👏 분할 정복이란?
분할 정복(DIvide & Conquer)은 가장 유명한 알고리즘으로 둘 이상의 부분 문제로 나눈 뒤 각 문제에 대한 답을 재귀 호출을 이용해 계산하고, 각 부분 문제의 답으로부터 전체 문제의 답을 계산합니다.
이때, 분할 정복이 일반 재귀 호출과 다른 점은 문제를 한 조각과 나머지 전체로 나누는 대신 거의 같은 크기의 부분 문제로 나누는 것입니다.
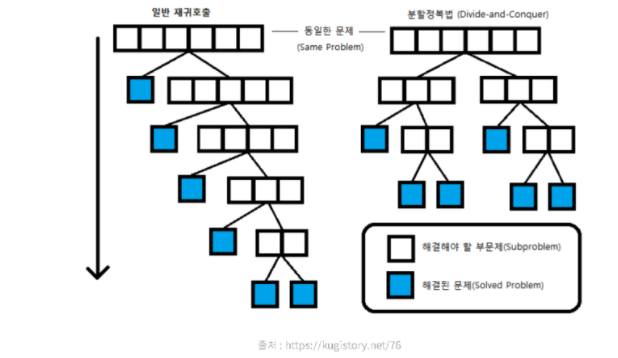
분할 정복의 과정
- Divide : 문제를 더 작은 문제로 분할하는 과정
- merge : 각 문제에 대해 구한 답을 원래 문제에 대한 답으로 병합하는 과정(merge)
- base case : 더 이상 답을 분할하지 않고 곧장 풀 수 있는 매우 작은 문제
분할 정복이 효과적일 때
1) 수열의 빠른 합
기존의 재귀호출의 시간 복잡도 : sum(n) = 1+2+3+ ... +n
분할정복의 시간 복잡도 : fastsum(n) = 2 * fastsum(n/2) + n2/4(n이 짝수 일때)
따라서 fastsum()은 호출될 때마다 최소한 두 번에 한번 꼴로 n이 절반으로 줄어든다. 따라서 fastsum의 시간 복잡도가 훨씬 적을 것이라는 것은 쉽게 예상할 수 있다.
2) 행렬의 빠른 제곱
- 행렬 또한 Am = Am/2 * Am/2로 기존의 행렬 곱셈 횟수보다 더욱 빠르게 계산할 수 있습니다.
앞서 수열의 빠른 합의 분할정복 시간 복잡도를 구했을 때 한 가지 전제가 깔려있었습니다. (n이 짝수 일때)
Q. 그렇다면 홀수일 때는 어떨까요??
A. pow(A,31)을 구하기 위해 분할 정복을 사용한다고 가정해 봅시다.
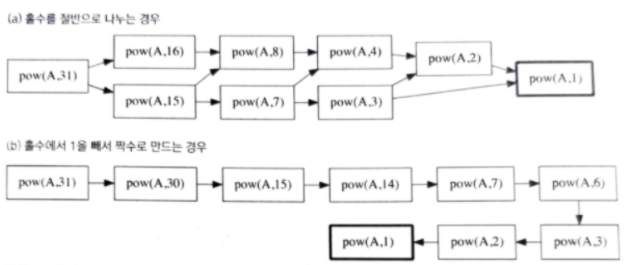
얼핏 보면 다를 것이 없어 보이지만 a)의 경우 pow(A,16)과 pow(A,15)를 구하기 위해 pow(A,8)이 두 번 호출된다는 것을 알 수 있다. 이처럼 같은 값을 중복으로 계산하는 일이 많기 때문에 m이 증가함에 따라 pow()의 호출 횟수는 m에 대해 선형적으로 증가합니다. 이렇게 될 경우 분할 정복을 하는 의미가 없으며 m-1번 곱셈하는 것과 다를 바가 없습니다. 반면 b)에서는 pow()가 O(lgm)개의 거듭제곱에 대해 한번씩 호출된다는 것을 쉽게 알 수 있습니다. 따라서 이러한 중복문제를 고안하기 위해 만든 것이 바로 동적 계획법입니다.
그렇다면 분할정복의 대표적인 예인 병합정렬과 퀵정렬에 대해 한번 살펴보자.
😎 병합정렬
병합정렬 알고리즘은 분할 정복 알고리즘과 마찬가지로
1. Divide : 문제를 더 작은 문제로 분할하는 과정
2. merge : 각 문제에 대해 구한 답을 원래 문제에 대한 답으로 병합하는 과정(merge)
3. base case : 더 이상 답을 분할하지 않고 곧장 풀 수 있는 매우 작은 문제
이 세과정을 거치는 데 자세한 것은 그림과 함께 설명하도록 하겠다.
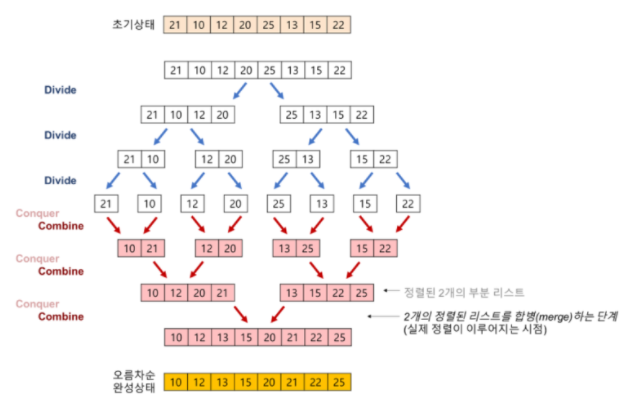
그림에서 보는 것처럼 병합 정렬 알고리즘은 주어진 수열을 가운데에서 쪼개 비슷한 크기의 수열을 두 개로 만든 뒤 이들을 재귀 호출을 이용해 각각 정렬합니다. 그 후 정렬된 배열을 하나로 합침으로써 정렬된 전체 수열을 얻습니다.
시간 복잡도
병합 알고리즘은 각 수열의 크기가 1이 될때까지 절반씩 쪼개 나간 뒤, 정렬된 부분 배열들을 합쳐 나가는 것을 볼 수 있다. 주어진 배열 가운데를 나누기 때문에 O(1)만에 수행할 수 있지만 배열을 하나로 합치기 위한 merge과정세 O(n)의 시간복잡도가 소요됩니다.
😁 퀵정렬
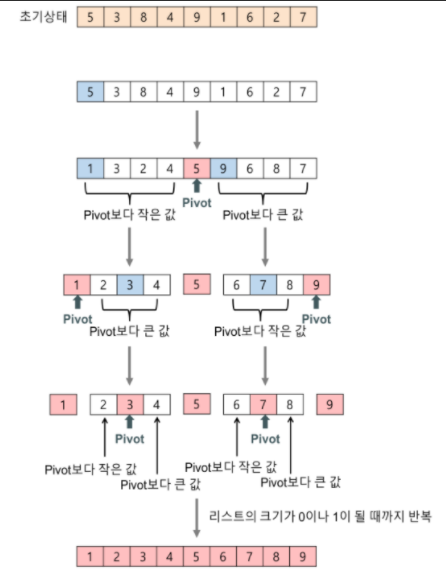
그림과 같이 퀵정렬은 각 부분 수열의 맨 처음에 있는 수를 기준으로 삼고, 이들보다 작은 수를 왼쪽으로, 큰 것을 오른쪽으로 가게끔 문제를 분해합니다. 기준이 된 수를 뽑고 분할하는 데 걸리는 시간은 O(n)의 시간이 걸립니다. 만약 위의 예처럼 1234를 1/234로 분해하는 비효율적인 분할을 불러올 여지가 있지만 그렇지 않을 경우 별도의 병합작업이 필요 없다는 장점이 있습니다.
| 병합정렬 | 병합 정렬의 경우 수열의 각 항의 길이가 1이 될때 까지 나누는 분할 과정 O(lgn)과 병합과정 O(n)이 항상 일정하기 때문에 항상 O(nlgn)의 시간복잡도가 소요됩니다. |
|---|---|
| 퀵정렬 | 퀵정렬의 경우 대부분의 시간을 차지하는 것은 주어진 문제를 두 개의 부분 문제로 나누는 파티션 과정입니다. 파티션은 주어진 수열의 길이에 비례하는 시간이 걸리므로, 사실 병합 정렬에서의 병합과정 O(n)과 같다.퀵정렬은 항상 두 부분문제가 비슷한 크기로 나누어 진다는 보장이 없으므로 퀵정렬의 최악의 시간 복잡도는 O(n^2)이 됩니다. 평균적으로 부분 문제가 절반에 가깝게 나누어 질 경우 O(nlgn)이 된다. |
😜 병합정렬 코드
n = int(input())
lst = list(map(int, input().split()))
cnt = 0
def srt(lst):
if len(lst) <= 1:
return lst
a = srt(lst[len(lst) // 2:])
b = srt(lst[:len(lst) // 2])
i = 0
j = 0
merg = []
while i < len(a) and j < len(b):
if a[i] <= b[j]:
merg.append(a[i])
i += 1
else:
merg.append(b[j])
j += 1
while i < len(a):
merg.append(a[i])
i += 1
while j < len(b):
merg.append(b[j])
j += 1
return merg
print(srt(lst))