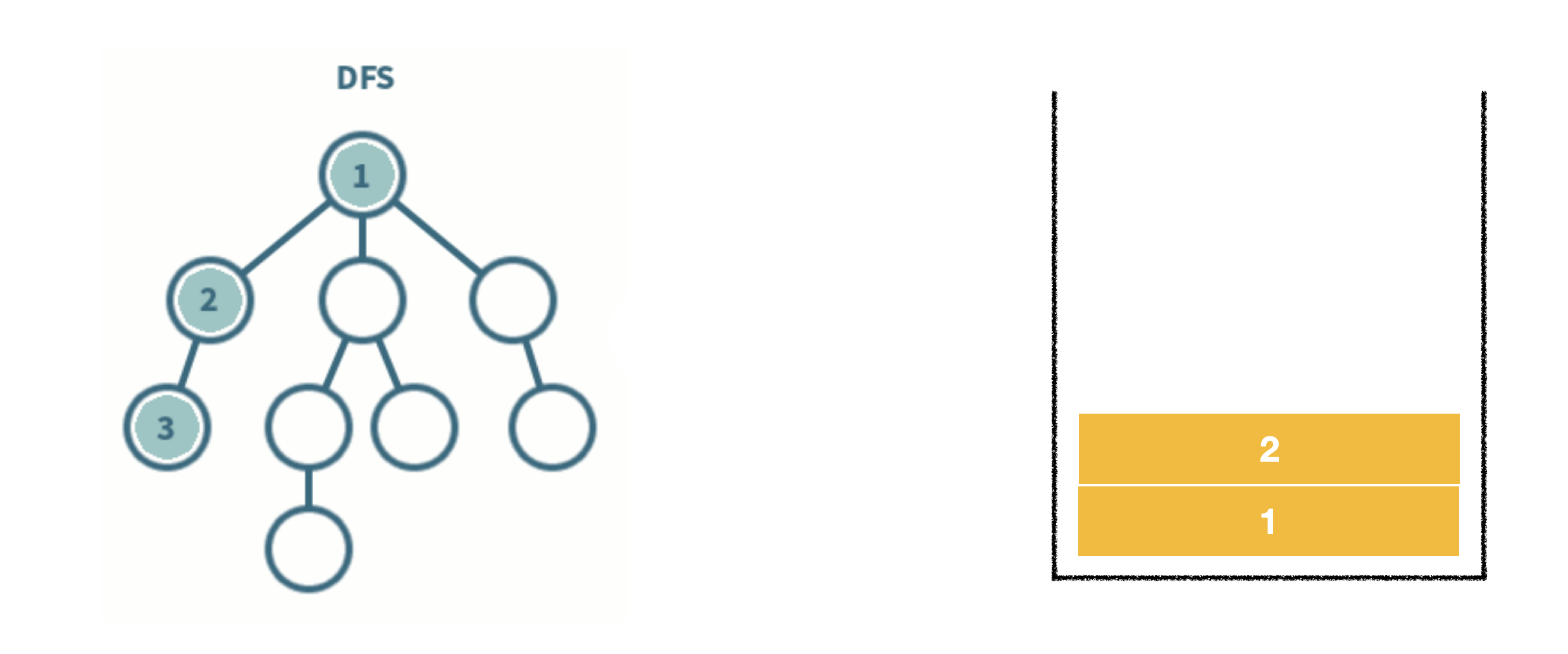
4. 노드 3과 연결된 노드는 2 뿐이며 이미 방문하여 이번 분기의 탐색이 완료되었으므로 3을 스택에서 빼준다(backtracking)
5. 노드 2 또한 연결된 노드 중에 방문하지 않은 노드가 없으므로 스택에서 빼준다(backtracking)
-> 위의 수행을 반복한다

6. 방문하지 않은 노드가 더 이상 존재하지 않으므로 1을 스택에서 제거한 후 탐색을 종료한다
<코드>
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int number = 7; // 노드의 개수
int c[7]; // 방문 처리를 위한 배열 생성
vector<int> a[8]; // 총 7개의 노드가 각각 인접한 노드를 가질 수 있도록 만든다
void dfs(int x) {
if (c[x]) return; // 그 노드를 방문했다면 함수를 끝낸다
c[x] = true; // 처음 방문하는 경우라면 방문 처리를 해준다
cout << x << ' '; // 방문한 노드를 출력한다
for (int i = 0; i < a[x].size(); i++) {
int y = a[x][i]; // 해당 노드와 붙어 있는 모든 노드를 하나씩 방문을 하면서
dfs(y); //dfs를 수행한다
}
}
int main() {
a[1].push_back(2);
a[2].push_back(1);
a[1].push_back(3);
a[3].push_back(1);
a[2].push_back(3);
a[3].push_back(2);
a[2].push_back(4);
a[4].push_back(2);
a[2].push_back(5);
a[5].push_back(2);
a[3].push_back(6);
a[6].push_back(3);
a[3].push_back(7);
a[7].push_back(3);
a[4].push_back(5);
a[5].push_back(4);
a[6].push_back(7);
a[7].push_back(6);
dfs(1);
cout << endl;
return 0;
}<DFS의 시간 복잡도>
- DFS는 그래프 (정점의 수 : N, 간선의 수 : E)로 모든 간선을 조회한다
인접 리스트로 표현된 그래프 O(N+E)
인접 행렬로 표현된 그래프 O(N^2)
즉, 그래프 내에 적은 숫자의 간선만을 가지는 희소 그래프의 경우 인접 행렬보다 인접 리스트를 사용하는 것이 유리

Hello World!