
📌 윈도우 함수
- ROWS : 행
- RANGE : 값
- RANK : 중복 건너뛰기(1134)
- DENSE_RANK : 건너뛰기X(1123)
📌 계층형 질의
프자부 부자순
PRIOR 자식데이터 = 부모데이터
부모데이터 = PRIOR 자식데이터
PRIOR EMPNO = MGR- 부모에서 자식으로 가는 경우(순방향)
📌 절차형 PL/SQL
- EXCEPTION 생략가능
✅ Procedure, Trigger, User Defined Function
- 프로시저 : 반환값 없음
- 트리거 : commit, rollback 불가, 주로 DML 사용
- 사용자정의함수 : 반환값 있음
📌 데이터 모델링
📌 엔티티
- 특징
- 분류(유사개, 기행중)
✅ ERD 서술규칙
- 시선 좌상단 => 우하단
- 관계명 반드시 표기 안해도됨
- UML은 객체지향에서만 사용
📌 속성
- 인스턴스의 특성
- 분류(기설파)
✅ 도메인
- 데이터 유형, 크기, 제약조건
- CHECK
📌 관계
- IE, BARKER
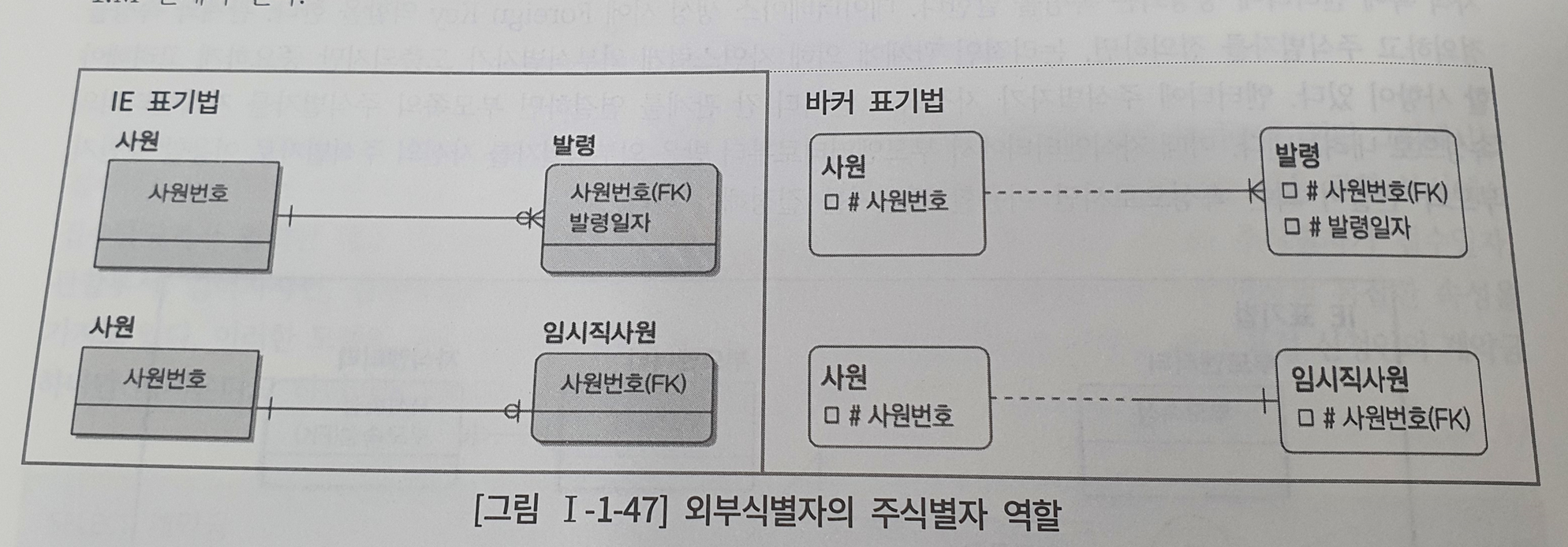
✅ 식별자 / 비식별자
- 식별자 : 실선, 강한관계, SQL구문이 복잡해짐(PK 속성수 증가)
- 비식별자 : 점선, 약한관계, 조인이 많아져서 느려진다
📌 식별자
- 특징(
유최불존) => 후보키 => 기본키, 대체키
📌 성능 데이터 모델링
- 아키텍처 : 파티션, 테이블 구조
- SQL 명령문 : 조인수행원리(해시조인), 옵티마이저, 실행계획
📌 정규화
- 1차 정규화 : 원자성 확보
- 2차 정규화 : 부분함수종속 제거
- 3차 정규화 : 이행함수종속 제거
- 성능적인 부분 SELECT 하락(JOIN), INSERT, UPDATE 상승
✅ 이상현상
- 삽입, 삭제, 갱신
📌 반정규화
- 데이터 무결성 해침
- 요약본 참고
📌 대량 데이터에 따른 성능
- ROW MIGRATION
- ROW CHAINING
=> 해결방법 파티셔닝
✅ 파티셔닝
- RANGE : 관리쉬움, 가장많이 쓰임
- LIST
- HASH : 관리가 어렵다
📌 슈퍼 / 서브타입
- 용량
- 적은경우 : ONE TO ONE TYPE
- 큰경우 : 트랜잭션으로
- 트랜잭션
- 공통,차이점 : PLUS TYPE
- 전체통합 : SINGLE TYPE
📌 분산데이터베이스
- 데이터 무결성 해침
- 투명성(
중위병장지분)
📌 조인수행원리
- NL JOIN
- 랜덤 액세스
- 대용량 소트작업시 유리
- SORT MERGE JOIN
- 조인키 기준정렬
- 등가, 비등가 조인 가능
- HASH JOIN
- 등가 조인만 가능
- 선행테이블 작다
- HASH처리 별도공간 필요
📌 옵티마이저
- CBO : 경로 제일싼거
- RBO : 규칙
📌 인덱스
- 부정형, LIKE, 묵시적형변환일때 사용안함
- DML(INSERT, UPDATE, DELETE)의 성능이 나빠짐
📌 실행계획
- 들여쓰기가 많은것부터 실행
- 뭉텅이 단위로잘라서 실행
1
2
3
4
5
-- 3 -> 2 -> 5-> 4 -> 1 순으로 실행