
📌 집합 연산자
- 두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회할 때 사용
- SELECT 절의 컬럼 수가 동일하고 SELECT절의 동일 위치에 존재하는 컬럼의 데이터 타입이 상호호환할 때 사용가능
⭐ 일반 집합 연산자(SET OPERATOR)
- UNION : 합집합(중복행 1개), 정렬O
- UNION ALL : 합집합(중복행 표시), 정렬X
- INTERSECT : 교집합(중복행 1개)
- MINUS, EXCEPT : 차집합(중복행 1개)
- CROSS JOIN : 곱집합
✅ 일반집합연산자와 SQL 문장 비교
- UNION : UNION
- INTERSECTION : INTERSECT
- MINUS : DIFFERENCE
- CROSS JOIN : PRODUCT
⭐ 순수 관계 연산자
- SELECT
- PROJECT
- (NATURAL) JOIN
- DIVIDE
✅ 순수관계연산자와 SQL 문장 비교
- SELECT : WHERE절로 구현
- PROJECT : SELECT절로 구현
- JOIN : JOIN으로 구현
- DIVIDE : 사용X
⭐ FROM절 JOIN 형태
- INNER JOIN
- NATURAL JOIN
- USING 조건절
- ON 조건절
- CROSS JOIN
- OUTER JOIN
✅ INNER JOIN
- JOIN 조건에서 동일한 값이 있는 행만 반환
- USING이나 ON 절 필수적으로 사용
SELECT 컬럼명 [, 컬럼명]
FROM 테이블A [INNER] JOIN 테이블B
ON 테이블A.조인키컬럼 = 테이블B.조인키컬럼;✅ NATURAL JOIN
- 두 테이블 간의 동일한 이름을 갖는 모든 컬럼들에 대해 EQUI JOIN 수행
- NATURAL JOIN이 명시되면 추가로 USING, ON, WHERE절에서 JOIN조건을 정의할 수 없다.
- SQL Server는 지원 X
SELECT deptno, empno, ename, dname
FROM t_emp NATURAL JOIN t_dept;
-- 컬럼이 존재하지않고 이름이 같은 컬럼끼리 알아서 JOIN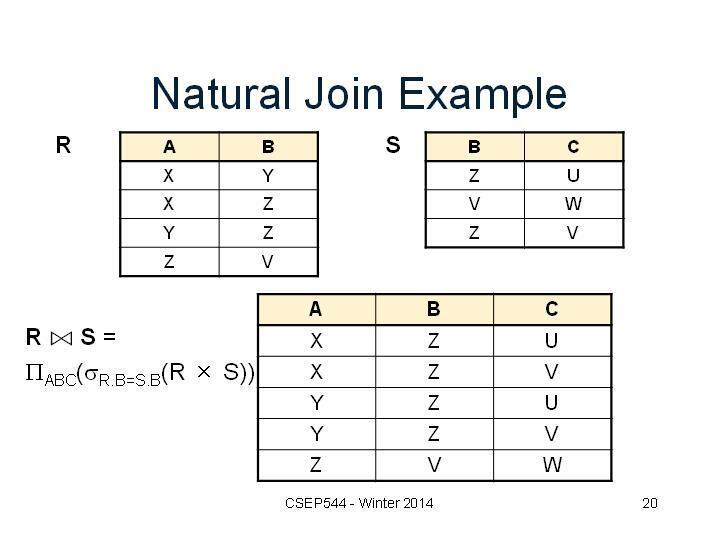
✅ USING 조건절
- 같은 이름을 가진 컬럼들 중에서 원하는 컬럼에대해서만 선택적으로 EQUI JOIN을 수행
- JOIN컬럼에 대해서 ALIAS나 테이블 이름과 같은 접두사를 붙일 수 없다
SELECT *
FROM t_dept JOIN dept_temp USING (DEPTNO); ✅ ON 조건절
- ON 조건절과 WHERE 조건절을 분리하여 이해가 쉬움
- 컬럼명이 다르더라도 JOIN 조건을 사용할 수 있는 장점
- ALIAS나 테이블명 반드시 사용
✅ CROSS JOIN
- 테이블 간 JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합
- 양쪽 집합의
M * N 건의 데이터 조합이 발생
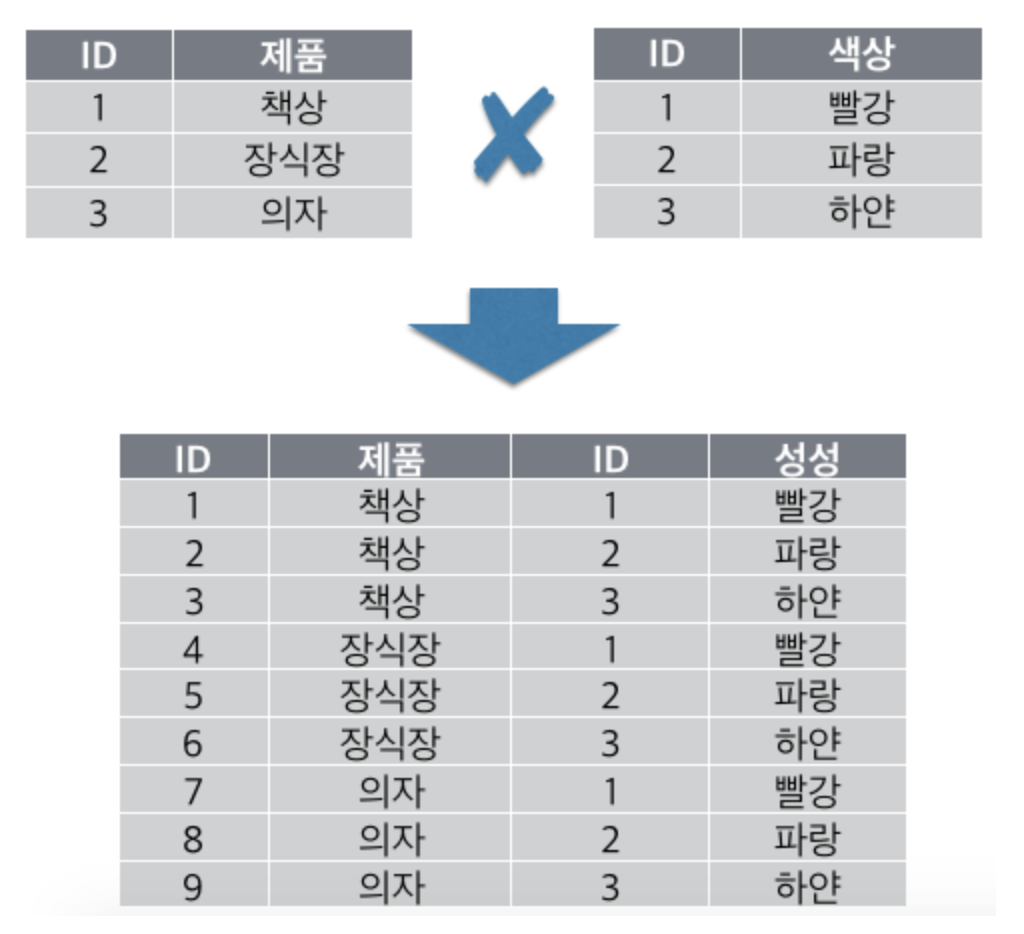
✅ OUTER JOIN
- JOIN조건에서 동일한 값이 없는 행도 반환 가능
- USING이나 ON 조건절 반드시 사용
- 기준테이블은 항상 모두 표시되며, 필터링은 WHERE조건절에 의해 수행
✅ LEFT OUTER JOIN
- 먼저 표기된 좌측 테이블에 해당하는 데이터를 읽은 후, 나중 표기된 우측 테이블에서 JOIN 대상 데이터를 읽어 온다
- 우측 값에서 같은 값이 없는 경우 NULL값으로 채움
✅ RIGHT OUTER JOIN
- LEFT OUTER JOIN 과 반대
✅ FULL OUTER JOIN
- 좌우측 테이블의 모든 데이터를 읽어 JOIN하여 결과를 생성
- LEFT OUTER JOIN + RIGHT OUTER JOIN - 중복 행
- 중복 데이터는 삭제
📌 계층형 질의
- 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해 사용
- SQL Server에서 CTE를 재귀호출함으로써 계층구조를 전개
- SQL Server에서 앵커멤버를 실행하여 기본결과집합을 만들고 이후 재귀멤버를 지속적으로 실행
- WHERE절은 모든전개를 진행한 이후 필터조건으로서 조건을 만족하는 데이터만을 추출하는데 활용
✅ START WITH
- 계층 구조 전개의 시작위치 지정(최상위)
- 루트 데이터 지정
- 서브쿼리 가능
- START WITH 조건의 최초조건은 무조건 출력
✅ CONNECT BY
- 연결고리
- 다음에 전개될 자식데이터 지정
- PRIOR 연산자로 계층구조를 표현
- 서브쿼리 사용불가
✅ PRIOR
프자부순
- CONNECT BY 절에 사용되며 현재 읽은 컬럼을 지정
PRIOR 자식 = 부모형태를 사용하면 계층구조에서 부모 데이터에서 자식 데이터 방향으로 전개하는순방향(부모->자식)전개를 한다.- 반대는 역방향 전개
- CONNECT BY 절 뿐만아니라 SELECT, WHERE절에서도 사용가능
✅ NOCYCLE
- 동일한 데이터가 전개되지 않음
✅ ORDER SIBLINGS BY
- 형제 노드간의 정렬 수행
✅ WHERE
- 모든 전개를 수행한 후에 지정된 조건을 만족하는 데이터만 추출(필터링)
✅ LEVEL
- 계층쿼리의 결과 DEPTH를 표현
- 계층형쿼리에만 존재하는 컬럼
- 루트 데이터는 1, 그 하위는 2, 리프데이터까지 1씩 증가
✅ CONNECT_BY_ISLEAF
- 리프데이터면 1, 아니면 0 반환
✅ CONNECT_BY_ISCYCLE
- 조상이면 1, 아니면 0 반환(CYCLE 옵션 사용했을때만 사용가능)
✅ SYS_CONNECT_BY_PATH
- 루트데이터 부터 현재 전개할 데이터까지의 경로를 표시
✅ CONNECT_BY_ROOT
- 현재 전개할 데이터의 루트데이터를 표시
- 단항연산자이다
⭐ SELF JOIN
- 한 테이블 내에 두 컬럼이 연관관계가 있을 때 동일 테이블 사이의 JOIN
- FROM 절에 동일 테이블이 2번이상 나타난다
- 반드시 테이블 별칭을 사용해야 함
📌 서브쿼리
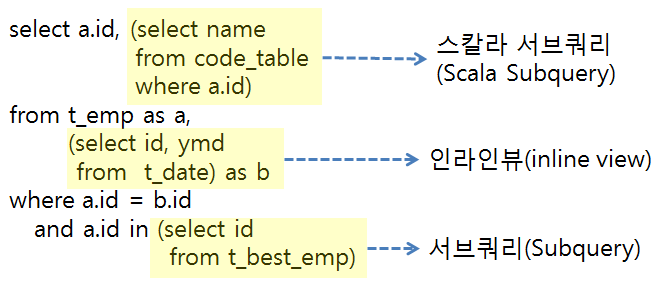
- 하나의 SQL문안에 포함되어 있는 또 다른 SQL문
- 알려지지 않은 기준을 이용한 검색에 사용
SELECT
FROM
WHERE ~~ = (SELECT
FROM
WHERE
);⭐ 서브쿼리 사용시 주의사항
- 서브쿼리를 괄호로 감싸서 사용
- 서브쿼리는 단일행 또는 복수행 비교연산자와 함께 사용가능, 단일행 비교연산자는 서브쿼리의 결과가 반드시 1건이하여야 하고 복수행 비교연산자는 상관없음
- 서브쿼리에서 ORDER BY 사용불가
- SELECT, FROM, WHERE, HAVING, ORDER BY, INSERT-VALUES, UPDATE-SET 절에서 사용가능
- 메인쿼리 작성 시, 서브쿼리에 있는 컬럼을 자유롭게 사용불가
✅ 단일행 비교연산자
- =, <, >=, <> 등
✅ 다중행(복수행) 비교연산자
- IN, ALL, ANY, SOME, EXISTS 등
- 단일행 비교연산자로도 사용가능(반대는 불가)
SELECT *
FROM 런닝맨 A
WHERE EXISTS (SELECT 'X'
FROM 무한도전 B
WHERE A.NAME = B.NAME);
-- 유재석, 하하
-- 여기서 'X'의 의미는 값을 의미하는 것이 아닌 상수표현임(1, 'X', 'A' 아무거나 써도됨)
-- 그냥 값이 존재한다는 의미
-- A에 있고 B에도 있는 교집합
-- NOT EXISTS경우 A에는 있고 B에는 없는 값 출력
-- IN, NOT IN으로 대체해서 사용가능✅ 스칼라 서브쿼리
- 한 행, 한 컬럼 만을 반환하는 서브쿼리
⭐ 동작방식에 따른 서브쿼리 분류
- 비연관 서브쿼리 : 서브쿼리가 메인쿼리 컬럼 안가짐, 메인쿼리에 값 제공 목적
- 연관 서브쿼리 : 서브쿼리가 메인쿼리 컬럼을 가짐
⭐ 반환 데이터에 따른 서브쿼리 종류
- 단일행 서브쿼리 : 실행결과 1건 이하, 단일행 비교연산자와 사용
- 다중행 서브쿼리 : 실행결과 여러건, 다중행 비교연산자와 사용
- 다중컬럼 서브쿼리 : 실행결과 컬럼 여러개, ORACLE에서만 사용가능
✅ 인라인 뷰(동적 뷰)
- FROM절에서 사용되는 서브쿼리
- ORDER BY 사용가능
- SQL문이 실행될때 임시적으로 생성되는 동적뷰이기 때문에 데이터베이스에 해당정보가 저장되지 않음
📌 뷰
- 테이블은 실제로 데이터를 가지고 있는 반면, 뷰는 실제 데이터를 가지고 있지 않다.
- 가상테이블이라고도 불림
- 실행 시점에 SQL을 재작성하여 수행됨
- 실제 데이터를 저장하고 있는 뷰를 생성하는 기능을 지원하는 DBMS도 있음
⭐ 뷰 사용 장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용프로그램은 변경하지 않아도 된다
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련질의를 단순하게 작성할 수 있다
- 보안성 : 직원의 급여정보와 같이 숨기고 싶은 정보가 존재할 때 사용
-- 뷰 생성
CREATE VIEW 뷰명 AS(
SELECT 문
);
-- 뷰 삭제
DROP VIEW 뷰명;📌 그룹함수
- ROLLUP, CUBE, GROUPING SETS 모두 일반그룹함수로 동일한 결과를 추출할 수 있다
- 그룹함수들의 대상 컬럼 중 집계된 컬럼 이외의 대상 컬럼값은 NULL을 반환
⭐ ROLLUP
- Subtotal을 생성하기 위해 사용
- Grouping Columns의 수를 N이라고 했을 때, N+1 레벨의 Subtotal이 생성됨
- 인수 순서에 주의

⭐ CUBE
- 결합 가능한 모든 값에 대하여 다차원 집계를 생성
- 다른 그룹함수들에 보다 시스템 부하가 심함
- 컬럼의 순서가 수행결과에 영향 X
- CUBE(A,B) = GROUPING SETS(A, B, (A, B), ())

⭐ GROUPING SETS
- 인수들에 대한 개별 집계를 구할 수 있다
- 다양한 소계 집합 생성 가능
- 인수의 순서가 바뀌어도 결과는 같다

⭐ GROUPING
- 그룹함수와 함께 쓰임
- GROUP BY에서 쓰인 소계함수 결과 CASE에서 빠진 컬럼(NULL컬럼)에 대해 1을 반환
- 집계 표시면(NULL이면) 1, 아니면 0

📌 윈도우 함수
윈도우함수() OVER (PARTITION BY 컬럼 ORDER BY 컬럼 DESC)
-- 윈도우함수 : 순위함수, 집계함수, 행순서함수, 비율함수
-- OVER : 필수로 존재
-- PARTITION BY : 전체집합을 어떤 컬럼기준으로 나눌지 결정
-- ORDER BY : 어떤컬럼을 기준으로 정렬할지- 행과 행간의 관계를 정의하거나 행과 행을 비교, 연산하는 함수
- Partition과 GROUP BY는 의미적으로 유사함
- Partition구문이 없으면 전체집합을 하나의 Partition으로 정의한것과 동일함
- 윈도우함수 처리로 인해 결과건수는 변함이 없음(결과에대한 함수처리이기때문) => 행수는 그대로(윈도우분석 컬럼이 하나더 생기는 느낌)
- 윈도우함수 적용범위는 Partition을 넘을수 없음
⭐ 순위 관련 함수
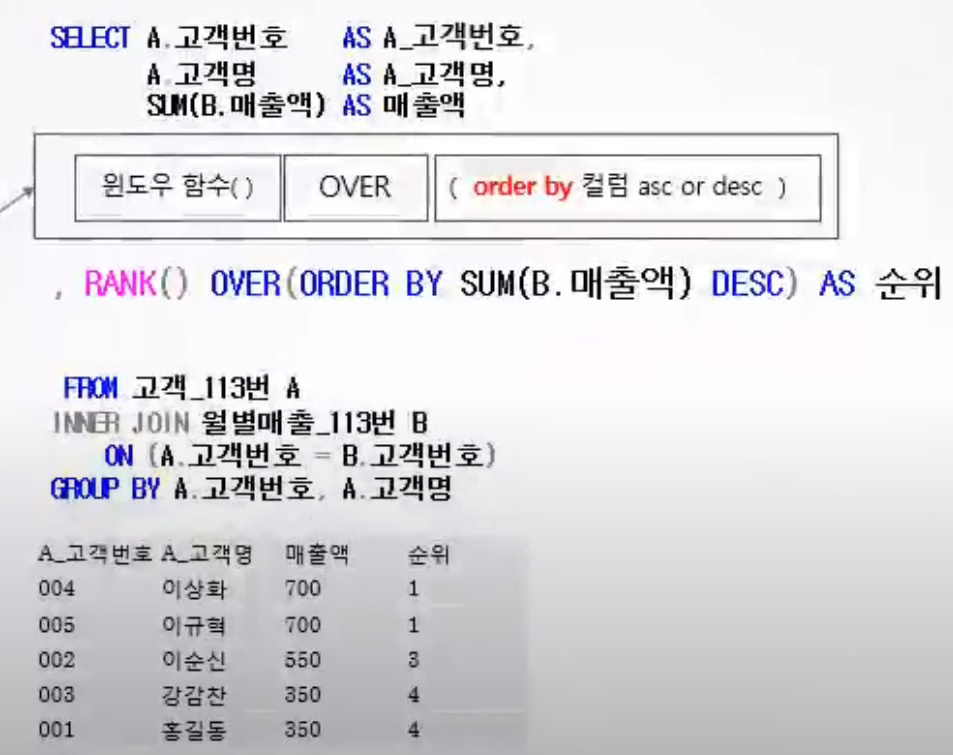
- 순위 함수 사용시 ORDER BY 절은 생략가능
✅ RANK
- 동일한 값에 대해 동일순위 부여(1,2,2,4)
✅ DENSE_RANK
- 동일 순위를 하나의 등수로 간주(1,2,2,3)
- 동일 등수 순위에 영향 x
✅ ROW_NUMBER
- 동일한 값이라도 고유한 순위 부여(1,2,3,4)
⭐ 집계 관련 함수
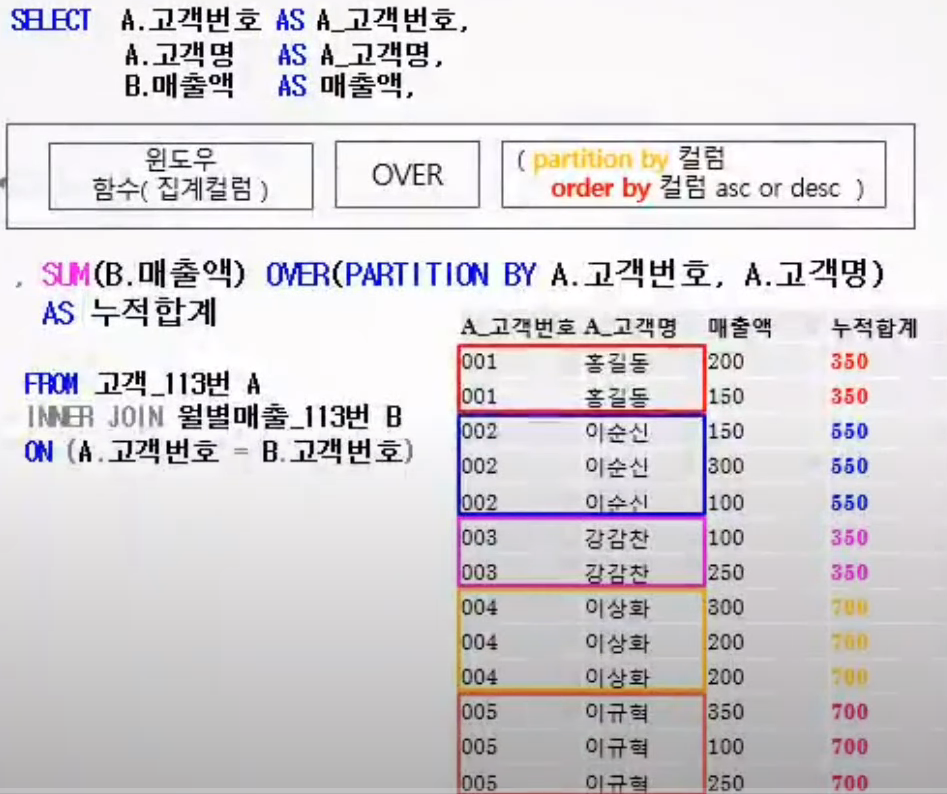
✅ SUM
- 파티션별 윈도우의 합 구할 수 있다
- ORDER BY를 넣으면 누적합계가 됨
✅ MAX, MIN
- 파티션별 윈도우의 최대, 최소값을 구할 수 있다
✅ AVG
- 원하는 조건에 맞는 데이터에 대한 통계값
✅ COUNT
- 조건에 맞는 데이터에 대한 통계값
✅ ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING
- 현재 행을 기준으로 파티션 내에서 앞의 1건, 현재행, 뒤의 1건을 범위로 지정
⭐ 행 순서 관련 함수(SQL Server 미지원)
✅ FIRST_VALUE
- 파티션별 윈도우의 처음 값
✅ LAST_VALUE
- 파티션별 윈도우의 마지막 값
✅ LAG
- 파티션별 윈도우에서 이전 몇번째의 행의 값
✅ LEAD
- 파티션별 윈도우에서 이후 몇번째의 행의 값
⭐ 비율 관련 함수
✅ RATIO_TO_REPORT
- 파티션 내 전체 SUM값에 대한 행별 컬럼 값의 백분율을 소수점으로 구할수 있다
- 결과값은 0초과 1이하
✅ PERCENT_RANK
- 파티션별 윈도우에서 처음 값을 0, 마지막 값을 1로 하여 행의 순서별 백분율을 구함
- 결과값은 0이상 1이하
✅ CUME_DIST
- 현재 행보다 작거나 같은 건수에 대한 누적 백분율을 구한다
- 결과값은 0초과 1이하
✅ NTILE
- 파티션별 전체건수를 인수값으로 N등분한 결과를 구한다
⭐ 윈도우 함수 BETWEEN A AND B
SUM(SAL) OVER (PARTITION BY JOB ORDER BY SAL ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
디폴트 : RANGE BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW- 현재 컬럼의 값 기준, 연산에 참여할 행 선택
UNBOUNDED PRECEDING -- 최종 출력될 값의 첫 행
CURRENT ROW -- 현재행
UNBOUNDED FOLLOWING -- 최종 출력될 값의 마지막 행, 무조건 AND 뒤에
-- UNBOUNDED 자리에 숫자를 넣을수도 있음📌 DCL
- 유저 생성하고 권한을 제어할 수 있는 명령어
⭐ ORACLE과 SQL Server의 사용자 아키텍처 차이
- ORACLE : 유저를 통해 DB에 접속을 하는 형태, ID와 PW의 방식으로 인스턴스에 접속을 하고, 그에 해당하는 스키마에 오브젝트 생성 등의 권한을 부여받게 됨
- SQL Server : 인스턴스에 접속하기 위해 로그인이라는 것을 생성하게 되며, 인스턴스 내에 존재하는 다수의 DB에 연결하여 작업하기 위해 유저를 생성한 후 로그인과 유저를 매핑해 주어야 함. Windows의 인증방식과 혼합모드 방식이 존재함
⭐ 시스템 권한
- 사용자가 SQL문을 실행하기 위해 필요한 적절한 권한
- GRANT : 권한 부여
- REVOKE : 권한 회수
GRANT CREATE USER TO SCOTT;
CONN SCOTT/TIGER(ID/PW)
CREATE USER PJS IDENTIFIED BY KOREA7;
GRANT CREATE SESSION TO PJS;
GRANT CREATE TABLE TO PJS;
REVOKE CREATE TABLE FROM PJS;- 모든 유저는 각각 자신이 생성한 테이블 외에 다른 유저의 테이블에 접근하려면 해당 테이블에 대한 오브젝트 권한을 소유자로부터 받아야 한다.
✅ ROLE
- 유저에게 알맞은 권한들을 한 번에 부여하기 위해 사용하는 것
- 다양한 권한을 그룹으로 묶어 관리할 수 있도록 사용자와 권한 사이에서 중개역할을 수행
CREATE ROLE LOGIN_TABLE;
GRANT CREATE TABLE TO LOGIN_TABLE;
DROP USER PJS CASCADE;✅ WITH GRANT OPTION
- 권한을 부여받은 유저가 동일권한을 줄 수있는 옵션
✅ CASCADE
- 하위 오브젝트까지 삭제
📌 절차형 SQL
- SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정기능을 수행하는 저장 모듈을 생성할수 있다.
- Procedure, User Defined Function은 트랜잭션 분할 가능
- 프로시저 내부에 작성된 절차적코드는 PL/SQL엔진이 처리하고 일반적인 SQL문장은 SQL실행기가 처리함
⭐ 저장 모듈
- PL/SQL 문장을 DB 서버에 저장하여 사용자와 애플리케이션 사이에서 공유할 수 있도록 만든 일종의 SQL 컴포넌트 프로그램
- 독립적으로 실행되거나 다른 프로그램으로부터 실행될 수 있는 완전한 실행 프로그램
- Oracle의 저장모듈에는 프로시저, 사용자 정의함수, 트리거가 있음
⭐ PL/SQL의 특징
- Block 구조로 되어있어 각 기능별로 모듈화 가능
- 변수, 상수등을 선언하여 SQL 문장 간 값을 교환
- IF, LOOP 등의 절차형 언어를 사용하여 절차적인 프로그램이 가능해짐
- DBMS 정의 에러나 사용자 정의 에러를 정의하여 사용가능
- PL/SQL은 Oracle에 내장되어 있으므로 호환성 좋음
- 응용 프로그램의 성능을 향상시킴
- 여러 문장을 블록 단위로 처리 -> 통신량을 줄일 수 있다
✅ DECLARE
- BEGIN~END 절에서 사용될 변수와 인수에 대한 정의 및 데이터 타입 선언부
✅ BEGIN ~ END
- 개발자가 처리하고자 하는 SQL문과 여러가지 비교문, 제어문을 이용해 필요한 로직 처리
-- 동적SQL 또는 DDL 문을 실행할때는 EXECUTE IMMEDIATE를 사용
EXECUTE IMMEDIATE 'TRUNCATE TABLE DEPT'✅ EXCEPTION
- BEGIN ~ END절에서 실행되는 SQL문이 실행될 때 에러가 발생하면 그 에러를 어떻게 처리할 지 정의하는 예외처리부
✅ T-SQL
- 근본적으로 SQL Server를 제어하는 언어
✅ Procedure
- SQL로직과 함께 데이터베이스 내에 저장해 놓은 명령문의 집합
- BEGIN ~ END 절 내에 TCL 사용가능
- EXECUTE 명령어로 실행
✅ Trigger
- 특정한 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때 DB에서 자동으로 동작하도록 작성된 프로그램
- 사용자 호출이 아닌 DB 자동수행
- 데이터의 무결성과 일관성을 위해 사용
- BEGIN ~ END절 내에 TCL 사용불가
✅ 사용자 정의함수
- 단독적으로 실행되기 보다는 다른 SQL문을 통해 호출되고 그 결과를 리턴하는 SQL의 보조적인 역할
⭐ 프로시저와 트리거의 차이점
- 프로시저 : BEGIN ~ END 절 내에 TCL 사용가능, EXECUTE 명령어로 실행
- 트리거 : BEGIN ~ END절 내에 TCL 사용불가, 생성 후 자동실행
CREATE PROCEDURE
CREATE TRIGGER