4.1 introduction
컴파일러에 대한 기본 원리만 설명하겠다
앞,뒤단계 로 2단계가 있다.
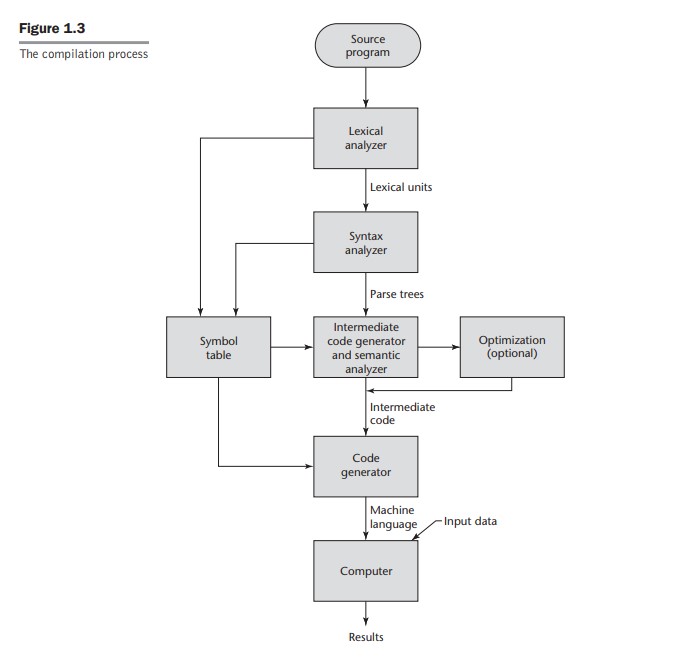
소스코드-lexical analyzer-syntax analyzer- 중간코드
- code generator
사실 syntax analyzer는 lexical과정과 연결되어 한 과정으로 이뤄진다.
lexeme마다 tocken(품사)이 있다.
소스코드를 해석하는 3가지 방식이 있었다.
컴파일,퓨어 인터프리터,(하이브리드->JIT)
4.2 lexical analysis
lexical 분석은 패턴찾기이다.
그 언어의 사전에 있는 패턴을 찾는다.
i am a boy.
Lexical analyzers extract lexemes from a given input string and produce the corresponding tockens.
어휘를 찾고, 품사를 찾아서 syntax를 분석한다.
주석(comment)는 생략한다. identifier는 symbol table이라는 곳에 등록한다. 어떤 변수가 symbol table에 없다면 에러가 난다.
- lexical analyzer의 역할
lexeme을 찾아 거기에 대한 tocken을 붙여서 syntax analy로 보내기
코드 스킵/ space,주석 등
심볼 테이블에 identifier 등록
프로그래머가 잘못 쓴 어휘들 찾아냄
lexical analyzer를 만드는 3가지 접근(state transition diagram)
- state transition diagram을 디자인한다.
states, input, action이 있다.
어떤 상태에서 특정동작을 하고,input을 통해 상태를 바꾼다.
A state transition diagram, or just state diagram, is a directed graph. The nodes of a state diagram are labeled with state names. The arcs are labeled with the input characters that cause the transitions among the states. An arc may also
include actions the lexical analyzer must perform when the transition is taken.
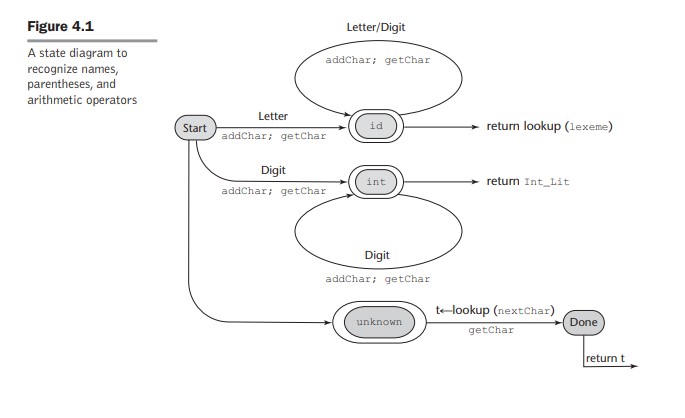
letter나 digit이외의 unknown이 들어오면 identifier가 끝났다고 생각한다. 그러면 다시 start로 간다.
193쪽 아래의lex()함수는 switch문으로 구현되 lexeme을 찾는다.
letter,digit,unknown,EOF
4.3 parsing problem
syntax analysis과정은 parsing이라고도 한다.
두 단어는 interchangeable하다.
parser는 parse tree를 그린다.
parsing의 목적은 주어진 프로그램이 문법에 맞게 짜여졌는가 확인.
analyzer가 에러를 발견하면 diagnostic(진단적) 메시지를 내보내고 recover하여 다음의 코드들 까지 analyze하여 에러를 한번에 찾을 수 있다.
최근의 컴파일러는 에러 뒤의 내용까지도 컴파일해 에러를 한꺼번에 알 수 있다(recover).
parsing의 방법은 크게 2가지이다.
rule의 오른쪽을 handle이라함.
bottom up에서는 handle을 reduce한다.
top-down
LL parsing
parse tree의 루트(최상위)부터 시작해 아래로.
parse tree를 preorder로 만든다.
->non terminal들을 왼쪽부터 처리한다.
topdown방식에서는 언어의 구현이 함수들의 호출로 이뤄진다.
198p 예- <>로 썻던 터미널을 간단히 하기위해 대문자로 나타냄
bottom-up
LR parsing
bottom-up방식은 코드를 품사로 바꾸어 해석한다.
아래에서부터 rule의 오른쪽과 같은것(handle) 찾으면 왼쪽것으로 치환해가며 위로 올라간다(역치환).
4.4 recursive-descent parsing
대표적인 top-down parse방식이다. LL 알고리즘이라고도 한다.
non-terminal들이 함수가 되어 연쇄적으로 호출됨
199-함수들을 보면 알 수 있다.
4.5 bottom-up parsing
207p
LR 알고리즘이라 한다. right most derivation
LR parser
knuth가 만든 방법. 212 figure 4.4,4.5
LR parser보충자료를 보자.LR parsing은 테이블을 만들면 그 후는 기계적으로 해석하므로 빠르다.
