index를 사용하는 이유
Q. age = 20인 행을 찾으시오.
SELECT * FROM table WHERE age = 20;
| first_name | age |
|---|---|
| 김씨 | 15 |
| 이씨 | 30 |
| 박씨 | 25 |
| 김씨 | 20 |
| 이씨 | 10 |
이렇게 생긴 테이블에서는 age가 20인 행을 찾기 위해 모든 행을 탐색한다.
행이 1억개면?? -> 1억개의 행을 모두 탐색한다.

이렇게 컴퓨터에게 가혹행위를 하게 되면 특이점이 왔을 때 위험할 수 있기 때문에 index를 사용하자

index를 알아보자

-> 인덱스 그자체
Q. 1~100 숫자 1개 생각해보겠음 맞춰보셈

A. 1 생각했음?
A. 2 생각했음?
A. 3 생각했음??
-> 최악의 경우에 100번 질문해야한다.

어떻게 질문해야 빨리 찾을 수 있을까
Q. 1~100 숫자 1개 생각해보겠음 맞춰보셈
A. 50보다 큼??
A. 75보다 작음??

이런식으로 질문하면 행이 1억개 있어도 20~30번 만에 찾을 수 있다.
하지만 이렇게 질문하려면 전제 조건이 있는데
순서대로 정렬되어 있어야 한다.
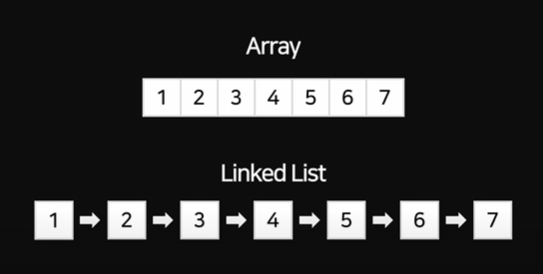
정렬을 하기 위해선 Array나 Linked List를 떠올릴 수 있다.
실제 데이터베이스에서는 Tree 형태로 데이터를 배치하고 정렬해 놓는다.
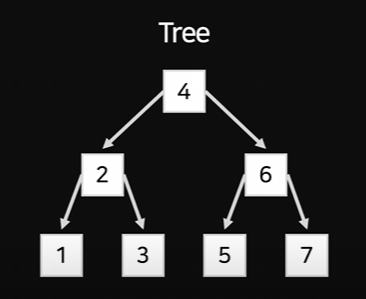
데이터를 다 가져와서 일렬로 줄 세우는 게 아니라 아무렇게나 흩뿌려져 있는 데이터를 화살표로 연결만 해놓음
Q. 5를 찾고 싶어요
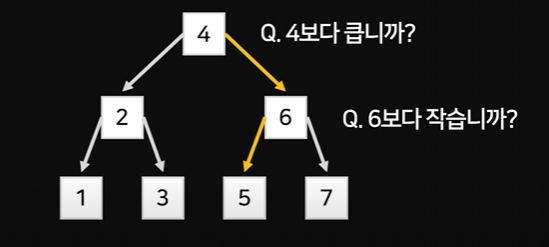
두번만에 찾을 수 있다.
이 트리를 Binary Search Tree라고 부른다.

성능을 개선하기 위한 방법
노드마다 데이터를 하나씩 넣는 게 아니라 여러개씩 넣는다.
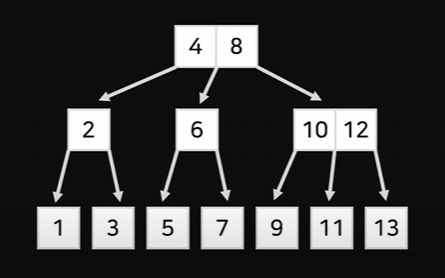
3분의 2씩 화끈하게 잘라버릴 수 있다
이 트리를 B-tree라고 부른다.
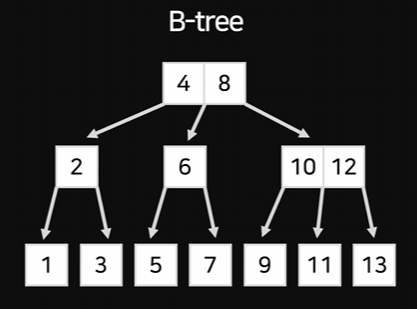
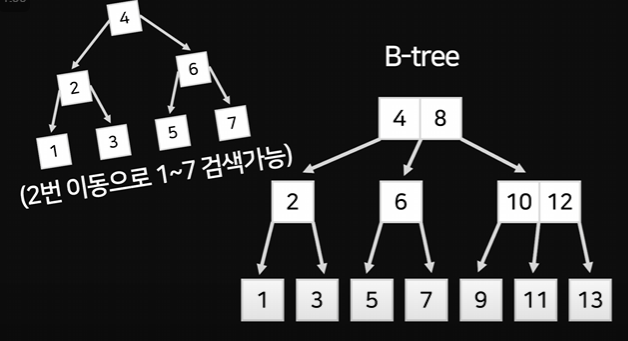
아까는 두번의 이동으로 1~7까지 검색이 가능했지만 B-tree는 10이 넘는 숫자까지 탐색 가능하다.
이 트리를 한 번 더 강화할 수 있는데 B+tree라고 부른다.
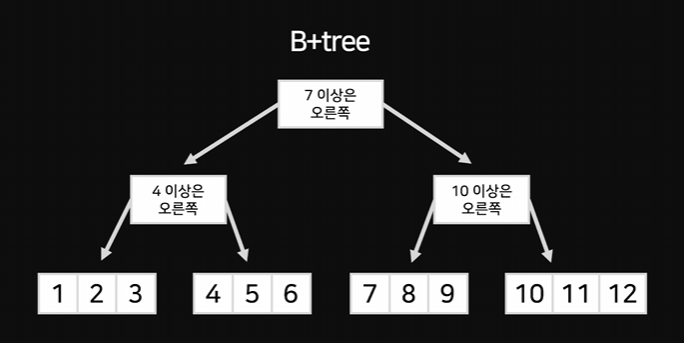
데이터를 가장 아래에 있는 노드에만 보관하고 위에 있는 노드에서는 가이드만 제공한다.
B+tree의 차이점은 맨 밑에 있는 노드들도 연결한다는 것인데
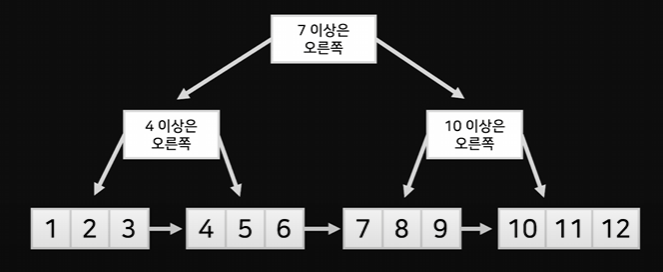
이렇게 했을 경우 범위 검색이 매우 쉬워진다
Q. 4~8 찾아줘
-> 두번의 질문으로 4 찾은 후 8 나올때까지 오른쪽으로 쭉 이동하면 된다.
처음으로 돌아와서
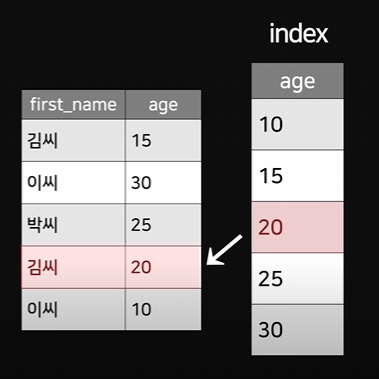
Q. age = 20인 데이터 찾아와라
- index 없는 경우
- 모든 행 다 뒤짐
- index 있는 경우
- index에서 age = 20 빠르게 찾음
- index와 연결된 원래 테이블 행을 가져옴
- 단점
- column을 따로 복사해서 정렬해두는 개념이기 때문에 만들때마다 db 용량을 더 차지한다.
(검색이 필요 없는 데이터인 경우에는 index를 따로 만들어 둘 필요가 없다) - 데이터를 삽입 삭제 수정할 때마다 index도 수정해야하기 때문에 성능 하락이 발생할 수 있다.
- column을 따로 복사해서 정렬해두는 개념이기 때문에 만들때마다 db 용량을 더 차지한다.
- Primary Key는 자동으로 정렬되어 있기 때문에 index 생성이 필요없다.
