
데이터베이스
- 체계적인 데이터 모음
- 데이터 : 저장이네 처리에 효율적인 정보로 변환된 정보
데이터를 저장하고 잘 관리하여 활용할 수 있는 기술이 중요해짐
기존의 데이터 저장 방식
- 파일(File) 이용
- 스프레드 시트(Spreadsheet) 이용
1. 파일을 이용한 데이터 관리
- 어디에나 쉽게 사용 가능
- 데이터를 구조적으로 관리하기 어려움
2. 스프레드시트를 이용한 데이터 관리
- 테이블의 열과 행을 사용해 데이터를 구조적으로 관리 가능
스프레드 시트의 한계
- 크기 : 일반적으로 약 100만 행까지만 저장 가능
- 보안 : 단순히 파일이나 링크 소유 여부에 따른 단순한 접근 권한 기능 제공
- 정확성
- 만약 공식적으로 '강원'의 지명이 '강언'으로 바뀌었다고 가정한다면?- 이 변경으로 인해 테이블 모든 위치에서 해당 값을 업데이트 해야 함
- 찾기 및 바꾸기 기능을 사용해 바꿀 수 있지만 만약 데이터가 여러 시트에 분산되어 있다면 변경에 누락이 생기거나 추가 문제가 발생할 수 있음
Relatinal Database
데이터베이스 역할
데이터를 저장(구조적 저장) 하고 조작(CRUD)
관계형 데이터베이스
- 데이터 간에
관계가 있는 데이터 항목들의 모음 - 테이블, 행, 열의 정보를 구조화하는 방식
서로 관련된 데이터 포인터를 저장하고 이에 대한액세스를 제공관계 : 여러 테이블 간의 (논리적) 연결
- 이 관계로 인해 두 테이블을 사용하여 데이터를 다양한 형식으로 조회할 수 있음
- 특정 날짜에 구매한 모든 고객 조회, 지난 달에 배송일이 지연된 고객 조회 등
관계형 데이터베이스 예시
-
고객 데이터 간 비교를 위해서는 어떤 값을 활용해야 할까?
-> 각 데이터에 고유한 식별 값을 부여하기(기본 키, Primary Key) -
누가 어떤 주문을 했는지 어떻게 식별할 수 있을까?
- 고객의 고유한 식별 값을 저장하자 (외래 키, Foregin Key)
관계형 데이터베이스 관련 키워드
1. Table(aka Relation)
- 데이터를 기록하는 곳
2. Field(aka Column, Attribute)(열 속성)
- 각 필드에는 고유한 데이터 형식(타입)이 지정됨
3. Record(aka Row, Tuple)
- 각 레코드에는 구체적인 데이터 값이 저장됨
4. Database(aka Schema)
- 테이블의 집합
5. Primary Key(기본 키)
- 각 레코드의 고유한 값
- 관계형 데이터베이스에서
레코드의 식별자로 활용
6. Foreign Key(외래 키)
- 테이블의 필드 중
다른테이블의 레코드를 식별할 수 있는 키 - 다른 테이블의 기본 키를 참조
- 각 레코드에서 서로 다른 테이블 간의
관계를 만드는 데사용
RDBMS
(Relational Database Management System)
- 데이터베이스를 관리하는 소프트웨어 프로그램(DBMS)에 관계형 붙은 것
- 관계형 데이터베이스를 관리하는 소프트웨어 프로그램
- SQLite / MySQL / Oracle Database / PostgreSQL
DBMS
- 데이터 저장 및 관리를 용이하게 하는 시스템
- 데이터베이스와 사용자 간의 인터페이스 역할
- 사용자가 데이터 구성, 업데이트, 모니터링, 백업, 복구 등을 할 수 있도록 도움
SQLite
- 경량의 오픈 소스 데이터베이스 관리 시스템
- 컴퓨터나 모바일 기기에 내장되어 간단하고 효율적인 데이터 저장 및 관리를 제공
- Table은 데이터가 기록되는 곳
- Table에는 행에서 고유하게 식별 가능한 기본 키라는 속성이 있으며, 외래 키를 사용하여 각 행에서 서로 다른 테이블 간의 관계를 만들 수 있음
- 데이터는 기본 키 또는 외래 키를 통해 결합(join)될 수 있는 여러 테이블에 걸쳐 구조화 됨
SQL
Structure Query Language

-
데이터베이스에 정보를 저장하고 처리하기 위한 프로그래밍 언어
-
관계형 데이터베이스와의 대화를 위해 사용하는 프로그래밍 언어
SQL Syntax

- SQL 키워드(SELECT / FROM)는 대소문자를 구분하지 않음
- 하지만 대문자로 작성하는 것을 권장 (명시적 구분) - 각 SQL Statements의 끝에는 세미콜론(;)이 필요
- 세미콜론은 각 SQL Statements을 구분하는 방법(명령어의 마침표)
SQL Statements
- SQL을 구성하는 가장 기본적인 코드 블록
수행 목적에 따른 SQL Statements의 4가지 유형
DDL
| Data Definition Language | 데이터 정의_데이터의 기본 구조 및 형식 변경 | CREATE / DROP/ ALTER |
|---|
DQL
| Data Query Language | 데이터 검색 = 조회(R)에 해당 | SELECT |
|---|
DML
| Data Manipulation Language | 데이터 조작(추가, 수정, 삭제) | INSERT / UPDATE / DELETE |
|---|
DCL
| Data Control Language | 데이터 제어_데이터 및 작업에 대한 사용자 권한 제어 | COMMIT / ROLLBACK / GRANT / REVOKE |
|---|
참고
Query
- "데이터베이스로부터 정보를
요청" 하는 것 - 일반적으로 SQL로 작성하는 코드를 쿼리문(SQL문)이라 함
SQL표준
- SQL은 미국 국립 표준 협회(ANSI)와 국제 표준화 기구(ISO)에 의해 표준이 채택됨
- 모든 RDBMS에서 SQL을 지원
- 다만 각 RDBMS마다 독자적인 기능에 따라 표준을 벗어나는 문법이 존재하니 주의
Single Table Queries_ Querying data
SELECT statement
- 테이블에서 데이터를 조회
- '
*'(asterisk)를 사용하여 모든 필드 선택
SELECT
select_list
FROM
table_name;
- SELECT 키워드 이후 데이터를 선택하려는 필드를 하나 이상 지정
- FROM 키워드 이후 데이터를 선택하려는 테이블의 이름을 지정
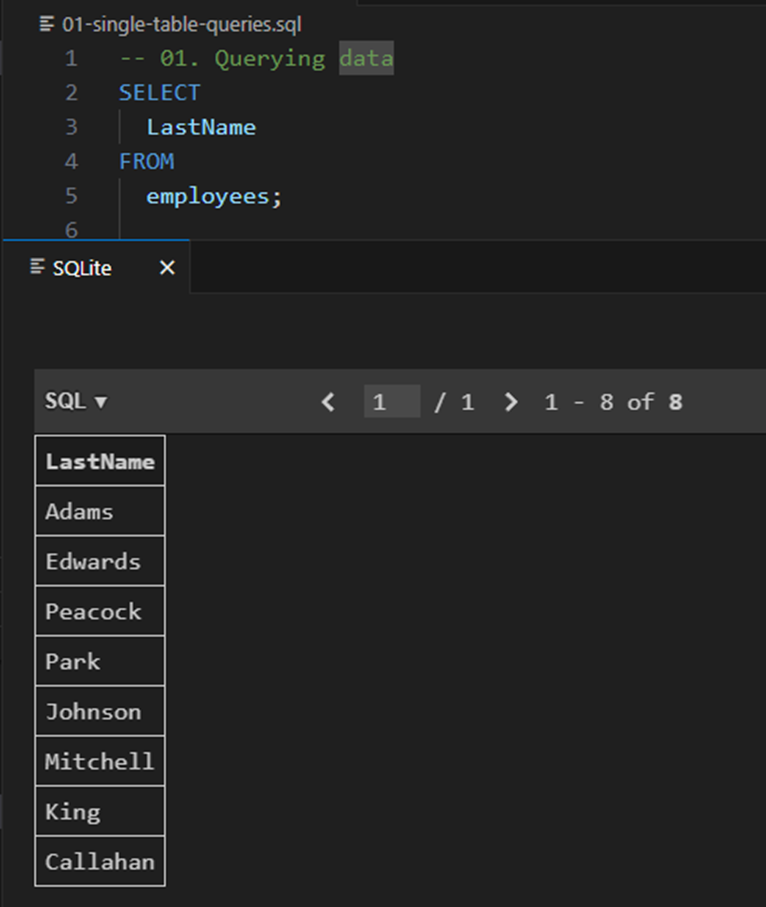
| SELECT 활용 1 |
|---|
| 테이블 employees에서 모든 필드 데이터를 조회 |
 |
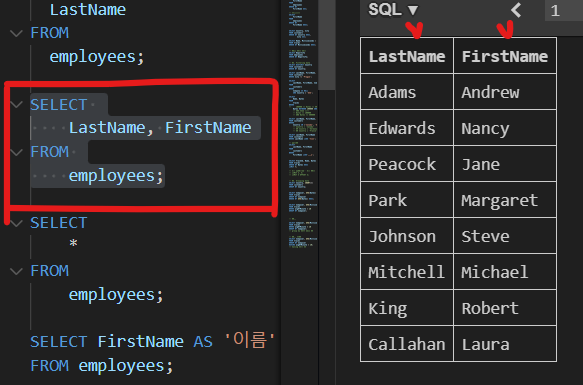
| SELECT 활용 2 |
|---|
| 테이블 employees에서 LastName, FirstName 필드의 모든 데이터를 조회 |
 |
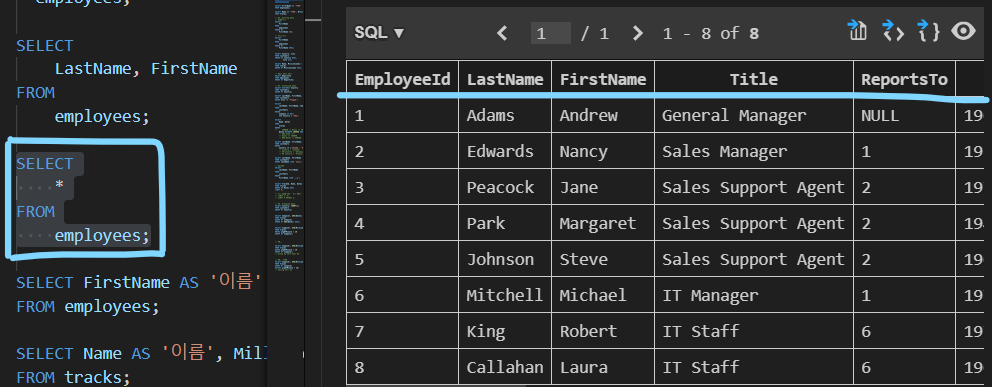
| SELECT 활용 3 |
|---|
| 테이블 employees에서 LastName, FirstName 필드의 모든 데이터를 조회 |
 |
| SELECT 활용 4 |
|---|
| 테이블 employees에서 FirstName 필드의 모든 데이터를 조회 |
| (단, 조회 시 FirstName이 아닌 '이름'으로 출력될 수 있도록 변경) |
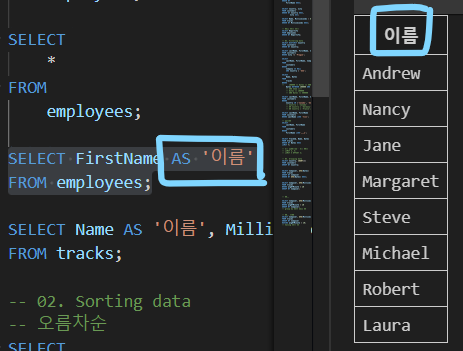 |
| SELECT 활용 5 |
|---|
| 테이블 tracks에서 Name, Milliseconds 필드의 모든 데이터를 조회 |
| (단, 조회 시 Milliseconds 필드는 60000으로 나눠 분 단위 값으로 출력) |
|
❗ Sorting data
ORDER BY statement
- 조회 결과 레코드를 정렬
SELECT
select_list
FROM
table_name
ORDER BY
column1 [ASC|DESC],
column2 [ASC|DESC],
...;
- FROM clause에 위치
- 하나 이상의 컬럼을 기준으로 결과를 오름차순(
ASC, 기본 값), 내림차순(DESC)으로 정렬
| ORDER BY 활용 1 |
|---|
| 테이블 customers에서 Country 필드를 기준으로 내림차순으로 정렬 한 다음, City 필드 기준으로 오름차순 정렬하여 조회 |
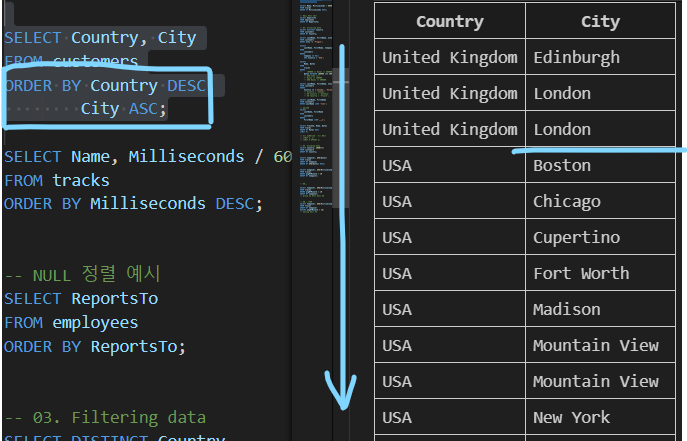 |
| ORDER BY 활용 2 |
|---|
| 테이블 tracks에서 Milliseconds 필드를 기준으로 내림차순으로 정렬 한 다음, Name, Milliseconds 필드의 모든 데이터를 조회 |
| (단, 조회 시 Milliseconds 필드는 60000으로 나눠 분 단위 값으로 출력) |
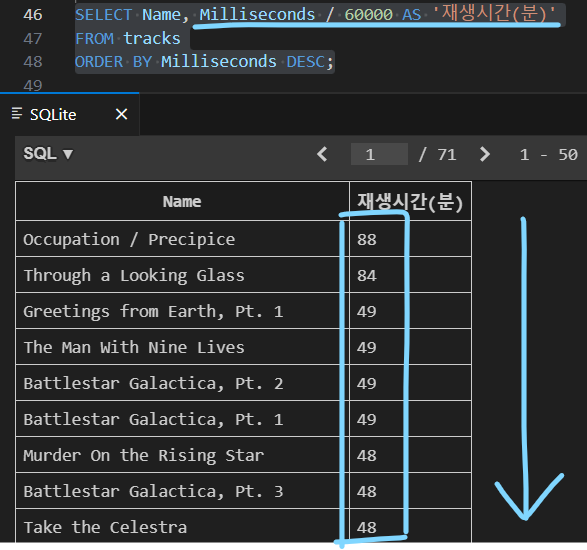 |
정렬에서의 NULL
- NULL 값이 존재할 경우 오름차순 정렬 시 결과에 NULL 값이 먼저 출력
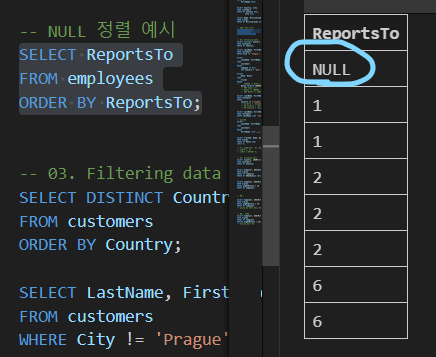
SELECT statement 실행 순서
From -> Select -> order by
테이블에서(from) 조회하여(select) 정렬(oder by)
❗ Filtering data
Filtering data 관련 Keywords
Clause(절)
- DISTINCT
- WHERE
- LIMIT
Operator(연산자)
- BETWEEN
- IN
- LIKE
- Comparison(비교연산자)
- Logical(논리연산자)
1. Clause(절)
1_1. Distinct statement
- 조회 결과에서 중복된 레코드를 제거
SELECT DISTINCT
select_list
FROM
table_name;
- SELECT 키워드 바로 뒤에 작성해야 함
- SELECT DISTINCT 키워드 다음에 고유한 값을 선택하려는 하나 이상의 필드를 지정
| DISTINCT 활용 |
|---|
| 테이블 customers에서 Country 필드의 모든 데이터를 중복없이 오름차순 조회 |
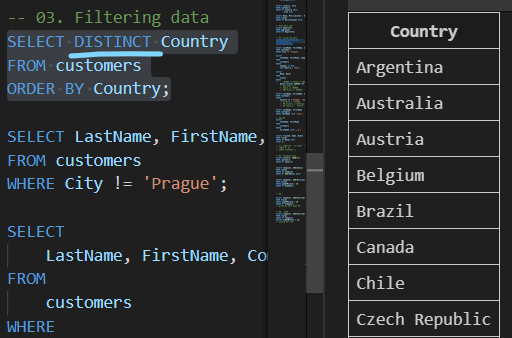 |
1_2. WHERE statement★
- 조회 시 특정 검색 조건을 지정
SELECT
select_list
FROM
table_name
WHERE
search_condition;
- FROM claus 뒤에 위치
- search_condition은 비교연산자 및 논리연산자(AND,OR,NOT등)를 사용하는 구문이 사용됨
| WHERE 활용 1 |
|---|
| 테이블 customers에서 City 필드 값이 'Prague'가 아닌 데이터의 LastName, FirstName, City 조회 |
| SELECT LastName, FirstName, City FROM customers WHERE City != 'Prague'; |
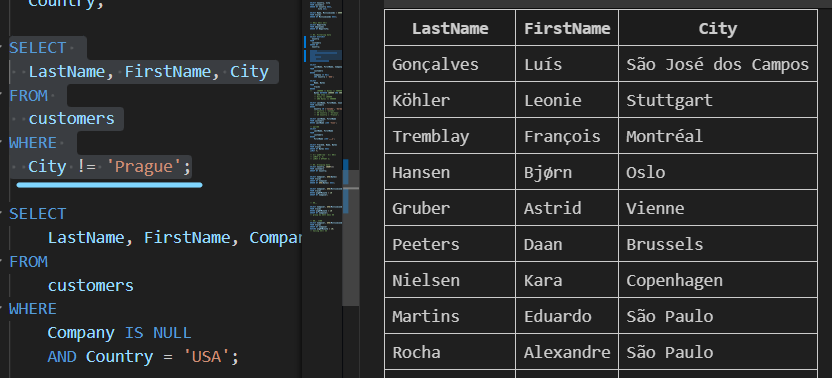 |
| WHERE 활용 2 |
|---|
| 테이블 customers에서 Company 필드 값이 Null이고 Contry 필드 값이 'USA'인 아닌 데이터의 LastName, FirstName, Company, Country 조회 |
| SELECT LastName, FirstName, Company, Country FROM customers WHERE Company IS NULL AND Country = 'USA'; |
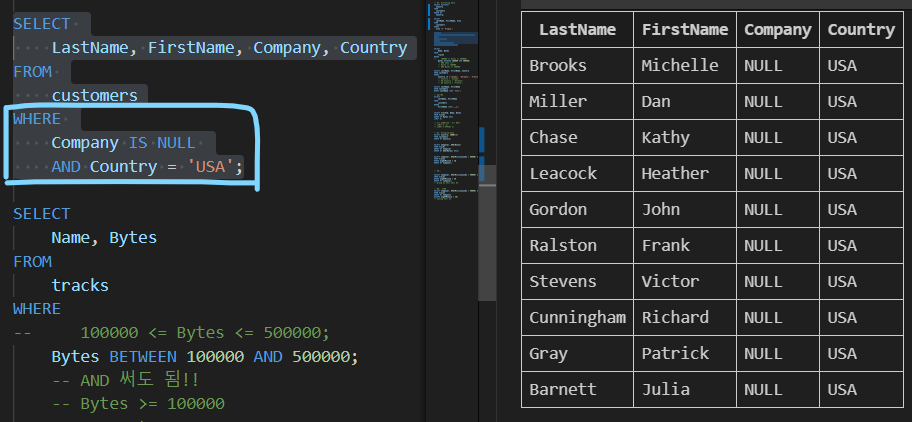 |
| WHERE 활용 3 |
|---|
| 테이블 tracks에서 Bytes 필드 값이 100000 이상 500000 이하인 데이터의 Name, Bytes 조회 |
| SELECT Name, Bytes FROM tracks WHERE Bytes BETWEEN 100000 AND 500000; |
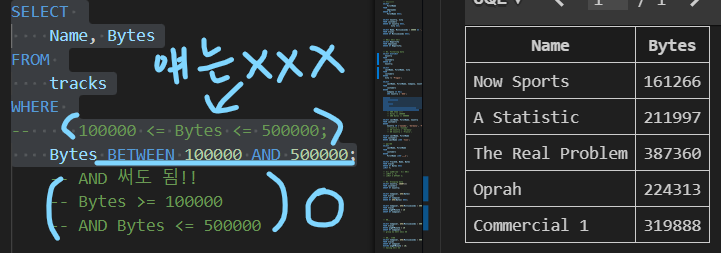 |
| WHERE 활용 4 |
|---|
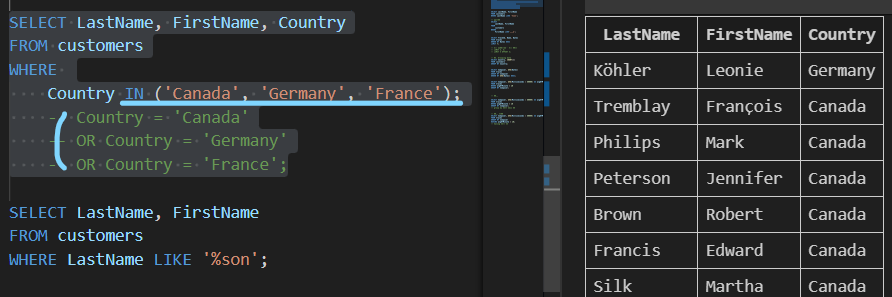
| 테이블 customers 에서 Country 필드 값이 'Canada' 또는 'Germany'또는 'France'인 데이터의 LastName, FirstName, Country 조회 |
| SELECT LastName, FirstName, Country FROM customers WHERE Country IN ( 'Canada','Germany', 'France'); |
 |
| WHERE 활용 5 |
|---|
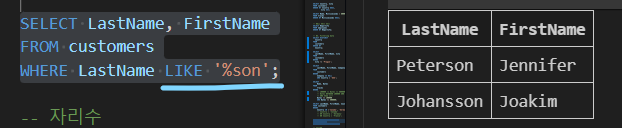
| 테이블 customers 에서 LastName 필드 값이 son으로 끝나는 데이터의 LastName, FirstName 조회 |
| SELECT LastName, FirstName FROM customers WHERE LastName LIKE '%son'; |
 |
| WHERE 활용6 |
|---|
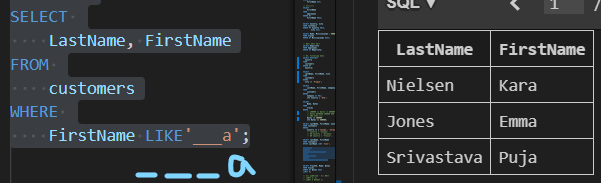
| 테이블 customers 에서 FirstName 필드 값이 4자리면서 'a'로 끝나는 데이터의 LastName, FirstName 조회 |
SELECT LastName, FirstName FROM customers WHERE FirstName LIKE '___a'; |
 |
1_3. Limit
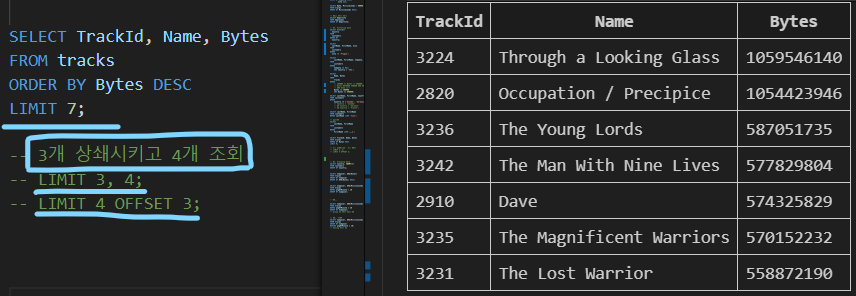
LIMIT clause
- 조회하는 레코드 수를 제한
SELECT
select_list
FROM
table_name
LIMIT [offset,] row_count;- 하나 또는 두 개의 인자를 사용(0 또는 양의 정수)
- row_count는
조회하는 최대 레코드 수를 지정
2. Operators(연산자)
2_1. Comparison Operators
- 비교 연산자 : =, >=, <= , !=, IS, LIKE, IN, BETWEEN ... AND
2_1_1. IN Operator
- 값이 특정 목록 안에 있는지 확인
2_1_2. LIKE Operator
- 값이 특정 패턴에 일치하는 확인(Wildcards와 함께 사용)
Wildcard Characters
%: 0개 이상의 문자열과 일치하는지 확인_: 단일 문자와 일치하는지 확인
2_2. Logical Operators
- 논리 연산자 : and(&&), or(||), not(!)
❗ Grouping data
GROUP BY clause
- 레코드를 그룹화하여 요약본 생성('집계함수'와 함께 사용)
집계함수(Aggregation Functions)
- 값에 대한 계산을 수행하고 단일한 값을 반환하는 함수
SUM,AVG,MAX,MIN,COUNT
SELECT
c1, c2, ..., cn, aggregate_functions(ci)
FROM
table_name
GROUP BY
c1, c2, ... , cn;
- FROM 절 WHERE 절 뒤에 배치
- GROUP BY 절 뒤에 그룹화 할 필드 목록을 작성
| GROUP BY 활용 1 |
|---|
| COUNT 함수가 각 그룹에 대한 집계된 값을 계산 |
| SELECT Country, COUNT(*) FROM customers GROUP BY Country; |
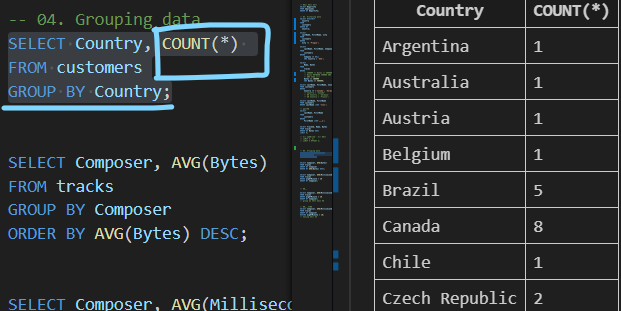 |
| GROUP BY 활용 2 |
|---|
| 테이블 tracks에서 Composer 필드를 그룹화하여 각 그룹에 대한 Bytes의 평균 값을 내림차순 조회 |
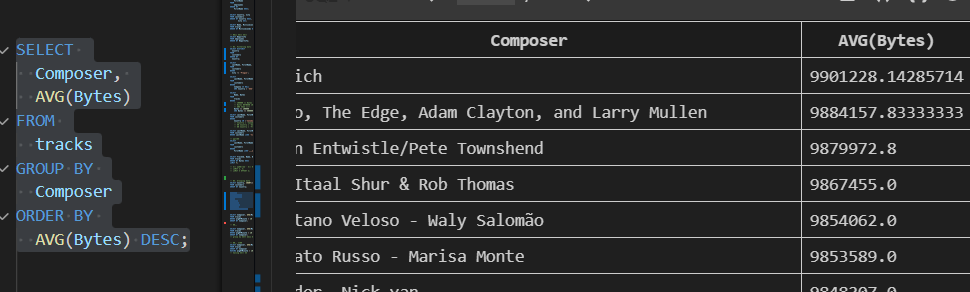 |
HAVING clause
- 집계 항목에 대한 세부 조건을 지정
- 주로 GROUP BY 와 함께 사용되며 GROUP BY가 없다면 WHERE처럼 동작
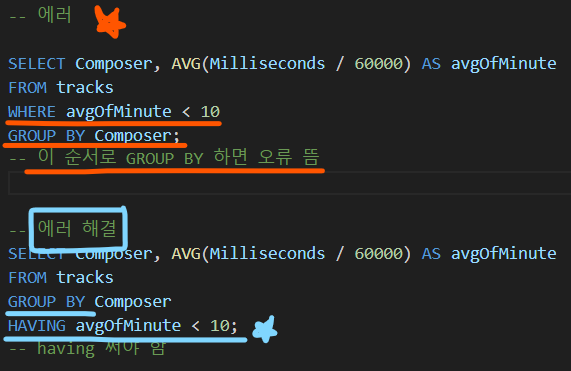
SELECT statement 실행 순서

테이블에서(
FROM) 특정 조건에 맞추어(WHERE) 그룹화하고(GROUP BY) 만약 그룹 중에서 조건이 있다면 맞추고(HAVING) 조회하여(SELECT) 정렬하고(ORDER BY) 특정 위치의 값을 가져옴(LIMIT)
Managing Tables
Create a table
- 테이블 생성
CREATE TABLE table_name(
column_1 data_type constraints,
column_2 data_type constraints,
...,
);
- 각 필드에 적용할 데이터 타입 작성
- 테이블 및 필드에 대한 제약조건(constraints) 작성
| examples 테이블 생성 및 확인 |
|---|
 |
| 테이블 스키마(구조) 확인 - PRAGMA |
|---|
 |
SQLite 데이터 타입
NULL: 아무런 값도 포함하지 않음을 나타냄INTEGER: 정수REAL: 부동 소수점TEXT: 문자열BLOB: 이미지, 동영상, 문서 등의 바이너리 데이터
Constraints (제약 조건)
- 테이블의 필드에 적용되는 규칙 또는 제한 사항
- 데이터의 무결성을 유지하고 데이터베이스의 일관성을 보장
대표적인 제약 조건
PRIMARY KEY: 해당 필드를 기본 키로 지정
: INTEGER 타입에만 적용되며, INT, BIGINT 등과 같은 정수 유형은 적용안됨NOT NULL: 해당 필드에 NULL 값을 허용하지 않도록 지정FOREIGN KEY: 다른 테이블과의 외래 키 관계를 정의
AUTOINCREMENT keyword
- 자동으로 고유한 정수 값을 생성하고 할당하는 필드 속성
- 특징
- 필드의 자동 증가를 나타내는 특수한 키워드- 주로 pirmary key 필드에 적용
INTEGER PRIMARY KEY AUTOINCREMENT가 작성된 필드는 항상 새로운 레코드에 대해 이전 최대 값보다 큰 값을 할당- 삭제된 값은 무시되며 재사용할 수 없게 됨
Modifying table fields
ALTER TABLE statement
- 테이블 및 필드 조작
| ALTER TABLE 역할 |
|---|
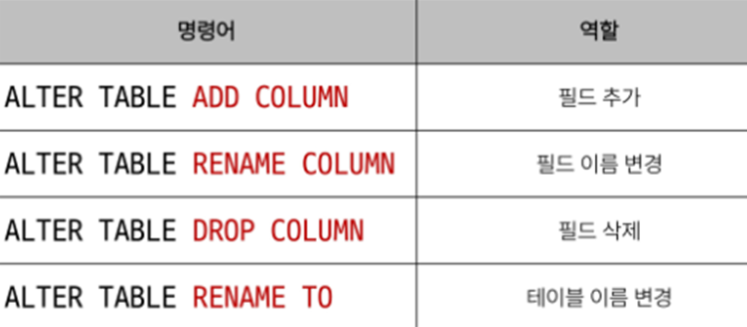 |
ALTER TABLE ADD COLUMN syntax
ALTER TABLE
table_name
ADD COLUMN
column_definition;
- ADD COLUMN 키워드 이후 추가하고자 하는 새 필드 이름과 데이터 타입 및 제약 조건 작성
- SQLite는 단일 문을 사용하여 한번에 여러 필드를 추가할 수 없당
ALTER TABLE RENAME COLUMN syntax
ALTER TABLE
table_name
RENAME COLUMN
current_name TO new_name;
RENAME COLUMN키워드 뒤에 이름을 바꾸려는 필드의 이름을 지정하고TO키워드 뒤에 새 이름을 지정
ALTER TABLE DROP COLUMN syntax
ALTER TABLE
table_name
DROP COLUMN
current_name;
DROP COLUMN키워드 뒤에 삭제하려는 필드의 이름을 지정- 삭제하는 필드가 다른 부분에서 참조되지 않고 PRIMARY KEY가 아니며 UNIQUE 제약조건이 없는 경우에만 작동
ALTER TABLE RENAME TO syntax
ALTER TABLE
table_name
RENAME TO
current_name TO new_name;
RENAME TO키워드 뒤에 새로운 테이블 이름 지정
Delete a table
DROP TABLE statement
- 테이블 삭제
DROP TABLE table_name;DROP TABLE statement 이후 삭제할 테이블 이름 작성
Modifying Data
DML데이터 조작(추가, 수정, 삭제) INSERT, UDATE, DELETE
Insert data
INSERT statement
- 테이블 레코드 삽입
INSERT INTO table_nema
(c1, c2, ...)
VALUES
('v1', 'v2', 'v3'...);
INSERT INTO절 다음에 테이블 이름과 괄호 안에 필드 목록 작성VALUES키워드 다음 괄호 안에 해당 필드에 삽입할 값 목록 작성
Update data
UPDATE statement
- 테이블 레코드 수정
UPDATE table_name
SET column_name = 'expression'
[WHERE
condition];
SET절 다음에 수정할 필드와 새 값을 지정WHERE절에서 수정 할 레코드를 지정하는 조건 작성WHERE절을 작성하지 않으면 모든 레코드를 수정한다!

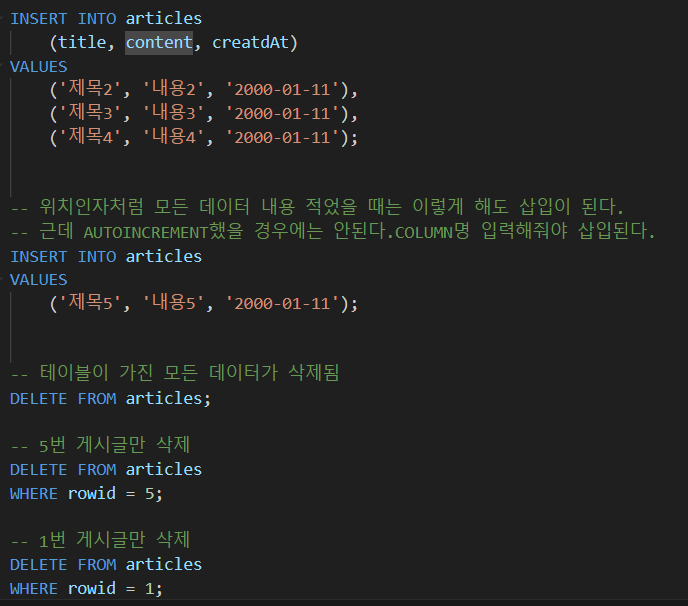
Delete data
DELETE statement
- 테이블 레코드 삭제
DELETE FROM table_name
[WHERE
condition];
DELETE FROM절 다음에 테이블 이름 작성- WHERE 절에서 삭제할 레코드를 지정하는 조건 작성
- WHERE 절을 작성하지 않으면 모든 레코드를 삭제한다!
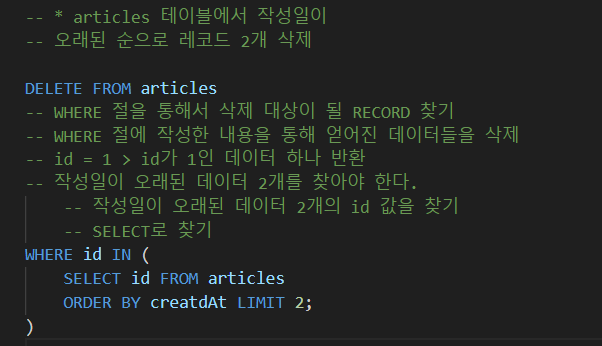
Multi table queries
관계
여러테이블 간의 (논리적) 연결- 관계의 필요성
- 커뮤니티 게시판에 필요한 데이터 생각해보기
- 하석주가 작성한 모든 게시글을 조회하기
- 어떤 문제점이 있을까?
- 동명이인이 있다면, 혹은 특정 데이터가 수정된다면?
- 테이블을 나누어서 분류하자!! 각 게시글은 누가 작성했는지 알 수 있을까??
- 작성자들의 역할은 무엇일까?
- articles와 users 테이블에 각각 userid, roleid외래 키 필드 작성
JOIN이 필요한 순간
테이블을 분리하면 데이터 관리는 용이해질 수 있으나 출력시에는 문제가 있음
테이블 한 개 만을 출력할 수 밖에 없어 다른 테이블과 결합하여 출력하는 것이 필요해짐
Joining tables
JOIN clause
- 둘 이상의 테이블에서 데이터를 검색하는 방법
종류
- INNER JOIN
- LEFT JOIN
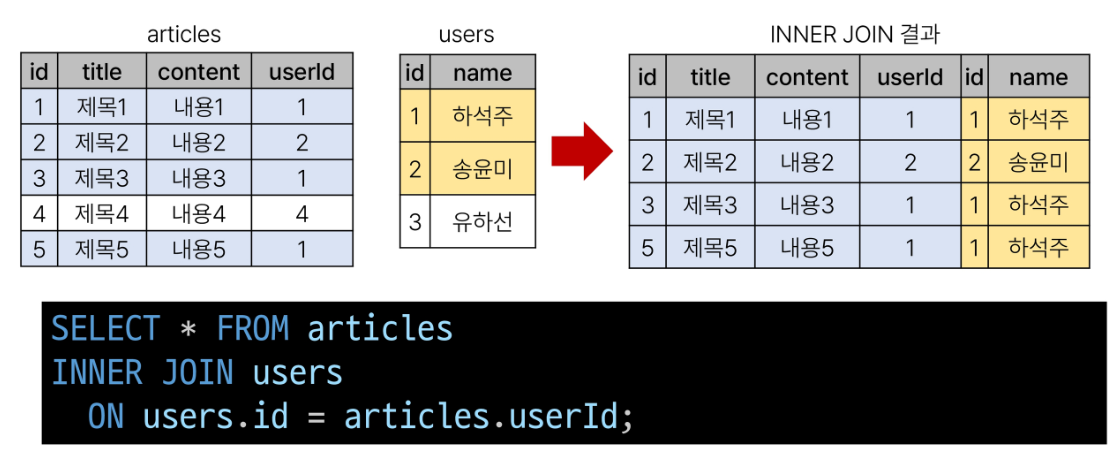
INNER JOIN claues
- 두 테이블에서 값이 일치하는 레코드에 대해서만 결과를 반환
SELECT
select_list
FROM
table_a
INNER JOIN table_b
ON table_b.fk = table_a.pk;
# fk = 외래키
# pk = 고유식별자
FROM절 이후 메인 테이블 지정(table_a)INNER JOIN절 이후 메인 테이블과 조인할 테이블을 지정(table_b)ON키워드 이후 조인 조건을 작성- 조인조건은 table_a와 table_b간의 레코드를 일치시키는 규칙을 지정
LEFT JOIN claues
- 오른쪽 테이블의 일치하는 레코드와 함께 왼쪽 레코드의 모든 레코드 반환
SELECT
select_list
FROM
table_a
LEFT JOIN table_b
ON table_b.fk = table_a.pk;
# fk = 외래키
# pk = 고유식별자
FROM절 이후 왼쪽 테이블 지정(table_a)INNER JOIN절 이후 오른쪽 테이블 지정(table_b)ON키워드 이후 조인 조건을 작성
- 왼쪽 테이블의 각 레코드를 오른쪽 테이블의 모든 레코드와 일치시킴
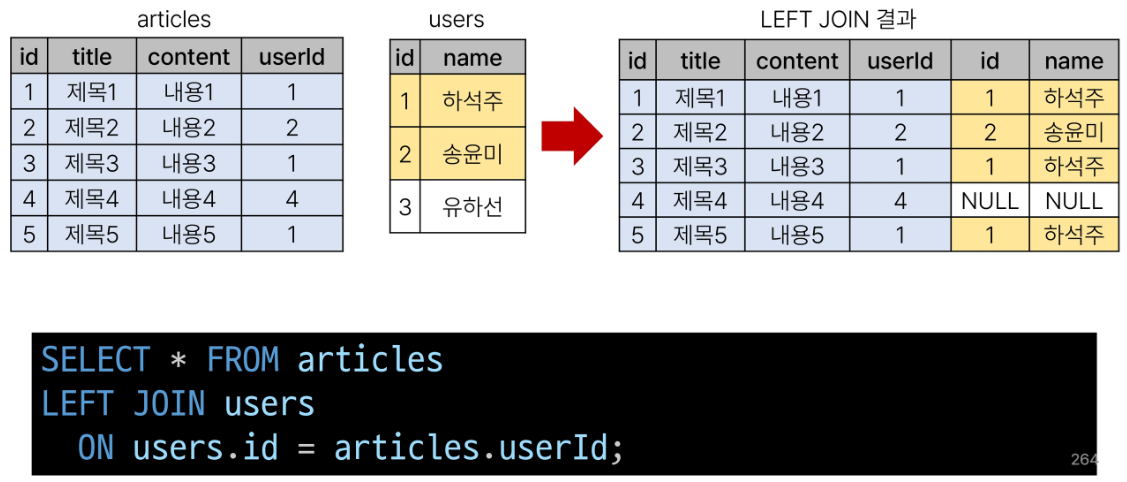
LEFT JOIN 특징
- 왼쪽은 테이블의 모든 레코드를 표기
- 오른쪽 테이블과 매칭되는 레코드가 없으면 NULL을 표시

나의 행복 만들기