
저번 INDEX와 같이 JOIN도 매우 중요한 내용이니 잘 알아두자.
JOIN
우리가 배우고 있는 관계형 데이터베이스에선 정규화를 이용해 테이블을 적절히 나누었다. 따라서 이를 합치기 위한 JOIN 연산 역시 필요하다.
JOIN 연산에는 다음과 같은 종류가 있다.
- Cross Join
- Inner Join
- Outer Join
CROSS JOIN
Cross Join이라 하니 무언갈 '교차' 시키는 느낌이 든다. 저번 GameDB를 이용하여, 다음과 같은 테이블과 행을 추가해보자.
CREATE TABLE testA
(
a INTEGER
)
CREATE TABLE testB
(
b VARCHAR(10)
)
INSERT INTO testA VALUES(1);
INSERT INTO testA VALUES(2);
INSERT INTO testA VALUES(3);
INSERT INTO testB VALUES('A');
INSERT INTO testB VALUES('B');
INSERT INTO testB VALUES('C');📌사실 Cross Join은 후술하겠지만 매우 비효율적으로 거의 쓰이지 않지만, Join의 개념을 알아두기 위한 한 과정으로 생각하자.
Cross Join을 사용하는 방법은 다음과 같이 두 가지 방법이 있다.
SELECT * FROM testA CROSS JOIN testB
SELECT * FROM testA,testB;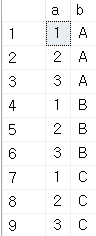
9행의 결과가 나왔다. 그런데 결과를 보면 아시다시피, 무엇이 Cross Join이 무엇인지 쉽게 알 수 있을 것이다.
🔑Cross Join은 두 테이블의 모든 행의 조합을 모두 반환한다.
tesetA에서도 3개, testB에서도 3개의 행이 있으니 3*3=9개의 행이 나온 것이다.
Cross Join의 문제점은 모든 행의 조합을 모두 반환하므로, 두 테이블의 행 수가 매우 크다면 매우 비효율적이 된다는 문제점이 발생한다.
두 테이블이 100행이라 하여도 100*100=1만개가 된다...
그렇기에 하단의 Inner Join과 Outer Join을 사용한다.
INNER JOIN
이제 Inner Join에 대해 알아보자.
🔑Inner Join은 두 개의 테이블을 가로로 이어 붙인 후, ON 절에 있는 기준을 만족한 행들을 반환한다.
역시나 예제를 통해 살펴보자. 이번엔 BaseBall Data를 사용한다. plaers, salaries 테이블엔 playerID 열이 공통으로 있으므로, 두 테이블을 사용해보자.
두 테이블의 PlayerID가 같은 행을 반환해야 하므로, 각 테이블을 AS를 이용해 구별하도록 하자.
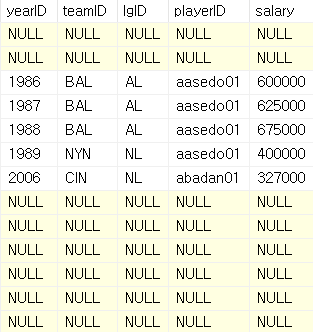
SELECT *
FROM players AS p
INNER JOIN salaries AS s
ON p.playerID=s.playerID;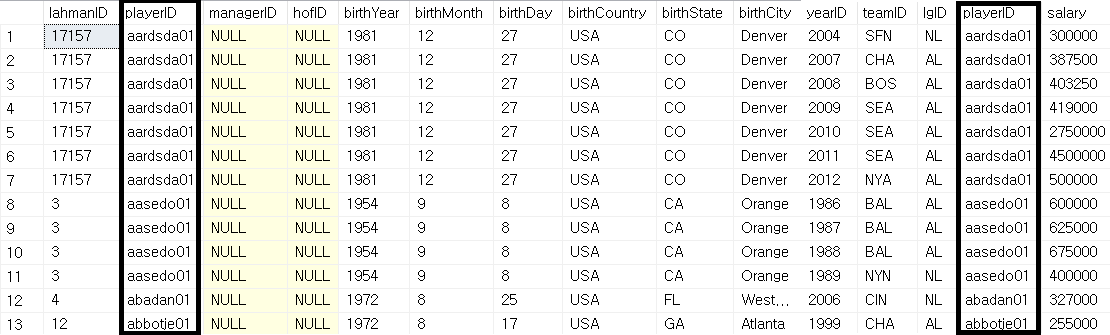
해당 결과와 같이, 두 테이블의 playerID가 같은 행들만 반환해주는 모습을 알 수 있다.
OUTER JOIN
Outer Join은 Inner Join과 유사하다. Outer Join은 Left/Right Join이 존재한다.
🔑Left Join은 두 개의 테이블을 가로로 이어 붙인 후, ON 절에 있는 기준을 만족한 행들을 반환한다. 단, 왼쪽 테이블에 존재하지만 우측 테이블에 존재하지 않는 경우 이 부분은 NULL로 채운다.
🔑Right Join은 두 개의 테이블을 가로로 이어 붙인 후, ON 절에 있는 기준을 만족한 행들을 반환한다. 단, 오른쪽 테이블에 존재하지만 왼쪽 테이블에 존재하지 않는 경우 이 부분은 NULL로 채운다.
Left Join의 예시를 통해 알아보자.
SELECT *
FROM players AS p
LEFT JOIN salaries AS s
ON p.playerID=s.playerID;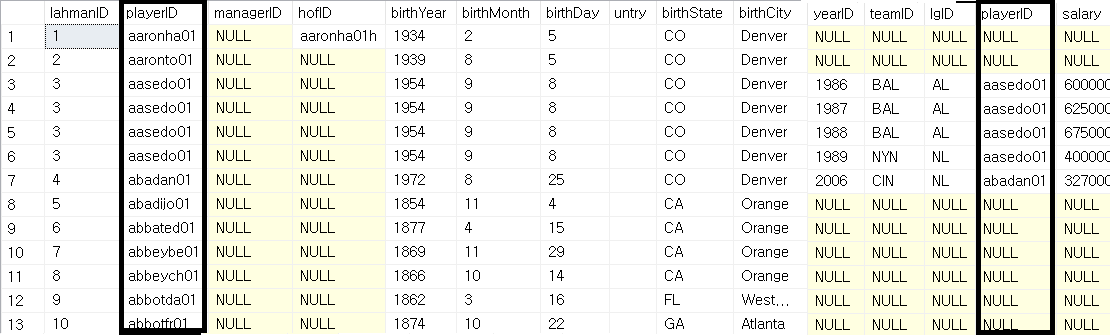
yearID부터는 salaries 테이블로 부터 가로로 붙여진 부분이다. playerID가 NULL이므로, 모든 부분이 NULL로 채워짐을 알 수 있다.
Right Join도 반대로 마찬가지가 되므로, 한 번 따라해보자.
