DB설계의 판단기준
무결성
기본적으로 데이터가 의도에 따라 일치되어 저장되고, 가짜 데이터, 필요없는 데이터가 없어야 좋다.
한 관심사에 대한 데이터로만 한 테이블을 구성하기
-
중복 데이터 생성
-> 저장 공간 낭비, 데이터 간의 불일치 가능성이 높아짐
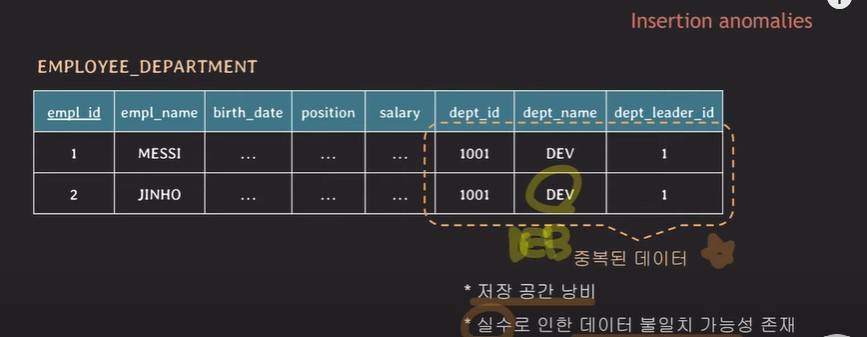
고용자 정보 - 부서 정보를 한 테이블에 같이 저장하게 되면 위와 같이
중복된 데이터를 저장하게 될 수 있다. -
부분적 insert,delete,update로 인해 null값을 저장할 가능성이 높아짐
- spurious tuples(가짜 데이터) 생성을 피하기 -> 적절한 값을 통해 join하자
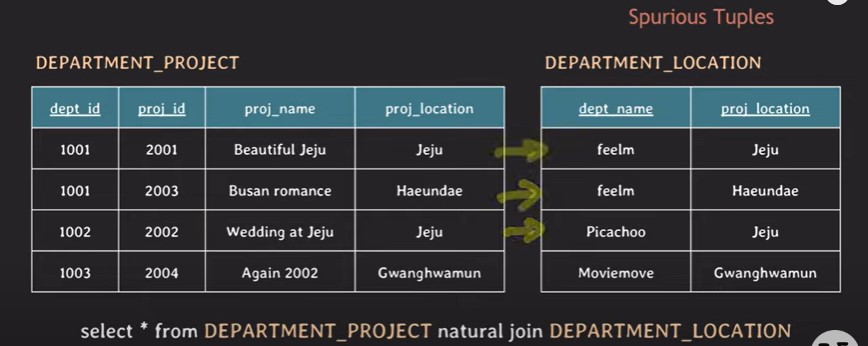
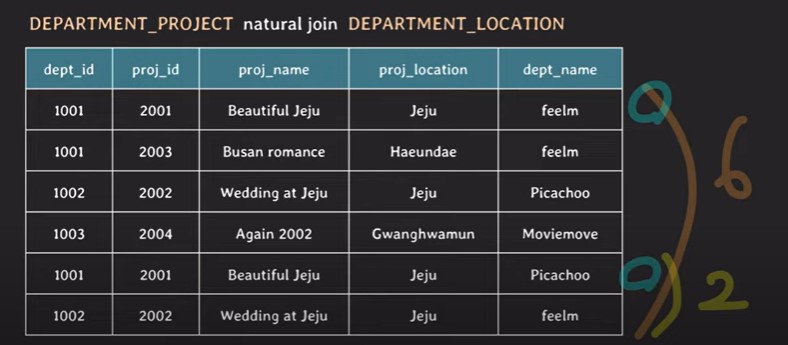
위 그림처럼 proj_location을 통해 join하면 jeju에 매핑되는 2개의 가짜 데이터가 새로 생성되어 잘못된 값을 저장하게 된다.
때문에 아래와 같은 원칙을 고려해 db를 설계하자. 이는 정규화의 원칙이랑 일맥상통하기도 한다.

유연성
레코드의 변경, 나아가 colum의 변경 시에 구조적 변화를 최소화하도록 설계되면 좋다.
예를 들어 다중 값, 다중 부분 필드는 데이터의 변경이나 그룹화가 어렵기에 이를 고려해 지양하는 선택을 할 수 있다.
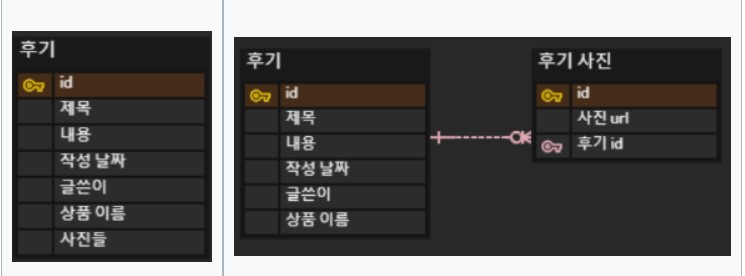
위 그림처럼 사진들을 다중값으로 설계하면 조회 시에도 like문을 사용하는 것과 같은 추가적 작업이 필요하고 데이터 변경 시에도 다른 사진까지 변경할 위험이 있다. 때문에 테이블을 분리해 설계한다.
확장성(장래성)
장래성,확장성을 고려해 설계를 하면 뒤늦게 불필요한 재설계를 할 필요가 없어진다.
예를 들어 상품의 카테고리를 처음에 한 상품을 한 카테고리에 속하도록 설계할 수도 있다. 하지만 동일 상품에 여러 카테고리가 적용된다던지, 카테고리가 계층적으로 세분화될 수 있다던지의 가능성을 열어놓고 설계를 하는 편이 비즈니스의 확장에 좋다.
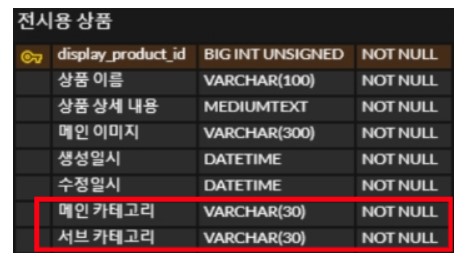 위처럼 카테고리을 상품의 column으로 둘 수는 있지만, 유연성/확장성이 부족하다.
위처럼 카테고리을 상품의 column으로 둘 수는 있지만, 유연성/확장성이 부족하다.
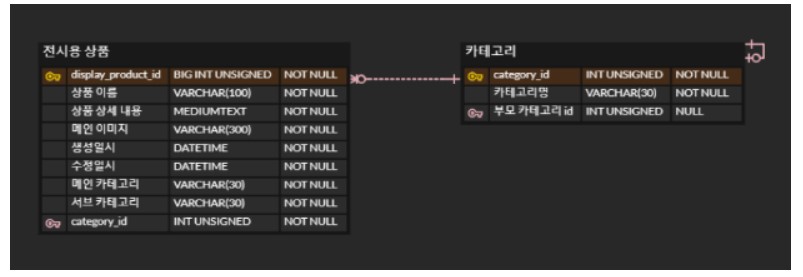
위와 같이 자기참조를 통해 카테고리의 확장성을 높일 수 있다.
다른 예로 상품에 할인을 적용한다고 할때, 할인 정책은 정액할인/할인율에 따른 할인/기간 할인 등의 변화가 생길 수 있다.
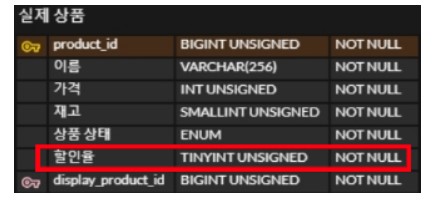
때문에 아래처럼 할인에 대한 테이블을 분리하는 설계가 도움이 될 수 있다.

위와 같은 확장성/비즈니스의 변화를 고려하려면 위해 도메인에 대한 이해 또한 필요하다.
- 정규화 과정에서 재이용의 가능성이 높은 데이터를 별도의 테이블로 분리하기는 하지만, 성능적 요구에 따라 (데이터의 변경이 거의 없는 대신 대부분 검색용으로 사용된다던지) 정규화하지 않을 수도 있다.
요건에 없는 시스템에서의 필요기능 상정
도메인적 지식에 영향을 받는 부분이기도 하지만, 요구사항에는 없지만 비즈니스적으로 필요할 것으로 예상되는 것 까지 설계에 반영할 필요가 있다.
예를 들어 회원이 상품을 주문하는 사이트의 db설계의 경우,
상품등록 시에 /등록한 사람에 대한 데이터가 필요할 수도 있고
/주문이 된 상품을 상품 테이블에서 삭제할 경우 대처가 필요할 수도 있다.
위와 같은 고려사항 때문에 /상품에 등록자 컬럼을 추가/물리삭제를 해버리기에는 위험한 레코드에 논리 삭제 flag 컬럼을 추가와 같은
고려를 해야한다.
넷플릭스 db유추를 통한 학습
넷플릭스의 db구조는 대략 어떤 식일까.
위 그림처럼 학 영상물에 보이는 정보는
id,제목,설명,출연진.. 등의 column이 있을 거라 예상 가능하다.
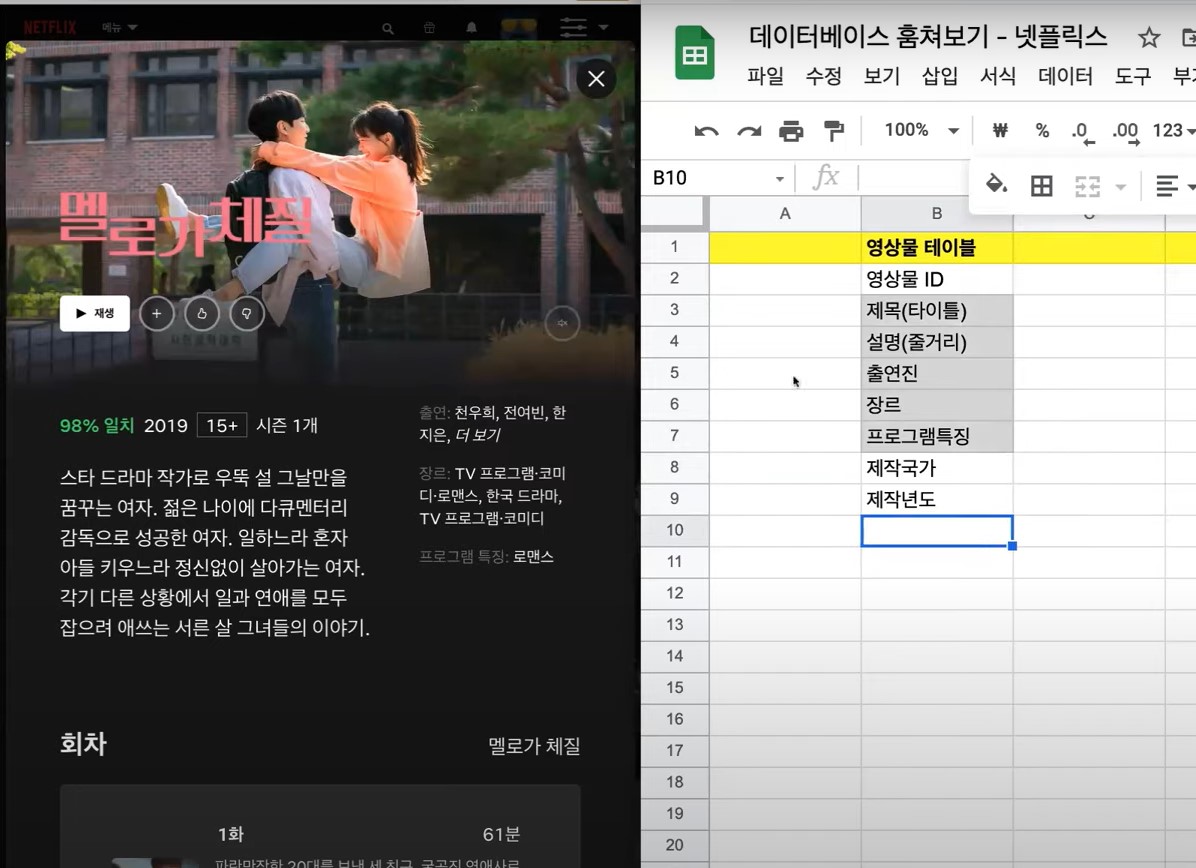
하지만 넷플릭스는 다국가-다언어 플랫폼이기에 여러 언어에 대한 데이터가 필요하다. 때문에 아래처럼 영상물의 요소마다 테이블이 분리되어 각 언어에 대한 column으로 구성될 수 있다.

- 새로운 국가에 대해 서비스를 확장하는 것으로 가정하자. 이 경우 테이블들에서 새 국가에 대한 colum이 추가될 것이다.
확장 시에 db의 레코드 확장 > column의 확장 > 테이블들의 구조 변경 순으로 지향해야 될 변경점이다. 즉 서비스 확장 시에도 테이블들의 구조적 변경이 아닌 레코드만이 변경되는 것이 이상적인 상황이다.
일대다 관계에서 다 인쪽이 참조키를 가지며 별개의 테이블로 분리해 데이터를 가진다는 개념은 알았지만 이렇게 한 데이터를 여러 형식으로 저장할 때도 분리할 수 있겠구나- 알아두어야겠다.
내 생각으로는 위처럼 다언어 저장을 위해 테이블을 나눈다면
한 영상물에 대한 정보 조회 쿼리마다 너무 많은 테이블을 join해야 되지 않을까해 비효율적일 것 같다.
다언어를 위한 저장은 넷플릭스 접근 시에 국가부터 선택하기에 db또한 국가 별로 분리되 저장되는게 효율적일 것 같다는 예상을 한다. 이렇게 한다면 데이터의 insert와 변경 시에 여러 db에 걸쳐야 하므로 데이터 변경의 효율성은 떨어지겠지만, 조회는 더 빠르게 할 수 있어 플랫폼의 성격에 더 적합하지 않을까한다.
어찌보면 DB의 유연성보다 성능을 우선한 발상이라 현실적이지 않을 수 있다. 혹은 내가 전혀 모르는 방식으로 구성되어 있을 수 있겠다.
REFERENCE
https://www.youtube.com/watch?v=JwfQ8ouhAzA //youtube 쉬운코드
https://www.youtube.com/watch?v=Wpy28DU4Sbc
https://engineer-mole.tistory.com/298
https://velog.io/@sontulip/how-to-db-design
