GPT-4 Technical Report Review

서론
The post-training alignment process results in improved performance on measures of factuality and adherence to desired behavior. A core component of this project was developing infrastructure and optimization methods that behave predictably across a wide range of scales. This allowed us to accurately predict some aspects of GPT-4's performance based on models trained with no more than 1/1,000th the compute of GPT-4.
GPT-4는 인간보다는 아직 못하지만, 몇몇 특정한 영역에서는 상위 10% 수준의 능력을 냅니다.
GPT-4 는 Multi Modal Model
Input: Image & Text / Output: Text & Image
GPT-4 프로젝트의 방향은 인프라와 컴퓨팅 최적화 방법을 개발하는 것이 중요했고,
그것을 통해서 GPT- 4 의 1/1000 수준의 모델로도 GPT-4 의 일부 성능 측면을 정확하게 예측해냈습니다.
(이 부분이 MoE 의 아이디어가 아닌가 생각도 해봅니다. 처음에 GPT-4 가 나왔을 때를 생각해보면, GPT 3.5 여러개를 엮어놓은 것이다 등등의 예측이 나왔던 것도 이러한 Predictable Scaling 때문이 아니었을까 생각해봅니다.)
Text Benchmarks 결과 요약
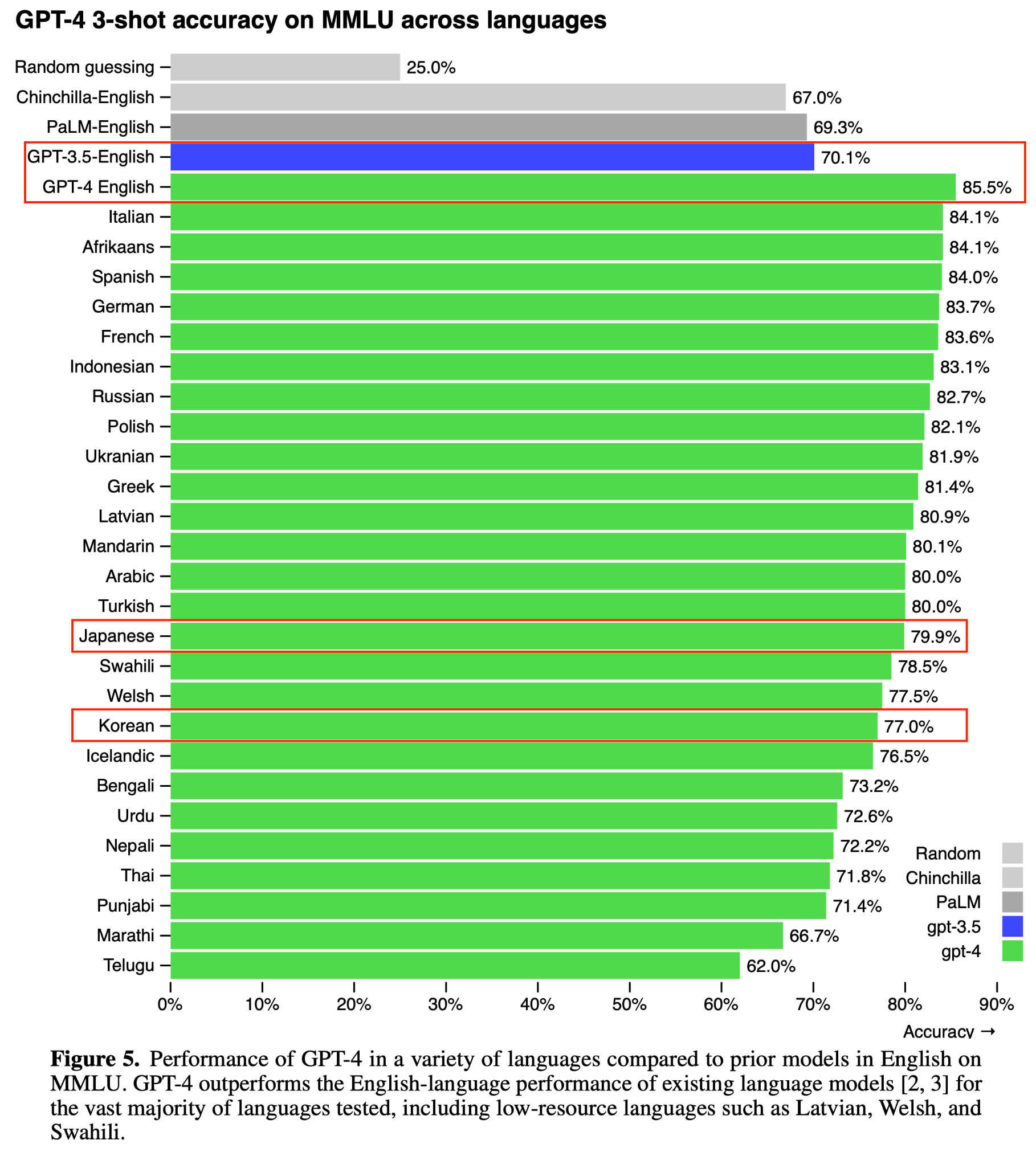
GPT-3.5 가 70.1 % 임을 생각하면 GPT-4 는 번역된 다른 언어에서조차 MMLU Benchmark 의 점수가 높았습니다.
언어에 관계없이 지식을 이용하는 문제를 푸는 성능 자체가 좋다는 걸 의미합니다.
- OpenAI 는 LLM Model 의 Evaluation 에 대해서도 오픈소스로 계속 업데이트 하고 있습니다.
- https://github.com/openai/evals
Multi-Modal: Image-Text Input & Output

처음 GPT-4 가 공개되었을 때, 사람들이 굉장히 놀랐던 부분.
- VGA 커넥터는 핸드폰에 꽂는 경우가 '거의' 없기 때문에, 그게 웃긴 포인트라고 딱 짚어냄
생각해보면, 세상 어디에선가는 손재주 좋은 사람이 VGA 커넥터 껍데기만 이용하면서 라이트닝 케이블 보호체(?)정도로 사용할 수도 있지 않을까요?
- 일본어로 써있는 케이블 포장지, 하단에 초록색으로 '라이트닝 케이블' 이라고 되어 있는데, 실제로 들어있는 케이블은 VGA 커넥터
- VGA 커넥터의 모양은 저렇게 생기지 않았음(화면에 보이는건 라이트닝 케이블)을 정확하게 잘 짚어냈습니다.
사실 그것 때문에 GPT4 가 Multi-Modal 을 잘한다라고 보기에는 좀 더 생각해볼 부분이 있다고 봅니다.
- 모두 VGA Connector 관련 이미지를 한번에 질문했는데, 각각 다른 이미지였다면 이런 결과가 나왔을지?
- '웃긴' 부분이 아닌 말을 조금 변경해서 '이상한' 부분이라고 하면 알아차릴지? (인간은 기존과 다르게
이상하면 그것을 웃기다라고 생각하는 경우가 있으므로 한번 꼬아서 질문하는 격)
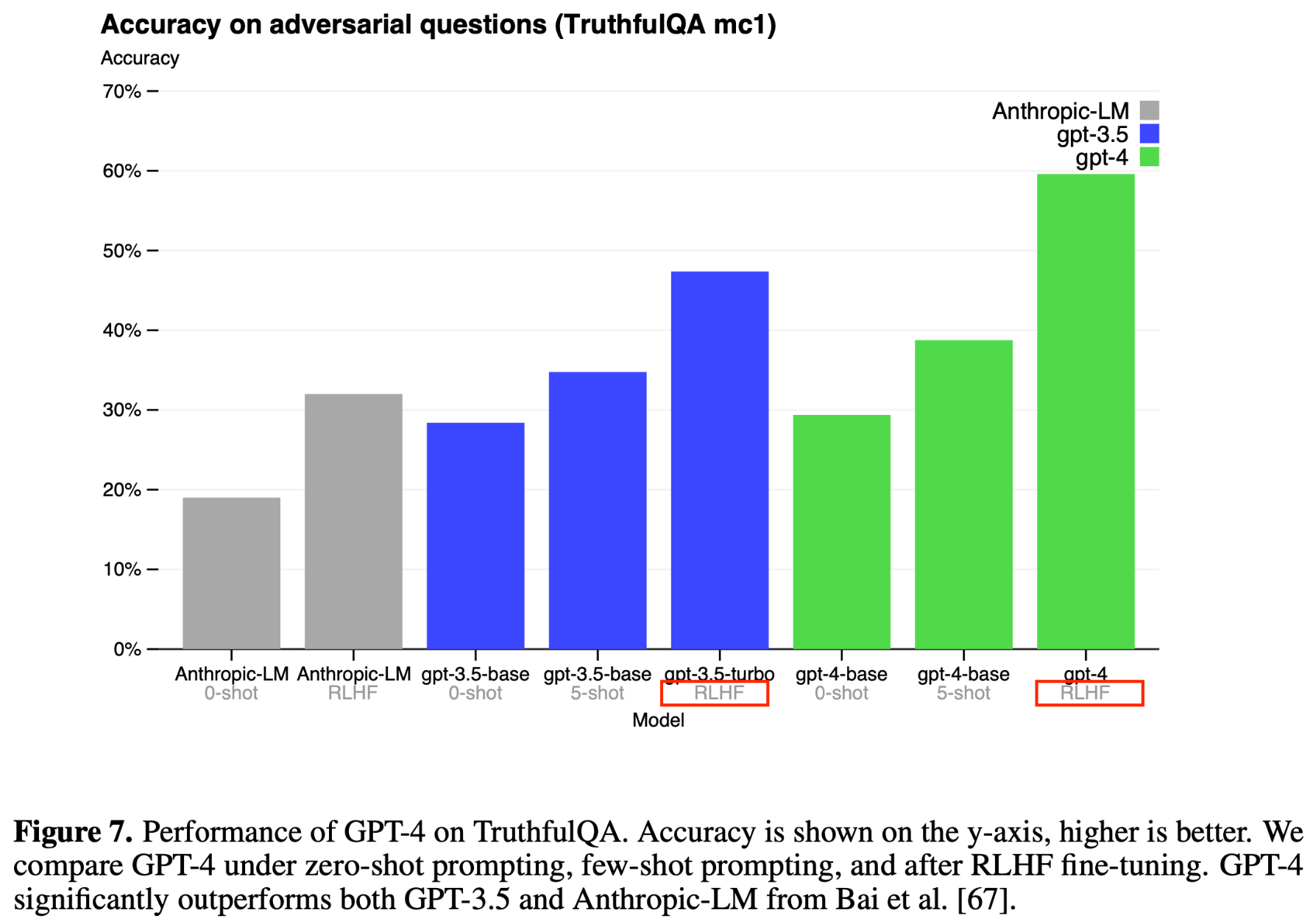
GPT-4 makes progress on public benchmarks like TruthfulQA, which tests the model’s ability to separate fact from an adversarially-selected set of incorrect statements (Figure 7). These questions are paired with factually incorrect answers that are statistically appealing. The GPT-4 base model is only slightly better at this task than GPT-3.5; however, after RLHF post-training we observe large improvements over GPT-3.5
(We did not check the RLHF post-training data for contamination with TruthfulQA)
그럼 RLHF 를 하는 과정에서 TruthfulQA Benchmark 의 데이터가 '사람이 의도하지 않았어도'들어갔을 가능성도 있지 않을까?(참고로 OpenAI 연구자들 중 대부분이 현재 Leader Board 등에서 사용되는 대부분의 Benchmark 들의 제작자입니다.)
-
또한 RLHF 하는 과정에서 정확도와 Risk 등을 해소하기 위해서, Adversarial Testing via Domain Experts 을 적극 활용(전문가들 자문 비용이 어마어마했을텐데...)

-
Rule-based reward models (RBRMs) are a set of zero-shot GPT-4 classifiers.
- 모델이 RBRMs 를 사용해서 zero-shot 기준 잘못된 대답을 했을 때, 올바른 대답을 하도록 Reward 를 감소시켜서 유도함
- 그럼few-shot 을 주고, 복잡한 CoT 를 적용한다면 GPT-4 의 Lock 을 해제할 수 있지 않을까?라는 생각도 해보게 되었습니다.
결론
GPT-4 는 인간이 사용하기에 엄청 좋아졌다. 하지만 완벽하게 기존 문제점을 해결한건 아니다.
더욱 모델이 커졌지만, 컴퓨팅 최적화 & 인프라 최적화를 수행했고 그걸 어느정도는 달성했다.
그 능력들은 각 기능을 가진 작은 모델(1000~10000배 컴퓨팅이 작은)들로 측정이 가능했다.
추가적으로 GPT-4 Eval & Instruction Tuning with GPT-4 & RLAIF 관련해서
gpt-4 eval
Instruction Tuning with GPT-4
RLAIF
- https://arxiv.org/abs/2309.00267
- Reinforcement learning from human feedback (RLHF) has proven effective in aligning large language models (LLMs) with human preferences. However, gathering high-quality human preference labels can be a time-consuming and expensive endeavor. RL from AI Feedback (RLAIF), introduced by Bai et al., offers a promising alternative that leverages a powerful off-the-shelf LLM to generate preferences in lieu of human annotators. Across the tasks of summarization, helpful dialogue generation, and harmless dialogue generation, RLAIF achieves comparable or superior performance to RLHF, as rated by human evaluators. Furthermore, RLAIF demonstrates the ability to outperform a supervised fine-tuned baseline even when the LLM preference labeler is the same size as the policy.
- 요약, 유용한 대화 생성, 무해한 대화 생성 작업 전반에서 RLAIF는 인간 평가자가 평가한 결과 RLHF와 비슷하거나 더 우수한 성능을 달성했습니다. 또한 RLAIF는 LLM 선호도 라벨이 정책과 동일한 크기일 때에도 감독을 통해 미세 조정된 기준선을 능가하는 성능을 보였습니다.
- In another experiment, directly prompting the LLM for reward scores achieves superior performance to the canonical RLAIF setup, where LLM preference labels are first distilled into a reward model. Finally, we conduct extensive studies on techniques for generating aligned AI preferences. Our results suggest that RLAIF can achieve human-level performance, offering a potential solution to the scalability limitations of RLHF.
