이번 파트는 기술 면접에서 데이터베이스 관련 질의를 할 때 꼭 나오는 것 중 하나인 INDEX에 대해 다룬다.
INDEX
지금 공부하고 있는 전공책을 뒤져보자. 필자의 경우 운영체제 책으로 유명한 공룡책을 예로 들었다. 만약 '데드락'이라는 단어를 찾고자 하면, 부록으로 실린 색인을 찾아보면 어느 페이지에 있는지 쉽게 알 수 있을 것이다.
만약 색인이 없다면 맨 처음 페이지부터 뒤져봐야하는 매우 비효율적인 상황이 나올 것이다.
INDEX가 바로 그러한 역할을 한다.
지난 시간 우리는 정규화에 대해 배우고, 테이블을 적절히 나누는 방법을 터득했다.
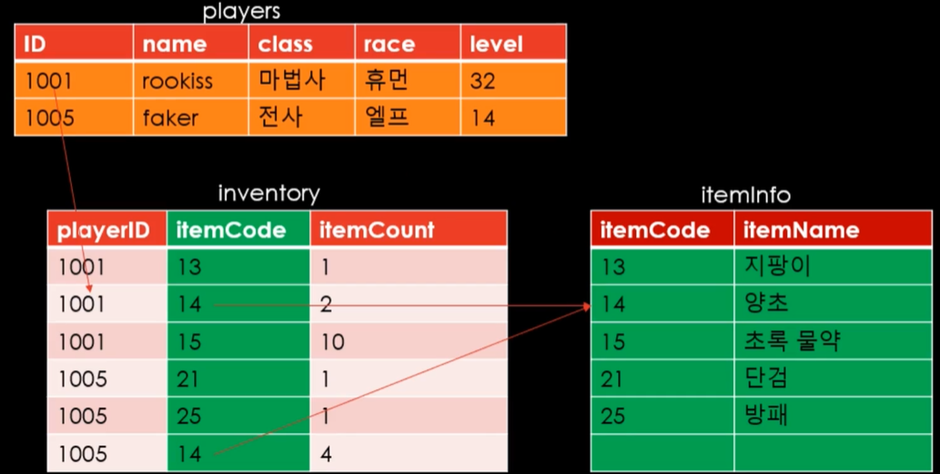
지금은 플레이어가 두 명이니 상관이 없겠지만, 게임이 너무나도 흥행해서! 유저 수가 매우 많아졌다고 가정하자. 게임을 할 때 귓속말을 날릴 때, 상대가 접속 중인지 아닌지 알기 위해선 데이터베이스 내에서 접속하고 있는지 알 필요가 있다.
이럴 때 INDEX가 필요한 것이다. 없다면 똑같이 수백만 명의 유저들 DB를 찾아봐야 할 터...
이렇게 INDEX에 대해 예찬을 하는데, 그렇다면 모든 열에 INDEX를 걸면 되지 않을까? 라는 의문이 들 것이다.
다만 INDEX를 사용하면 오히려 독이 되는 경우도 있다. 해당 예제 class 열에 INDEX를 건다고 가정하자. 마법사에 대한 정보를 찾는다면 무지막지한 양의 결과가 나올 것이다. 마치 데드락을 운영체제 책에서 찾으려고 색인을 펼쳤더니 수십만의 페이지가 나열되어 있는 것마냥...
그러므로, INDEX는 단어의 종류가 많되 겹치는게 별로 없어야 최적의 성능을 낸다. 어느 눈치 빠른 독자 분들은 이렇게 생각하실 수도 있겠다.
그러면 Primary Key가 INDEX에 제격이겠군요!
맞다. 그러나 여기선 조금 보완을 해야할 것은 INDEX에서도 여러 종류가 있다. 다음과 같이 두 종류로 나누어진다.
Clustered Index: 실제 데이터가 정렬된 상태로 저장됨(물리적인 데이터 저장 순서의 기준)
-> 영한 사전
Non-Clustered Index: 따로 관리하는 일종의 LOOK UP 테이블.
->전공책 후반부의 색인
Primary Key는 대부분 Clustered Index이며, 테이블 당 1개만 존재하고 제일 좋고 빠른 존재이다.
이제 지난 시간에 만든 GameDB 데이터베이스의 accounts 테이블로 간단하게 Index를 만들어보자.
우선 Primary Key도 Index이므로, accountId 열에 이를 추가해주자.
ALTER TABLE accounts
ADD CONSTRAINT PK_Account PRIMARY KEY (accountId);테이블을 새로고침한다면
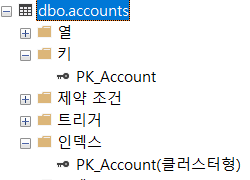
다음과 같이 Key에도 속하고, 클러스터형 인덱스에 해당한다는 점을 알 수 있다.
해당 테이블에선 accountName(계정 이름)도 인덱스에 꽤나 적절한 열이라고 볼 수 있다. 대부분의 게임에선 닉네임도 중복을 허용하지 않으니. 이럴때 Non-Clustered Index로 추가해주면 좋을 것이다.
CREATE INDEX i1 ON accounts(accountName);--accounts 테이블 내 accountName 열에 i1이라는 Index를 추가한다.
똑같이 새로고침을 한다면, 인덱스에 비클러스터형 i1이 생성될 것이고, 키에는 생성이 안될 것이다.(당연하다!)
인덱스를 제거하려면 다음과 같은 명령어를 사용하면 된다.
DROP INDEX accounts.i1;