프로세스와 스레드 실행 시 cpu,메모리 수준에서 어떤 동작을 하는 지와
이 실행흐름들을 concurrent, 병렬적으로 실행할 때의 문제 해결
-> 동기화 방법들에 대해 알아보겠습니다.
- 프로세스
- 메모리 로드영역
- 프로세스 상태관리(process state, pcb)
- context switching 과정
- 스레드
- 멀티 스레딩의 장점, 극복할 점
- 스레드의 종류: user thread, (os thread)kernal thread, hardware thread
- 동기화
- 임계영역
- 동기화 툴
프로세스와 스레드
프로세스
프로그램이 실행된다는 것 (프로세스가 실행)은 디스크에서부터 일련의 명령어들이 메모리에 올라와 cpu를 통해 연산되고 다시 메모리,디스크에 저장되는 것을 말한다.
디스크 -> 메모리 -> cpu -> 메모리 -> 디스크로 명령어와 데이터들이 이동,수행되는 과정이다.
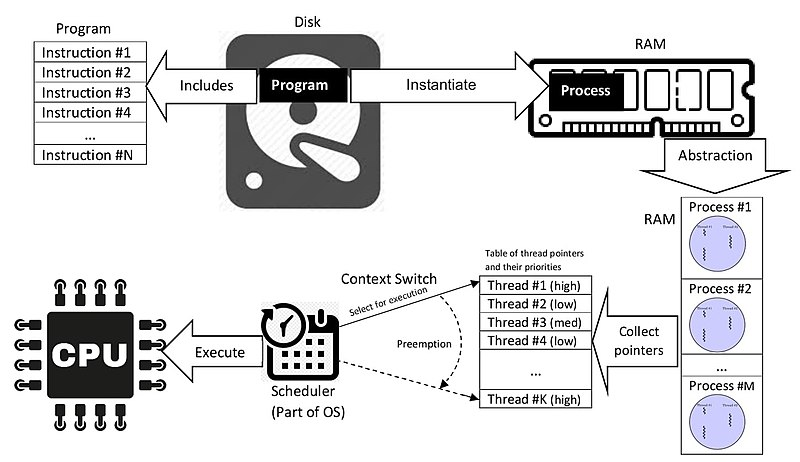
좀 더 자세히 알아보자.
프로그램 파일은 실행 전에는 디스크에 저장된 0,1의 집합체일 뿐이다.
메모리에 이 데이터가 적재된 후 cpu의 제어장치에 도달해 해석(decode)되면서부터 의미를 가지고 동작을 수행한다.
때문에 프로그램을 실행하면 우선 메모리를 할당하는 로드 과정을 수행한다.
프로세스 메모리 로드
아래와 같은 흐름이다.
1) 프로그램 코드와 정적 데이터(static data)들을 메모리에 적재한다.
이 과정에서 프로그램 실행 시에 모든 코드와 데이터를 메모리에 로드할 수도 있겠지만, 이는 많은 boot strap시간을 소요해야 하므로 우선 중요한 일부만 로드한다. (dynamic loading)
2) 해당 프로그램이 사용할 스택 공간을 메모리에 마련해야 한다.
지역변수, 함수 인자, 리턴 주소등을 저장하는 용도이다.
3) 프로그램의 힙(heap) 메모리 영역도 할당한다.
4) 해당 프로그램의 입출력을 위한 파일 디스크립터(file descriptor)도 생성한다.
5) 프로그램 시작점( main()함수 )부터 프로그램 코드의 명령어를 cpu의 레지스터로 올리고 연산하는 등의 작업흐름 시작.
메모리는 위에서 알 수 있듯 여러 개의 섹션으로 나눠져 있다.
- text section
- data section
- heap section
- stack section
text 섹션에는 기계어로 번역된 명령어들이 올라오고,
data 섹션에는 전역변수, 정적 변수들이 저장된다.
BSS 섹션에는 초기화 되지 않은 전역,정적 변수들이 저장된다.
heap 섹션은 프로그램에서 동적으로 할당하는 메모리 공간 (c의 malloc, 자바의 컬렉션, new ... )이다.
stack 섹션은 함수의 인자,지역변수,반환주소 등이 저장된다.
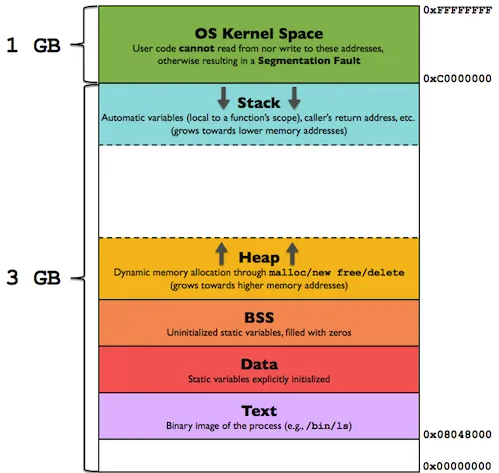
프로세스 실행 시 메모리의 이슈들
그런데 메모리에 올라왔다고 해서 각 프로세스들의 모든 명령어들이 동시에 cpu를 사용하며 실행되는 것은 물리적으로 불가능하다. 또한 디스크의 모든 데이터들이 한번에 메모리에 올라와 있는 것도 용량의 차이 때문에 불가능하고 메모리를 최대한 효율적으로 사용하기 위한 전략이 필요하다.
이런 시간적, 공간적 한계를 극복하기 위한 전략을 고민하면서
context switching,
메모리 페이징,
실행흐름 간의 메모리의 보호
같은 이슈가 생겨난다.
time sharing 전략을 사용해 빠르게 각 프로세스들이 cpu를 번갈아가며 점유해 마치 동시적으로 프로세스를 실행하는 듯한 효과를 내는데 이것이 context switching이다.
이 관리를 위해서는 프로세스의 상태, context switching 직전 프로세스가 하던 작업에 대한 정보 저장이 필요하다. 컨텍스트 스위칭 전까지 프로세스 자신이 어떤 작업을 하고 있었는지까지도 기억해야 다시 돌아와 하던 작업을 할 수 있다.
메모리에 cpu에서 필요한 데이터들을 효율적으로 선택해 올려놓기 위해 페이징, 페이징 교체 알고리즘 을 이용한다.
각 프로세스들이 자신에게 매칭된 메모리 영역은 어디부터 어디까지인지(protection of memory), 이 메모리 영역은 어떻게 표현하고 가상의 주소와 물리적인 주소를 매칭할 지(address binding)도 고민하게 된다.
하나하나 알아가보자.
프로세스의 상태
프로세스는 관리되기 위해 상태,생명주기를 가진다.
이 프로세스가 i/o 작업을 기다리고 있는지, 다시 로드해 실행이 가능한 상태인지를 알아야 스케줄링으로 cpu연산을 최대한 활용할 수 있다.
NEW / RUNNING / WAITING / READY / TERMINATED
상태를 가진다.
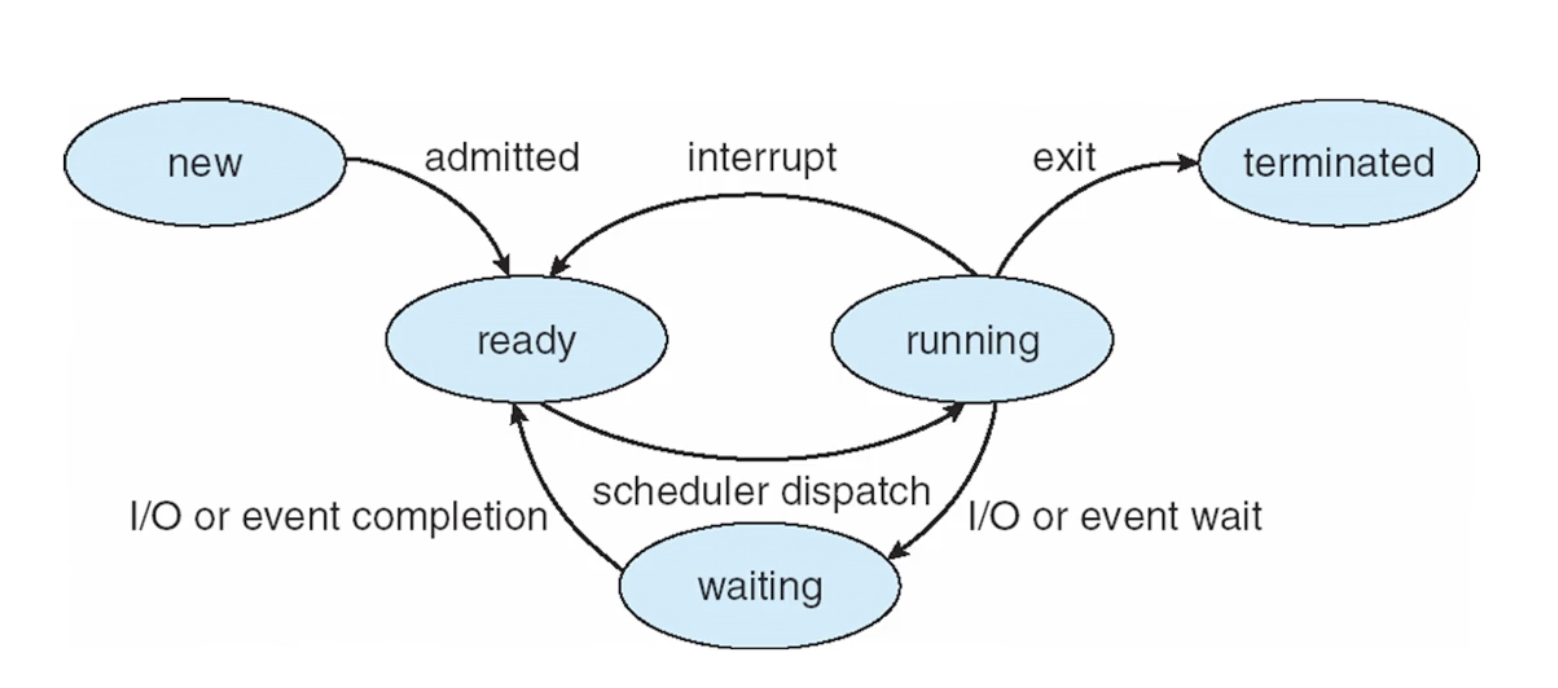
WAITING은 디스크 I/O, 마우스 키보드 I/O등의 등의 이벤트를 기다리는 상태이다.
READY는 cpu로의 할당(RUNNING)을 기다리는 상태이다. 즉 스케줄링에 의해 RUNNING되지 않고있는 상태이다. 모든 프로세스가 동시에 cpu를 점유할 수는 없는일이기에 생기는 상태인 듯하다. READY 상태가 된다는 것은 ready queue에 들어간다는 것이다.
그러면 이 프로세스의 상태를 어떻게 저장해서 관리할까?
상태변경, 문맥교환 시에 PCB(process control block) 에 필요한 정보를 저장하며 이용한다.
PCB(process control block)
pcb는 os의 커널 메모리 영역에 저장되는 프로세스 관련 정보이다. PCB에는 프로세스의 상태, 프로그램 카운터, CPU 레지스터 값, 메모리 관리 정보, 스케줄링 정보, 입출력 상태 정보 등 문맥교환 시 필요한 정보들이 저장된다.
- process state
- program counter(PC): 다음으로 어떤 명령어를 실행해야 하는 지 저장해여 스케줄링에 의해 cpu점유에서 벗어나더라도 다시 해당 프로그램의 명령어 흐름으로 pc를 통해 들어올 수 있다.
- cpu registers: cpu에서 쫓겨났을 당시에 레지스터에 어떤 값이 있었는지도 기억해두어야 다시 cpu를 점유했을 때 명령어 흐름을 이어갈 수 있다.

이 PCB는 어떻게 교체될까? cpu코어에서 이 pcb에 어떻게 접근하지?
이건 컨텍스트 스위칭의 과정을 알아야 이해가 될 듯하다.
컨텍스트 스위칭 과정
문맥교환 시 인터럽트가 발생하면 os커널이 실행흐름을 잡고 문맥교환을 시작한다.
os 커널의 메모리 영역의 프로세스 테이블에는 각 프로세스의 pcb가 메모리 어디에 위치하는 지를 저장하기에 해당하는 프로세스의 pcb 위치를 알 수 있다.
아래와 같은 과정을 거친다.
- 타이머 인터럽트, i/o를 위한 인터럽트 등의 이유로 인터럽트 신호 발생
- 제어장치가 이 인터럽트 신호를 받아 인터럽트 서비스 루틴(isr) 수행하는 과정에서 기존 프로세스의 pcb 정보 저장.
- 스케줄링에 따라 다음 프로세스 선정
- 다음 프로세스의 pcb를 레지스터에 적재, mmu의 ptbr 레지스터 값 수정.
- 변경된 레지스터를 이용해 연산 수행.
즉 컨텍스트 스위칭의 과정은 메모리의 pcb를 갱신하고 레지스터에 적재하는 등의 작업이 일어난다. 메인 메모리에 접근할 수 밖에 없는 작업이기에 문맥교환 시 비용은 무시할 수 없는 수준이다.
더 싸게 꼭 필요한 메모리 영역과 레지스터값만 교체해 실행흐름을 바꿀 수는 없을까?
이것을 스레드로 이룰 수 있다.
스레드
흔히 스레드를 프로세스 내에서 text,data,heap 영역을 공유하는 작은 실행흐름이라 한다. 스택 메모리 영역만 따로 쓰는 프로세스보다 작은 최소의 실행흐름이다.

정리하면 위 같이 공유하는 메모리 영역,그로 인한 실행흐름끼리의 통신방법, 문맥교환 시 비용의 차이가 있다.
스레드는 그러면 프로세스의 자원(heap,data,text 메모리)을 공유하며 cpu의 코어들이 다른 실행흐름을 수행하는 것인데 이게 어떻게 가능할까?
메모리 관점에서 프로세스랑 스레드는 무슨 차이가 있을까?
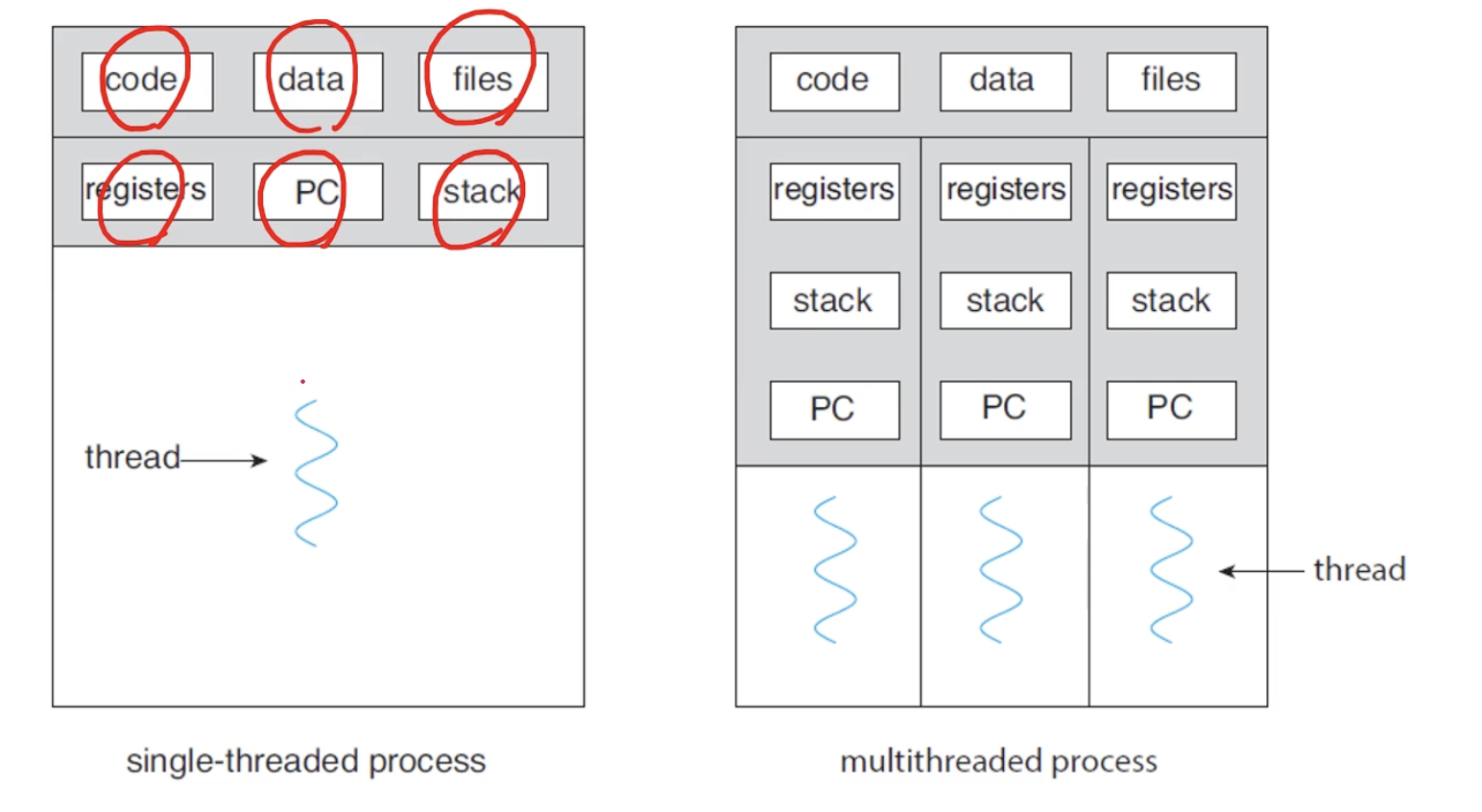
결론부터 말하자면 프로세스의 스레드는 코어의 alu와 레지스터가 접근하는 context(맥락)의 차이가 있다.
이 맥락은 메모리 보호(protection of memory)를 위해 접근하는 페이지 테이블, pcb, tcb(thread control block)을 말한다.
tcb에는 스레드의 id, 해당 스레드의 스택영역의 주소 등을 저장한다. pcb내에서 값 자체를 가지고 있거나 참조주소를 저장할 수도 있다.
프로세스는 같은 pcb, ptbr과 page table을 사용하는 실행흐름이고,
스레드도 heap,data,text 영역을 공유하기에 같은 pcb를 사용하지만 pcb 내의 TCB(thread control block)는 달라지고, 달라진 tcb 내에서 참조하는 스택 영역도 다르다.
이건 몰랐던 사실인데, 스레드의 스택 영역은 protection of memory가 안되어 있는 듯하다. 즉 스레드는 각자 스택 영역을 따로 쓰기는 하지만 같은 프로세스라면 서로의 스택영역에 접근은 가능하다.
https://stackoverflow.com/questions/30989192/protecting-thread-local-storage-of-a-thread-from-other-threads
이에 대해서는 페이징과 메모리 보호에 대해 알면 더 이해될 것이다.
다음 포스팅에서 이에 대해 설명한다.
https://velog.io/@ttomy/%EB%A9%94%EB%AA%A8%EB%A6%AC%EC%9D%98-%EC%A3%BC%EC%86%8C%EC%B2%B4%EA%B3%84%EC%99%80-%ED%8E%98%EC%9D%B4%EC%A7%80
스레드의 종류,하이퍼 스레딩
스레드는 alu와 레지스터가 사용하는 메모리 영역이 다른 최소의 실행흐름들이라 말했다. 그러면 스레드는 코어의 개수 이상으로는 concurrnet하게 실행될 수 없는걸까?
한 코어의 효율 향상을 위해 여러 코어에 작업을 분산하는 기술(하이퍼 스레딩)을 통해 코어 개수보다도 많은 스레드의 사용이 가능해졌다.
코어가 하나라도 그 안에 레지스터의 집합을 더 만든다면, 한 스레드의 메모리 접근 작업 동안에는 다른 스레드의 레지스터 집합을 통해 alu로 연산하는 작업을 한다면 여러 개의 스레드를 실행할 수 있다. -> 하드웨어 스레드
- 하드웨어 스레드 : cpu에서 concurrent하게 실행되는 스레드 (물리적으로 같은 레지스터 집합을 사용하는 스레드)
- os 스레드 : 스케줄링의 단위가 되는 스레드
- 유저 스레드 : 프로그램 레벨에서 추상화된 스레드, os 스레드와의 관계에 따라 아래로 나뉜다. 한 os 스레드 위에서 사용자 레벨에서는 여러 실행흐름을 만들어 실행하도록 구현할 수 있다.
- one to one ( java의 thread, runnable)
- many to one
- many to many
- 그린 스레드 : 유저 스레드와 비슷한 맥락. os레벨이 아닌 프로그램 레벨에서 스케줄되는 유저 스레드를 말한다.
프로세스, 스레드의 동기화 - 임계영역
프로세스, 스레드들이 데이터를 공유하며 concurrent, 병렬적으로 작업하면 data inconsistency문제가 발생. -> 작업들의 순서를 보장해야 한다.
ex) producer - consumer 문제에서 일종의 갱신유실(lost update가 발생한다)
이 해결을 위해서 동기화를 해야하는데 이를 위해 임계영역 (critical section)을 구현한다.
임계영역은 entry section, critical section, exit xection, remainder section 으로 나눌 수 있다.
임계영역에 특정 시간에는 임계영역에 특정 실행흐름만 접근하도록 제한하는 식으로
상호배제를 구현하다보면 해결해야 하는 문제가 있다.
deadlock과 starvation이다.
임계영역 문제( deadlock, starvation(기아) )의 해결법들
- 싱글 코어에서의 가장 간단한 방법으로는 임계영역에 들어간 실행흐름이 있는동안은 다른 실행흐름이 들어올 수 없고, 실행흐름이 알아서 반납하도록 만드는 방법이다.(비선점형 스케줄링)
해당 instruction을 fetch, execute, store하는 동안은 interrupt 불가능하게 하기.
하지만 이런 비선점형은 다른 실행흐름이 기다리는 것밖에 할 수 없기 때문에 성능의 개선이 힘들다.
그래서 다른 알고리즘들을 고안한다.
- 데커 알고리즘
- 아이젠버스 맥과이어 알고리즘
- 피터슨 알고리즘
...
피터슨 알고리즘
flag, turn이용한 이중의 entry-section검증으로 임계영역의 접근을 제어한다.

flag만으로는 서로 동시에 true바꾸고 임계영역에 들어갈 수 있으니 0 아니면 1값을 가질 수 밖에 없는 turn변수로 이중의 검증을 한다.
https://www.youtube.com/watch?v=r3Ma_4_vF2s
이 영상에서 잘 설명해주었다.
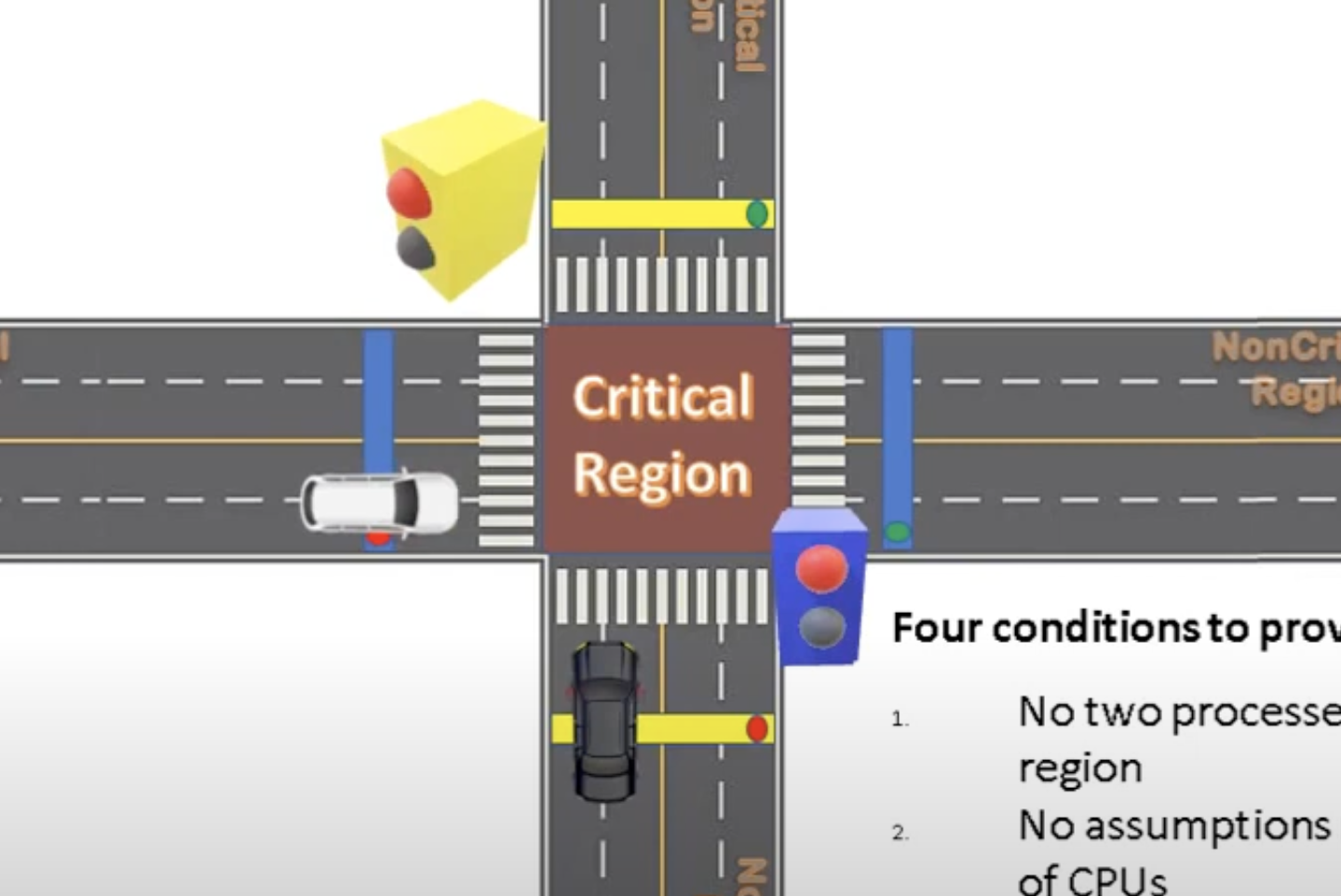
자동차는 횡단보도 앞의 선과 신호등을 통해 임계영역에 충돌없이 진입할 수 있다.
그런데 이 알고리즘은 기계어 레벨에서 생각하면 문제가 생기는 경우가 있다!
turn변수의 검증은 코드레벨에서야 한번에 이뤄지는 것 같이 보이지만 기계어로 보면 여러 instruction으로 수행될 수 있다.
이 instruction 수행 사이에 컨텍스트 스위칭이 일어나면 둘다 임계영역에 접근하는 상황이 존재한다....
ex) 한 스레드에서 turn의 동일성 검증 명령어까지 실행하고 문맥교환 후 바로 다른 스레드에서 turn에 값 적재하는 명령어 수행 후 동일성 검증하면 감쪽같이 두 스레드가 다 임계영역 접근
이를 해결하기 위해 1클락만에 명령어가 실행되도록 하드웨어의 지원을 통해 보완할 수 있다.
-
atomic instruction
하드웨어의 지원을 받아 atomic한 inctruction 단위를 만들어준다.
ex) value++(test_and_set()), swap(compare_and_swap())같은 연산을 하드웨어의 논리회로를 통해 1클락에 연산할 수 있도록만든다. -
atomic variable
이런 연산 (test_and_set()), swap(compare_and_swap()) 을 이용해 atomic variable을 만들어 사용할 수 있다.
-> java 의 atomicBoolean
동기화 툴 - 뮤텍스, 세마포어, 모니터
피터슨 알고리즘이나 atomicBoolean은 저수준에서의 동기화 방법들이다.
사용자레벨에서 임계영역을 더 쉽게 다룰 수 있는 방법들로
뮤텍스, 세마포어, 모니터가 있다.
- mutex lock

lock의 획득과 해제로 임계영역을 보호한다. 이때 피터슨 알고리즘과 마찬가지로 available은 atomic해야 동시적인 연산에서도 정상동작할 것이다.
때문에 역시 test_and_set()과 compare_and_swap()과 같은 것을 통해 하드웨어의 도움을 받아 atomic variable로 만든다.
이 경우 busy waiting으로 인해 cpu자원을 계속 사용한다. 스핀락이 걸려있는 상태이다. 스핀락은 코어가 여러 개 여서 cpu자원의 여유가 있는 상황이라면 ready queue로부터 컨텍스트 스위칭하는 비용 없이 임계영역에 진입할 수 있다는 장점이 있다.
하지만 이 경우 starvation의 위험이 있다.
그리고 임계영역에 들어갈 수 있는 실행흐름이 1개뿐이다.
- 세마포어(semaphore )
S개의 실행흐름이 임계영역에 들어가게 만들어보자.
개수를 test(wait())하고 signal(V())하는 방식으로 구현한다.

이 S도 운영체제에서 atomic한 숫자 변수로 구현한다.
스핀락을 통해 cpu자원을 소모한하는 방법이 아니라 스케줄링을 통해 wait queue, ready queue를 이용해 구현하는 방식도 있다.

다만 임계영역에 여러 실행흐름이 접근할 경우 race condition이 여전히 발생할 수 있다는 걸 인자하고 사용해야한다.
세마포어는 잘못된 방식으로 사용할 수 있다는 위험도 있다.

세마포어 사용자가 만약 wait()하지 않고 signal()을 호출하거나, signal()없이 wait()해버리면 임계영역에 의도하지 않은 수의 실행흐름이 접근할 수 있다.
때문에 좀 더 다루기 쉽고, 안전한 사용자 레벨의 툴을 개발하는데 이것이 모니터이다.
- 모니터(monitor)
상호배제를 구현하는 데이터 타입이다.
- 프로그래밍 언어의 synchronized
ex) java synchronized

안녕하세요 블로그글 을 통해 많은 부분을 배우고 있는 취준생입니다
제가 이번에 스프링 자바로 프로젝트를 하게 되었는데 , 전체적인 코드 흐름이라던지 사용법이 막막해서
혹시 실례가 아니면 제가 ttomy님 깃허브 주소를 주시면 제가 코드를 보고 좀 배울 수 있을 까요?